




导读
Redo 是数据库事务的生命线,Oracle 通过先写日志再改数据,保证了任何时候的事务安全。那么,Redo 究竟是什么?它又是如何保障数据库的稳定运行的呢?
本次我们邀请到云和恩墨技术顾问惠星星,带来《深入解析:Oracle redo log运行机制精彩分享,他将从概念、结构、生成过程、归档管理和常见问题等多个维度,系统解析 Oracle Redo 的机制与原理。
本文整理自直播分享,部分语句在不改变原意的基础上做了更改。
演讲资料:https://www.modb.pro/doc/146799
视频回放:https://www.modb.pro/video/10648
大家好!很高兴今天能在这里与大家交流 Oracle 数据库相关的技术实践。今天,我将围绕 Redo 日志及其在数据库事务安全、灾难恢复和主备同步中的应用,分享一些在实际运维和恢复策略中的经验与思考。希望通过本次交流,大家能对 Redo 的内部结构、生成流程、归档管理以及常见问题有更清晰的理解,从而在日常管理和故障应对中更加得心应手。

惠星星
前Oracle ACE,获得Oracle 10G OCP 11G OCP 11G OCM认证
个人技术Blog:http://blog.itpub.net/31442014/
云和恩墨西区技术顾问,公众号:数据库技术笔记
什么是 Oracle Redo
1. 在线日志:保障事务安全
联机重做日志(Online Redo Log Files)是 Oracle 数据库中最关键的物理文件之一。它采用 预写式日志(Write-Ahead Logging, WAL) 机制,其核心原则是:
日志先写入,再修改数据
这一机制确保了:
- 即便数据库意外中断,也可以依靠 redo 日志恢复所有已提交的事务;
- 数据库始终保持强一致性,避免因崩溃而出现“丢账”情况。
📌 关键组成:
- Redo Log Buffer:内存中的循环缓冲区,用于记录数据库变更;
- LGWR(Log Writer):负责将缓冲区中的内容安全写入日志文件,确保数据持久性。
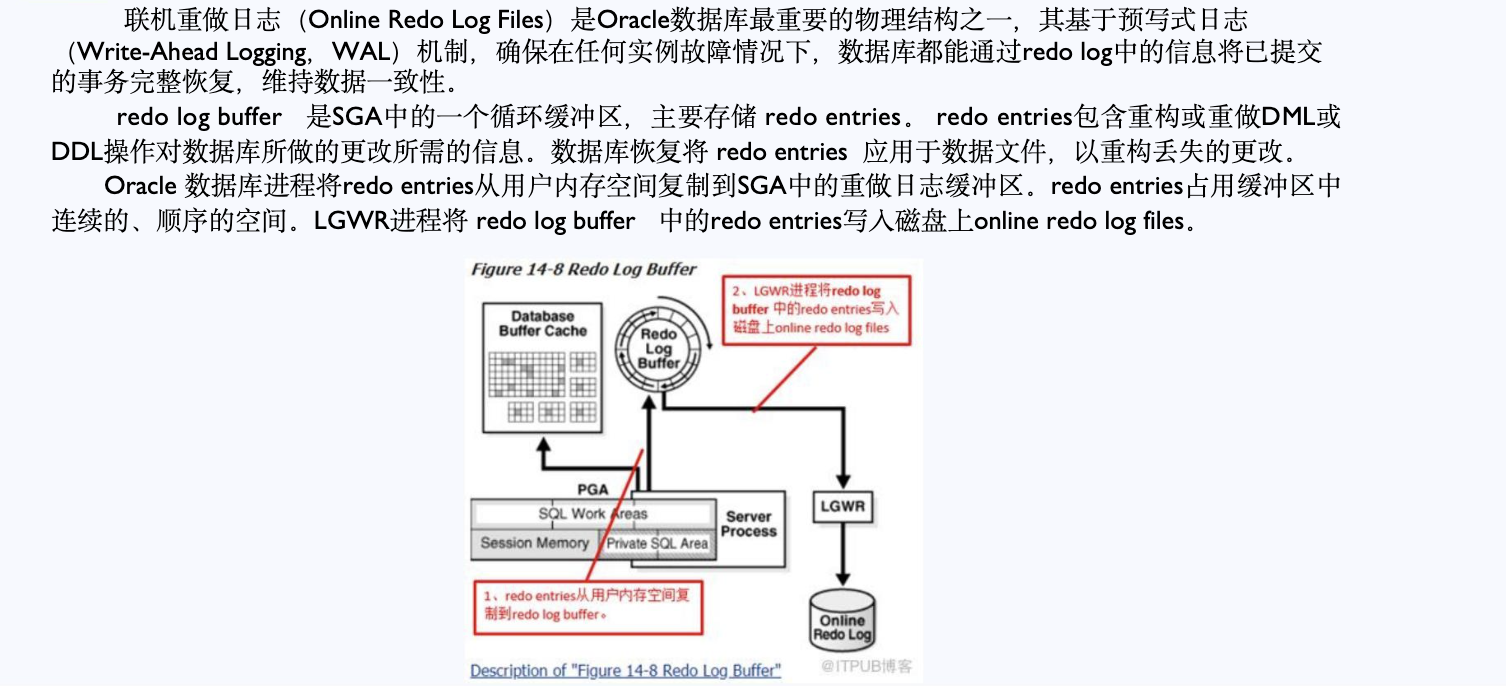
图1:在线日志概念定义
2. 归档日志:恢复与灾备的关键
归档重做日志(Archive Redo Log Files)是已写满的联机日志组的副本,由数据库自动生成并存放到用户指定的目录中。它在数据库的安全性和可用性中扮演着非常重要的角色:
- 数据库恢复:在数据库意外崩溃或遇到灾难性事件时,归档日志是将数据库恢复到最新状态的关键依据。
- 主备同步:在 Oracle Data Guard 等主备环境中,归档日志可传输到备库,确保主库和备库的数据一致性。
- 历史追溯:结合 Log Miner 工具,归档日志可用于解析历史操作记录,甚至实现反向恢复或回滚操作。
