






大家好,我是陈乔怀古。
资深数据仓库工程师,捣鼓大数据、数据仓库和数据治理,分享路上的“坑”与“果”,用实战经验,助你少走弯路,共同成长。
添加v:cqhg_bigdata,备注数仓/大数据/数据治理/AI大模型,领取对应资料。
后台发送“资料”获取更多大数据资源。
tips:关注公众号发送“用户画像”可下载「如何从0到1构建用户画像系统.pdf」
一、 用户画像体系的核心价值与挑战
1.1 核心价值
精准营销:基于用户兴趣、消费能力、生命周期等标签,实现千人千面的广告投放与活动触达,提升转化率。 个性化推荐:利用用户偏好、行为序列等标签,为内容、商品、服务提供个性化排序与推荐。 风险控制:通过设备、行为、信用等标签识别欺诈、洗钱、刷单等异常行为。 产品优化:洞察用户需求、使用习惯、流失原因,指导产品迭代与用户体验提升。 商业洞察:支持用户分群、市场细分、用户生命周期管理(LTV预测),辅助战略决策。
1.2 亿级规模的核心挑战
数据规模巨大:日增行为数据可达TB/PB级,涉及用户属性、行为日志、交易、内容等多源异构数据。 实时性要求高:部分场景(如实时推荐、反欺诈)需要分钟级甚至秒级的标签更新。 数据质量与一致性:海量数据下,数据清洗、去噪、归一化、ID对齐(跨设备、跨平台)难度剧增。 标签体系复杂性:标签数量可达数万甚至数十万,需科学分类、管理、维护,避免冗余与冲突。 计算与存储成本:大规模特征计算、模型训练、标签存储与查询对资源消耗巨大。 系统稳定性与可扩展性:需支持高并发读写、容错、弹性伸缩,保障业务连续性。 隐私与合规:严格遵守GDPR、CCPA、中国《个人信息保护法》等法规,确保数据安全与用户隐私。
二、 用户画像标签系统设计
标签系统是用户画像的“原子”单元,其设计是整个体系的基石。
2.1 标签分类体系构建清晰、可扩展的标签分类树是管理海量标签的前提。常见分类维度:
按数据来源: 基础属性标签:注册信息(性别、年龄、地域)、设备信息(机型、OS)、会员等级等。通常来自用户资料库。 行为标签:浏览、点击、搜索、收藏、加购、下单、支付、分享、停留时长、访问频次、路径等。来自埋点日志。 交易标签:消费金额、客单价、购买品类、支付方式、优惠券使用、复购率等。来自订单/交易系统。 内容标签:阅读/观看内容主题、作者、标签、情感倾向等。来自内容库与NLP分析。 社交标签:好友关系、互动行为(点赞、评论)、社群归属等。来自社交图谱。 衍生/模型标签:通过算法模型计算得出的标签,如用户价值(RFM)、兴趣偏好(基于协同过滤/深度学习)、流失风险、LTV、信用评分等。 按标签类型: 事实标签 (Factual):直接描述客观事实,如 性别=男
、最近登录时间=2025-08-24
。统计标签 (Statistical):基于一段时间内行为的聚合统计,如 近30天登录次数=15
、历史总消费金额=8000元
。预测标签 (Predictive):基于模型预测的结果,如 流失概率=0.8
、高价值用户=是
。规则标签 (Rule-based):通过业务规则生成,如 活跃用户=近7天登录>=3次
。按更新频率: 静态标签:极少变化,如出生年份、注册渠道。 动态标签:周期性更新(小时/天/周),如最近访问时间、周活跃度。 实时标签:近乎实时更新(秒/分钟级),如当前会话行为、实时兴趣。
2.2 标签定义与管理
唯一标识:每个标签需有全局唯一ID(如 tag_user_gender
)和清晰的中文名。数据类型:明确定义(字符串、整数、浮点数、布尔值、枚举、数组、JSON等)。 取值范围/枚举值:定义合法值域(如性别:男、女、未知)。 更新策略:明确计算逻辑、数据源、更新周期/触发条件、过期时间(TTL)。 血缘关系:记录标签的原始数据源、计算过程、依赖的其他标签或模型。 元数据管理:建立标签元数据仓库(Metadata Repository),包含标签描述、负责人、创建/修改时间、使用场景、敏感等级等。可使用Apache Atlas等工具。
