




正则大挑战
最近发现的一个网站,关于正则的练习网站:RegexGolf,大概16题,从Easy到Hard,覆盖的面很广,有评分,也有很多大佬追求极致评分,页面大概长下面这样,让我们现在开始吧。
因为网站改版,现在已经不显示分数了,大致的评分机制如下:
Points = (需求列表匹配数 * 10) - (不允许列表匹配数 * 10) - 表达式字符数
例如:foo
的字符数是3,需求列表匹配数=42,不允许列表匹配数=21,代入上面的公式:得到的分数是分
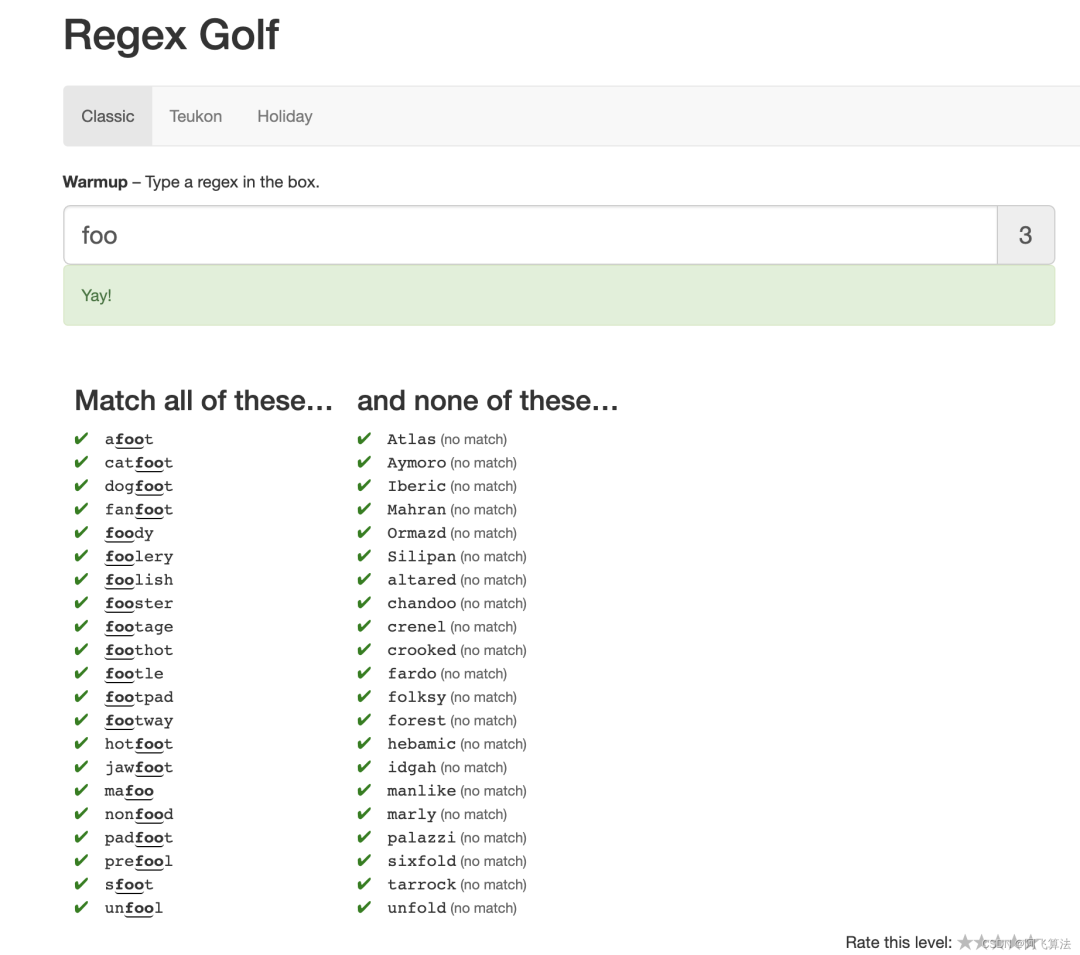
下面的部分是Classic部分
1.Warmup
Type a regex in the box.

仔细观察,左侧的字符都出现了 foo
这字符,右侧则没有,因此直接填入foo
可以解,得分为分
2.Anchors
You are deducted one point per character you use, and ten if you match something you shouldn't.
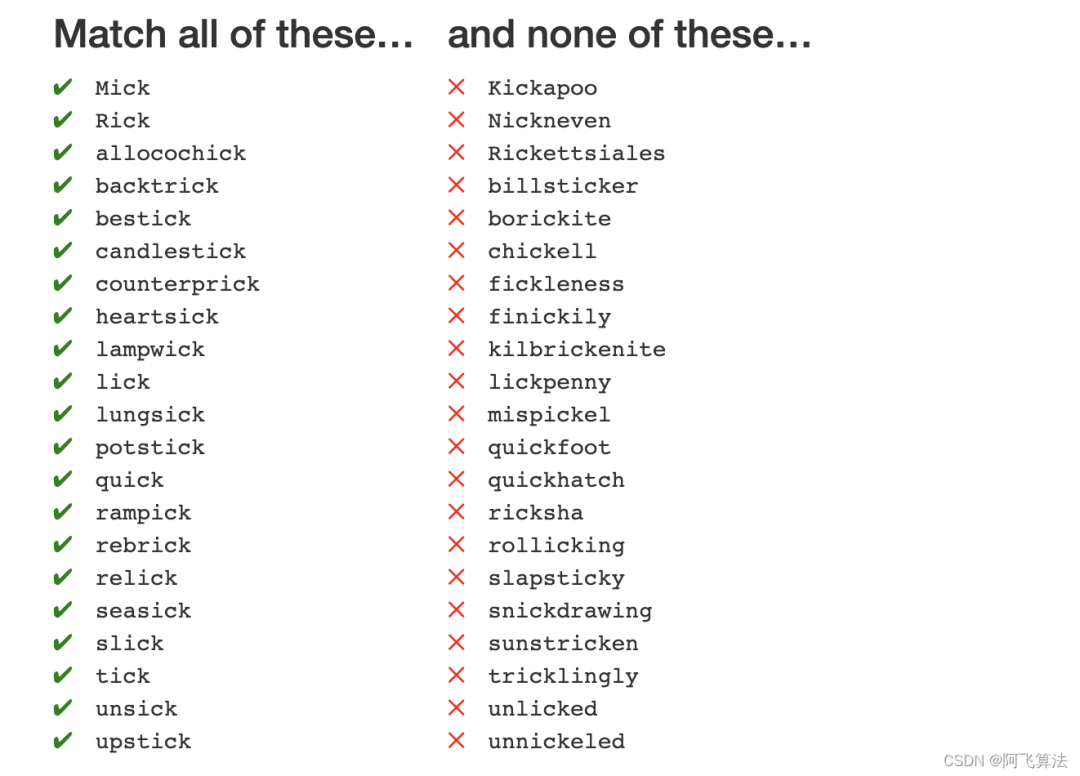
左侧的每个字符都是以 ick
结尾的,使用ick$
,得分分,如果还想要精简一下的话,k$
也可以做到匹配,得分能到分
紧接着,根据上一题的做法,给了下面这道题,但是不允许有$
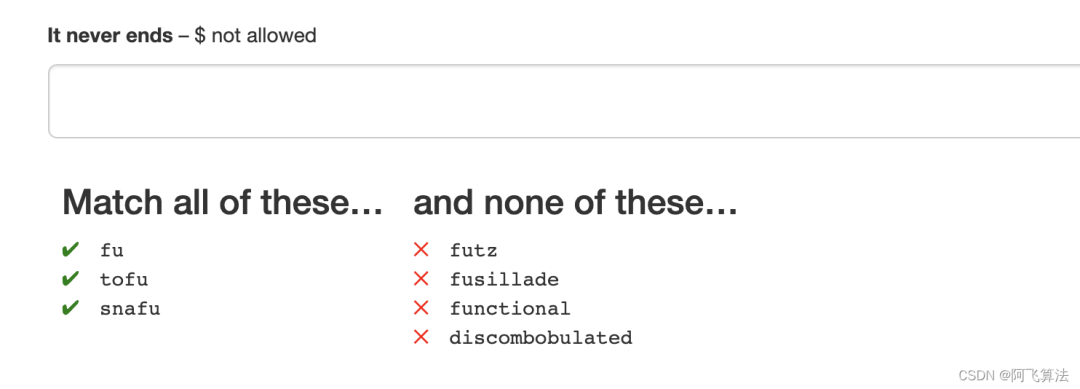
考虑使用 \b
这个匹配,\b
断言此位置为单词边界:(^\w|\w$|\W\w|\w\W)
,u\b
可以解本题,得分分
3.Ranges
The test vectors were generated by grepping /usr/dict/words. Can you tell?

