





在当今数字化浪潮中,数据的实时处理能力成为企业竞争的关键。随着软硬件结合技术的快速发展,数据库云原生能力的逐步成熟,以及DuckDB等现代嵌入式分析型数据库的迅速崛起,数据库HTAP理念和实践走向一个全新转折点,即:TP 和 AP 不再是割裂的应用场景,而是互相渗透,已经不再是技术选型上的取舍,而变成日常的调优手段。
本文介绍阿里云瑶池旗下的云原生数据库PolarDB PostgreSQL版(以下简称PolarDB-PG)HTAP建设思路,涉及PolarDB IMCI列存索引(In-Memory Column Index,简称IMCI)的适用场景、技术原理、功能形态、核心优势以及深度融合DuckDB的技术路线,并结合地平线自驾标签数据分析挖掘场景,分析IMCI在真实生产业务中的价值体现。

PolarDB-PG的HTAP实践思路
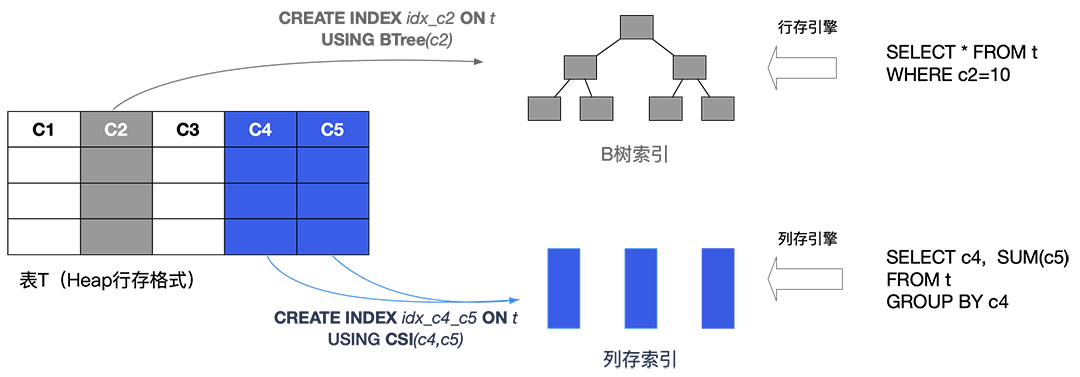
PolarDB-PG IMCI的使用场景与优势
PolarDB-PG IMCI当前支持两种开启方式,一种是添加独立的列存只读节点,一种是在现有的节点中直接使用预安装的IMCI插件。列存只读节点能够充分利用所在节点内存资源,同时使TP(事务)与AP(分析)业务在不同节点上相互隔离,互不影响。
HTAP混合负载:实时交易与复杂分析并行,无需额外系统支撑,如:实时交易统计+报表生成。 复杂查询加速:慢SQL治理场景,全表统计、多列分组/排序,结合多表JOIN、多条件过滤等。 ETL加速计算:基于IMCI强大而灵活的计算能力,直接在PolarDB中完成数据清洗、转换与聚合。 数据仓库场景:基于列存表实现AP分析、大宽表无固定索引查询/分析加速、以及多模数据的查询加速。
查询性能跃升:相比于行存引擎,基于列存引擎的复杂分析查询性能可以提升60-100X以上。 低成本存储:仅需为查询涉及列创建索引,列存索引空间占用仅为行存的10%-50%;无论行存、列存,扩展RO节点仅共享存储一份数据。 PG生态兼容:支持原生PostgreSQL语法(CREATE/DROP INDEX),无需修改查询SQL,仅需要创建索引后,即可加速。 行列实时转换:行存数据毫秒/秒级生成列存索引,自动维护一致性,无需手动刷新。 智能查询路由:Cost + SQL耗时采样技术,实现动态的行列路由,选择最佳引擎执行。
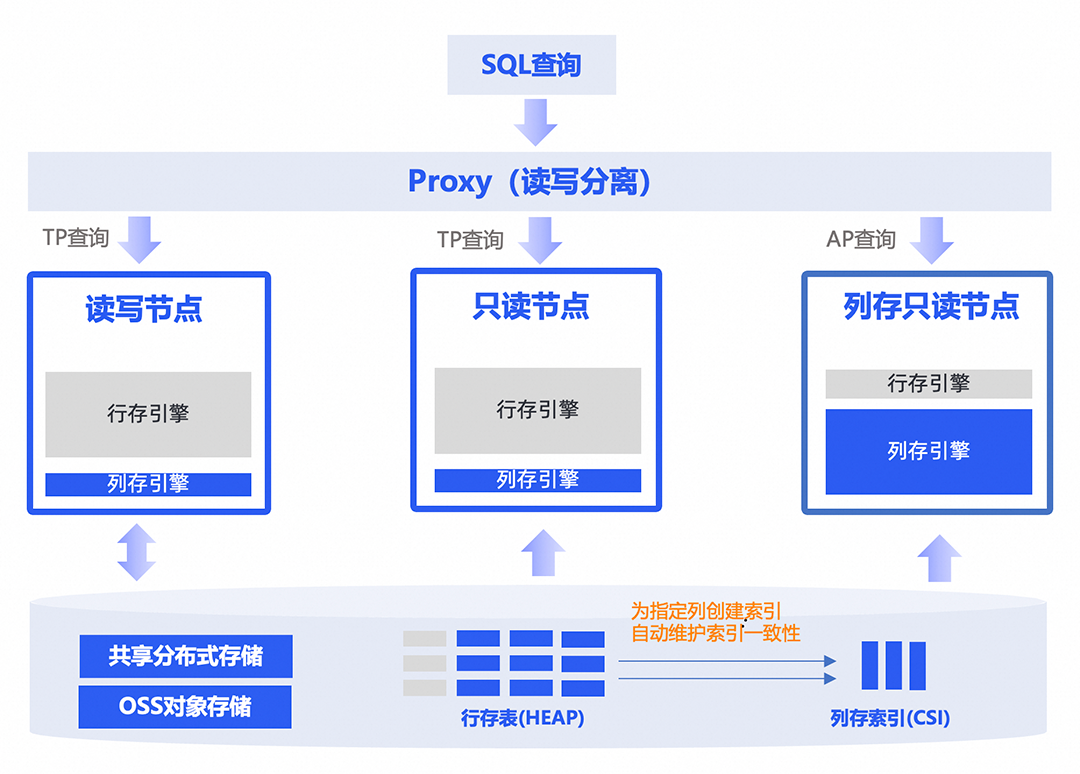
与云原生架构的深度融合
与云原生架构结合
DuckDB本身是嵌入式单机形态,天然并不支持共享存储、存算分离的多机处理模式,PolarDB IMCI通过引入多节点通信会话和协作事务处理机制,实现了与云原生架构的深度融合,无论行存数据还是列存数据,都支持弹性横向扩展,并借助PolarFS分布式文件系统以及OSS分层存储,多个计算节点始终共享一份数据,而不是每加一个计算节点都要借助数据同步额外存储一份数据,可大幅降低存储成本。
多样化列存形态
基础能力适配
改进DuckDB
在地平线自驾核心业务中的应用
客户核心场景诉求
围绕IMCI核心能力实现数据价值落地
结语


点击阅读原文了解 PolarDB-PG IMCI 更多内容