2.3 ID-Mapping(用户身份识别)亿级用户往往通过多个设备(手机、PC、平板)和账号体系(主账号、子账号、游客)访问服务。精准的ID-Mapping是画像准确性的关键。
技术方案: 设备ID:DeviceID (Android ID, IDFA, OAID)、MAC地址(受限)、IP+UserAgent指纹。 账号ID:登录态下的用户唯一标识。 ID关联:通过登录行为、设备共现、行为相似性(如浏览序列、地理位置)等算法,将设备ID与账号ID关联,构建统一的用户视图(Unified User Profile)。常用技术:图数据库(Neo4j)、基于规则的关联、机器学习聚类。 挑战:隐私政策限制(如iOS ATT)、用户清除Cookie/重置ID、多用户共享设备。
三、 用户画像模型构建与落地
模型是生成高级标签(尤其是预测标签)的核心引擎。
3.1 特征工程 (Feature Engineering)
特征来源:整合用户属性、行为序列、交易记录、内容交互、社交关系等多维度原始数据。 特征类型: 基础特征:原始字段或简单变换(如年龄分段、金额取对数)。 统计特征:时间窗口内的聚合(求和、均值、最大值、最小值、方差、计数、占比、增长率)。如 近7天点击次数
、近30天消费金额均值
。序列特征:利用RNN、Transformer等模型处理用户行为序列(如点击流),提取时序模式。 嵌入特征 (Embedding):将高维稀疏类别特征(如商品ID、兴趣标签)映射到低维稠密向量空间(如Word2Vec for items, Graph Embedding for users)。常用模型:Item2Vec, Node2Vec, DeepWalk。 交叉特征:特征组合(如 地域_性别
、用户等级_品类偏好
),可人工构造或使用FM/DeepFM等模型自动学习。特征处理: 缺失值处理:填充(均值、中位数、众数、特定值)、删除、模型预测。 异常值处理:Winsorization(缩尾)、对数变换、基于IQR/3σ规则剔除。 归一化/标准化:Min-Max Scaling, Z-Score Standardization,确保不同量纲特征可比。 离散化:将连续特征分箱(等频、等距、聚类分箱),便于模型处理或生成规则标签。 特征存储:构建特征仓库(Feature Store),统一管理特征定义、计算逻辑、版本、血缘,支持离线与在线特征服务。工具:Feast, Tecton, Hopsworks。
3.2 模型选择与训练
常见模型场景: 协同过滤 (CF):基于用户-物品交互矩阵(User-Based, Item-Based)。 矩阵分解 (MF):SVD, FunkSVD, BiasSVD -> 生成用户/物品隐向量。 深度学习:Wide & Deep, DeepFM, DIN (Deep Interest Network), DIEN (Deep Interest Evolution Network) -> 处理高维稀疏特征和序列行为。 用户分群/聚类:K-Means, DBSCAN, GMM (高斯混合模型) -> 生成如“价格敏感型”、“内容爱好者”等标签。 用户价值评估 (RFM):基于最近购买时间(Recency)、购买频率(Frequency)、购买金额(Monetary)进行分层。 兴趣偏好建模: 流失预测:逻辑回归 (Logistic Regression), GBDT (XGBoost, LightGBM), 随机森林 (Random Forest), LSTM/GRU -> 预测用户流失概率。 LTV预测:回归模型 (线性回归、GBDT)、生存分析 (Survival Analysis)、深度学习模型。 点击率(CTR)/转化率(CVR)预估:广泛使用深度学习模型(如DeepFM, DIN, DCN, MMOE)。 训练流程: 数据准备:从数据仓库(如Hive)或特征仓库获取训练样本(正负样本需合理采样)。 模型选择与调参:根据问题选择模型,使用网格搜索、随机搜索、贝叶斯优化进行超参数调优。 离线训练:在Spark MLlib, Flink ML, TensorFlow, PyTorch等框架上进行大规模分布式训练。 模型评估:使用AUC, Precision, Recall, F1-Score, LogLoss, MAE, RMSE等指标评估模型效果。进行交叉验证。 模型版本管理:记录模型版本、训练数据、参数、评估结果。工具:MLflow, DVC。