可以把归档日志理解为 Oracle 的“黑匣子”:即便系统宕机,也能从中找到完整的变更记录,帮助数据库恢复和审计。

图2:归档日志概念定义
3. Redo 内部结构:Change Vector
在了解了联机重做日志的基本作用之后,我们来看 Redo 的内部结构。需要注意的是,Redo 记录的并不是 SQL 语句本身,而是 数据库块的变更信息(Block Changes)。
其中的核心单元是 Change Vector(Redo Vector),它包含:
- 块的原始镜像(Before Block Image)
- 操作代码
- 具体的变更内容
多个 Change Vector 可以组成一个 Redo Record,从而保证数据库变更的 一致性与原子性。在内存中,这些记录会根据 SCN(System Change Number) 进行排序,最终由 LGWR 顺序写入 Redo 文件。Redo 文件采用首尾相接的组织方式,并结合 Sequence Number / Change Number 来保证日志的连续性,使得在恢复过程中可以精确还原数据。
4. 完全检查点:数据文件与日志对齐
在 Redo 机制中,检查点(Checkpoint) 是另一个不可或缺的概念。它的主要作用是将内存中的数据与磁盘上的数据进行同步,以确保数据一致性。
通过完全检查点,数据文件和日志文件在某一时刻实现了 完全对齐,为 Redo 的循环使用和数据库恢复奠定了基础。
实际上,Redo 体系还包含更多关键机制,例如:
- 各类 Checkpoint 的触发机制;
- Redo 的管理与日志切换策略;
- Resetlogs 在数据库恢复中的重要作用。
这些机制共同确保 Oracle 数据库在各种异常情况下,仍能高效、可靠地保障数据的完整性。
点击查看>完整技术文档
结构解析
1. Oracle Redo 生成过程
Oracle 数据库的 Redo 生成与写入过程较为复杂,主要步骤如下:
-
Server Process 在 User Memory Space 中产生 Redo Entry
当用户执行 DML 或 DDL 操作时,Server Process 会在用户内存空间生成 Redo Entry。这些信息是数据库恢复的重要依据。 -
Server Process 获取 Redo Copy Latch
用于保护 Redo Log Buffer 的数据一致性,防止多个进程同时写入。 -
Server Process 获取 Redo Allocation Latch
在 Redo Log Buffer 中分配空间,保证足够的存储并避免冲突。 -
在 Log Buffer 中分配空间
分配连续、顺序的空间存储 Redo Entry,Redo Log Buffer 是循环缓冲区。 -
释放 Redo Allocation Latch
允许其他进程分配空间,提高系统并发效率。 -
