




大语言模型(LLMs)凭借强大的语言生成和推理能力,已经在数学和代码生成等许多领域取得了显著成功,然而在处理城市环境中的现实地理空间任务时,它们往往表现不佳,这种局限性源于训练过程中模型缺乏物理世界知识和相关数据。为了解决这一问题,需要提出一种新的训练框架,以增强LLMs对城市空间的理解并提高解决相关城市任务的能力。本次为大家带来数据挖掘领域顶级会议KDD 2025的文章《CityGPT: Empowering Urban Spatial Cognition of Large Language Models》。

一. 背景
近年来,大语言模型(LLMs)在聊天和代码生成等各种基于语言的场景中取得了飞速发展。多项研究表明,LLMs在广泛的任务中表现出强大的泛化能力,并在复杂任务上展现出推理能力。这些发展推动了 LLMs在不同特定领域的更广泛应用,例如金融领域的BloombergGPT。
在地理学和城市科学领域,研究人员也在探索LLMs在地理空间理解和预测等特定领域任务中的潜力。然而他们发现当任务尺度缩小到城市级别时,LLMs的表现会变得很差。例如LLMs对美国城市的位置坐标预测准确率在70%以上,但对纽约市兴趣点(PoIs)的预测准确率不足30%。研究结果表明,从在线网页文本进行训练可能会导致LLMs缺乏对城市中物理世界的详细地理空间知识。此外,现有评估在两个方面存在不足,这极大地限制了对LLMs在城市空间中效用的理解:一方面,大多数评估任务基于简单的位置坐标,但位置坐标只是空间的一小部分;另一方面,大多数评估是在全球或国家尺度上进行的,在城市尺度上的评估有限。这导致LLMs是否能真正应用于解决城市尺度的地理空间任务,以及它们是否拥有与人类相似的空间认知能力仍然未知。
因此,在本文中,作者提出了CityGPT,一个用于评估和增强LLMs理解城市空间和解决城市地理空间任务能力的系统性框架,由以下三个部分组成:
1. CityInstruction: 作者构建了一个指令微调数据集CityInstruction,它能有效增强通用LLMs理解城市空间的能力,该数据集通过一个带有真实地图的移动模拟器来构建,它模拟了人类在日常生活中探索和感知城市空间的经验。
2. SWFT (自加权微调): 作者提出了一种鲁棒的自加权微调方法SWFT,它能自动评估领域数据的质量,相应地重新加权损失,并有效增强LLMs的空间能力,同时最小化对其通用能力的负面影响。
