





堆内元组是关系型数据库的基石,影响着数据库的核心能力、性能和可靠性。海量数据库Vastbase实现的堆内元组特性,可高效地利用索引与表的数据页,减少清理过程,提升数据库性能。本期海量智库将为大家介绍堆内元组以及Vastbase的实现原理。
堆内元组指直接存储在数据库表的数据页(也称堆页)中的元组的原始版本。
堆:指数据结构中的无序数据集合。表数据被分割成固定大小的页,这些页的集合构成了堆文件。
页:指磁盘和内存之间传输数据的基本单位,每个页里面存储着多行元组(行记录)。
元组:指一行数据,包括各个列的值以及系统字段(如xmin、xmax、ctid等)。
因此,堆内元组是最直接、最原始地存放在数据页中的一行数据。如果没有堆内元组的更新,将会出现以下情况:
假设表tbl有两个列id和data,其中列id是表tbl的主键。
testdb=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | text | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
假设表tbl有1000条元组,最后一个元组的id是1000,存储在第5个数据页中,最后一条元组被相应的索引元组所引用,索引元组的key是1000,并且ctid是(5, 1),如下图(a)所示:
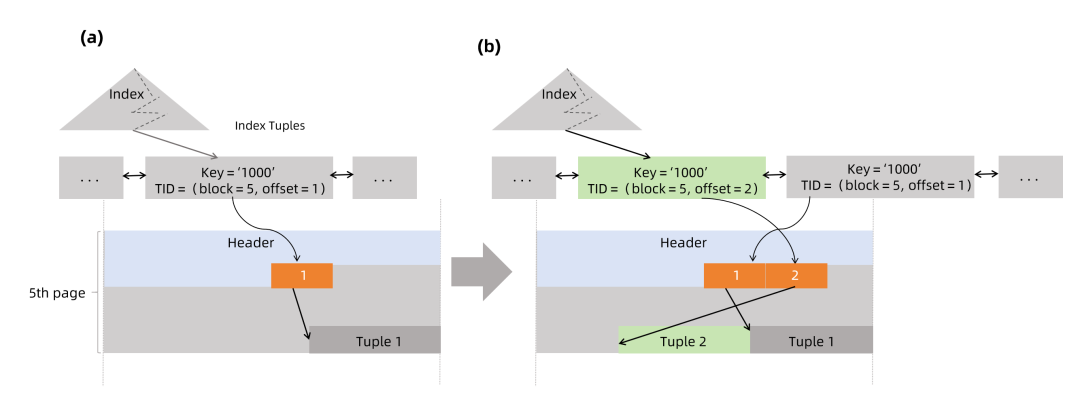
没有堆内元组特性时,最后一个元组的更新将如以下情况:
testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000;