Server Process 将 Redo Entry 写入 Log Buffer
将内存中的内容完整写入缓冲区,确保数据准确完整。 -
释放 Redo Copy Latch
允许其他进程继续复制和写入 Redo Entry。 -
LGWR 进程将 Log Buffer 写入磁盘
核心环节,按照 Write-Ahead-Log 原则,将数据安全写入 Online Redo Log Files,为故障恢复提供保障。
通过以上步骤,Oracle 数据库能够高效地生成和管理 Redo Entries,确保故障恢复的快速与准确。
2. Oracle Redo 物理结构解析
Oracle 重做日志文件(Online Redo Log Files)物理结构关键点如下:
-
文件组成:
- 文件头(File Header):包含文件基本信息;
- 重做头(Redo Header):记录元数据;
- 重做记录(Redo Record):包含记录头和多个 Change Vector。
-
块大小:默认 512 字节,测试环境下 50MB 日志包含 102400 个块。
-
文件头信息:
- 文件类型、块大小、块数量;
- 数据库 ID、数据库名称;
- 文件编号、文件类型。
-
重做头信息:
- 重做日志块号、序列号;
- 磁盘校验和、兼容性版本;
- 控制序列、激活 ID;
- 描述线程号、SCN 范围等;
- Resetlogs count、Thread closed SCN、prev resetlogs count。
-
重做记录信息:
- RBA(Redo Block Address):物理位置标识;
- 长度、有效性标志、SCN、SUBSCN;
- 操作码(Opcode):插入、更新、删除、DDL 等;
- 对象 ID、数据块地址、撤销地址、列数据。
-
操作码分类示例:
- Undo Record、Commit、INSERT 单行/多行、DELETE、UPDATE 等;
- DDL 操作,如 CREATE TABLE。
-
RBA 组成:
- 日志序列号(4 字节)、块号(4 字节)、块内偏移量(2 字节)。
通过文件头、重做头和重做记录的明确字节布局,Redo 文件能够确保事务的原子性、数据变更顺序和物理定位精确性。
归档管理
在理解了 Redo 日志的生成与内部结构后,数据库的归档与日志切换管理成为保障数据安全和恢复能力的关键环节。归档管理主要涉及三个方面:归档备份、归档删除和日志切换触发机制。
1. 归档备份
归档日志备份是数据库灾备和恢复策略的重要组成部分。Oracle RMAN 提供了多种归档备份方式:
BACKUP ARCHIVELOG ALL—— 备份所有归档日志;
BACKUP ARCHIVELOG FROM SEQUENCE ... UNTIL SEQUENCE ... —— 按序列号范围备份归档日志;
BACKUP ARCHIVELOG ALL DELETE INPUT —— 备份完成后自动删除归档日志。