3. CityEval: 作者建立了一个全面的评估基准CityEval,用于评估LLMs在各种城市场景和下游任务中的能力 。CityEval中的评估任务分为四组:城市意象(City Image)、城市语义(Urban Semantics)、空间推理(Spatial Reasoning)和复合任务(Composite Task)。
总的来说,文章的贡献如下:
1. 提出了第一个评估和增强通用LLMs在城市环境中空间认知能力的系统性框架。
2. 提出了一种基于移动行为模拟的指令微调数据合成方法,可以为向LLMs注入城市知识准备高质量的数据。
3. 提出了一种有效的微调方法,即SWFT,以实现鲁棒且易于使用的领域特定模型训练,而不降低模型的通用能力。
4. 提出了CityEval,一个全面的城市空间评估基准,用于评估LLMs在城市空间知识和推理能力方面的表现。
5. 在CityEval上的大量实验表明,该方法有效增强了通用LLMs的空间知识和能力。使用该方法训练后,较小的模型能够达到与顶级专有LLMs相当甚至更好的性能。
二. 方法
CityGPT的框架结构如图1所示,包括三个核心组件:CityInstruction、SWFT和CityEval。
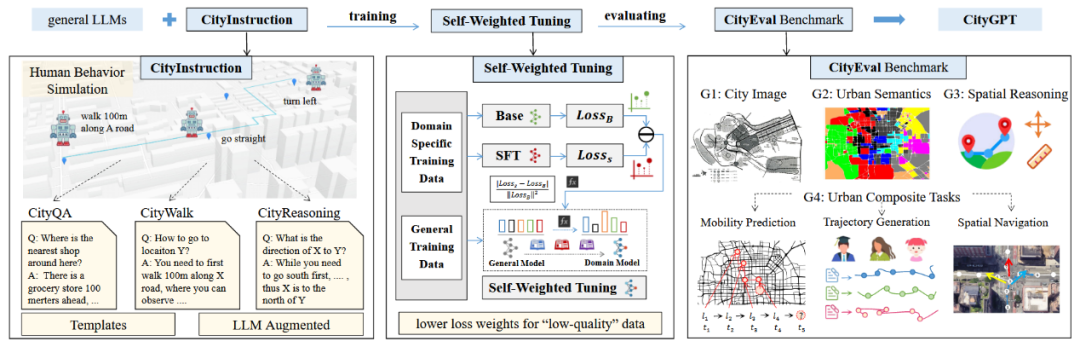
图1 CityGPT框架总览
2.1 CityInstruction的构建
正如前面所说,由于缺乏线下城市知识,通用LLMs难以解决城市规模的任务。 为了解决这一问题,一个简单的方法是直接学习城市知识,例如原始地图数据,然而为高效存储和计算而设计的原始地图数据对学习并不友好。已经有一些研究来解决这个问题,并有效地将地理空间信息和自然语言联系起来,但是效果仍然有限。
为了解决这个问题,作者重新审视了人类的空间认知机制:实际上,人类通过具身经验来感知和认识物理世界,这些经验通常以多视图数据的形式出现,产生于日常活动中,如通勤和漫步,因此作者建议模拟日常生活中的人类移动行为,以同时收集多视图数据作为模型微调的具身经验数据。例如,具身经验数据可以是:“在当前位置我能观察到什么?”,答案可能包括兴趣点(PoI)、道路、区域(AoI)等信息。
