




记录一次CPU使用率过高故障的分析与处理

一、问题现象
下午接到系统运行卡顿的反馈后,首先对主机性能进行了检查,发现CPU使用率异常偏高,系统整体负载压力巨大(环境是CentOS7.9+Oracle11.2.0.4单机)。具体情况如下图所示:
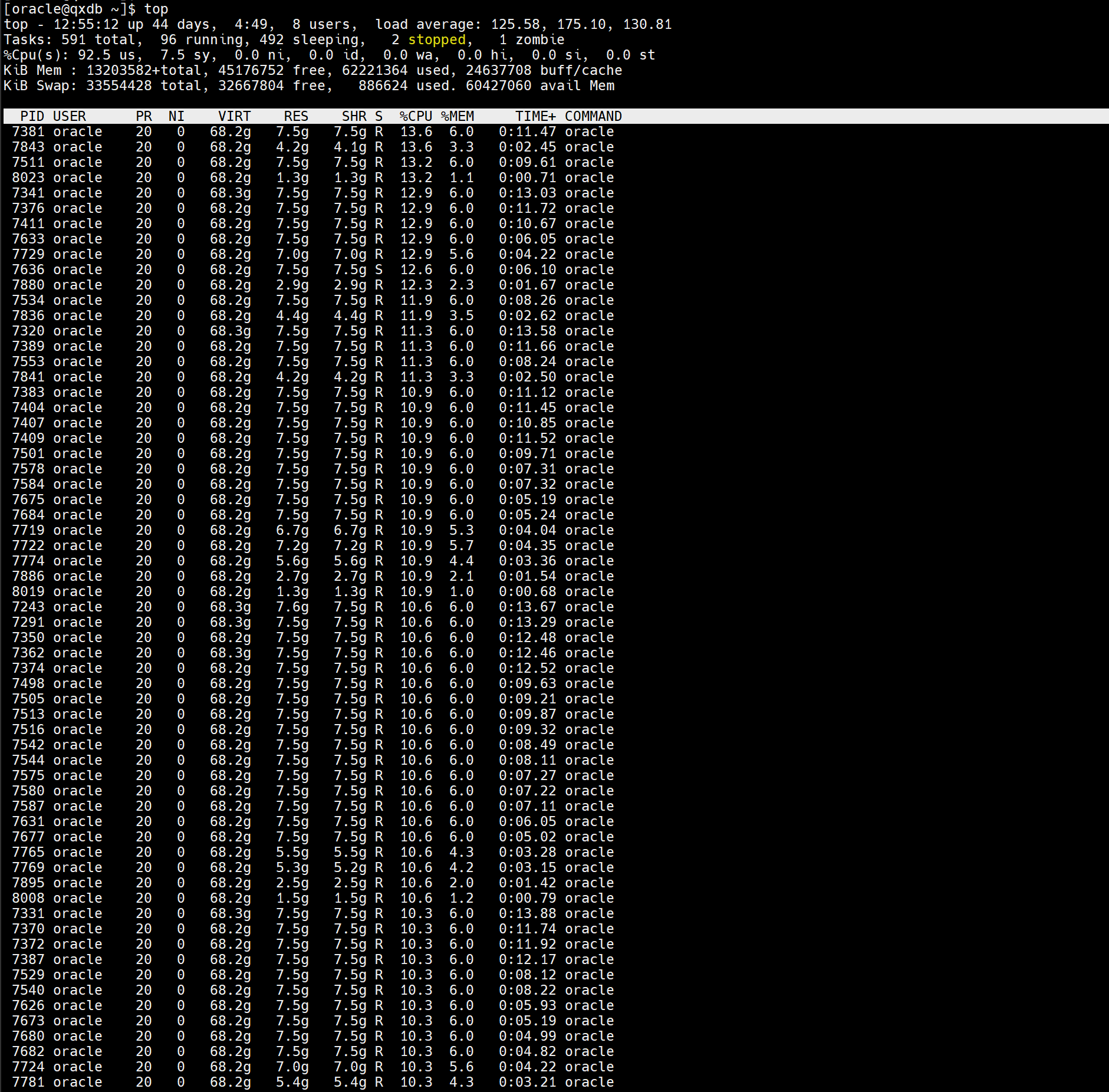
二、初步分析
通过sqlplus连接数据库后,查看当前会话等待事件,发现存在大量的resmgr:cpu quantum等待:
[oracle@qxdb ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Mon Sep 1 12:49:57 2025
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> select event,count(*) from v$session group by event;
EVENT COUNT(*)
---------------------------------------------------------------- ----------
SQL*Net message from client 51
resmgr:cpu quantum 398
Streams AQ: waiting for messages in the queue 2
read by other session 13
rdbms ipc message 16
smon timer 1
pmon timer 1
Streams AQ: qmn slave idle wait 1
latch free 2
SQL*Net message to client 1
Streams AQ: waiting for time management or cleanup tasks 1
EVENT COUNT(*)
---------------------------------------------------------------- ----------
Streams AQ: qmn coordinator idle wait 1
VKTM Logical Idle Wait 1
DIAG idle wait 2
VKRM Idle 1
15 rows selected.
