





亲爱的社区小伙伴们,我们很高兴地向大家宣布,近期我们迎来了 Apache Doris 3.1 版本的正式发布,欢迎大家下载使用体验。
3.1 版本是 Apache Doris 在半结构化分析上的一个里程碑版本。在 VARIANT 类型上,3.1 版本新增了稀疏列能力,使得 VARIANT 可以轻松应对数万子列的场景。同时,在 VARIANT 类型上引入了模板化 schema 能力,让 VARIANT 类型在关键路径上,查询更快、索引更稳、成本可控,同时不丢失灵活性。在倒排索引能力上,3.1 版本引入了 index v3 版本的索引格式,相比较于 v2 版本存储空间节省可达 20%。同时,支持了更为丰富的分词手段,提供了三种全新的分词器:ICU Tokenizer、IK Tokenizer 和 Basic Tokenizer。还进一步支持了自定义分词器,可以突破内置分词器的局限性,根据业务场景定制,显著提升搜索召回率。
3.1 版本同样在湖仓一体上有了显著的增强。在 3.1 版本中,Apache Doris 将异步物化视图中的分区构建和透明改写分区补偿,这两项重要能力引入数据湖中,在湖和仓中间架起一座重要的桥梁。3.1 版本还扩充了对 Iceberg 和 Paimon 特性的支持范围。另外,通过引入动态分区裁剪和批量分片执行在特定场景下提升了数据湖查询的性能多达 40%,并显著降低了 FE 的内存占用。同时 3.1 版本还重构了各个数据源的连接属性,不仅能够以更加清晰的方式对接各类元数据服务和数据存储系统,同时还支持了更加丰富的连接能力。
3.1 版本 Apache Doris 持续打磨存储引擎。提供了全新的数据更新方式 —— 灵活列更新。在部分列更新的基础上,进一步放开限制。在一次导入中对于每一行可以更新不同的列。另外,在存算分离场景下,优化了 MOW 表部分链路的锁获取逻辑和使用范围,提升高并发导入场景的使用体验。
在性能方面,3.1 着重优化了分区裁剪的能力和规划性能。在数万分区和复杂分区过滤表达式的场景下,能够显著提升查询性能并降低资源消耗。同时,3.1 还在优化器中全面引入了基于数据特征的优化手段,在特定场景下可以获得超过 10 倍的性能提升。
在 3.1 版本的研发过程中,有超过 90 名贡献者为 Apache Doris 提交了 1000+ 个优化与修复。在此向所有参与版本研发、测试和需求反馈的贡献者们表示最衷心的感谢。
一、VARIANT 半结构化查询华丽变身
存储能力质变:稀疏列与子列 Vertical Compaction,轻松支持数万子列
传统 OLAP 面对“超宽表/超多列”(上千到上万)常遇到元数据膨胀、合并放大与查询退化;Doris 3.1 通过 VARIANT 的稀疏子列与子列级 Vertical Compaction,将可维护的列数上限抬升到数万级。
通过对存储层的深入优化, Variant 给用户带来以下收益:
稳定支撑“上千 - 数万”子列(列式存储),查询/合并延迟更平滑。
元数据与索引可控,避免指数级膨胀。
实测可进行 10,000+ 子列提取(列式存储),Compaction 效率顺畅。
超多列的适用场景:
车联网/IoT 遥测:设备型号多、传感器维度动态增减。
营销自动化/CRM:事件/用户属性持续扩展(如自定义 event/property)。
广告/埋点事件:海量可选 properties,字段稀疏且不断演进。
安全审计/日志:不同源日志字段各异,需按模式聚合检索。
电商商品属性:类目跨度大,商品属性高度可变。
实现原理
稀疏子列(Sparse Subcolumns):按 JSON Key 频次排序,只提取 Top-N 高频子列入“真列式”;长尾保持在稀疏列存储,避免无序扩张。
子列级 Vertical Compaction:对 VARIANT 子列应用 Vertical Compaction,分组合并、内存占用更小;合并时动态识别并固化热点路径,进一步降低合并开销。
优化值填充默认值效率,按 batch 的方式进行批量填充(减少虚函数开销)。
通过 LRU 机制减少内存中列存储相关元数据缓存内存开销。
如何开启与使用
新增列级别控制 Variant 参数,列属性(Properties):
variant_max_subcolumns_count:默认是0
, 表明不开启稀疏列能力, 设置成特定值后将会提取 Top-N 高频的 JSON key 作为列式存储,余下的列进入稀疏列存储。
-- Enable sparse subcolumns and cap hot subcolumn count
CREATE TABLE IF NOT EXISTS tbl (
k BIGINT,
v VARIANT<
properties("variant_max_subcolumns_count" = "2048") -- pick top-2048 hot keys
>
) DUPLICATE KEY(k);
模板化 Schema(Schema Template) - 变化中的不变量
一句话总结:模板化 Schema 让“常变”的 JSON 在关键路径上“变得可预期”:查询更快、索引更稳、成本可控,同时不丢失灵活性。
使用模板化的 Schema, 将会给使用 Variant 数据类型带来以下收益:
类型稳定:关键子路径类型可在 DDL 中固定,避免类型漂移引发的查询报错、索引失效与隐式转换开销。
检索更快更准:为不同子路径定制倒排策略(分词/非分词、解析器、短语搜索等),常用查询延迟更低、命中更稳定。
索引与成本可控:不再“整列统一继承索引”(2.1 的做法易膨胀),而是“按子路径精细化配置”,显著降低索引数量、写放大与存储成本。
可维护/可协作:等同给 JSON 加“数据契约”,跨团队语义一致;类型与索引状态更可观测,问题更易定位。
演进友好:核心高频路径模板化并可选建索引,长尾字段继续保持灵活扩展,不牺牲可扩展性。
如何开启与使用
显式声明结构,指定类型:在
VARIANT<...>
中预定义常用子路径与类型(含通配),例如'a' : int, 'c.d' : text, 'array_int_*' : array<int>
。配置索引,针对同一 VARIANT 列的不同子路径配置不同索引策略(field_pattern、解析器、分词、短语搜索等),差异化提升检索效率,可用通配符批量匹配。
新增列级别控制 Variant 参数,列属性(Properties):
variant_enable_typed_paths_to_sparse
:默认是false
, 表明预定义的列不会进入稀疏列,true
开启后预定义类型路径也会进入稀疏存储(用于避免匹配过多列后导致的列数膨胀)
示例 1:Schema 定义 + 单列多索引
-- Common properties: field_pattern (target subpath), analyzer, parser, support_phrase, etc.