考察的是字母的范围,观察下来,左侧的字母都是 a-f
之间的,右侧不需要匹配的,则超出了这个范围,^[a-f]*$
可以解,要求a-f
的字符出现了0次以上,得分分
4.Backrefs
This doesn't really work as a tutorial. Not really clear what you're supposed to do here.

观察下来是 xxx......xxx
这样的形式,如allochirally
,all
在前面出现过一次,在后面又出现了一次,这种结构很容易使用反向引用解决,(...).*\1
可以解决,得分分,其中\1
匹配与捕获组1st最近匹配的相同的文本,也就是前面的那个括号
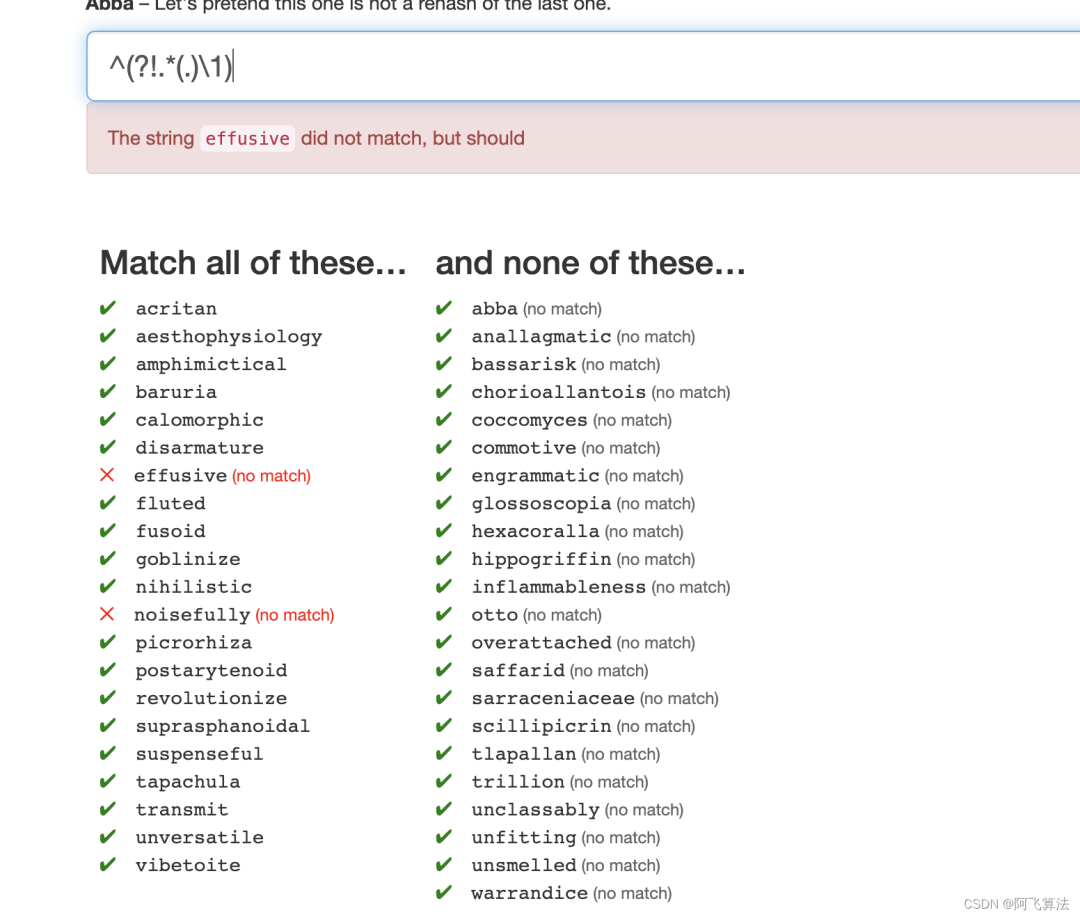
5.Abba
Let's pretend this one is not a rehash of the last one.

这一题要求的是不能匹配形如
abba
这样结构的字符,如右侧的anallagmatic这个单词,alla便是这种结构,需要把这种结构的字符全部排除掉使用负向零宽先行断言,可以筛选出左侧匹配上的,
(?!(.)(.)\2\1)
,但是右侧的不能筛选出来,而且需要排除掉这种串****xoox****
,只需要在前后补字符并把这段能匹配上的字符全部排除掉,^(?!.*(.)(.)\2\1.*)
为最终解,这个字符是19个,总的是43个单词,扣除右边不要的22个单词,得分是210-19=分在本题中,去掉最后的字符匹配也能通过,
^(?!.*(.)(.)\2\1)
,得分来到还看到多大神的一种解法
^(?!.*(.)\1)
相当于强制筛选abba中间的结构,而不管前后的a,然而输入进去后,发现左侧有两个应该要匹配的字符匹配不上,这时候观察了下这个两个字符,都有ef两个相连的字符
,^(?!.*(.)\1)|ef
可以解本题,得分来到分
6.A man, a plan
You're allowed to cheat a little. Even in hard mode, words will be no longer than 13 characters.

