




面试三分钟,大黄带你冲。
今天我给大家介绍一下Redis中被问得最多的,sorted set,又简称zset。
我们先来看一下常见的面试题,暂停三秒钟,看看你可以回答出来几个,这些问题稍后都会给大家做介绍。
常见的问题
1、redis 几种基本数据结构
2、zset底层数据结构?简单说说跳表底层的数据结构?
3、什么时候采用压缩列表、什么时候采用跳表呢?
4、跳表的时间复杂度
5、简单描述一下跳表如何查找某个元素呢?
6、zset为什么用跳表而不用二叉树或者红黑树呢?
数据类型
在问跳表之前,大概面试官会问你 Redis
有哪些数据类型和底层的数据结构,这里你只需要理解这一张图即可。
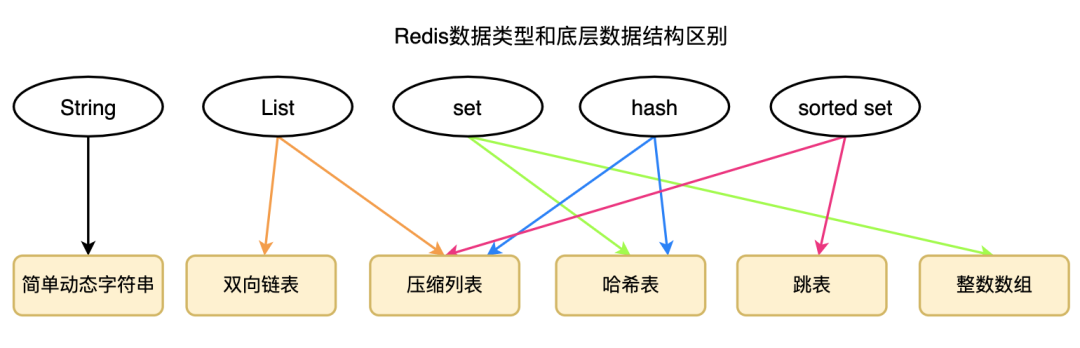
数据类型分别包括,String、List、Set、Hash、sorted Set
,每个数据类型对应的数据结构如下,
你只需要理解这张图即可,不过面试中,问得最多的是 sorted Set
。
面试官 :比如 简单说说
zset
的底层数据结构吧?
zset
底层对应的数据结构包括 压缩列表和跳表 哦,千万不要自以为只有跳表。
压缩列表
可以简单看看压缩列表的底层结构,压缩列表也比较好理解,不过压缩列表不是我们今天分享的主题。

压缩底层本质上就是一个数组。
其他的比如列表长度、尾部偏移量、列表元素个数等等,只是有利于快速寻找列表的首、尾节点。
寻找其他的元素,效率仍然没有那么高效,只能一个一个遍历了。
面试官:那什么时候采用压缩列表呢?
有序集合保存的元素数量小于128个
有序集合保存的所有元素的长度小于 64字节
跳表
掌握一个知识的三要素:What、Why、How。
面试官:什么时候跳表?
WHAT
跳表在链表的基础上,增加了多级索引,通过多级索引位置的转跳,实现了快速查找元素。
比如假设下面一个普通的链表,如果想要查找元素27,该如何查找呢?

只能从链表的头往后一步步开始遍历,这个过程中需要查找 六次 才可以找到元素27。
正是由于普通的链表太慢了,因此想要换一种结构来提升元素查找的速度。
How
跳表如何做的呢?