CREATE TABLE IF NOT EXISTS tbl (
k BIGINT,
v VARIANT<'content' : STRING>, -- specify concrete type for subcolumn 'content'
INDEX idx_tokenized(v) USING INVERTED PROPERTIES("parser" = "english", "field_pattern" = "content"), -- tokenized inverted index for 'content' with english parser
INDEX idx_v(v) USING INVERTED PROPERTIES("field_pattern" = "content") -- non-tokenized inverted index for 'content'
);
-- v.content will have both a tokenized (english) inverted index and a non-tokenized inverted index
-- Use tokenized index
SELECT * FROM tbl WHERE v['content'] MATCH 'Doris';
-- Use non-tokenized index
SELECT * FROM tbl WHERE v['content'] = 'Doris';
示例 2:通配符批量处理符合模式的列
-- Use wildcard-typed subpaths with per-pattern indexes
CREATE TABLE IF NOT EXISTS tbl2 (
k BIGINT,
v VARIANT<
'pattern1_*' : STRING, -- batch-typing: all subpaths matching pattern1_* are STRING
'pattern2_*' : BIGINT, -- batch-typing: all subpaths matching pattern2_* are BIGINT
properties("variant_max_subcolumns_count" = "2048") -- enable sparse subcolumns; keep top-2048 hot keys
>,
INDEX idx_p1 (v) USING INVERTED
PROPERTIES("field_pattern"="pattern1_*", "parser" = "english"), -- tokenized inverted index for pattern1_* with english parser
INDEX idx_p2 (v) USING INVERTED
PROPERTIES("field_pattern"="pattern2_*") -- non-tokenized inverted index for pattern2_*
) DUPLICATE KEY(k);
示例 3:允许预定义类型的列进入稀疏列
-- Allow predefined typed paths to participate in sparse extraction
CREATE TABLE IF NOT EXISTS tbl3 (
k BIGINT,
v VARIANT<
'message*' : STRING, -- batch-typing: all subpaths matching prefix 'message*' are STRING
properties(
"variant_max_subcolumns_count" = "2048", -- enable sparse subcolumns; keep top-2048 hot keys
"variant_enable_typed_paths_to_sparse" = "true" -- include typed (predefined) paths as sparse candidates (default: false)
)
>
) DUPLICATE KEY(k);
二、索引架构全面进化
倒排索引存储格式 V3 - 性能和功能的双重提升
相比 V2 进一步优化存储
索引文件更小,减少磁盘占用和 I/O 开销,以 httplogs 与 logsbench 两个测试集测试结果来看,存储空间最大可以通过 V3 节省 20%,适合大规模文本数据、日志分析场景。

核心改进
引入倒排索引 ZSTD 词典压缩:采用 ZSTD 压缩算法对倒排索引内的词典文件进行压缩,通过 index properties 中的
dict_compression
开启。新增倒排索引位置信息压缩:支持对倒排索引中为每个 term 即词元记录的位置信息进行编码压缩,进一步减少倒排索引空间占用。
使用方式
-- 建表时启用V3格式
CREATE TABLE example_table (
content TEXT,
INDEX content_idx (content) USING INVERTED
PROPERTIES("parser" = "english", "dict_compression" = "true")
) ENGINE=OLAP
PROPERTIES ("inverted_index_storage_format" = "V3");
倒排索引 - 分词器灵活多样好用易用
