




DSE精选文章
PostMan: A Productive System for Spatio‑temporal Data Management and Analysis
文章介绍
方法框架
PostMan 系统的总体架构如图1所示,其主要由存储层、预处理层、计算层和应用层组成。其中存储层基于HDFS存储多源、多类型的时空数据,包括向量数据(如点、线、面)与栅格数据(如遥感影像等),并并支持可弹性扩展的对象存储(OBS);预处理层基于Apache Spark,提供数据ETL接口,将多种格式数据转换为统一的内存结构STDataset,并实现统一分区管理和两阶段静态分区,支持元数据管理、分区持久化及增量更新,提升计算效率和负载均衡;计算层支持高效时空查询(范围、kNN、连接)、矢量/栅格分析与像素级操作,提供混合索引、多种查询策略及GPU加速接口;应用层提供多级 API(Spark RDD、DataFrame、SQL),支持 Java/Scala/类SQL,并通过时空自定义函数支持Spark SQL,同时提供云端在线接口平台。
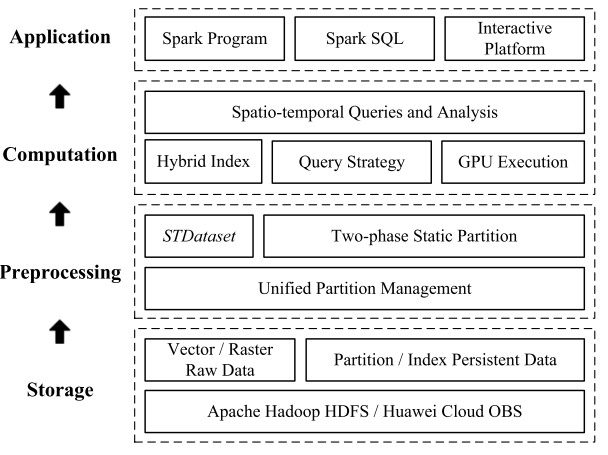
图1. 系统框架图
PostMan的数据工作流如图2所示,包括数据加载、预处理、计算和应用四个阶段,支持分区持久化和混合索引加速查询。
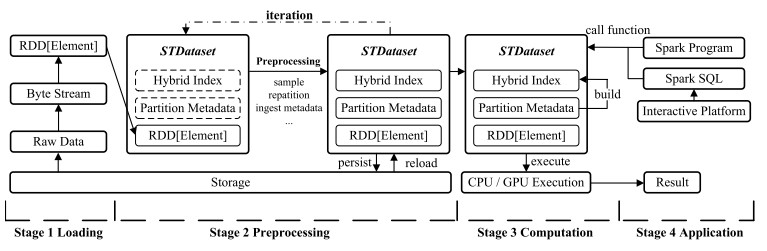
图2. 数据工作流
2. 统一分区管理与混合索引
(1)统一分区管理
PostMan在分区元数据中记录分区基本信息、统计数据等和并支持用户自定义分区元数据模式,使用灵活。其支持时空维度独立分区,提供分区持久化、重载与增量更新,并提出了一种两阶段静态分区方法以确保分区过滤前后的负载均衡。