SQL>
resmgr:cpu quantum等待事件表明会话正在等待Oracle资源管理器(Resource Manager)分配CPU资源。
参考Oracle官方文档(MOS)的相关说明:
- High “Resmgr:Cpu Quantum” Wait Events In 11g Even When Resource Manager Is Disabled [ID 949033.1]
- 11g: Scheduler Maintenance Tasks or Autotasks [ID 756734.1]
- Large Waits With The Wait Event “Resmgr:Cpu Quantum” [ID 806893.1]
三、初步处理
根据上述分析,尝试调整资源管理计划参数,并关闭自动任务以减少资源争用:
-- 检查当前资源管理计划
SQL> show parameter resource_manager_plan
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
resource_manager_plan string SCHEDULER[0x3009]:DEFAULT_MAIN
-- 清空资源管理计划 TENANCE_PLAN
SQL> alter system set resource_manager_plan='';
System altered.
-- 清除维护窗口的资源计划
SQL> execute dbms_scheduler.set_attribute('WEEKNIGHT_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('WEEKEND_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('MONDAY_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('TUESDAY_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('WEDNESDAY_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('THURSDAY_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('FRIDAY_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('SATURDAY_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
SQL> execute dbms_scheduler.set_attribute('SUNDAY_WINDOW','RESOURCE_PLAN','');
PL/SQL procedure successfully completed.
-- 禁用自动空间顾问和SQL调优顾问任务
SQL> BEGIN
DBMS_AUTO_TASK_ADMIN.DISABLE(
client_name => 'auto space advisor',
operation => NULL,
window_name => NULL);
END;
/ 2 3 4 5 6 7
PL/SQL procedure successfully completed.
SQL> BEGIN
DBMS_AUTO_TASK_ADMIN.DISABLE(
client_name => 'sql tuning advisor',
operation => NULL,
window_name => NULL);
END;
/ 2 3 4 5 6 7
PL/SQL procedure successfully completed.
SQL> select client_name,status from dba_autotask_client;
CLIENT_NAME STATUS
---------------------------------------------------------------- --------
auto optimizer stats collection ENABLED
auto space advisor DISABLED
sql tuning advisor DISABLED
-- 重启数据库使配置生效
SQL> shut immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 7.2688E+10 bytes
Fixed Size 2260728 bytes
Variable Size 6979322120 bytes
Database Buffers 6.5498E+10 bytes
Redo Buffers 208642048 bytes
Database mounted.
Database opened.