建立多级索引
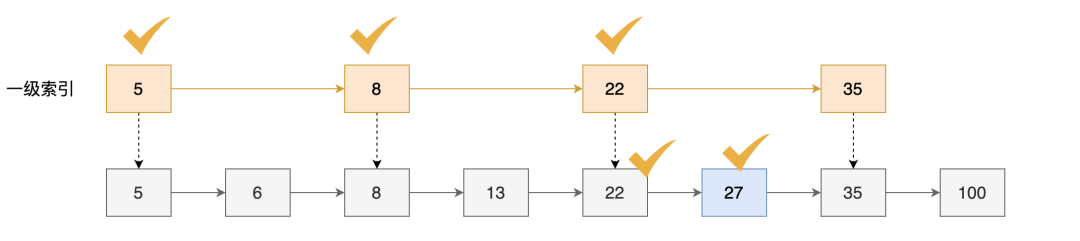
如果建立一次索引,一级索引,每隔一个元素建立一个索引,每个索引结构有一个指向下一层的 指针。

利用一次索引,我们只需要遍历5个节点,就可以寻找到元素27了。
第一次查找判断,5 < 27,并且后面的节点还比27小,继续往后寻找
第二次判断,8<27,并且后面的节点还比27小,继续往后寻找
第三次判断 22< 27,但是后面的节点比27大,则判断所需的节点在这个区间范围内,下降到下一层,则继续往后寻找
再在下一层,遍历两个元素即可找到元素27。
遍历的节点如下
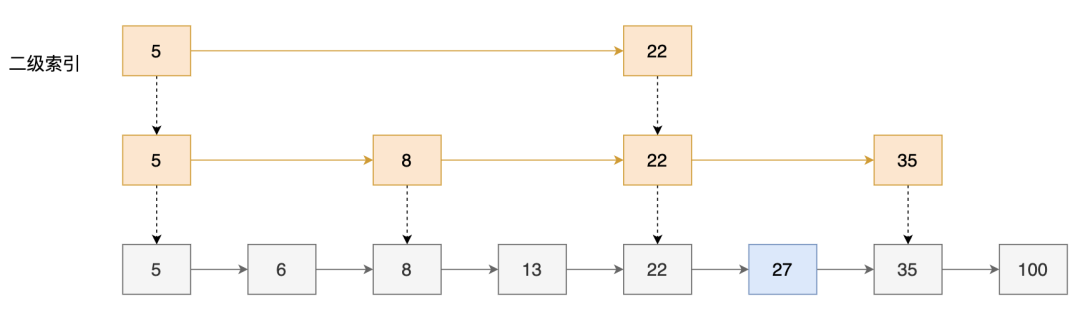
如果建立二次索引,在一级索引之上,在每隔一个元素建立一个索引节点,构成了如下的二级索引