本题是要找这种回文结构,如deedeed,civic,也就是常说的偶回文,奇回文,写出 (.)(.).?\2\1
后发现,右侧有一个字符没有被排除掉,观察左侧的字符,可以往后再多多加一个字符强制提前结束,写出这样的正则:(.)(.).?\2\1.?$
,得分为分
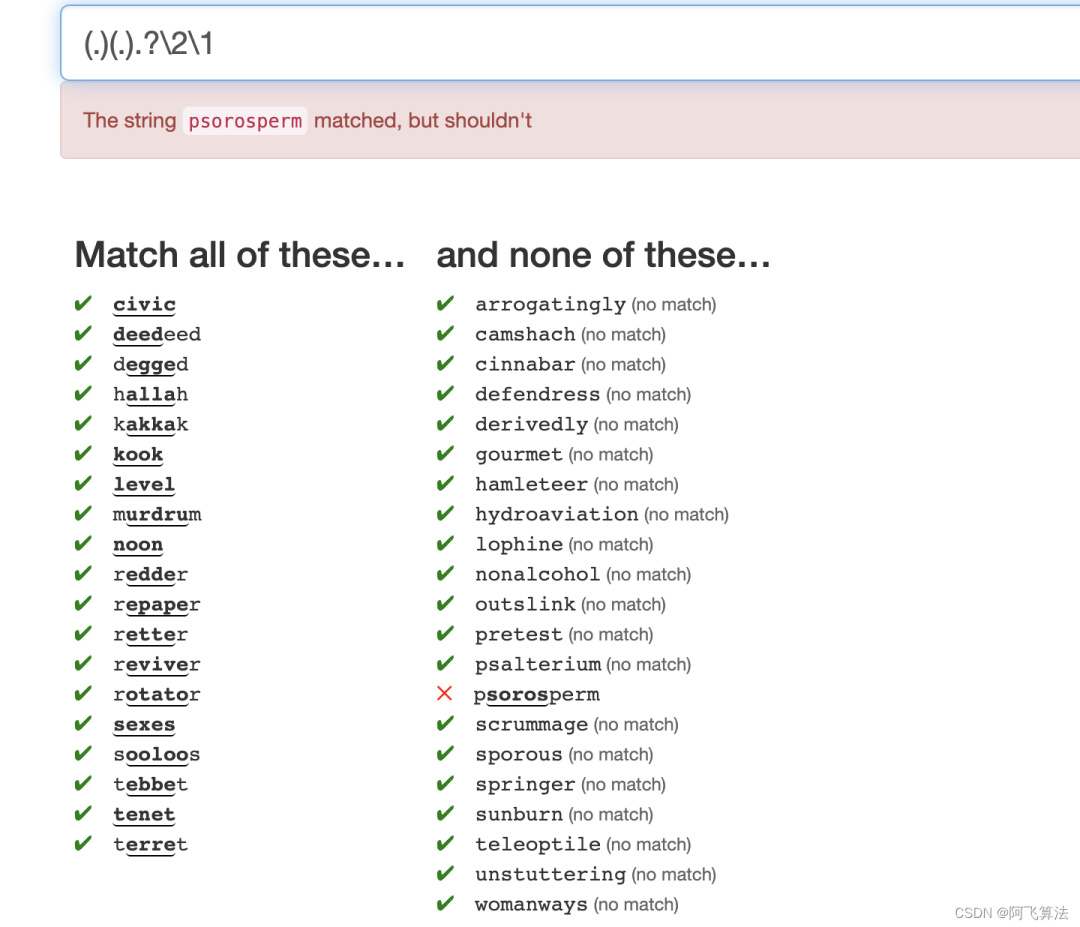
但是本题题干部分给出了「cheat」的字眼,那我们就不客气了,精简到只反向引用一个字符,写出 ^(.).*\1$
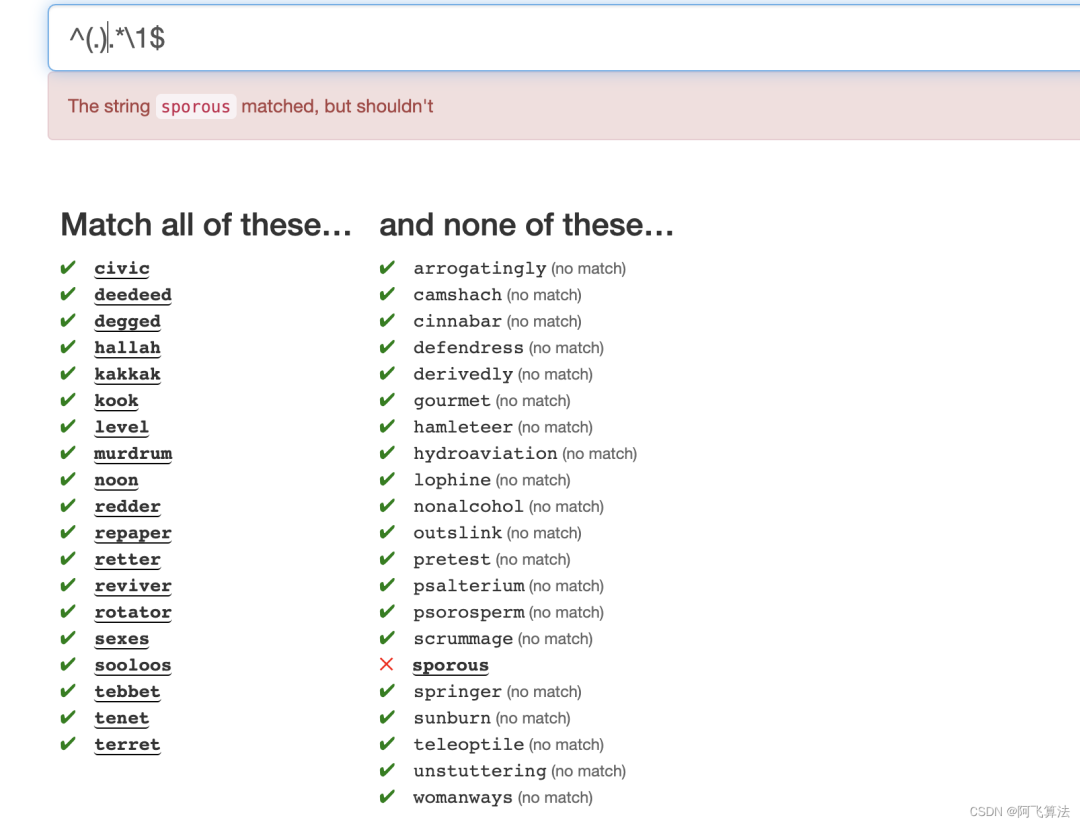
,但是如下图,右侧有一个单词没有被排除掉,采用「cheat」的方式,排除掉这个单词^(.)[^p].*\1$
,得分来到
7.Prime