3.3 模型部署与服务 (Model Serving)
离线批处理:模型定期(如每日)对全量或增量用户进行预测,结果写入画像数据库。适用于更新频率要求不高的标签(如日更的用户价值分层)。 技术栈:Spark, Flink Batch, Airflow (调度)。 近实时/实时服务: 微批处理 (Micro-batching):每分钟/几分钟处理一批数据(如Flink Streaming)。 在线预测 (Online Inference):模型以API服务形式部署,接收实时请求(如用户ID、上下文)并返回预测结果。用于实时推荐、反欺诈。 技术栈:TensorFlow Serving, TorchServe, Triton Inference Server, 自研服务框架(结合Redis/KV缓存)。 特征服务:确保在线预测时能快速获取用户最新的特征。特征仓库需支持低延迟查询。
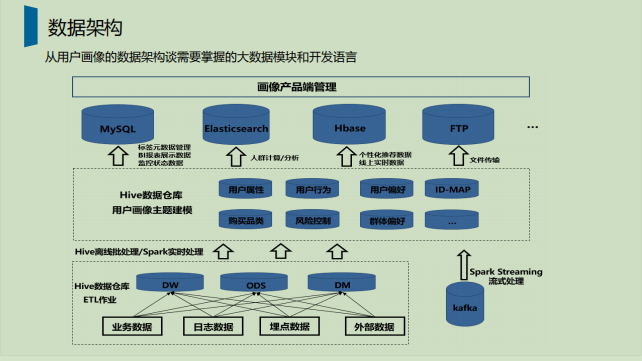
四、 用户画像系统架构
一个健壮的亿级画像系统需分层设计,解耦各组件。
4.1 典型架构分层
+---------------------+
| 应用层 |
| (推荐/广告/风控/BI) |
+----------+----------+
|
| (API/SDK/数据导出)
v
+---------------------+
| 用户画像服务层 |
| - 标签查询API |
| - 用户分群API |
| - 特征服务API |
| - 模型服务API |
+----------+----------+
|
| (读写)
v
+---------------------+
| 用户画像存储层 |
| - 实时标签库: Redis, HBase, Druid |
| - 离线标签库: Hive, ClickHouse, HBase |
| - 统一用户视图: HBase, Graph DB |
+----------+----------+
^
| (写入)
+----------+----------+
| 计算与处理层 |
| - 批处理: Spark, Hive, Flink Batch |
| - 流处理: Flink, Spark Streaming |
| - 模型训练: Spark ML, TensorFlow |
| - 模型服务: TF Serving, 自研 |
+----------+----------+
^
| (数据接入)
+----------+----------+
| 数据源与接入层 |
| - 埋点日志: Flume, Logstash, Kafka |
| - 业务数据库: MySQL, Oracle -> CDC |
| - 第三方数据: API |
| - 数据总线: Kafka, Pulsar |
+---------------------+
4.2 关键组件选型与考量