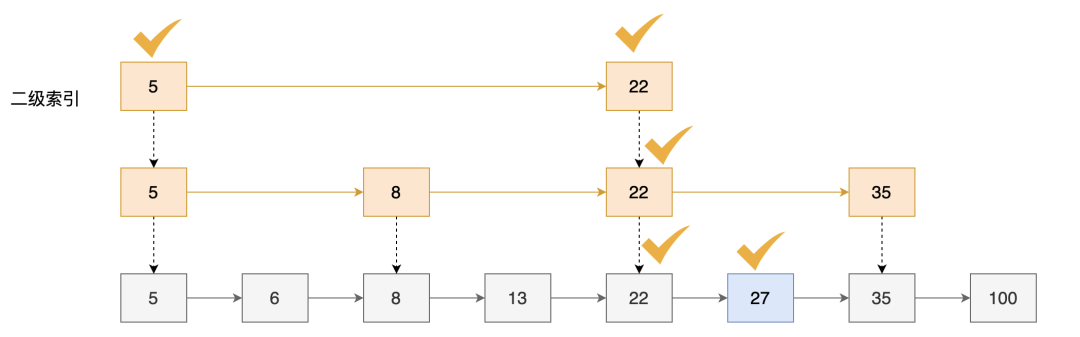
利用二级索引,我们只需要遍历 5个节点 就可以找到元素27。
第一次查找判断,5 < 27,并且后面的节点还比27小,继续往后寻找
第二次判断,22<27,后面没有元素,说明需要下降到下一级
第三次判断 22< 27,但是后面的节点比27大,则判断所需的节点在这个区间范围内,下降到下一层,则继续往后寻找
再在下一层,遍历两个元素即可找到元素27。
每次遍历节点情况如下
可能你会想,加了一级索引,遍历的节点还是没有变呐,别心急,这里是因为我的节点太少了,你可以下来试试多增加一个节点,再查找某个元素 ,看看一级和两级索引的效率如何。