SQL> show parameter resource_manager_plan
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
resource_manager_plan string
SQL>
然而,重启后CPU使用率仍然居高不下:
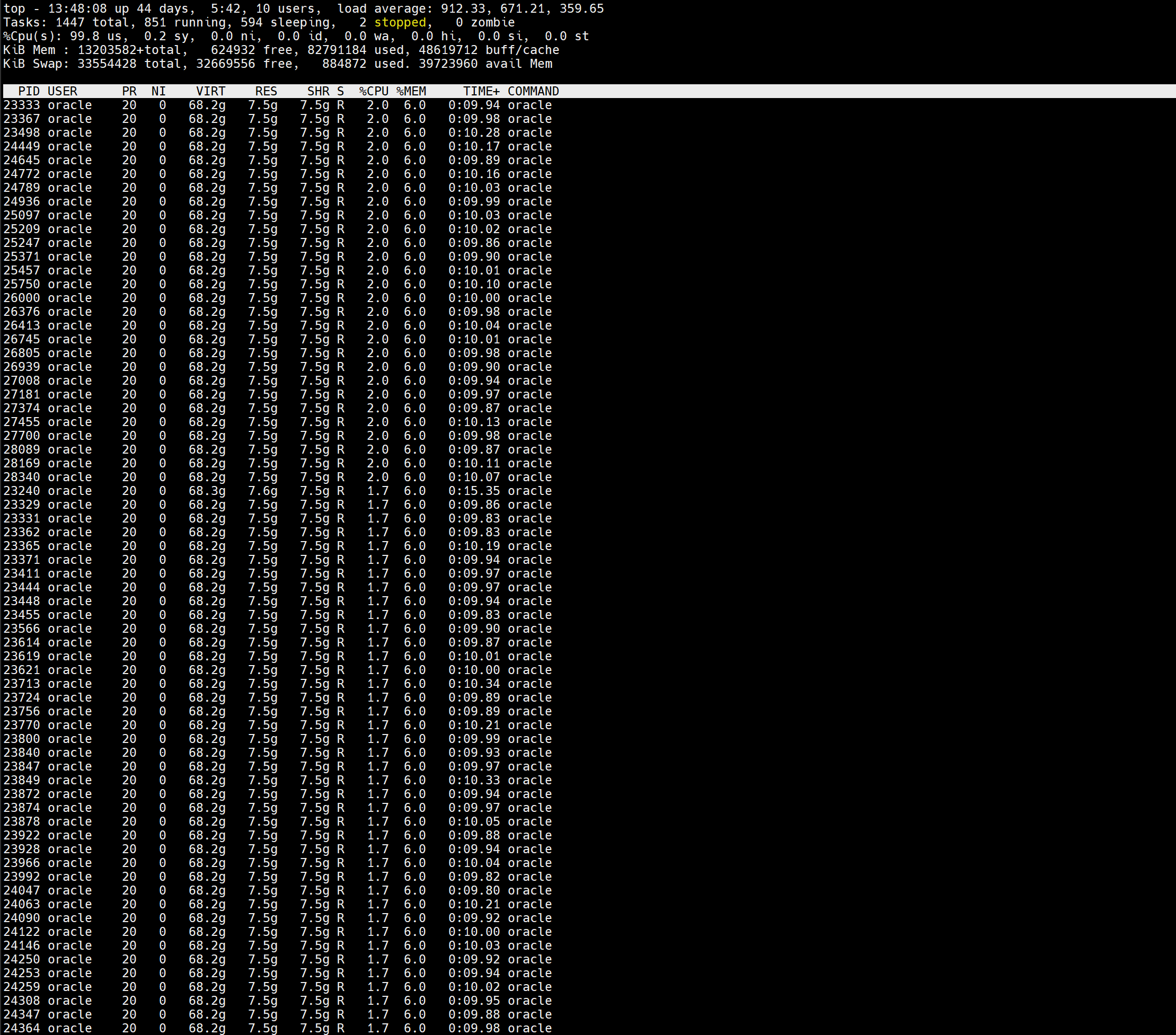
四、深入分析
再次检查会话等待事件,发现等待类型已发生变化,出现了大量的latch free和latch: cache buffers chains等待:
SQL> select event,count(*) from v$session group by event;
EVENT COUNT(*)
---------------------------------------------------------------- ----------
SQL*Net message from client 41
Streams AQ: waiting for messages in the queue 5
read by other session 3
null event 2
rdbms ipc message 15
latch: cache buffers chains 30
db file sequential read 7
pmon timer 1
smon timer 1
job scheduler coordinator slave wait 1
latch free 92
EVENT COUNT(*)
---------------------------------------------------------------- ----------
Streams AQ: qmn slave idle wait 1
SQL*Net message to client 1
Disk file operations I/O 1
Streams AQ: qmn coordinator idle wait 1
VKTM Logical Idle Wait 1
Streams AQ: waiting for time management or cleanup tasks 1
DIAG idle wait 2
18 rows selected.