题目要求筛选出长度是Prime也就是诸如2、3、5、7、11、13、17等这样的质数,的字符串,字符都是x组成的,一开始我看出了要判断括号的里的数字,其实是题面省略了x的个数,比如说 xx...(17)..xx
表示这一行x
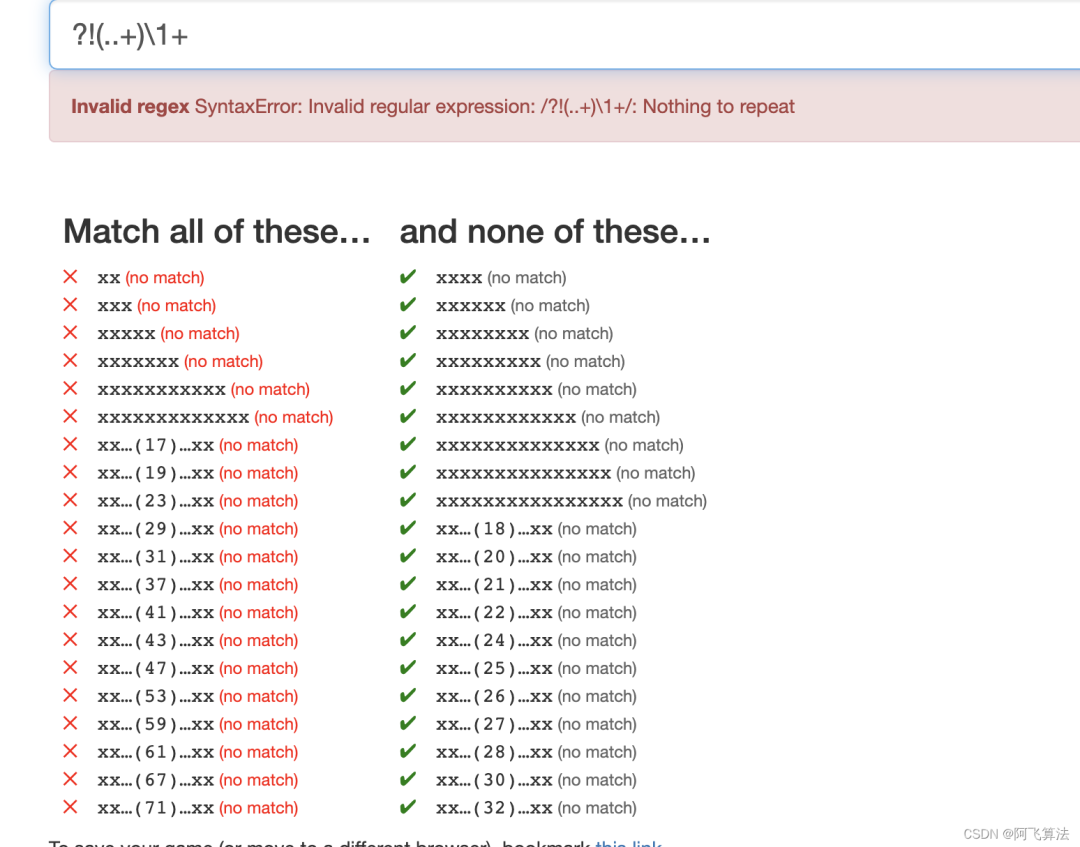
出现了17次,也就是质数,右侧的是非质数做法也很巧妙,主体思想是要筛掉右侧这种非质数,也就是诸如4、6、8、9、10、12、14、15、16等这样的数,了解埃筛(埃拉托斯特尼筛法)的话,这一题就很容易解答,首先发现2的倍数诸如4、6、8、10、12等这样的数不是质数、3的倍,6、9、12、15、18等这样的不是质数,同理对于5,7等数的倍数也不是质数,只需要使用反向引用可以达到翻倍的效果 (..+)
中+
表示出现一次或者无数次,也就是说,某个字符出现2、3、4、5等次数,(..+)\1+
,使用反向引用对前面匹配到的捕获组进行重复,+
表示至少1次,通过这样的方式,保留了作为2、3、4、5这样的基本数,筛选出了2的倍数,3的倍数、4的倍数、5的倍数,加一个否定环视?!(..+)\1+
,就能匹配到右边,而左边没匹配
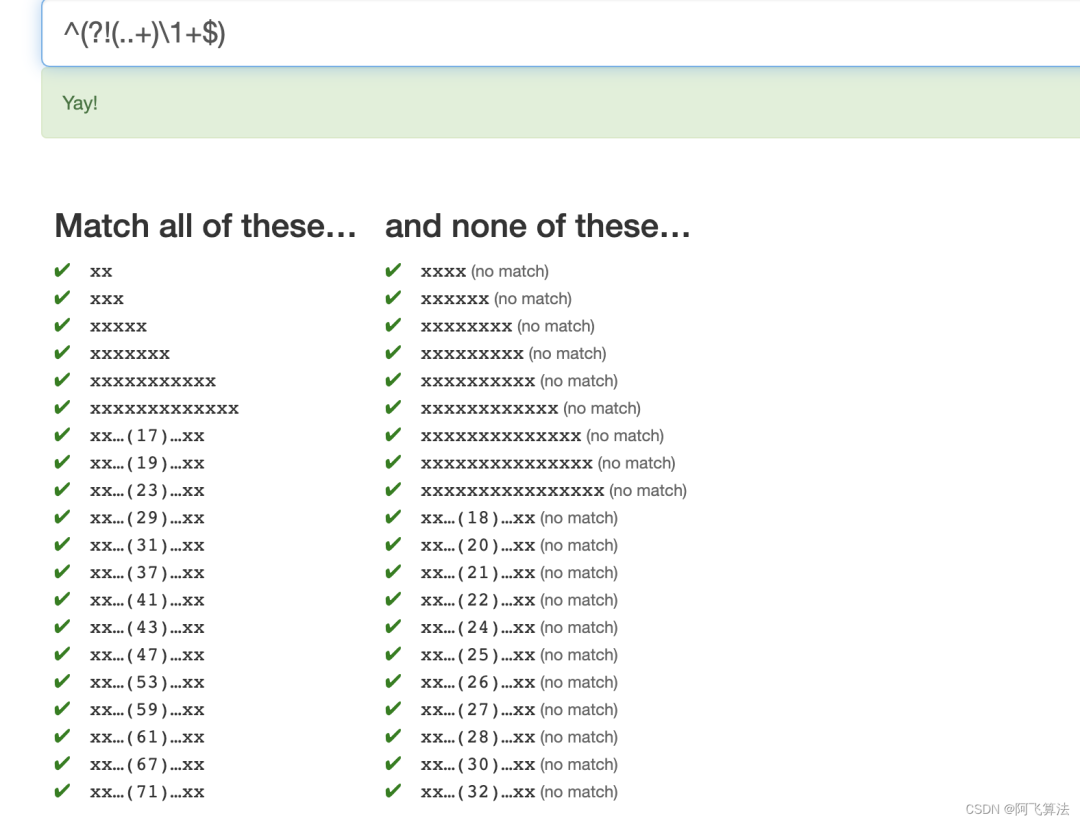
接着,提供一个反选,可以匹配到左边,筛出掉右边 ^(?!(..+)\1+$)
,)`
8.Four
You can get an extra point by ignoring the name of this level.