在该场景中,Vastbase不仅要插入一条新的表元组,还需要在索引页中插入新的索引元组,如上图(b)所示。索引元组的插入消耗了索引页的空间,插入和清理将带来更大成本,堆内元组则可降低索引元组的影响。
当使用堆内元组特性更新元组时,如果被更新的元组存储在老元组的页面中,Vastbase就不会再插入相应的索引元组,而是分别设置新元组的HEAP_ONLY_TUPLE标记位,以及老元组的HEAP_HOT_UPDATED标记位,两个标记位都保存在元组t_informask2字段中。如下面两个图所示:
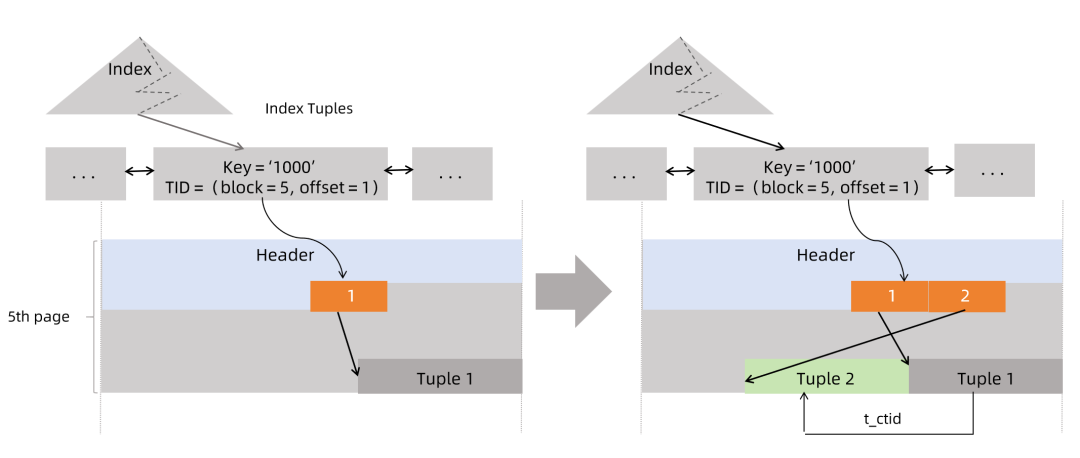

上面例子中Tuple_1和Tuple_2分别被设置成HEAP_HOT_UPDATED和HEAP_ONLY_TUPLE。另外,在修剪和碎片整理处理过程中,都会使用HEAP_HOT_UPDATED和HEAP_ONLY_TUPLE标记位。
接下来,当基于堆内元组进行更新元组后,Vastbase在索引扫描中,访问被堆内元组更新的元组时,将如下图(a)所示:
1、找到指向目标数据元组的索引元组;
2、按所获索引元组指向的位置访问元组指针数组,找到元组指针1;
3、读取Tuple_1;
4、经由Tuple_1的t_ctid字段,读取Tuple_2。
在这种情况下,Vastbase会读取Tuple_1和Tuple_2两条元组,并通过并发控制机制来判断哪条元组可见;如果数据页中的死元组已经被清理,如在下图(a)中,Tuple_1由于是死元组而被清理,则无法通过索引访问Tuple_2。
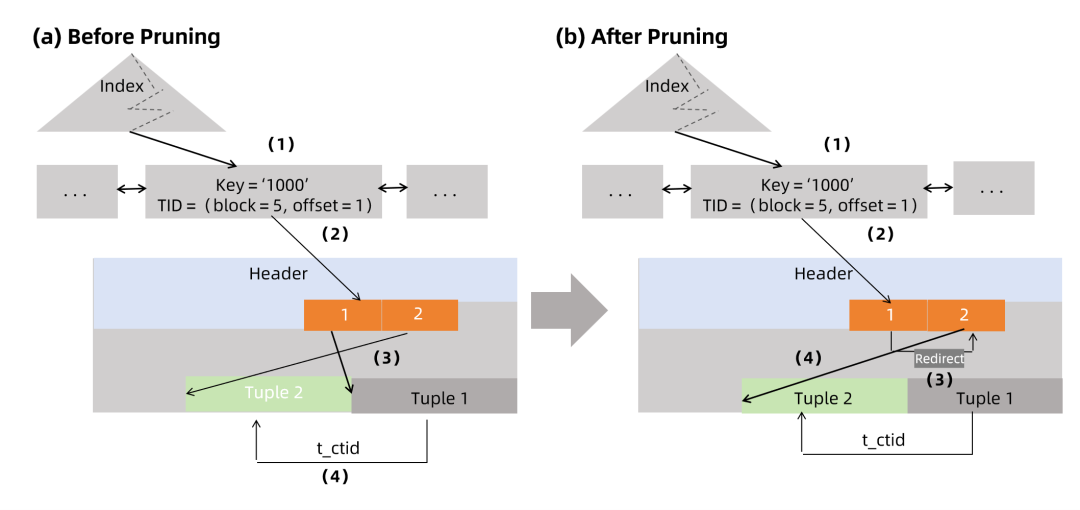
为了解决这个问题,Vastbase会进行元组指针重定向,将指向老元组的元组指针重新指向新元组的指针,这一过程称为修剪 。