SQL>
通过关联SQL_ID定位到具体问题语句:
SQL> select event,sql_id,count(1) from v$session where event='latch free' group by event,sql_id
2 ;
EVENT SQL_ID
---------------------------------------------------------------- -------------
COUNT(1)
----------
latch free d4guxxn00hu01
1
latch free gm684ycvk15qd
1
latch free 0z45dukpd4nan
144
EVENT SQL_ID
---------------------------------------------------------------- -------------
COUNT(1)
----------
latch free gptqjj4hx10rm
1
SQL> select sql_text from gv$sql where sql_id='0z45dukpd4nan';
SQL_TEXT
--------------------------------------------------------------------------------
SELECT COUNT(1) FROM SCM_INOUT_LOT_HISTORY_EXT WHERE STATDATE = TRUNC(LAST_DAY(A
DD_MONTHS(SYSDATE,-1))) AND COMPID = :B2 AND OWNERID = :B1
SQL>
同时发现数据库中存在大量作业运行:
SQL> select count(1) from dba_jobs;
COUNT(1)
----------
6201
SQL> select count(1) from dba_jobs_runnings;
COUNT(1)
----------
16
SQL>
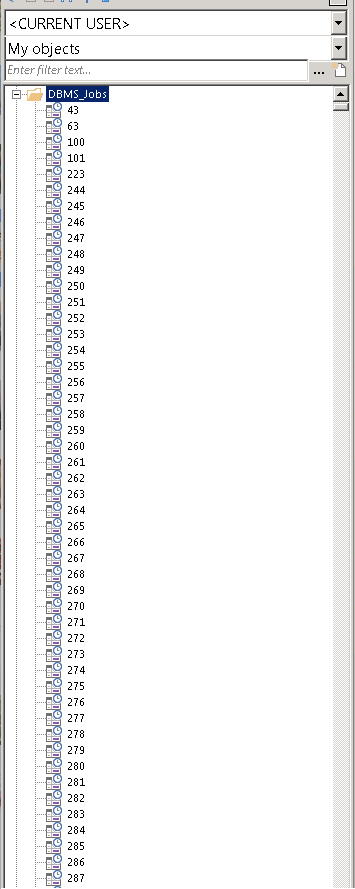
分析问题SQL的执行计划,发现对SCM_INOUT_LOT_HISTORY_EXT表(约2亿条记录)进行了全表扫描:
SQL> conn MED_GKCS
Enter password:
Connected.
SQL> set autotrace trace exp
SQL> SELECT COUNT(1) FROM SCM_INOUT_LOT_HISTORY_EXT WHERE STATDATE = TRUNC(LAST_DAY(ADD_MONTHS(SYSDATE,-1))) AND COMPID = 2 AND OWNERID = 1;
Execution Plan
----------------------------------------------------------
Plan hash value: 343819289
--------------------------------------------------------------------------------
----------------
| Id | Operation | Name | Rows | Bytes | Cost (%
CPU)| Time |
--------------------------------------------------------------------------------
----------------
| 0 | SELECT STATEMENT | | 1 | 14 | 10820
(1)| 00:02:10 |
| 1 | SORT AGGREGATE | | 1 | 14 |
| |
|* 2 | TABLE ACCESS FULL| SCM_INOUT_LOT_HISTORY_EXT | 1 | 14 | 10820
(1)| 00:02:10 |
--------------------------------------------------------------------------------
----------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OWNERID"=1 AND "STATDATE"=TRUNC(LAST_DAY(ADD_MONTHS(SYSDATE@!,-1)
)) AND
"COMPID"=2)
SQL> set autot off
SQL> SELECT COUNT(1) FROM SCM_INOUT_LOT_HISTORY_EXT;
COUNT(1)
----------
195323892
SQL>
五、根本原因与最终处理
综合以上分析,确定故障的根本原因:
-
开发人员误操作导致作业异常重复创建,产生大量并发进程
-
关键SQL语句缺乏合适索引,导致全表扫描
-
大量并发全表扫描操作引发缓冲链闩锁争用
采取以下处理措施:
1.紧急重启数据库并停止监听:
SQL> conn / as sysdba
Connected.
SQL> shut immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> exit
Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
[oracle@qxdb ~]$ lsnrctl stop
LSNRCTL for Linux: Version 11.2.0.4.0 - Production on 01-SEP-2025 13:30:31
Copyright (c) 1991, 2013, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.16.168.135)(PORT=1521)))
The command completed successfully
[oracle@qxdb ~]$
2.创建缺失索引并更新统计信息:
[oracle@qxdb ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Mon Sep 1 13:30:36 2025
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup
ORACLE instance started.