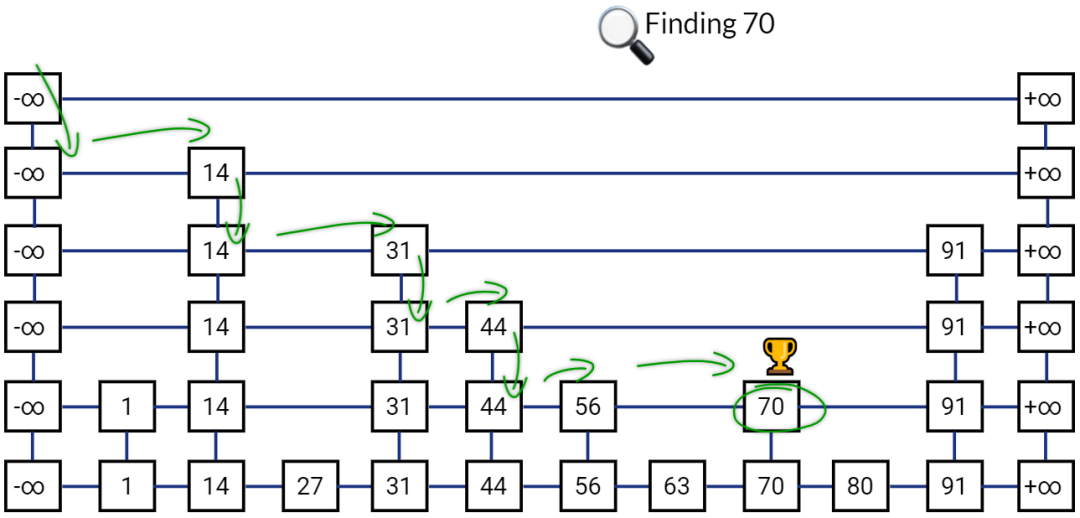
这个查找过程就是在多级索引上跳来跳去,最后定位到元素。所以叫做跳表。
当数据量很大时,跳表的查找复杂度就是 O(logN)。
我们再来看看开头说的问题三要素之一的 Why
普通链表的查找一个元素时间复杂度为 O(n),而跳表的查找一个元素时间复杂度为 O(logN),速度更快。
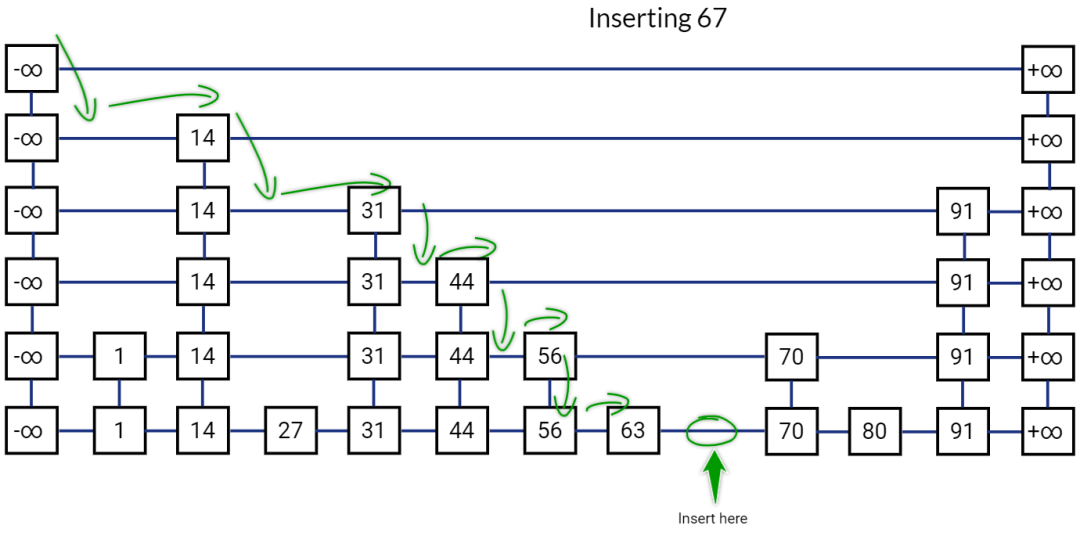
不仅如此,删除、插入元素,时间复杂度也可以降为 O(logN)
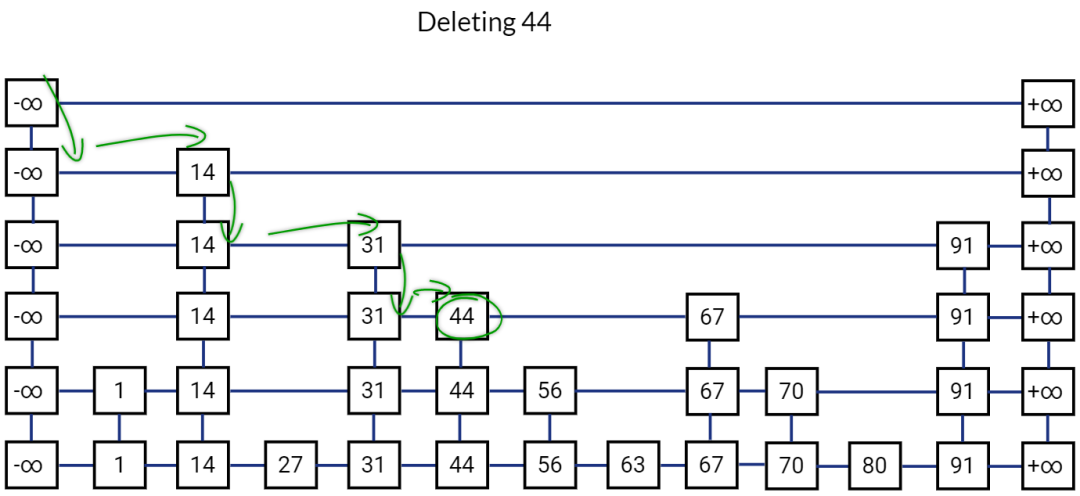
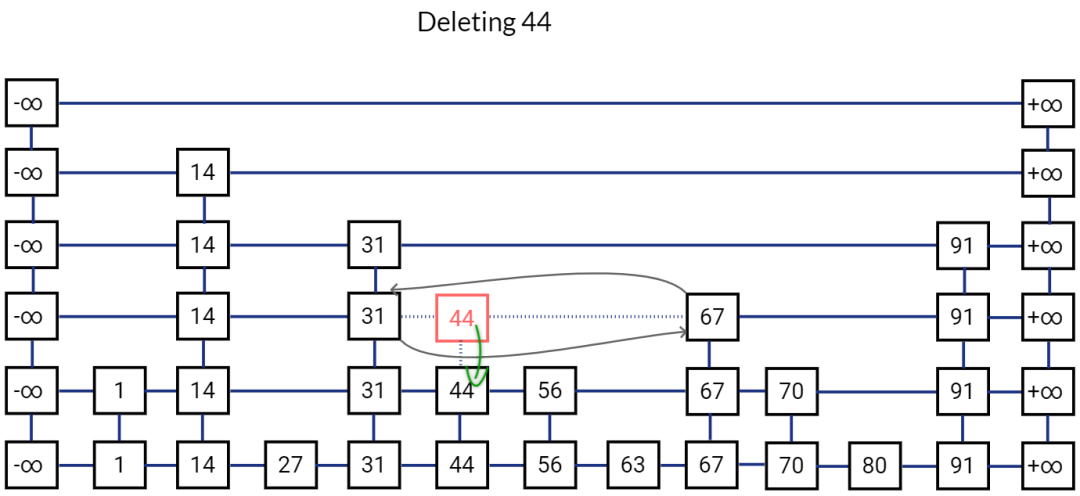
删除一个元素
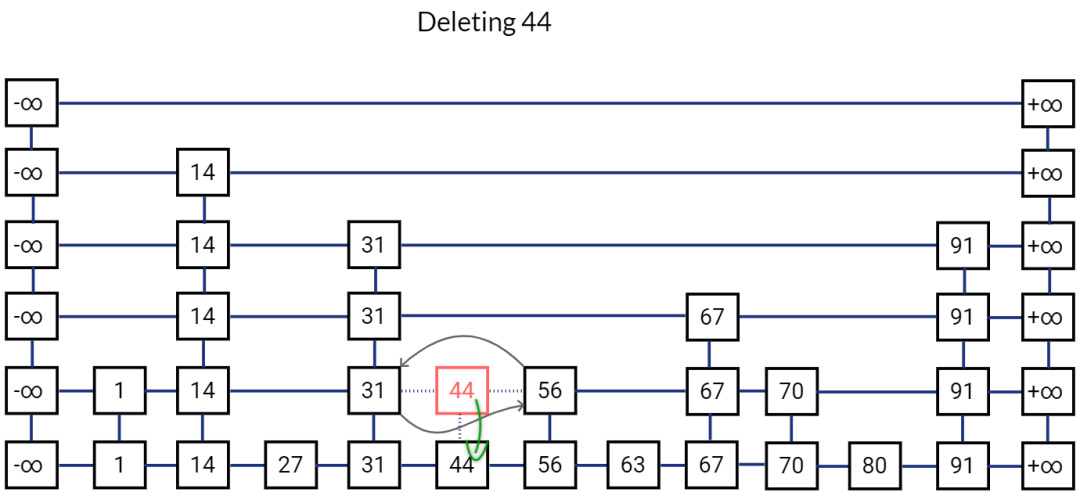