需要匹配这种 x*x*x*x*
结构,只需要反向引用第一个字符,整体3次即可,(.)(.\1){3}
,得分
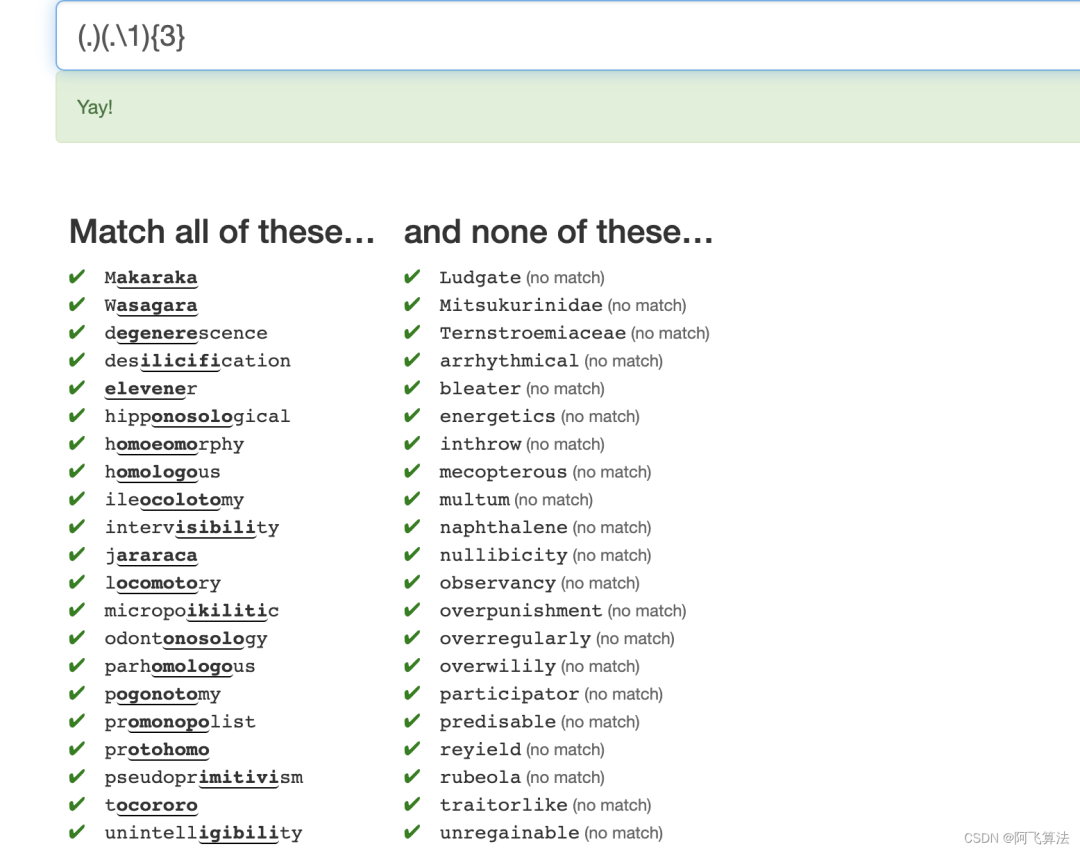
9.Order
Cheat
这一题题面已经给了可以「cheat」,看了下大佬的解,我不说话了: ^.{5}[^e]?$
,左边的字符都是5个,右边的字符都含有e这个字符,排除掉
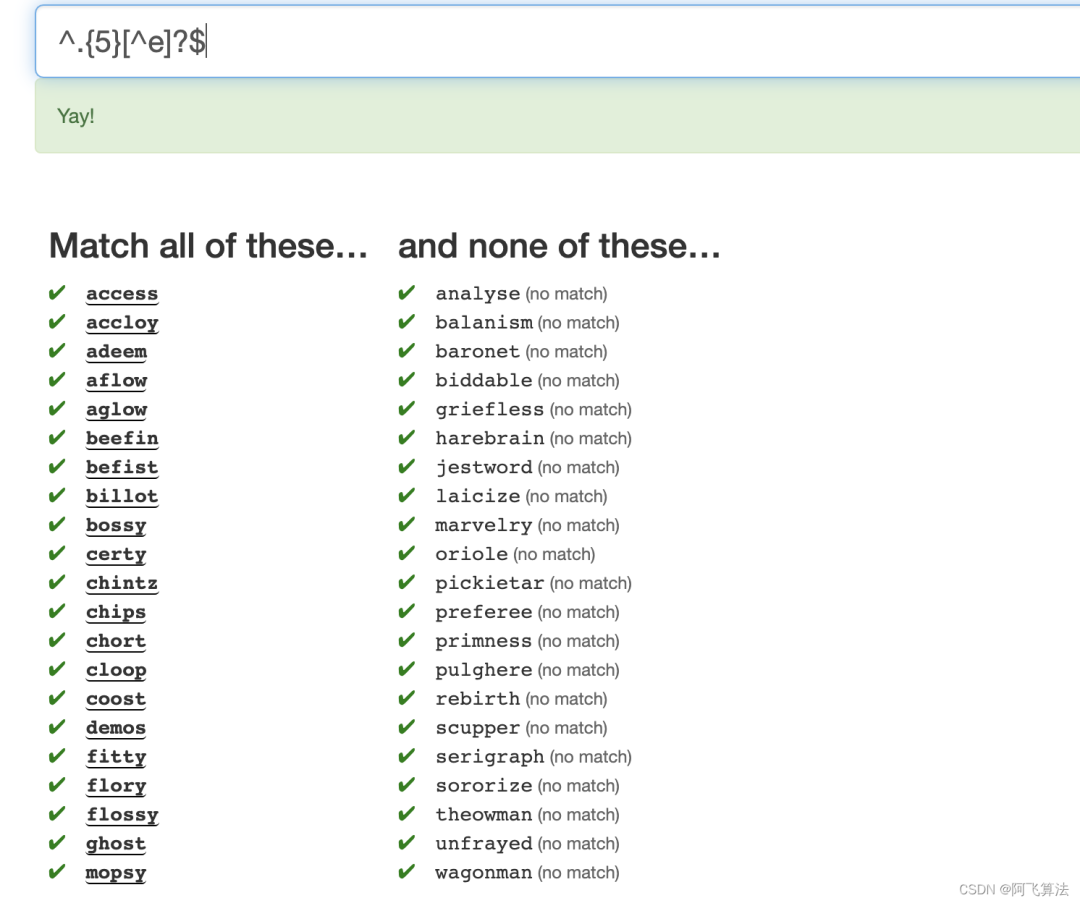
10.Triples
Multiples of 7 are left as an exercise for the reader.
这一题之前的文章详细介绍过怎么使用自动状态机构造符合3的倍数的正则:正则表达式如何匹配3的倍数?
看了下牛人给出的答案,没什么营养,大体就是面向测试写正则:
00($|3|6|9|12|15)|4.2|.1.+4|55|.17
,这种方式应该是一种作弊手段,且不太可能被推广,7的倍数也可以使用上面链接讲到的方式去完成
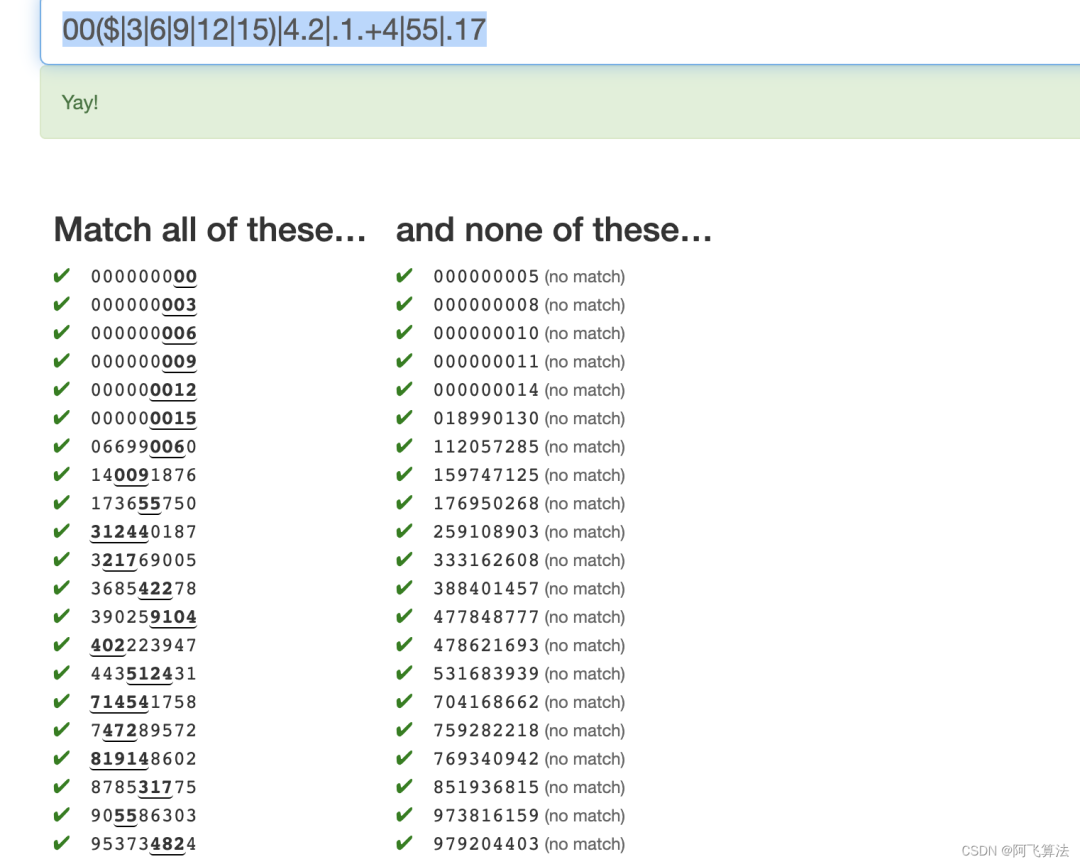
11.Glob