另外,城市空间中的空间推理问题在现有工作中没有被广泛研究,因为它们大多主要关注基于地理坐标的推理,然而基于地理坐标的推理与人类的空间认知机制并不一致,人类通常通过整合访问路径的近似记忆和粗略计算来进行空间推理,而不是具体的地理坐标,因此需要一种推理机制与人类认知习惯保持一致的数据集。
作者基于收集到的简单经验数据,首先为每种数据手动设计模板,然后利用 ChatGPT和精心设计的提示来扩展这些模板,使其格式更加多样化。这样就以指令的形式获得了多样化的多视图经验数据,包括 CityQA 和 CityWalk,最后通过使用手动设计的解决方案和 ChatGPT 辅助的解决方案来解决空间推理问题,构建了带有中间步骤的 CityReasoning 数据集。总的来说,三类数据集的特点如下:
1. CityQA - 单步探索: 为城市空间中的各种单一实体(如兴趣点PoI、区域AoI、道路和路口)定义简单问题。
2. CityWalk - 多步探索: CityWalk提供了与人类体验相似的城市空间具身体验,通过在模拟器中探索城市空间来构建。构建数据时,为智能体分配预定义起点和终点的任务,智能体遵循固定路径收集多步数据,包括位置之间的路线和旅途中的其他观察结果。
3. CityReasoning - 带有显式空间推理步骤的探索: 推理机制与人类认知习惯保持一致,在数据集构建过程中关注最基本的基于方向和距离的空间推理问题,首先随机选择两个位置,并获取它们的导航路径作为上下文。基于导航路径,可以生成推断方向和距离的明确推理步骤,并用预定义的模板将它们转换为指令数据的格式。
2.2 SWFT: 自加权微调
为了在指令微调阶段降低通用能力灾难性遗忘的风险,作者引入ShareGPT、AgentTuning等通用数据集。另外,作者引入地理数据集 GeoGLUE以增强地理语言理解能力,以及基于语言的空间推理数据集 StepGame和 ReSQ,以通过语言增强 CityGPT 的定性空间推理能力。
即便如此,训练后的模型在通用能力和领域特定性能上仍有下降。通过分析,作者发现了一部分“低质量”数据(图2中红色五角星区域),它们要么质量差,要么引入了与基础模型的先验分布显著偏离的全新知识。此外,训练后这些数据点的损失减少量仍然小于整个数据集观察到的平均减少量(图2虚线趋势线)。这证实了这些数据点确实是“低质量”的,它们可能会对模型学习产生较大的负面影响。
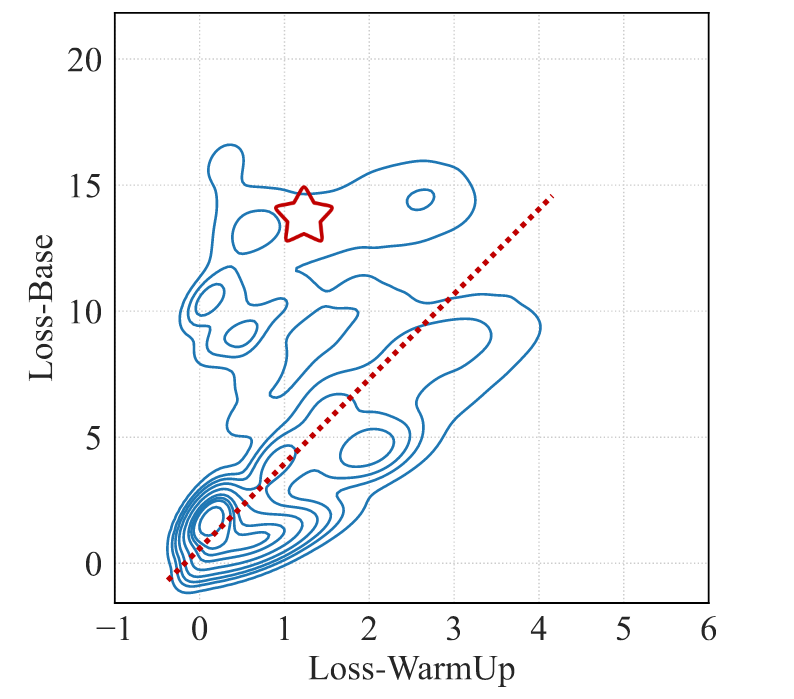
