





点击蓝字,关注我们

👋 大家好,我是远朋。过去 3 年,我们团队把部分调度任务从 Azkaban 逐步迁移到 DolphinScheduler,并开展了 K8s 容器化。今天把踩过的坑、攒下的经验一次性复盘,建议收藏!
作者介绍
王远朋
奇虎科技 数据专家
商业化SRE&大数据团队核心成员
长期负责DolphinScheduler在生产环境的部署与优化,具备丰富的容器化与大数据调度经验。
作者介绍
王远朋
奇虎科技 数据专家
商业化SRE&大数据团队核心成员
长期负责DolphinScheduler在生产环境的部署与优化,具备丰富的容器化与大数据调度经验。

在大数据任务调度的日常工作中,Apache DolphinScheduler 已经成为我们团队最核心的工具之一。过去我们一直依赖物理机进行部署,例如 3.1.9 版本仍运行在物理机环境中,但这种方式在弹性扩展、资源隔离和运维效率上逐渐暴露出问题。随着公司整体的云原生战略推进,我们最终在 2025 年将 DolphinScheduler 升级到 3.2.2,并部分迁移到 Kubernetes 平台。
1
镜像构建:从源码到模块
在迁移过程中,镜像构建是第一步。

我们先准备了一个包含 Hadoop、Hive、Spark、Flink、Python 等环境的基础镜像,然后在此基础上构建 DolphinScheduler 的基础镜像,将重新编译的各个模块和 MySQL 驱动打包其中。

这里需要注意的是,MySQL 被用作 DolphinScheduler 的元数据存储,因此驱动包必须软链到每一个模块,包括 dolphinscheduler-tools
、dolphinscheduler-master
、dolphinscheduler-worker
、dolphinscheduler-api
和 dolphinscheduler-alert-server
。

Worker镜像
模块镜像则是在 DS 基础镜像之上进行定制,主要修改端口和配置。为了减少后续配置文件的改动,我们尽量保持模块镜像的名称与官方一致。构建时既可以单独构建某个模块,例如:
./build.sh worker-server
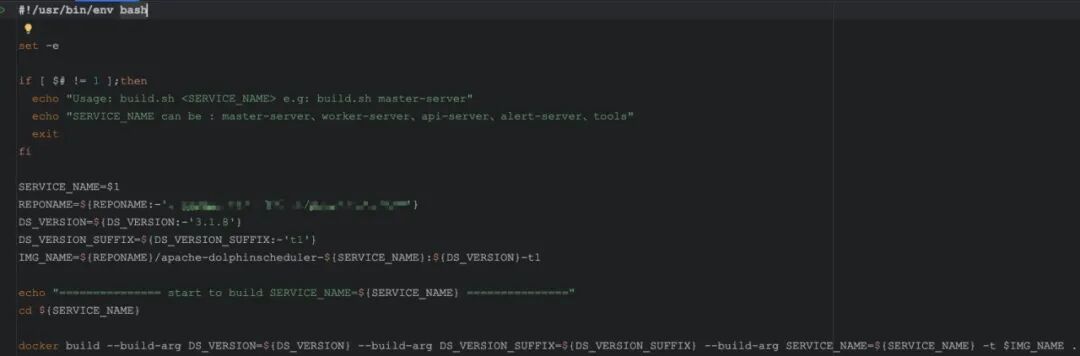
单独构建镜像
也可以批量构建所有模块:
./build-all.sh