Total System Global Area 7.2688E+10 bytes
Fixed Size 2260728 bytes
Variable Size 6979322120 bytes
Database Buffers 6.5498E+10 bytes
Redo Buffers 208642048 bytes
Database mounted.
Database opened.
SQL> conn MED_GKCS
Enter password:
Connected.
SQL> create index idx_scm_inout_lot_hist_ext_st on SCM_INOUT_LOT_HISTORY_EXT(STATDATE);
Index created.
SQL> exec dbms_stats.gather_table_stats('MED_GKCS','SCM_INOUT_LOT_HISTORY_EXT',cascade=>true);
PL/SQL procedure successfully completed.
SQL>
3.验证执行计划已改用索引:
SQL> set autotrace trace exp
SQL> SELECT COUNT(1) FROM SCM_INOUT_LOT_HISTORY_EXT WHERE STATDATE = TRUNC(LAST_DAY(ADD_MONTHS(SYSDATE,-1))) AND COMPID = 2 AND OWNERID = 1;
Execution Plan
----------------------------------------------------------
Plan hash value: 651601031
--------------------------------------------------------------------------------
------------------------------
| Id | Operation | Name | Rows | B
ytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
------------------------------
| 0 | SELECT STATEMENT | | 1 |
14 | 7753 (1)| 00:01:34 |
| 1 | SORT AGGREGATE | | 1 |
14 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID| SCM_INOUT_LOT_HISTORY_EXT | 1 |
14 | 7753 (1)| 00:01:34 |
|* 3 | INDEX RANGE SCAN | IDX_SCM_INOUT_LOT_HIST_EXT_ST | 542K|
| 1467 (1)| 00:00:18 |
--------------------------------------------------------------------------------
------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OWNERID"=1 AND "COMPID"=2)
3 - access("STATDATE"=TRUNC(LAST_DAY(ADD_MONTHS(SYSDATE@!,-1))))
SQL> exit
Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
[oracle@qxdb ~]$
4.重启监听并清理异常作业:
[oracle@qxdb ~]$ lsnrctl start
LSNRCTL for Linux: Version 11.2.0.4.0 - Production on 01-SEP-2025 13:59:38
Copyright (c) 1991, 2013, Oracle. All rights reserved.
Starting /app/oracle/product/11.2.0.4/db_1/bin/tnslsnr: please wait...
TNSLSNR for Linux: Version 11.2.0.4.0 - Production
System parameter file is /app/oracle/product/11.2.0.4/db_1/network/admin/listener.ora
Log messages written to /app/oracle/diag/tnslsnr/qxdb/listener/alert/log.xml
Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.16.168.135)(PORT=1521)))
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.16.168.135)(PORT=1521)))
STATUS of the LISTENER
------------------------
Alias LISTENER
Version TNSLSNR for Linux: Version 11.2.0.4.0 - Production
Start Date 01-SEP-2025 13:59:38
Uptime 0 days 0 hr. 0 min. 0 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File /app/oracle/product/11.2.0.4/db_1/network/admin/listener.ora
Listener Log File /app/oracle/diag/tnslsnr/qxdb/listener/alert/log.xml
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.16.168.135)(PORT=1521)))
Services Summary...
Service "csqxcs" has 1 instance(s).
Instance "csqxcs", status UNKNOWN, has 1 handler(s) for this service...