图2 训练前后的Loss变化
因此,作者提出了自加权微调(SWFT)方法,该方法利用学习动态为每个数据样本生成个性化权重,从而自适应地调整损失函数中的样本特定权重w。损失函数如下:
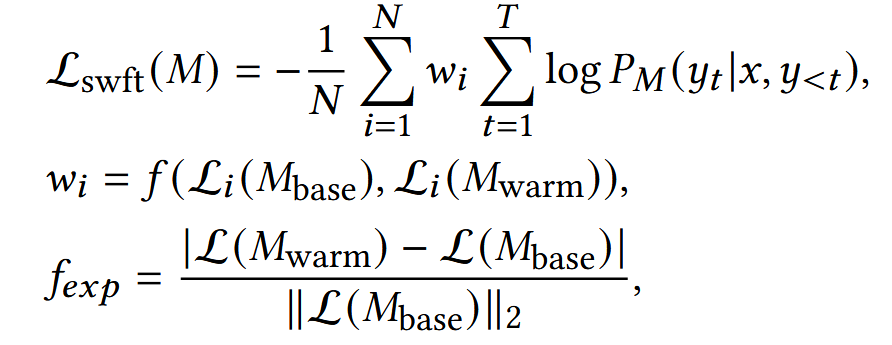
其中,权重wi是一个函数 f,它考虑了基础模型 (Mbase) 和预热训练模型 (Mwarm) 在该样本上的损失。通过这种方式,“低质量”数据将被自动分配较低的权重,使模型能更有效地关注匹配度高、质量好的数据,从而获得更好、更鲁棒的性能。
2.3 CityEval 基准测试
作者提出了一个系统性的评估基准 CityEval,以检验 LLM 在城市空间中的能力。如图3所示,评估基准包含四个子模块,强调人类空间认知的不同方面和城市科学的应用,包括城市意象、城市语义、空间推理和复合任务。
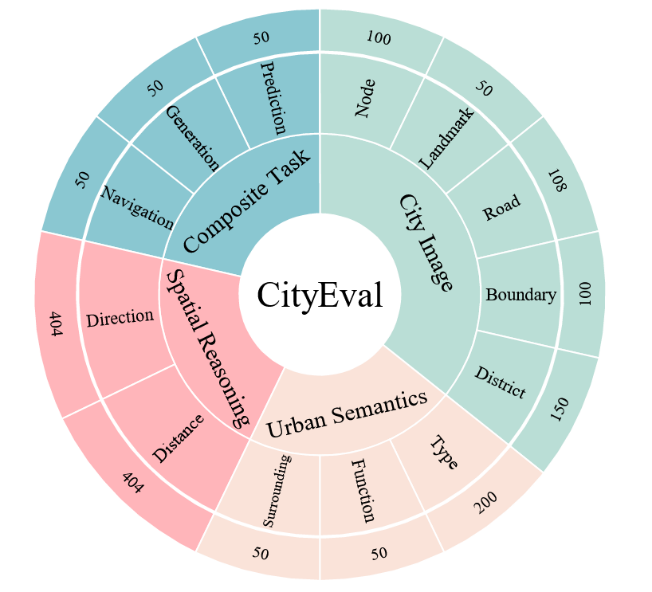
图3 CityEval的组成
1. 城市意象: 人类通常在头脑中将城市空间解构为五个基本元素的组合:路径、边界、区域、节点和标志物,神经认知科学也验证了类似的概念和机制。基于这些观察,作者提出了城市意象任务组,以评估 LLM 是否能理解这些概念并解决相关问题。在城市意象中,作者为每个元素手动设计了各种问题,例如属性和潜在关系,例如,当人们在头脑中使用路径来记住如何到达不同地点时,一个典型的问题是“你知道南苑路的起点和终点交叉口吗?”这个问题并不直接存在于指令微调数据中,模型需要从 CityWalk 的经验中学习,并通过组织其关于南苑路所有可能交叉口的记忆来回答这个问题。
2. 城市语义:与城市意象不同,城市语义关注城市环境中发生的人类活动,并评估理解城市功能的能力。 作者将城市语义的任务定义为在给定PoI分布的情况下推断区域的功能,以及环境中很可能缺失的PoI。 例如,关于推断区域功能的问题可以是:“Y 区域有 PoI A、PoI B、PoI G,Y 区域的潜在功能是什么?”。
3. 空间推理:与前两个更多要求记忆和关联分析能力的任务相比,作者引入了空间推理任务组来评估定量推理和空间认知的能力,这对 LLM 来说更具挑战性。 空间推理的设计与 CityReasoning 中的方法十分类似。
4. 城市复合任务:最后,作者引入了复合任务组,包括移动性预测、轨迹生成和空间导航,用于评估 LLM 在城市空间中的整合能力,这些任务需要 LLM 结合多种能力来理解城市环境和人类行为才能完成。