Vastbase在修剪之后访问更新的元组,如上图(b)所示:
1、找到索引元组;
2、通过索引元组,找到元组指针1;
3、通过重定向的元组指针1,找到元组指针2;
4、通过元组指针2,读取Tuple_2。
剪枝任何时候都有可能会发生。Vastbase执行剪枝时,会挑选合适的时机清理死元组,这种操作称为碎片整理,如下图所示:
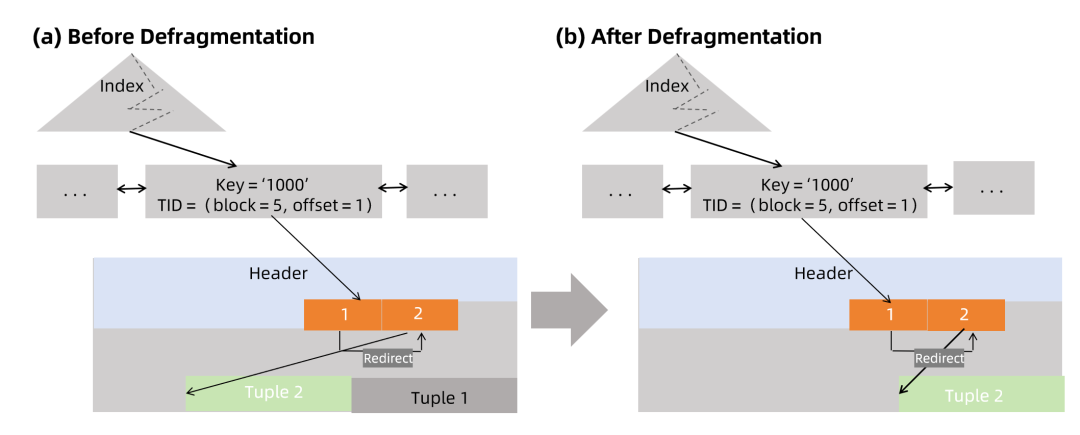
碎片整理的工作并不涉及到索引元组的移除,因此碎片整理比起常规的清理成本更低。堆内元组特性降低了索引和表的空间消耗,以及清理过程需要处理的元组数量,因此堆内元组对于性能提高有良好的促进作用。
元组是不可变的有序集合,一旦创建就不能修改其内容。因此,元组适用于数据固定、不需要修改的场景,如表示常量、函数返回多个值等,不适用于需要频繁修改数据、动态调整大小、排序或修改元素顺序、与其他可变数据结构交互的场景。
例如以下不可用场景:
1、当更新的元组在其他的页面时,即和老元组不在同一个数据页中时,指向该元组的索引元组也会被添加至索引页中,如下图(a)所示。
2、当索引的键被更新时,会在索引页中插入一条新的索引元组,如下图(b)所示。
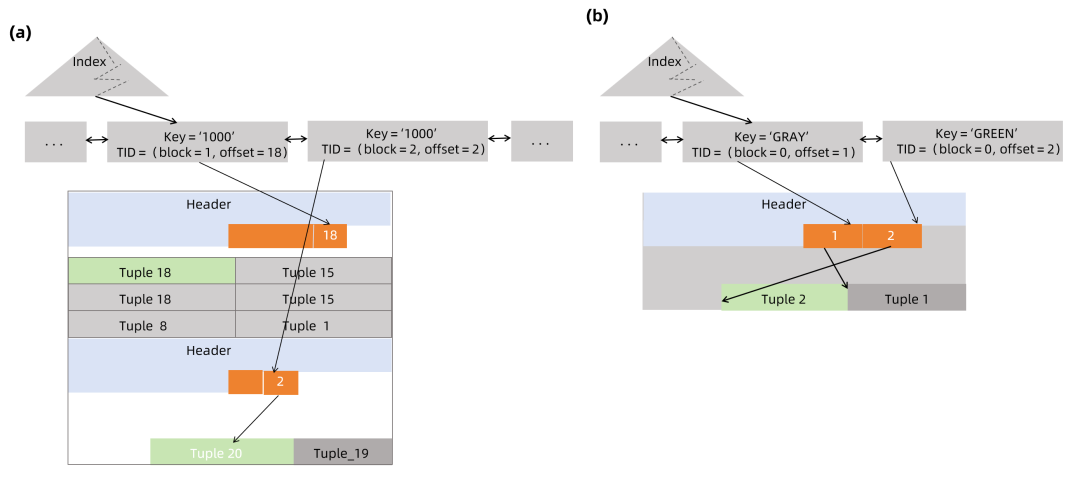
海量数据库Vastbase实现的堆内元组特性,可以将新元组放置在老元组所处的同一个数据页中,通过减少索引维护成本,提升数据库性能,减少空间浪费和性能损耗。
• END •
往期推荐




关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司近二十年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。