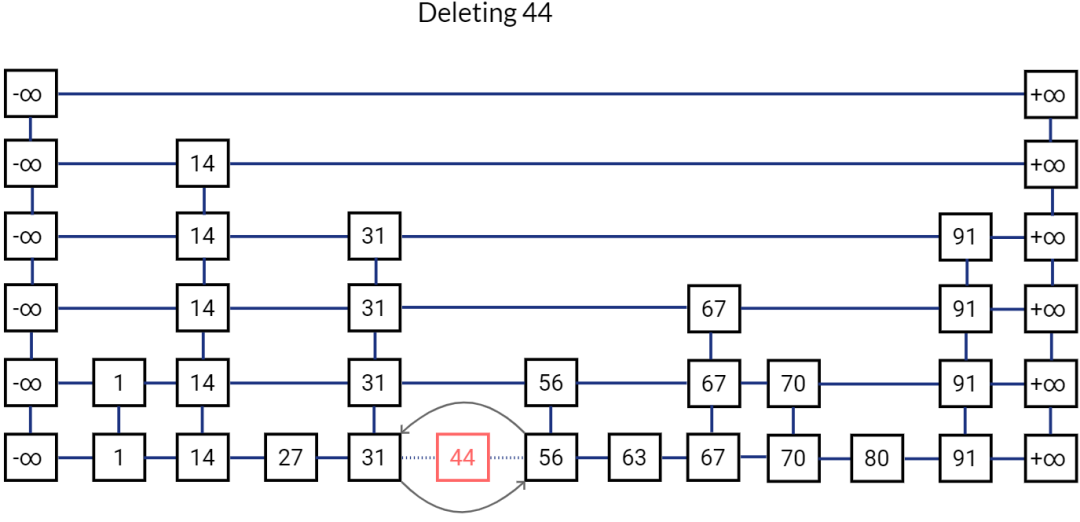

问题:可能有人会问,像二叉树或者红黑树,查找一个元素时间复杂度不也是 O(logN)吗,为啥不用树型结构呢?
原因1:
因为 zset
有一个核心操作:在某个范围内查找元素。
对于按照区间查找数据这个操作,跳表可以做到 O(logn)
的时间复杂度定位区间的起点, 然后在原始链表中顺序往后遍历就可以了。
而红黑树的范围查找效率没有跳表高。
原因2:
跳表的实现比红黑树、平衡二叉树简单许多,更容易实现。跳表比红黑树更加的灵活,可以有效的控制跳表的索引层级来控制内存的消耗。
总结
好了,关于zset 底层数据结构的问题,其实跳表本身思想和二分法类似,只不过其用于链表中。