题意是想匹配 xxx mathchs yyy
这样的结构,可能xxx
中有*
,需要替换掉对应的字符,位置顺序必须一致,看了眼答案:ai|c$|^p|[bcnrw][bnopr]
,是观察出来的结果
12.Balance
This one is also impossible, but there’s a finite number of test cases.

题意是要筛选出正确的括号对,
^(<(..(?!<.>$))*>)*$
,这里面用到了循环捕获组,只捕获最后一次匹配。在循环捕获组外层加一个括号以获取所有结果,或使用非捕获组如果您对捕获数据不感兴趣的话,这其中也使用了否定型顺序环视(?!<.>$)
,上面的结果不足以通过所有的case,最后补了一个.{37}
,排除掉了例外的情况,^(<(..(?!<.>$))*>)*$|.{37}
是最终的答案括号配对,对于正则是一个非常大的难题,正则文法的定义先天就不是递归的。现在用的加强的正则表达式,尽管加入了反向引用、计数、前瞻后瞻等高级功能,只是在引擎层面新增了功能。
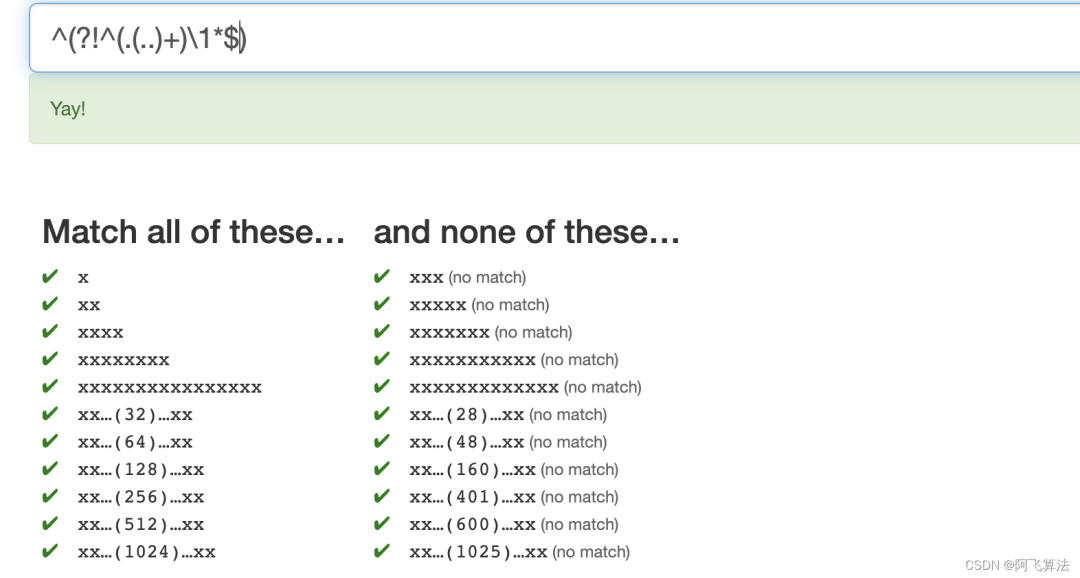
13.Powers