新增三种常用分词器
进一步提升用户在不同场景下的分词需求:
ICU Tokenizer
实现:ICU(International Components for Unicode)
适用场景:包含复杂文字系统的国际化文本,特别适合多语言混合文档。
示例:
SELECT TOKENIZE('مرحبا بالعالم Hello 世界', '"parser"="icu"');
-- 结果: ["مرحبا", "بالعالم", "Hello", "世界"]
SELECT TOKENIZE('มนไมเปนไปตามความตองการ', '"parser"="icu"');
-- 结果: ["มน", "ไมเปน", "ไป", "ตาม", "ความ", "ตองการ"]
IK Tokenizer
实现:IK Analyzer(中文分词器),基于算法的高级中文分词,结合词典和统计模型。
适用场景:对分词质量要求较高的中文文本处理。
模式:
ik_smart:智能模式,词少且更长,语义集中,适合精确搜索。
ik_max_word:最细粒度模式,更多短词,覆盖更全面,适合召回搜索。
示例:
-- 智能模式
SELECT TOKENIZE('中华人民共和国国歌', '"parser"="ik","parser_mode"="ik_smart"');
-- 结果: ["中华人民共和国", "国歌"]
-- 最细粒度模式
SELECT TOKENIZE('中华人民共和国国歌', '"parser"="ik","parser_mode"="ik_max_word"');
-- 结果: ["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "共和国", "共和", "国歌"]
Basic Tokenizer
实现:简单规则的自定义分词器,基础分词,采用字符类型识别进行分词。
适用场景:简单场景、对性能要求极高的场景。
分词规则:
连续的字母数字字符作为一个词(word tokens)。
中文字符单独分词(每个汉字一个 token)。
忽略标点符号、空格和特殊符号。
示例:
-- 英文文本分词
SELECT TOKENIZE('Hello World! This is a test.', '"parser"="basic"');
-- 结果: ["hello", "world", "this", "is", "a", "test"]
-- 中文文本分词
SELECT TOKENIZE('你好世界', '"parser"="basic"');
-- 结果: ["你", "好", "世", "界"]
-- 混合语言分词
SELECT TOKENIZE('Hello你好World世界', '"parser"="basic"');
-- 结果: ["hello", "你", "好", "world", "世", "界"]
-- 包含数字和特殊字符
SELECT TOKENIZE('GET images/hm_bg.jpg HTTP/1.0', '"parser"="basic"');
-- 结果: ["get", "images", "hm", "bg", "jpg", "http", "1", "0"]
-- 处理长数字序列
SELECT TOKENIZE('12345678901234567890', '"parser"="basic"');
-- 结果: ["12345678901234567890"]
自定义分词
推出自定义分词功能,方便用户根据自身分词需求,进行 DIY 组合,进一步提高文本检索召回率。自定义分词可以突破内置分词的局限,根据特定需求组合字符过滤器、分词器和词元过滤器,精细定义文本如何被切分成可搜索的词项,这直接决定了搜索结果的相关性与数据分析的准确性。

使用场景举例
问题
使用默认 unicode 分词器时,电话号码"13891972631"被当作完整 token,无法支持前缀搜索如"138"。
解决方案
创建分词器(tokenizer)
使用 Edge N-gram 自定义分词器:
CREATE INVERTED INDEX TOKENIZER IF NOT EXISTS edge_ngram_phone_tokenizer
PROPERTIES
(
"type" = "edge_ngram",
"min_gram" = "3",
"max_gram" = "10",
"token_chars" = "digit"
);
创建分析器(analyzer)
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS phone_prefix_analyzer
PROPERTIES
(
"tokenizer" = "edge_ngram_phone_tokenizer"
);
创建表指定 analyzer
CREATE TABLE customer_contacts (
id bigint NOT NULL AUTO_INCREMENT(1),
phone text NULL,
INDEX idx_phone (phone) USING INVERTED PROPERTIES(
"analyzer" = "phone_prefix_analyzer"
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY RANDOM BUCKETS 1
PROPERTIES ("replication_allocation" = "tag.location.default: 1");