批量构建镜像
这一步里我们遇到的典型问题包括:基础镜像过大导致构建时间过长,源码改造后的 jar 包没有覆盖旧文件,甚至不同模块的端口配置和启动脚本不一致。 这些细节如果处理不当,就会在后续部署阶段带来一系列棘手的问题。
lib/目录 | |
find -name "*.jar" -delete |
2
部署方案:
从自制YAML到官方Helm Chart
2
部署方案:
从自制YAML到官方Helm Chart
在部署初期,我们是手写 YAML 文件来完成部署的,但这种方式在配置分散和升级维护上成本极高。后来我们改用了官方提供的 Helm Chart,这样配置集中管理,升级也更方便。
我们使用的 K8S 集群版本是 v1.25,部署时需要先创建命名空间 dolphinscheduler
,然后拉取 helm 包,例如:
helm pull oci://registry-1.docker.io/apache/dolphinscheduler-helm --version 3.2.2
在真正落地过程中,values.yaml
是最核心的文件,我们在这里踩过很多坑。下面贴出几个关键配置片段,供大家参考:
1. 镜像配置
image:registry: my.private.reporepository: dolphinschedulertag: 3.2.2pullPolicy: IfNotPresent
👉 提示:一些前置的工具镜像最好提前 push 到私有仓库,避免因网络或镜像源问题导致部署失败。
2. 外置数据库配置(MySQL)
mysql:enabled: false # 关闭内置 MySQLexternalMysql:host: mysql.prod.localport: 3306username: ds_userpassword: ds_passworddatabase: dolphinscheduler
👉 内置数据库务必关闭,生产环境统一接入外部 MySQL(未来我们将切换到 PostgreSQL)。
3. LDAP 登录认证
ldap:enabled: trueurl: ldap://ldap.prod.local:389userDn: cn=admin,dc=company,dc=compassword: ldap_passwordbaseDn: dc=company,dc=com
👉 我们接入了公司 LDAP,统一用户认证,方便权限管理。
4. 共享存储配置
sharedStoragePersistence:enabled: truestorageClassName: nfs-rwxsize: 100GimountPath: /dolphinscheduler/shared
👉 注意:storageClassName 必须支持 ReadWriteMany
,否则多个 Worker 节点无法同时访问共享目录。

5. HDFS 配置
hdfs:defaultFS: hdfs://hdfs-nn:8020path: dolphinschedulerrootUser: hdfs
👉 所有大数据相关组件路径需要提前准备好,例如 /opt/soft
。
6. Zookeeper 配置
zookeeper:enabled: false # 关闭内置 ZKexternalZookeeper:quorum: zk1.prod.local:2181,zk2.prod.local:2181,zk3.prod.local:2181
👉 使用外置 Zookeeper 时,记得关闭内置配置,同时确认 ZK 版本符合官方最低要求。
3
踩坑经验与维护挑战
在整个迁移过程中,我们踩过的坑不少。比如,镜像制作问题、Helm values.yaml 修改的坑,以及定制化升级和维护成本过高等。
镜像制作相关问题
镜像制作时因为基础镜像太大,导致构建过程漫长; 模块依赖差异导致重复安装; 有时候 MySQL 驱动包路径不正确,模块启动时报错; 源码改造后的 jar 包忘记覆盖旧文件,也曾造成过运行时异常,不同模块端口与启动脚本不一致,导致启动不顺利。
Helm values.yaml 注意点
sharedStoragePersistence.storageClassName 必须支持 ReadWriteMany存储类 storage 大小 mountPath 与配置文件不一致 配置项路径缩进 关闭默认配置以及一些不需要的配置,例如Zookeeper 外置时需关闭内置选项,同时注意zk需要的版本
维护升级成本
更大的挑战来自后续维护。因为我们对源码和镜像做过定制化修改,所以每当 DolphinScheduler 发布新版本,我们都需要重新对比修改点,重新构建并测试全部模块镜像。
同时,由于不同版本之间配置项差异较大,升级和回滚的过程都容易出错。这些问题导致我们的升级周期变长,维护难度加大,团队人力成本也显著上升。
4
未来规划与思考
4
未来规划与思考
为了降低长期的运维成本,我们已经在逐步推进标准化。未来计划包括:
将 DolphinScheduler 的元数据库从 MySQL 切换到 PostgreSQL,全面采用社区官方镜像而非自研镜像,生产任务也会逐步迁移到 K8S 环境中。
同时,我们会引入 CI/CD 流程,并结合 Prometheus 与 Grafana 做可观测性建设,提升部署效率与监控能力。
总的来说,K8S 部署让 DolphinScheduler 在扩展性、弹性和迁移性上具备了远超物理机的优势。虽然镜像定制化和配置修改带来了不小的挑战,但随着我们逐渐回归社区版本和标准化运维,维护成本会越来越低,部署效率会越来越高。
我们的长期目标,是构建一个高可用、易扩展、统一化的调度平台,真正释放云原生的价值。如果你也在考虑把调度系统搬上 K8s,欢迎评论区交流,或加入 DolphinScheduler 社区一起搬砖!



用户案例
迁移实战
发版消息
加入社区
关注社区的方式有很多:
GitHub: https://github.com/apache/dolphinscheduler 官网:https://dolphinscheduler.apache.org/en-us 订阅开发者邮件:dev@dolphinscheduler@apache.org X.com:@DolphinSchedule YouTube:https://www.youtube.com/@apachedolphinscheduler Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
📂非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
👩💻代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。

你的好友秀秀子拍了拍你
并请你帮她点一下“分享”