这题和第7题Prime很像,想要的匹配的是1、2、4、8、32、64、128等这样2的幂的数量的字符串,3、5、7等这种不应该出现,这些长度的字符串有个特点,可以表示成 2n+1
,可以写出^(.(..)+)$
这种形式的,可以筛选掉部分,但是401、1025这种长度的还是没有筛选掉,对这些不符合的数做因式分解,28=7*2*2
,48=3*2*2*2*2
,160=5*2*2*2*2*2
,600=75*2*2*2
,也就是说都是(2n+1)*pow(2, m)
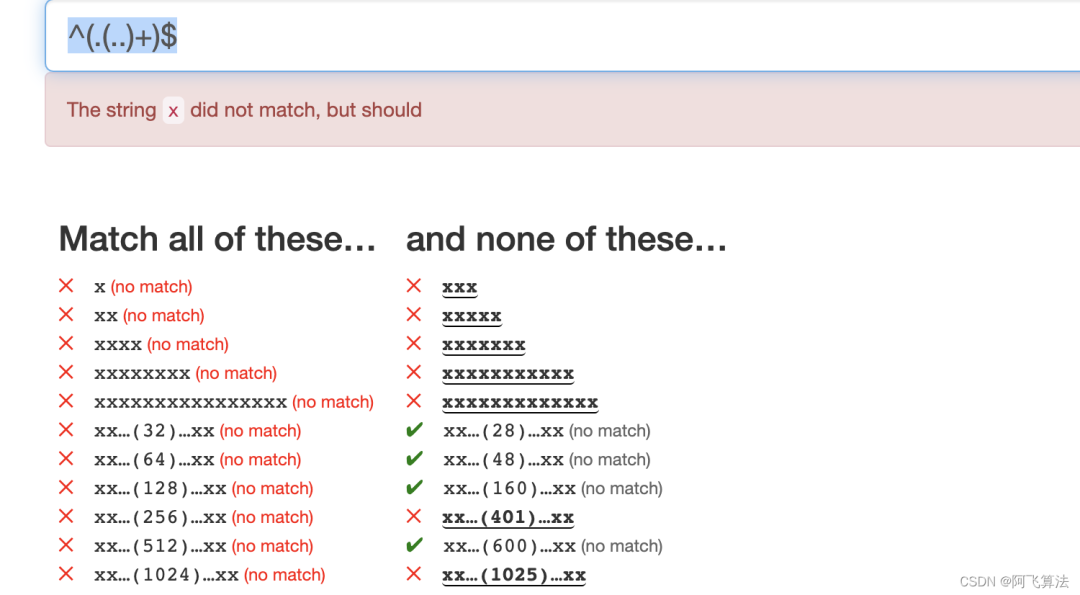
也就是说,加一个反向引用可以达到倍数的效果,再把这些结构的字符长度的全部筛选掉,答案是: ^(?!^(.(..)+)\1*$)
14.Long count

又一个反向引用的例子, ((.+)0\2+1){8}
,这段是观察后的结果,大体意思是把x0x1
这种结构重复8次,当然\2+
匹配的到的(.+)
可以是0次
15.Alphabetical
To save typing the input will only use the characters a/e/n/r/s/t, even in hard mode.

看了下答案 .r.{32}r|a.{10}te|n.n..
,三段的正则,应该是根据目标集找单词的规律的,好吧,这题我没看懂~
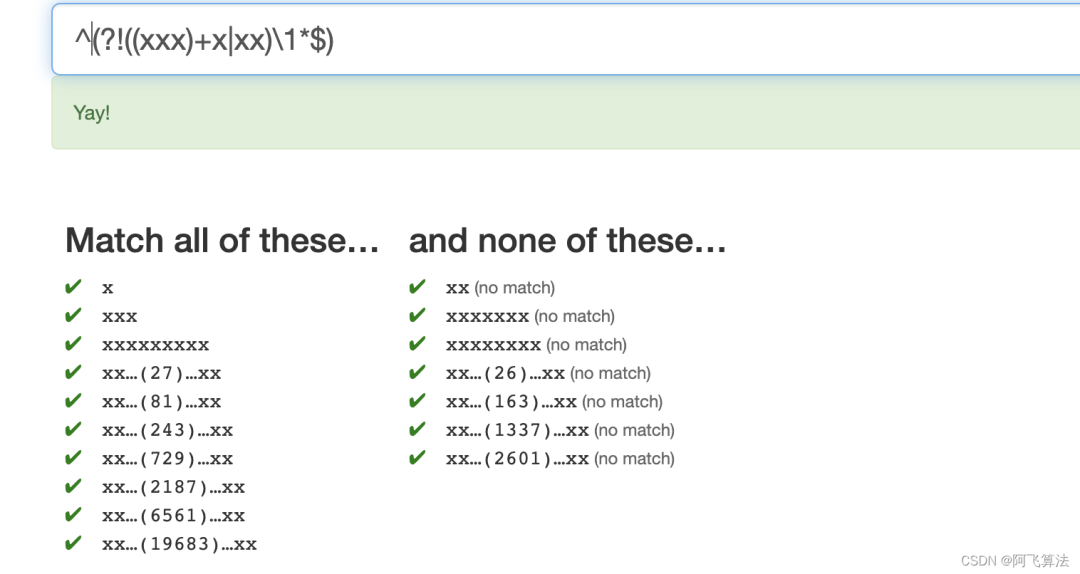
16.Powers 2
Or 3

想要筛选掉不是3的幂的数,也就是筛选出1 、3、9、27、81这种、筛选掉2、4、5、6、7、8这种不是3的幂的数,和13题Powers类似,需要考虑筛选掉 3n+1
,3n+2
的倍数,因为所有数mod3只有只有三种数0、1、2排除掉后两种^(?!((xxx)+x|xx)\1*$)
,里面括号可以筛选出3n+1
,3n+2
这样的数,最后反选掉
下面的部分是Teukon部分
17.Subtraction
题目要求筛选出正确的等式