查看分词效果
SELECT tokenize('13891972631', '"analyzer"="phone_prefix_analyzer"');
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| tokenize('13891972631', '"analyzer"="phone_prefix_analyzer"') |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| [{
"token": "138"
}, {
"token": "1389"
}, {
"token": "13891"
}, {
"token": "138919"
}, {
"token": "1389197"
}, {
"token": "13891972"
}, {
"token": "138919726"
}, {
"token": "1389197263"
}] |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
文本搜索效果
SELECT * FROM customer_contacts_optimized WHERE phone MATCH '138';
+------+-------------+
| id | phone |
+------+-------------+
| 1 | 13891972631 |
| 2 | 13812345678 |
+------+-------------+
SELECT * FROM customer_contacts_optimized WHERE phone MATCH '1389';
+------+-------------+
| id | phone |
+------+-------------+
| 1 | 13891972631 |
| 2 | 13812345678 |
+------+-------------+
2 rows in set (0.043 sec)
通过 Edge N-gram 分词器,一个电话号码被拆分成多个前缀 token,实现了灵活的前缀匹配搜索。
三、湖仓一体能力再跃新高
异步物化视图全面支持数据湖
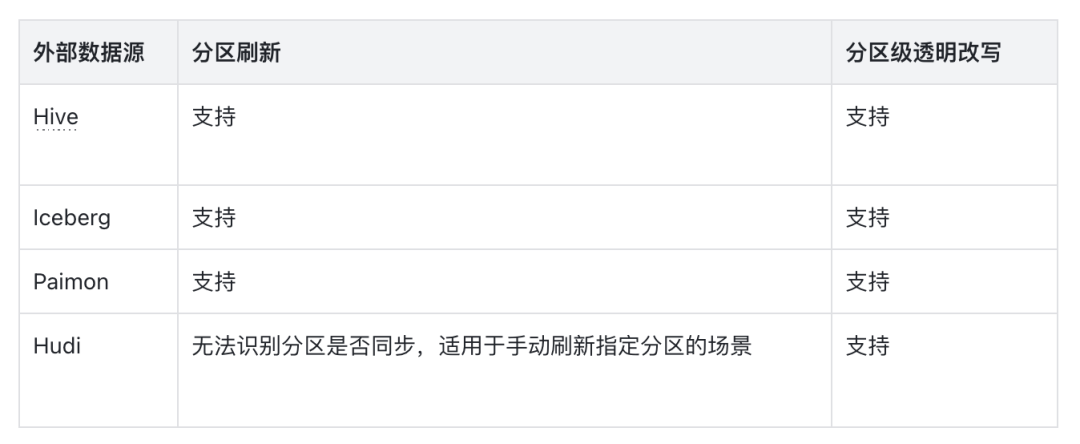
在 3.1 版本中,异步物化视图再次进化,现在可以完整支持 Paimon Iceberg Hudi 的分区增量构建和分区透明改写。 Doris 自 2.1 版本支持异步物化视图功能开始。经过多个版本的迭代。已经支持了非常多有价值的特性。包括:

3.1 版本则重点打磨湖仓一体方向上的功能,全面支持主流的数据湖表格式 Paimon/Iceberg/Hudi 的分区刷新,和透明改写时的外部数据源分区补偿。使其成为联通湖和仓之间的高速公路。具体支持范围详见下表:
Iceberg Paimon 能力全面扩充
Iceberg
3.1.0 版本针对 Iceberg 表格式上做出多项优化和能力增强,紧密推进与 Iceberg 最新特性的融合。
| 支持 Branch Tag 完整生命周期管理
从 3.1.0 开始,Doris 原生支持 Iceberg Branch & Tag 的创建、删除、读取与写入操作。该功能能够让用户像 Git 一样操作和管理 Iceberg 表数据。这一能力为 Iceberg 表格式的多版本并行管理、灰度测试、环境隔离等业务场景提供了原生的支持,无需额外引擎或自定义逻辑。
-- 创建分支
ALTER TABLE iceberg_tbl CREATE BRANCH b1;
-- 写入数据到指定分支
INSERT INTO iceberg_tbl@branch(b1) values(1, 2);
-- 查询指定分支
SELECT * FROM iceberg_tbl@branch(b1);
| 丰富的 Iceberg 系统表支持
3.1.0 新增对 Iceberg $entries
, $files
, $history
, $manifests
, $refs
, $snapshots
等系统表的支持,可用 SELECT * FROM iceberg_table$history
、…$refs
等语句直接查询 Iceberg 的底层 metadata、snapshot 列表、分支/标签信息等,从而深入了解数据文件的组织结构、快照的变更历史以及分支的映射情况。这种能力大大提升了 Iceberg 元数据的可观测性,使得问题定位、调优分析和治理决策更加直观、透明。
如通过系统表查看 delete file 数量:
SELECT
CASE
WHEN content = 0 THEN'DataFile'
WHEN content = 1 THEN'PositionDeleteFile'
WHEN content = 2 THEN'EqualityDeleteFile'
ELSE'Unknown'
END AS ContentType,
COUNT(*) AS FileNum,
SUM(file_size_in_bytes) AS SizeInBytes,
SUM(record_count) AS Records
FROM
iceberg_table$files
GROUP BY
ContentType;
+--------------------+---------+-------------+---------+
| ContentType | FileNum | SizeInBytes | Records |