(2)混合索引机制
PostMan的混合索引机制如图 3所示,其结合全局索引(用于快速定位分区)与本地索引(用于精确过滤分区内数据)减少不必要扫描,实现高效的谓词下推。
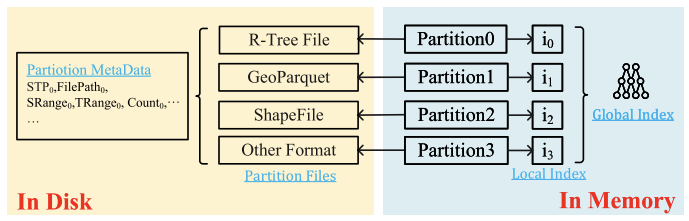
图3. 混合索引机制
3. 两阶段静态分区(TPSP)
TPSP通过两个阶段解决分布式环境下的负载均衡问题。在分区生成阶段,改进的R*-Tree算法综合考虑分区大小、记录数和计算复杂度等因素,生成均衡的数据分区;在分区分配阶段,则将问题建模为优化问题,通过贪心算法最小化分区过滤后的负载方差,确保各计算节点负载均衡。
4.GPU加速流程
PostMan提供可直接在Spark中调用的GPU-时空算子UDF,可利用GPU加速处理独立的计算密集型任务,具体流程如图4所示。
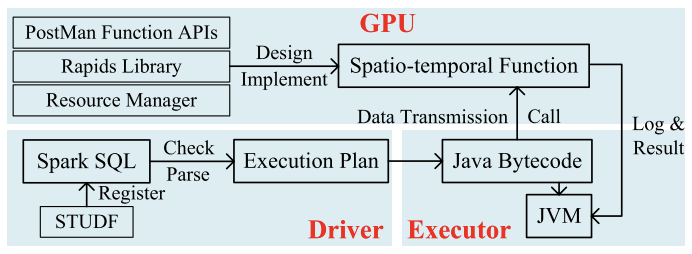
图4. GPU加速时空算子流程
实验与评估
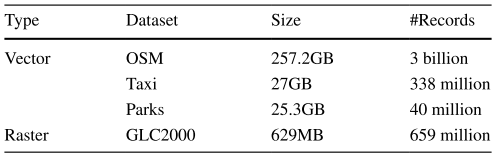
本文在多种数据集上对PostMan进行了系统评估,数据集包括OSM、Taxi、Parks以及 GLC2000等,覆盖了向量数据与栅格数据两大时空数据类型,统计信息如表1所示。
表1. 数据集统计信息
为评估PostMan的性能,本文选取了当前几种先进的分布式时空数据处理系统作为基线,包括 Simba、Sedona、Beast、GeoMesa、Simba及Geotrellis-Spark等。评估指标涵盖查询性能、可扩展性、分区负载均衡性以及 GPU 加速效果等。
(1)查询性能
在范围查询、kNN 查询、向量-向量连接、向量-栅格连接等任务中,PostMan借助统一分区管理、混合索引与过滤下推机制显著降低了数据扫描与网络传输开销。具体实验结果如图5-7所示。