^(.+)(.+) - \1 = \2$
很好理解,第一部分的字符拆成两个部分,分别给到第一个反向引用和第二个反向引用
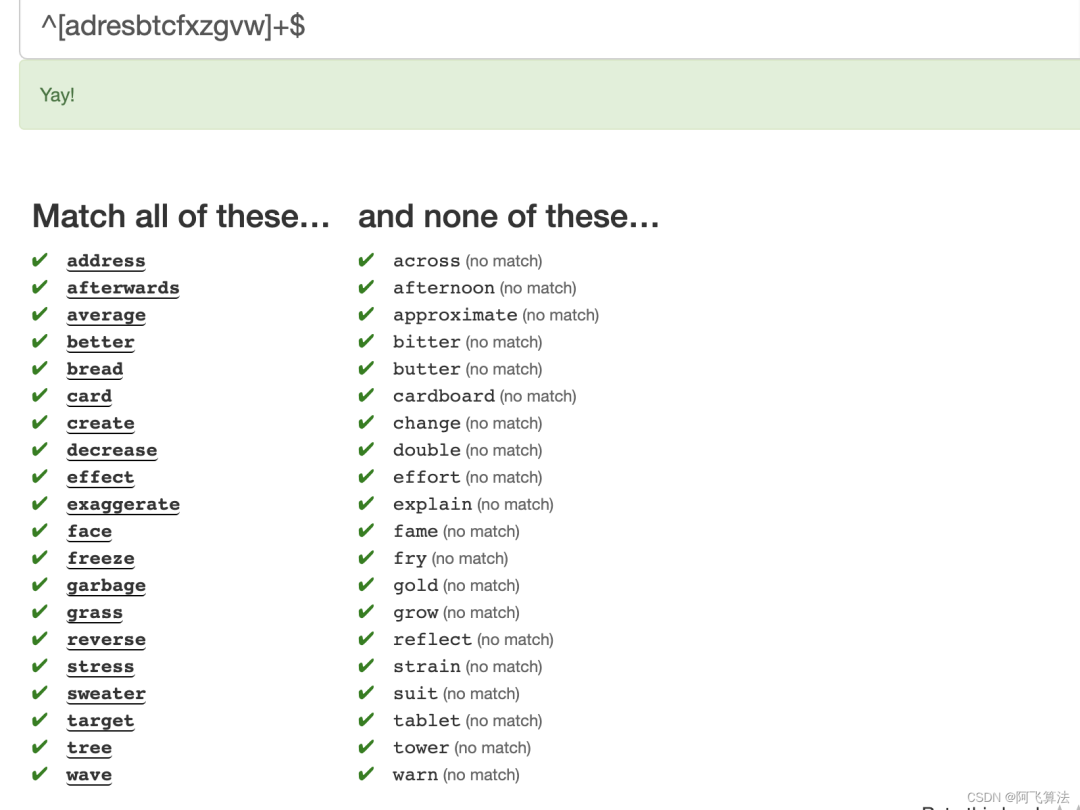
18.Typist
With apologies to Dr. Dvorak.
找字符的规律: ^[adresbtcfxzgvw]+$
19.Addition
Beauty in symmetry.

和17题Subtraction类似,处理方式是将 = 号左右两边的+号当成一个组的字符来看, ^(.*)(.*)(.*) = \3\2\1$
,左边当成一个整体来看,反选掉不符合等式的结果
20.Anyway
Old MacDonald had a farm...

大神的写法: ^[aeiouy]?(.[aeiouy])+[^aeiou]?$
21.Tic-tac-toe
Don't forget the horizontals.
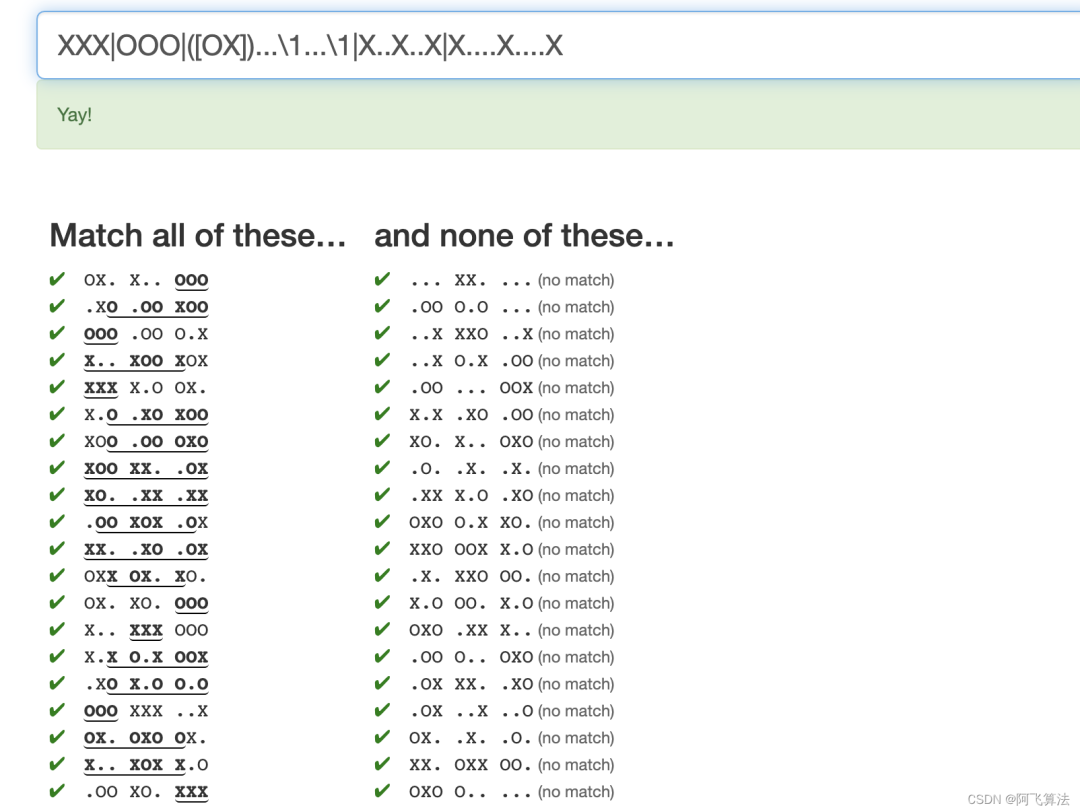
找的字符串的规律: XXX|OOO|([OX])...\1...\1|X..X..X|X....X....X
,能筛选出来
总结
后面还有题目,我没写完,有机会再发第二期吧~
Reference
正则大挑战github
延伸阅读
「正则大法好」:正则技术交流群,群内有不少大佬,可以提需求,迅速有响应,也欢迎拉人~