特别需要注意的是命令 BACKUP DATABASE PLUS ARCHIVELOG 的执行流程,它包括五个关键步骤:
- 归档当前日志;
- 备份所有已归档日志;
- 备份数据库数据文件;
- 再次归档新的日志;
- 备份新增归档日志。
在此过程中,至少会触发两次日志切换,这是很多人容易忽略的细节,也直接影响数据库恢复和 Redo 循环使用。
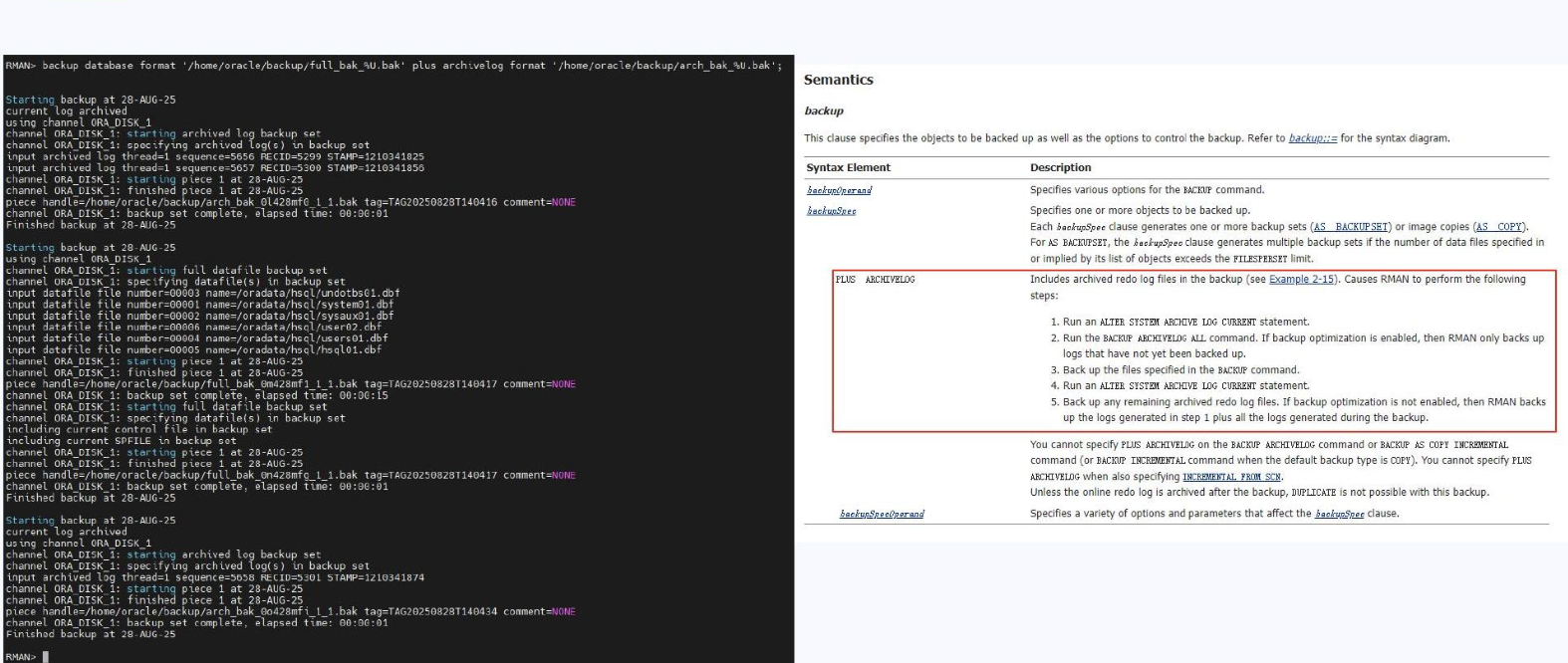
图3:归档备份示例
2. 归档删除
随着归档日志数量增加,存储管理成为必须关注的问题。归档日志的删除方式主要有两种:
DELETE INPUT—— 备份完成后删除归档日志,保证备份和删除同步进行;DELETE NOPROMPT ARCHIVELOG—— 直接删除归档日志,无需确认,适用于空间紧张场景。
合理管理归档日志的删除,可以在保证数据安全的前提下,避免存储压力过大。
3. 日志切换触发机制
日志切换是归档管理和 Redo 循环使用的重要环节,它决定了日志文件的使用效率和数据恢复能力。常见的触发方式包括:
- 日志文件写满;
- 手动执行 ALTER SYSTEM SWITCH LOGFILE;
- 手动归档当前日志;
- RMAN 执行归档备份;
- 某些恢复操作。
需要注意的是:
- 增量检查点 通常发生在 Online Redo 日志写入过程中,只推进部分数据文件的检查点位置;
- 全量检查点 由手动触发,或特定恢复操作执行,会将所有脏块刷入磁盘;
- 数据库 crash recovery 会触发日志切换,而 startup immediate 并不会。
通过合理的归档备份、删除与日志切换策略,Oracle 数据库能够在异常情况下高效、可靠地保证数据完整性,并为灾备与恢复提供坚实保障。
点击此处查看完整技术文章:
《what operation cause the Oracle db redo switch logfile》
常见问题解答
在 Oracle 数据库管理中,归档日志的使用和数据库恢复是运维中最关键的环节之一。下面从几个典型问题出发,系统性解析归档与恢复机制。
1. 为什么有些归档不在控制文件中
归档日志是否出现在控制文件中,取决于是否被正确登记(registered)。常见情况包括:
- 通过 RMAN 备份并加上 DELETE INPUT 后,控制文件中可能已无对应记录;
- 在操作系统层手动删除归档日志,但未同步更新控制文件,会出现“缺档”现象;
- 归档日志被移动到 FRA(Flash Recovery Area)或其他路径,但未重新 catalog。
提示:如果控制文件缺失归档记录,可使用 CATALOG START WITH 命令重新登记,确保 RMAN 可见。
图4: 为什么有些归档不在控制文件中
2. 日志切换是全量还是增量检查点?