+--------------------+---------+-------------+---------+
| EqualityDeleteFile | 2787 | 1432518 | 27870 |
| DataFile | 2787 | 4062416 | 38760 |
| PositionDeleteFile | 11 | 36608 | 10890 |
+--------------------+---------+-------------+---------+
| Iceberg 视图查询
3.1.0 版本新增对 Iceberg 逻辑视图的访问和查询。该功能进一步提升了 Doris 对 Iceberg 功能的完善程度。在后续 3 位版本迭代中,我们将进一步支持 Iceberg View 的 SQL 方言转换能力。
| 通过 ALTER 语句修改 Iceberg 表结构
3.1.0 支持通过 ALTER TABLE
语句对 Iceberg 表进行字段的新增、删除、重命名和重排序操作。该功能进一步完善了 Doris 对 Iceberg 表的管理能力,无需再借助 Spark 等第三方引擎进行 Iceberg 表管理。
ALTER TABLE iceberg_table
ADD COLUMN new_col int;
同时,在 3.1.0 版本中,Iceberg 的依赖版本升级到 1.9.2,以便更好的支持 Iceberg 的新的功能。在后续 3.1 的迭代版本中,我们将进一步增强 Iceberg 的表管理能力,包括数据合并、分支演进等能力。
文档参考:https://doris.apache.org/docs/lakehouse/catalogs/iceberg-catalog(复制至浏览器打开)
Paimon
3.1.0 版本针对 Paimon 表格式,结合用户实际场景,进行了多项功能更新和能力增强。
| 支持 Paimon Batch Incremental Query
3.1.0 版本支持读取 Paimon 表指定的两个快照之间的增量数据。该功能增强了用户对 Paimon 表增量数据的访问能力。尤其是在增量物化视图构建方面,基于此功能实现了 Paimon 表的增量聚合物化视图能力。详见物化视图方面的说明。
SELECT * FROM paimon_tbl@incr('startSnapshotId'='2', 'endSnapshotId'='5');
| 支持 Branch Tag 读取
从 3.1.0 开始,Doris 支持对 Paimon 表的 Branch Tag 进行读取,帮助用户更灵活的访问多版本的 Paimon 数据。
SELECT * FROM paimon_tbl@branch(branch1);
SELECT * FROM paimon_tbl@tag(tag1);
| 丰富的 Paimon 系统表支持
同 Iceberg 一样,3.1.0 新增对 Paimon $files
, $partitions
, $manifests
, $tags
, $snapshots
等系统表的支持,可用 SELECT * FROM partition_table$files
等语句直接查询 Paimon 的底层元数据信息。更方便用户对 Paimon 表进行探测、调试和优化。
如我们可以通过系统表统计分区新增数据文件:
SELECT
partition,
COUNT(*) AS new_file_count,
SUM(file_size_in_bytes)/1024/1024 AS new_total_size_mb
FROM my_table$files
WHERE creation_time >= DATE_SUB(NOW(), INTERVAL 3 DAY)
GROUP BY partition
ORDER BY new_total_size_mb DESC;
在 3.1.0 版本中,Paimon 的依赖版本升级到 1.1.1,以便更好的支持 Paimon 的新的功能。
文档参考:https://doris.apache.org/docs/lakehouse/catalogs/paimon-catalog(复制至浏览器打开)
数据湖查询性能更上一层楼
3.1.0 版本,针对数据湖表格式的查询性能进行了多项深度优化,旨在实际生产环境下,为用户提供更加稳定、高效的数据湖分析能力。
动态分区裁剪
动态分区裁剪功能,能够在多表关联查询场景下,根据右表数据生成分区列谓词,并对左表数据进行运行时的分区剪枝,从而减少数据 IO,提升查询性能。在 3.0 版本中,Doris 已经支持了 Hive 表的动态分区裁剪功能。在 3.1.0 版本中,这个功能进一步扩充到了 Iceberg、Paimon 和 Hudi 表上。在测试场景下,针对选择率较高的查询,可以提升 30%-40%的性能。
批量分片执行
当湖表的数据分片较多时,如果 FE 进行规划并将所有分片信息一次性组装完成发送给 BE,那么可能造成 FE 内存消耗过大以及处理实际过长的问题。尤其是在查询大数据量表时,会导致规划部分的资源开销大耗时长。批量分片执行功能,通过分批次生产数据分片信息,并且边生产变执行,能够有效缓解 FE 的内存开销,同时能够让分片信息的生产和执行并行执行,提升整体的执行效率。在 3.0 版本中,Doris 已经支持了 Hive 表上的该功能。在 3.1.0 版本中,进一步增加了对 Iceberg 表的批量分片执行支持。在大数据量测试场景下,可以显著降低 FE 的内存开销和查询规划时间。