数据接入: 日志:Flume/Kafka/Filebeat 收集埋点日志到Kafka。 数据库:Debezium等CDC工具捕获MySQL/Oracle变更日志到Kafka。 消息队列:Kafka/Pulsar 是核心,提供高吞吐、低延迟、可回溯的数据管道。 计算引擎: 批处理:Spark (生态成熟,MLlib) 或 Flink (批流一体) 处理T+1的标签计算、模型训练。 流处理:Flink 是首选,处理实时行为流,计算实时标签(如实时兴趣、会话特征)、触发实时模型预测。支持Exactly-Once语义。 存储系统: 实时/热数据:Redis (高性能KV,缓存实时标签、特征)、HBase (海量稀疏数据,支持宽表,适合存储用户所有标签)、Druid (OLAP,支持复杂聚合查询)。 离线/冷数据:Hive (基于HDFS,成本低,适合T+1标签存储、分析)、ClickHouse (高性能OLAP,适合即席查询、BI报表)。 统一用户视图:HBase或图数据库(Neo4j)存储用户及其所有标签、ID-Mapping关系。 查询服务: 提供RESTful API或RPC接口,支持按用户ID查询标签、按标签筛选用户(用户分群)。 需优化查询性能(索引、缓存、分库分表)。 调度系统:Airflow 或 DolphinScheduler 管理复杂的ETL、模型训练、标签计算任务的依赖与调度。
五、 落地实践与关键考量
5.1 分阶段实施
MVP (最小可行产品):聚焦核心业务场景(如新用户欢迎页推荐),构建基础标签(基础属性、核心行为)和简单模型(如热门推荐),快速验证价值。 横向扩展:逐步丰富标签体系(增加交易、内容、社交标签),引入更复杂的模型(如协同过滤、GBDT)。 纵向深化:提升实时性(引入Flink流处理),建设特征仓库、模型仓库,优化模型效果(深度学习),支持更多业务场景。
5.2 数据质量与监控
数据质量监控:监控数据接入延迟、数据量波动、字段缺失率、异常值比例。 标签质量监控:监控标签覆盖率、分布合理性(如预测概率是否过于集中)、与业务指标的相关性。 模型效果监控:持续跟踪线上模型AUC、准确率等指标,设置基线告警。 系统监控:监控计算任务延迟、资源使用率(CPU、内存、IO)、存储水位、API响应时间与错误率。
5.3 性能优化
计算优化:数据倾斜处理(加盐、广播)、算子优化(减少Shuffle)、缓存中间结果。 存储优化:冷热数据分离、数据压缩(Snappy, ZSTD)、列式存储(Parquet, ORC)、索引优化(HBase RowKey设计)。 查询优化:建立倒排索引(支持按标签查用户)、缓存热点查询结果。
5.4 隐私与安全合规
数据脱敏:对敏感信息(手机号、身份证号)进行脱敏处理后再用于分析。 权限控制:严格的RBAC(基于角色的访问控制),确保数据“最小权限”访问。 数据加密:传输加密(TLS)、存储加密。 合规审计:记录数据访问日志,支持用户数据删除/查询请求(满足GDPR等法规)。 匿名化处理:在可能的情况下,使用聚合数据或匿名化ID进行分析。
5.5 组织与协作
跨团队协作:画像团队需与数据平台、算法、业务(产品、运营、市场)紧密合作。 工具化与平台化:开发标签管理平台、模型实验平台、特征平台,降低使用门槛,提升效率。 文档化:完善的文档(架构、接口、标签定义、模型说明)是知识沉淀和团队协作的基础。
六、 总结
搭建亿级用户画像体系是一项复杂的系统工程,远不止是技术选型。它要求:
顶层设计:清晰的标签分类、ID-Mapping策略、分阶段目标。 坚实的数据基础:可靠的数据接入、高质量的数据处理、高效的ID识别。 先进的模型能力:结合业务场景选择合适的模型,持续迭代优化。 健壮的系统架构:基于批流一体(如Flink)、分布式存储(HBase/Redis/Hive)、消息队列(Kafka)构建高可用、可扩展的平台。 严谨的落地实践:关注数据质量、性能、监控、安全合规,并通过平台化工具赋能业务。
成功的用户画像体系,最终应能敏捷地响应业务需求,将海量数据转化为可行动的洞察,驱动业务增长与用户体验提升。这需要技术、数据、业务的深度融合与持续投入。
知识星球少量优惠券,先到先得
据统计,99%的大咖都关注了这个公众号👇
猜你喜欢👇

文章转载自陈乔数据观止,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