- 正常日志切换:触发增量检查点(Incremental Checkpoint);
- 手工
ALTER SYSTEM CHECKPOINT:触发完全检查点(Full Checkpoint)。
日志切换的主要目的是保证 redo 循环使用和归档触发,而非执行全量检查点。如果误解日志切换为全量 Checkpoint,可能会影响恢复策略的设计。
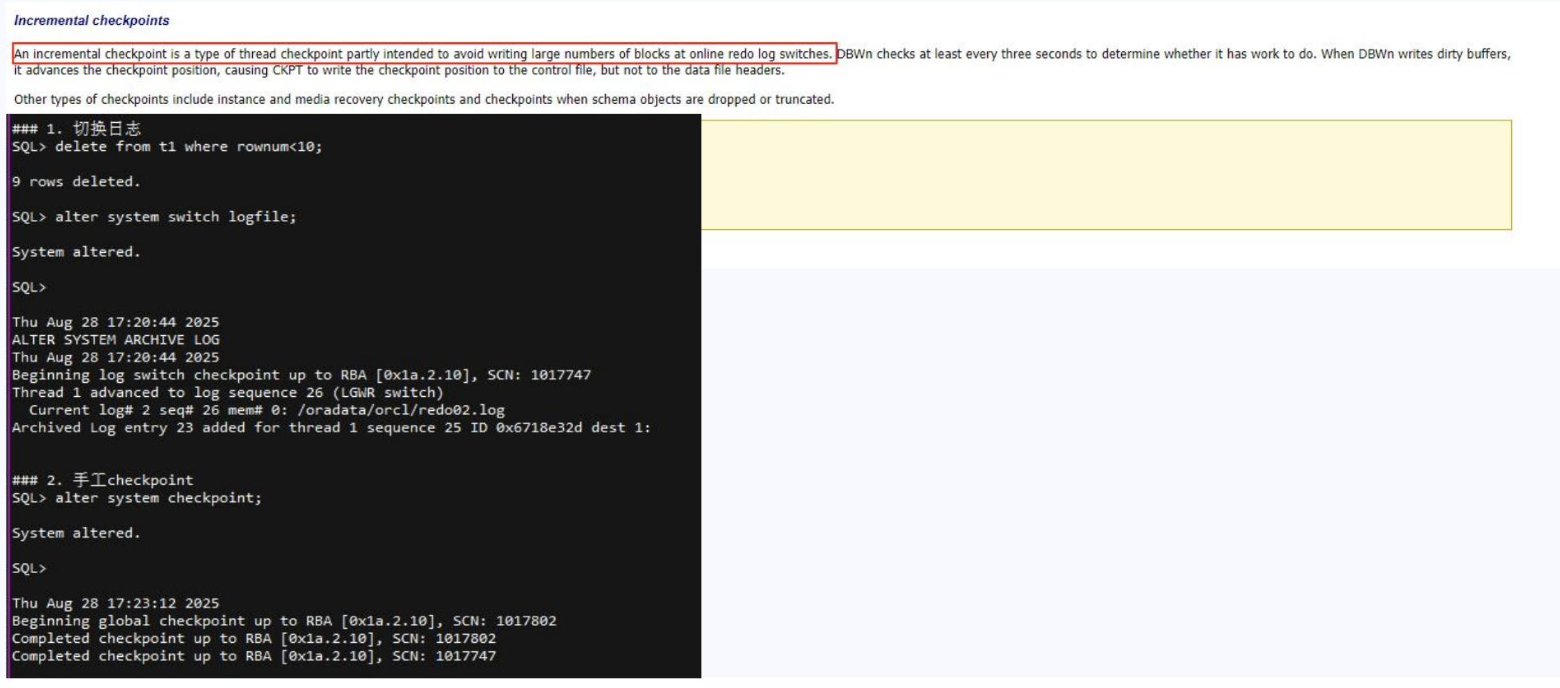
图5: 日志切换是全量还是增量检查点
3. 缺归档时数据文件为什么无法 Online?