联邦分析 - 连接器更好用更多样
3.1 版本重构了各个数据源的连接属性,不仅能够以更加清晰的方式对接各类元数据服务和数据存储系统,同时还支持了更加丰富的连接能力。
Iceberg Rest Catalog
3.1 版本进一步增强了对 Iceberg Rest Catalog 的支持。不仅支持了包括 Unity、Polaris、Gravitino、Glue 等多种 Iceberg Rest Catalog 后端实现,同时支持了 vended credentials 功能,能够更加安全、灵活的管理访问凭证。目前支持 AWS 平台,后续小版本迭代中将陆续支持 GCP、Azure 等云平台的凭证管理。
文档参考:https://doris.apache.org/docs/lakehouse/metastores/iceberg-rest(复制至浏览器打开)
支持 Paimon Rest Catalog
3.1.0 版本中支持基于阿里云 DLF 的 Paimon Rest Catalog,可以直接访问新版本 DLF 管理的 Paimon 表数据。
文档参考:https://doris.apache.org/docs/lakehouse/best-practices/doris-dlf-paimon(复制至浏览器打开)
多 Kerberos 环境支持
3.1 版本允许用户在同一个 Doris 集群内访问不同的 Kerberos 认证环境。不同的 Kerberos 环境可能采用不同的 KDC 服务、Principal 以及对应的 Keytab。新版本允许针对不同的 Catalog,配置不同的 Kerberos 认证信息,并且相互之间不受干扰。该功能极大的方便了拥有多套 Kerberos 认证环境的用户,可以使用 Doris 进行统一的访问管理。
文档参考:https://doris.apache.org/docs/lakehouse/storages/hdfs#kerberos-authentication(复制至浏览器打开)
多 Hadoop 环境支持
在之前的版本中,Doris 只允许用户在 conf 目录下放置一套 hadoop 集群的配置文件(hive-site.xml,hdfs-site.xml 等)。如果用户有多套不同的 Hadoop 环境和配置,则无法支持。新版本运行用户为不同的 Catalog 指定不同的 Hadoop 配置文件,帮助用户更灵活的管理外部数据源。
文档参考:https://doris.apache.org/docs/lakehouse/storages/hdfs#kerberos-authentication(复制至浏览器打开)
四、存储层构持续打磨
灵活列更新 - 数据更新全新体验
此前 Doris 的部分列更新功能要求一次导入中每一行必须更新相同的列。在一些场景下,源端系统输出的记录往往只包含主键和被更新的列,不同行更新的列可能不同。为了解决这种需求,Doris 引入了 灵活列更新 功能,使用灵活列更新可以大幅简化用户侧按列攒数据的工作以及提升写入性能。
使用方式
创建 Merge-on-Write Unique 表 时,在表属性中开启:
"enable_unique_key_skip_bitmap_column" = "true"在导入时指定导入模式:
unique_key_update_mode: UPDATE_FLEXIBLE_COLUMNSDoris 会自动完成灵活列更新与数据补齐。
示例
支持在一次导入中对不同记录更新不同的列,例如:
删除某行(
DORIS_DELETE_SIGN
)更新部分列(如
v1
、v2
、v5
等)插入新行(仅提供主键和被更新列,其他列使用默认值或补齐历史值)
效果
在测试环境下(1 FE + 4 BE,16C 64GB,3 亿行 101 列数据,3 副本行存表):
每次导入 20,000 行,仅更新 1 列(需补齐 99 列)
单并发导入性能可达 10.4k 行/s
单机资源占用:CPU ~60%,内存 ~30GB,读 IOPS ~7.5k/s,写 IOPS ~5k/s
存算分离 mow 锁优化
在存算分离场景下,MOW 表更新 Delete Bitmap 需要获取分布式锁 delete_bitmap_update_lock
。原有实现中,导入、Compaction 和 Schema Change 会竞争该锁,容易在高并发导入场景下导致长时间等待甚至失败。
本次优化包括两方面:
减少 Compaction 持锁时间
通过引入新的
mow_tablet_compaction_key
,避免多个 Compaction/Schema Change 任务在更新initiators
列表时产生不必要的事务冲突。在多 Tablet 高并发导入测试中,导入提交事务的 p99 平均耗时从 1.68 分钟降低到 49.4 秒,大幅降低了事务提交延迟。
新增配置项
delete_bitmap_lock_v2_white_list
,支持为指定仓库开启该优化。
降低导入事务长尾延迟
增加 FE 配置
mow_load_force_take_ms_lock_threshold_ms
,当导入事务等待锁超过阈值时,将强制获取分布式锁,避免长时间饥饿。在高并发导入测试下,该优化显著减少了导入事务的长尾延迟。
五、查询性能提升
分区裁剪性能和适用范围提升
Doris 支持数据按照分区组织,这些分区可以独立存储、独立查询、独立管理。通过分区,可以提升查询性能、优化数据管理,并降低资源消耗。在查询过程中,通过使用过滤条件,提前过滤无需查询的分区,可以显著提升查询性能,降低系统资源消耗。在日志数据分析系统,风控系统等使用场景中,单表可能存在万级别甚至十万级别的分区数量,而通常单词查询,只会命中百级别以下的分区数据。对于在这类数据上的查询,能否分区裁剪,对于查询性能的影响十分显著。