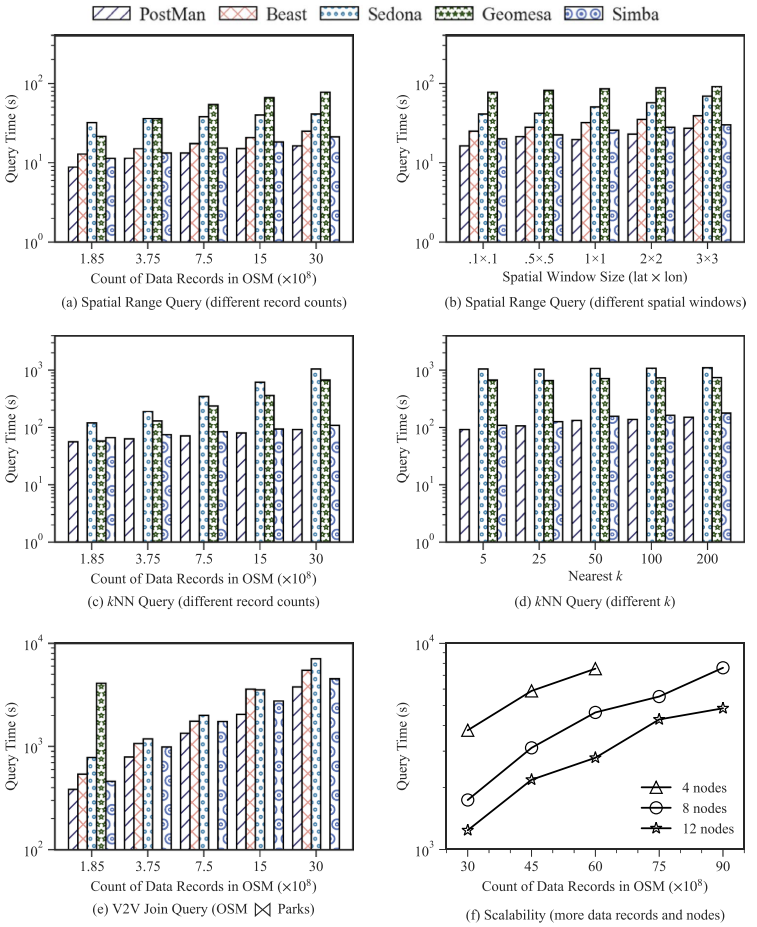
图5. 空间向量算子性能对比
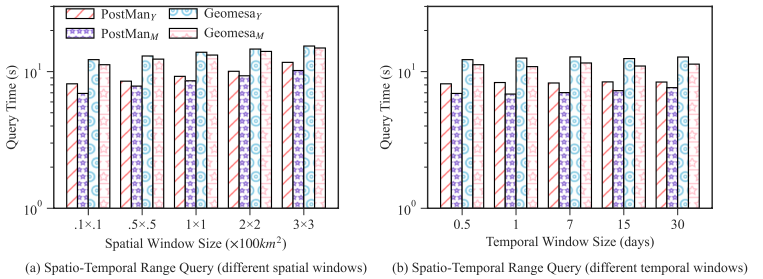
图6. 时空向量算子性能对比
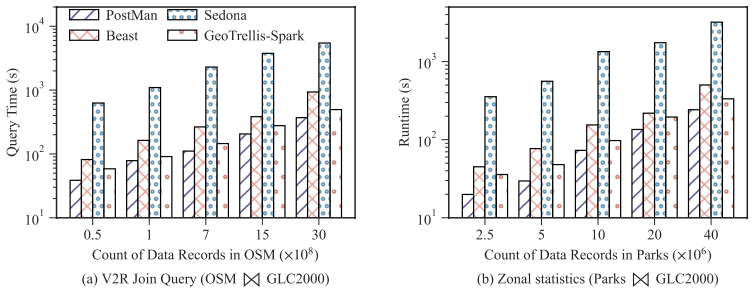
图7. 栅格算子性能对比
(2)分区负载均衡性
作者用OSM中不同的数据记录计数来评估两阶段静态分区(TPSP)方法的性能,通过重分区时间来评估重分区的成本,并通过归一化标准差对分区生成的平衡性进行了评价。实验结果如图8所示,结果表明TPSP在可接受的分区成本下有效改进了负载均衡效果。
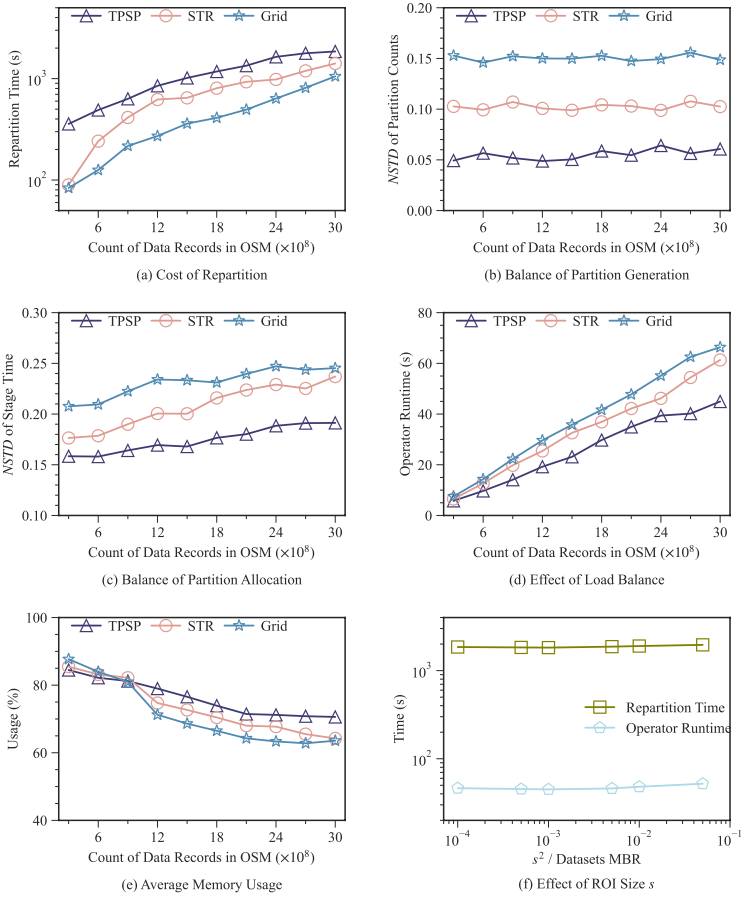
图8. 两阶段静态分区性能评估
(3)GPU加速性能
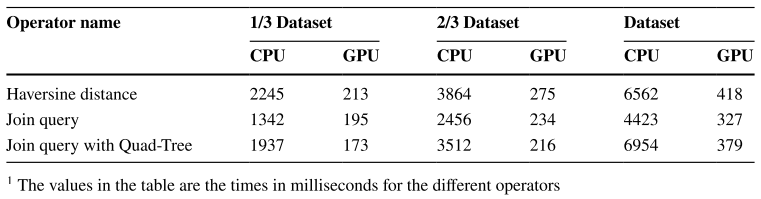
为评估GPU加速的有效性,作者在Taxi数据集上针对一些代表性算子就行了性能评估。实验结果如表2所示,结果表明集成GPU加速显著提高了系统性能,实现了约14倍的平均加速。
表2. 不同算子在GPU和CPU上运行时间的对比
结语
本文提出了PostMan——一个高效的分布式时空数据管理与分析系统,PostMan支持多类型时空数据表示、多种查询与分析方法,并具备良好的可扩展性与易集成性。此外,PostMan借助统一分区管理、混合索引、两阶段静态分区策略及GPU加速算子等策略有效提升了系统性能。在真实世界数据集上的广泛实验表明,PostMan在计算效率与负载均衡方面相较现有基线系统具备显著的性能优势(如13%-36%的提升)。
作者简介




期刊简介