- 数据文件损坏,需要
RECOVER DATAFILE时,如果缺少对应归档日志,恢复无法完成,数据文件无法 online。 - 归档日志是恢复必备条件,缺失只能依赖备份集或不完全恢复(Point-in-Time Recovery)。
📌 示意:
[归档日志缺失] → [数据文件恢复失败] → [无法 Online]
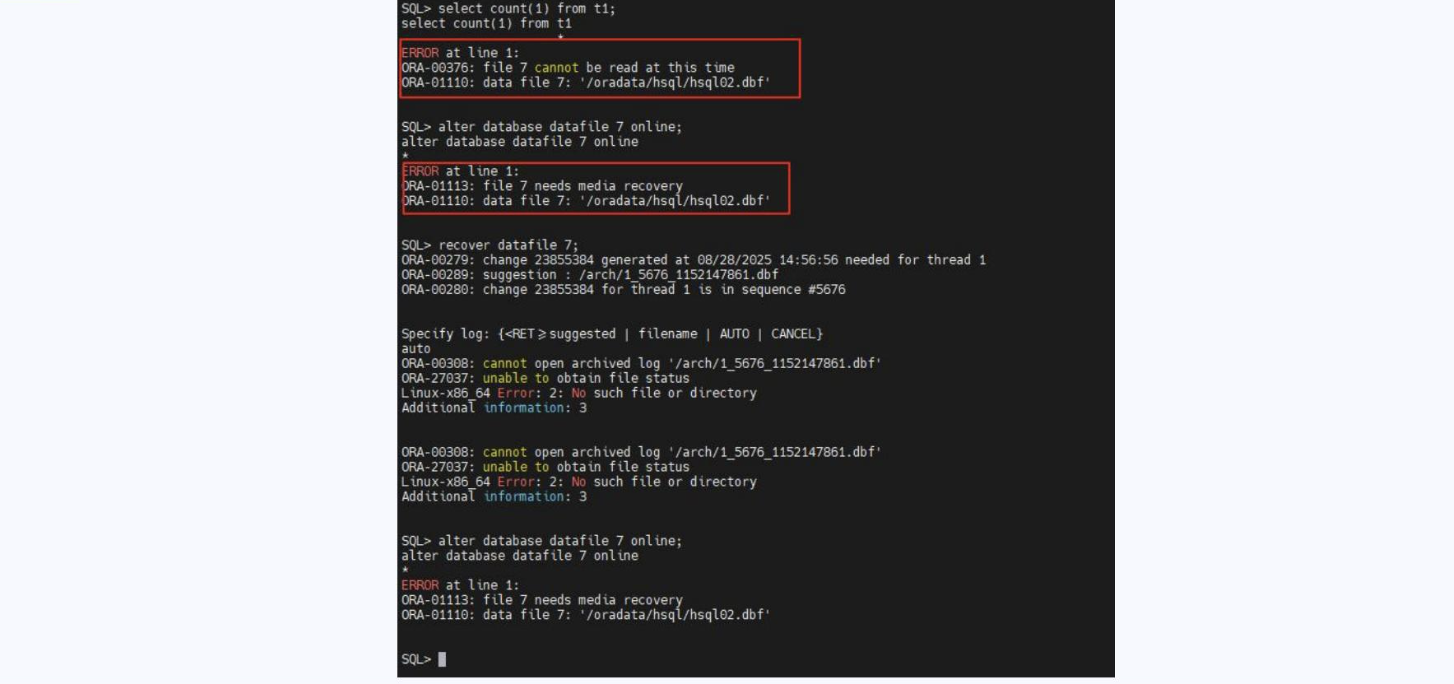
图6: 缺归档时数据文件为什么无法 Online
4. 什么时候需要 Instance Recovery / Media Recovery?
当数据库数据文件损坏,需要执行 RECOVER DATAFILE 时,如果缺少对应区间的归档日志,恢复操作将无法完成,导致数据文件无法切换为 Online 状态。
归档日志是恢复的必备条件,缺失时只能依赖:
- 备份集(Backup Set);
- 不完全恢复(Point-in-Time Recovery)。
📌 示意流程:
[归档日志缺失] → [数据文件恢复失败] → [无法 Online]
此外本次还分享了 Consistent Shutdown、Instance Recovery 和 Media Recovery 的不同解决方案,帮助 DBA 系统性理解数据库在不同关闭或故障场景下的恢复策略,点击>>技术文档查看完整内容。
Redo 日志不仅是 Oracle 数据库事务安全的基石,也是灾难恢复、主备同步和历史追溯的核心机制。通过深入理解其内部结构、生成流程以及归档管理策略,DBA 能够更科学地制定恢复方案,保障数据库的高可用性和数据完整性。
正如一句技术哲言所说:“Redo 日志记录的不只是数据变化,更是数据库在面对意外时的生命线。” 我今天分享的内容就到这里,谢谢大家!