在 3.1 版本中,Doris 通过引入一系列的优化,显著提升了分区裁剪的性能和适用范围,包括
分区裁剪二分查找。对于在时间列上的分区,通过将分区按照列值排序,将分区裁剪的计算从线性遍历,改为二分查找。在使用 DATETIME 类型作为分区字段,13.6 万分区数的场景下。实测分区裁剪的耗时,从 724ms 提升到 43ms。提升超过 16 倍。
增加大量单调函数参与分区裁剪。在实际的使用场景中,在时间分区列上的过滤条件,通常不是简单的逻辑比较,而是在分区列上包含时间函数计算的复杂表达式。如:
to_date(time_stamp) > '2022-12-22
',date_format(timestamp,'%Y-%m-%d %H:%i:%s') > '2022-12-22 11:00:00'
等。Doris 在 3.1 版本中引入了函数单调特性描述,当函数为单调函数时,可以通过计算分区边界值是否可以被裁剪得知整个分区是否可以被裁剪。在 3.1 版本中,已经支持了 CAST 和 25 个常见的时间相关的函数。可以覆盖绝大多数常见的时间类型分区列上的过滤条件。此外,3.1 版本中,还对分区裁剪的全路径代码做了许多代码级别的详细优化,减少了不必要开销。
洞察数据特征 - 获得性能 10 倍的潜力
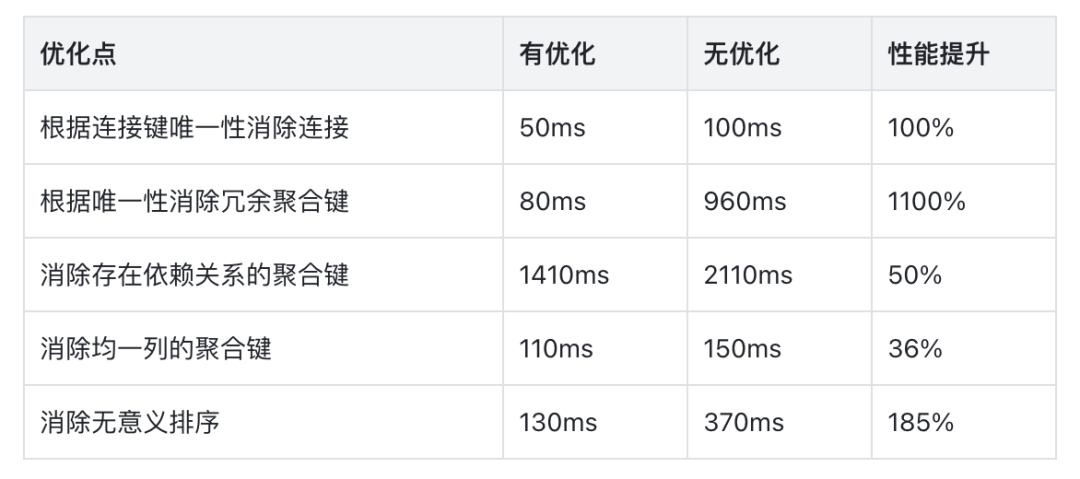
在 3.1 中,优化器可以更聪明的使用数据特征对查询进行优化。优化器会执行计划树种各个节点的收集唯一性(Unique)、均一性(Uniform),等值集(Equal Set)等数据特征,并推导列之间的函数依赖关系。当在特定的节点,数据符合特定特征时,可以移除不必要的连接、聚合或排序计算,显著提升查询性能。
在针对特定优化构建的测试用例下,利用数据特征可以获得超过 10 倍的性能提升,详见下表。
六、功能改进
半结构化
VARIANT
新增
variant_type(x)
函数:返回 Variant 子 field 对应的“当前实际类型”。新增 ComputeSignature/Helper,增强函数参数/返回类型推断能力。
STRUCT
支持使用 Schema Change 为 STRUCT 类型增加子列
湖仓一体
支持在 Catalog 级别设置元数据缓存策略,如缓存过期时间等。帮助用户根据需求灵活调整数据时效性和元数据访问性能。
文档:https://doris.apache.org/docs/lakehouse/meta-cache
支持
FILE()
表函数(Table Valued Function),该表函数是原有的S3()
,HDFS()
,LOCAL()
表函数的集合,方便用户使用和理解。文档:https://doris.apache.org/docs/dev/sql-manual/sql-functions/table-valued-functions/file
聚合算子能力增强
在 3.1 版本中,优化器重点增强了聚合算子。支持了两个使用较为广泛的能力。
非标 GROUP BY 支持
对于标准的聚合查询,要求聚合输出的标量表达式,其本身或其子树必须是聚合键。但在 MySQL 中,当设置了 SQL_MODE 不包含 "ONLY_FULL_GROUP_BY" 时,则没有次限制。
MySQL 文档详见: https://dev.mysql.com/doc/refman/8.4/en/sql-mode.html#sqlmode_only_full_group_by(复制至浏览器打开)
此时,此列输出的值为聚合键对应多行中的任意一行计算的值。举例如下:
-- 非标 GROUP BY
SELECT c1, c2 FROM t GROUP BY c1
-- 等价于
SELECT c1, any_value(c2) FROM t GROUP BY c1在 3.1 版本中。Doris 在 SQL_MODE 中默认开启 "ONLY_FULL_GROUP_BY" ,即和之前的行为保持一致。如果需要使用非标 GROUP BY 功能。则可以通过如下设置开启:
set sql_mode = replace(@@sql_mode, 'ONLY_FULL_GROUP_BY', '');
多 distinct 聚合支持
在之前的版本中,如果聚合查询中,包含多个 distinct 聚合函数,且他们的参数不一致。同时聚合函数的 distinct 语义和非 distinct 语义不一致,且不是以下之一,则 Doris 无法执行查询:
单参数的 COUNT
SUM
AVG
GROUP_CONCAT
在 3.1 版本中,Doris 对此方面进行了加强。现在这些查询可以正常执行并获取结果。例如:
SELECT count(DISTINCT c1,c2), count(DISTINCT c2,c3), count(DISTINCT c3) FROM t;
连接协议增强
开启 Proxy Protocol 协议后,依然可以通过非该协议的客户端连接。该改进在负载均衡 IP 透传场景下,方便用户更灵活的连接 Doris。
查询 VIEW 时,JDBC 的元数据接口 ResultSetMetaData#getColumnName 可以正确的返回 VIEW 中的列名
七、行为变更
VARIANT
variant_max_subcolumns_count