The command completed successfully
[oracle@qxdb ~]$
-- 联系开发人员确认并清理异常作业
[oracle@qxdb ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Mon Sep 1 14:00:01 2025
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> select count(1) from dba_jobs_running;
COUNT(1)
----------
0
SQL> select count(1) from dba_jobs;
COUNT(1)
----------
16
SQL>
六、处理结果
系统恢复正常运行,CPU使用率降至正常水平:
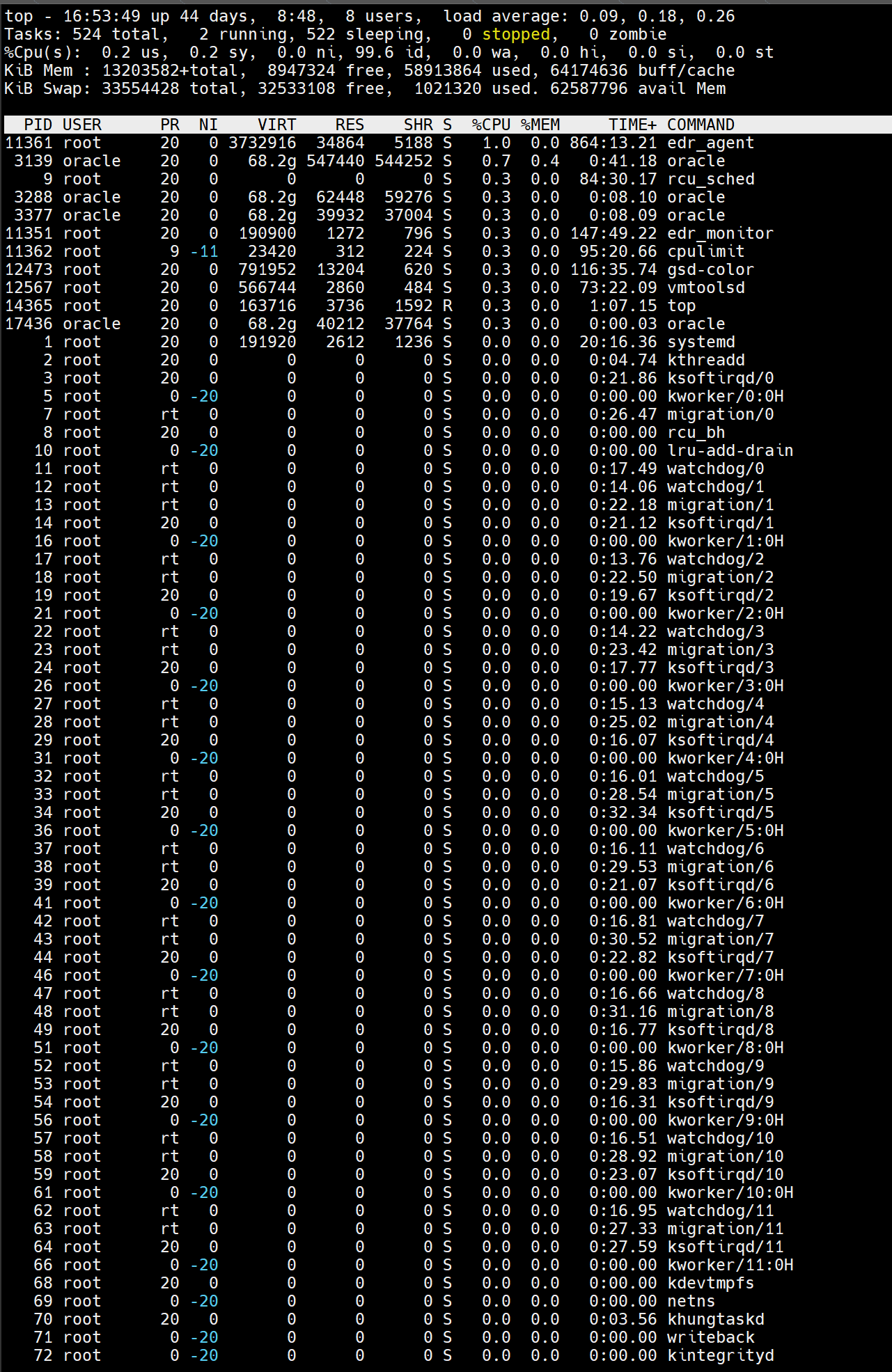
七、经验总结
本次CPU使用率过高故障是由多方面因素共同导致的:
-
直接原因:开发误操作导致作业异常重复创建,产生大量并发进程
-
性能瓶颈:关键SQL缺乏适当索引,导致全表扫描和缓冲链闩锁争用
-
加剧因素:资源管理器配置可能放大了资源争用问题
处理经验:
- 系统性能问题需要综合多方面因素进行分析,不能仅关注表面现象
- 等待事件分析是定位数据库性能问题的重要方法
- 对于大规模数据表,适当的索引设计至关重要
- 建立健全的监控体系,能够及时发现作业异常等异常情况
- 重要的配置变更和作业调度应建立严格的审核机制
以上就是本次故障处理全过程,分享出来希望能给各位小伙伴一些帮助☺️。
最后修改时间:2025-09-02 10:11:38
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