约束同一张表中,所有 Variant 列的
variant_max_subcolumns_count
必须“要么全为 0,要么全为 > 0”。混用会在建表 / Schema Change 时报错。新的 Variant 读写/serde 与 Compaction 路径对旧数据兼容。老版本 Variant 升级上来查询格式会产生差异(比如多一些空格、或是`。`分隔符导致层级构建,产生额外的层级)
创建 Variant 倒排索引,如果数据中所有字段不符合索引条件也会生成空索引文件,属预期行为
权限
show transcation 的权限需求从拥有 ADMIN_PRIV 权限,变更为拥有导入对应数据库的 LOAD_PRIV 权限
统一了 SHOW FRONTENDS / BACKENDS 和 NODE Restful API 的权限。现在这些接口的权限需求为拥有 information_schema 库的 SELECT_PRIV 权限。
立刻开启 3.1
在 3.1 版本正式发布之前,半结构化和数据湖的多个能力已经经过真实线上场景的验证,并获得了符合预期的性能提升。推荐有相应能力需求的用户下载尝鲜。
致谢
在此,再次向所有参与版本研发、测试和需求反馈的贡献者们表示最衷心的感谢:
@924060929 @airborne12 @amorynan @BePPPower @BiteTheDDDDt @bobhan1 @CalvinKirs @cambyzju @cjj2010 @csun5285 @DarvenDuan @dataroaring @deardeng @dtkavin @dwdwqfwe @eldenmoon @englefly @feifeifeimoon @feiniaofeiafei @felixwluo @freemandealer @Gabriel39 @gavinchou @ghkang98 @gnehil @gohalo @HappenLee @heguanhui @hello-stephen @HonestManXin @htyoung @hubgeter @hust-hhb @jacktengg @jeffreys-cat @Jibing-Li @JNSimba @kaijchen @kaka11chen @KeeProMise @koarz @liaoxin01 @liujiwen-up @liutang123 @luwei16 @MoanasDaddyXu @morningman @morrySnow @mrhhsg @Mryange @mymeiyi @nsivarajan @qidaye @qzsee @Ryan19929 @seawinde @shuke987 @sollhui @starocean999 @suxiaogang223 @SWJTU-ZhangLei @TangSiyang2001 @Vallishp @vinlee19 @w41ter @wangbo @wenzhenghu @wumeibanfa @wuwenchi @wyxxxcat @xiedeyantu @xinyiZzz @XLPE @XnY-wei @XueYuhai @xy720 @yagagagaga @Yao-MR @yiguolei @yoock @yujun777 @Yukang-Lian @Yulei-Yang @yx-keith @Z-SWEI @zclllyybb @zddr @zfr9527 @zgxme @zhangm365 @zhangstar333 @zhaorongsheng @zhiqiang-hhhh @zy-kkk @zzzxl1993
欢迎扫码添加小助手,备注“3.1”加入新版本交流专项群,还可以免费领取 Doris x AI 和 100+ 企业实践案例集,获取技术帮助、了解最新动态,并与更多开发者和用户互动。

更多标杆企业信赖
智慧金融与政企:东北证券|国金证券|国信证券|杭银消金|河北幸福消费金融|汇添富基金|金融壹账通|陆金所控股|霖梓控股|拉卡拉|平安人寿|奇富科技|同程数科|通联支付|无锡锡商银行|星云零售信贷|星火保|银联商务|易生支付|招商信诺人寿|招联金融|中信银行信用卡中心|360 数科|360 企业安全浏览器
互联网与文娱:菜鸟|抖音集团|斗鱼|叮咚买菜|浩瀚深度|京东|工商信息查询平台|货拉拉|快手|荔枝微课|票务平台|墨迹天气|MiniMax|奇安信|趣丸科技|顺丰科技|腾讯音乐|天眼查|网易|网易游戏|网易严选|网易云信|网易云音乐|小米|小鹅通|迅雷|约苗|字节跳动|知乎|360 商业化
企业服务与新经济:宝尊科技|Cisco|橙联|度言|观测云|慧策|快成物流|领健|领创|灵犀科技|名创优品|Moka BI|美联物业|钱大妈|拈花云科|森马 |思必驰|顺丰科技|上海家化 | 物易云通|云积互动|有赞|雨润集团|纵腾集团|中通快递
先进智造与电信:爱玛|长安汽车|极越汽车|金风科技|科大讯飞|Lifewit|哪吒科技|四川航空|上海通用五菱|三星电子|蜀海供应链|特步|天翼云|雅迪|中国联通

作为基于 Apache Doris 的商业化公司,飞轮科技秉承着 “开源技术创新”和“实时数仓服务”双轮驱动的战略,在投入资源大力参与 Apache Doris 社区研发和推广的同时,基于 Apache Doris 内核打造了聚焦于企业大数据实时分析需求的企业级产品 SelectDB ,面向新一代需求打造世界领先的实时分析能力。自 2022 年成立以来,获得 IDG 资本、红杉中国、襄禾资本等顶级 VC 的近 10 亿元融资,创下了近年来开源基础软件领域的新纪录。