三. 实验
3.1 实验设置
除了文章提出的 CityEval 基准,作者还使用通用基准评估模型,包括用于评估通用知识能力的 MMLU,用于评估数学能力的 GSM8K,以及用于评估常识推理能力的 BBH。作者选择了北京、伦敦、纽约和巴黎,并在这些城市的整个地理区域进行实验,并将基线模型分为三组:小型开源模型(如ChatGLM3-6B, Qwen2.5-7B, Llama3-8B),大型开源模型(如LLama3.1-405B)和商业APIs(如GPT-3.5, GPT-4omini)
3.2 在CityEval上的表现
在CityEval上的实验结果如表1所示。总体而言,CityGPT-Qwen2.5-7B在大多数任务中显著优于所有基线模型,与最佳基线模型相比,CityGPT-Qwen2.5-7B在具有挑战性的空间推理任务中性能提升了33.33%。与它自身的原始版本Qwen2.5-7B相比,在城市语义任务中至少提升了5.68%,在空间推理任务中提升了236.59%。这些结果展示了CityInstruction数据集的有效性,并且充分证明了CityEval评估基准能够有效区分不同模型在理解城市空间上的能力。
表1 在CityEval上的实验结果
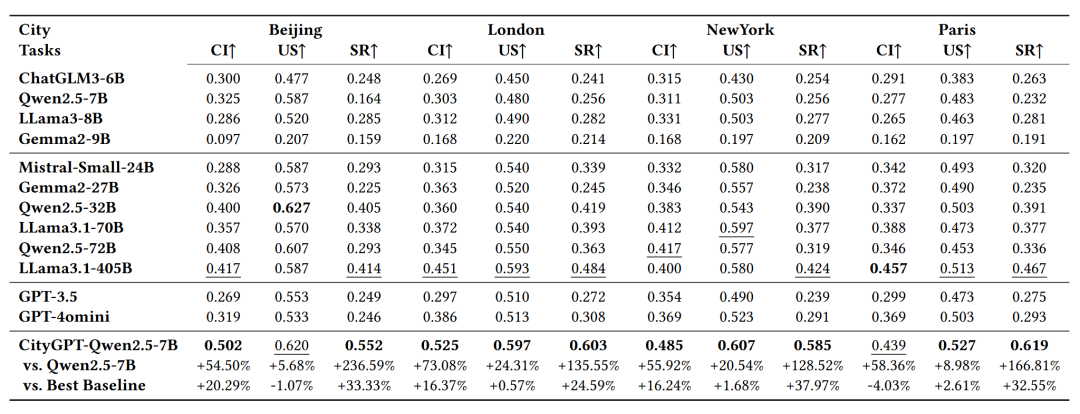
表2展示了基于不同基础模型训练的CityGPT的性能,这表明 CityGPT 模型在通用能力方面通常与基础模型相当。
表2 在通用基准评估模型上的实验结果
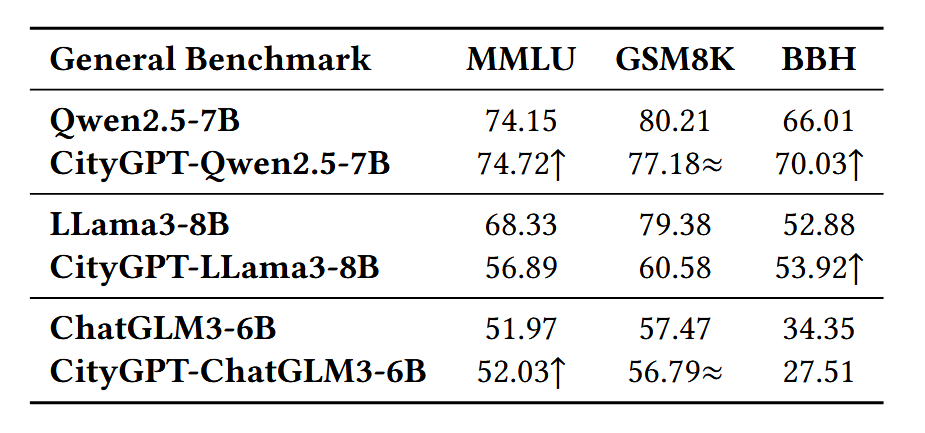
然而,实验结果表明CityGPT-LLama3-8B 在 MMLU 和 GSM8K 上有显著下降,CityGPT-ChatGLM-6B 在 BBH 上也有下降。作者使用之前提到的SWFT来解决这些问题。
作者使用 LLama3-8B 进行了关于SWFT的探索性实验,该模型在通用能力上下降最大。 如图4(a)所示,SFT-CityGPT 的损失范围明显窄于基础模型,表明微调过程的有效性,同时,从图4(b)可以观察到 SWFT-CityGPT 在 CityEval 和通用基准测试上都比 CityGPT-SFT 显著提高了性能,这证明了SWFT 方法的有效性。
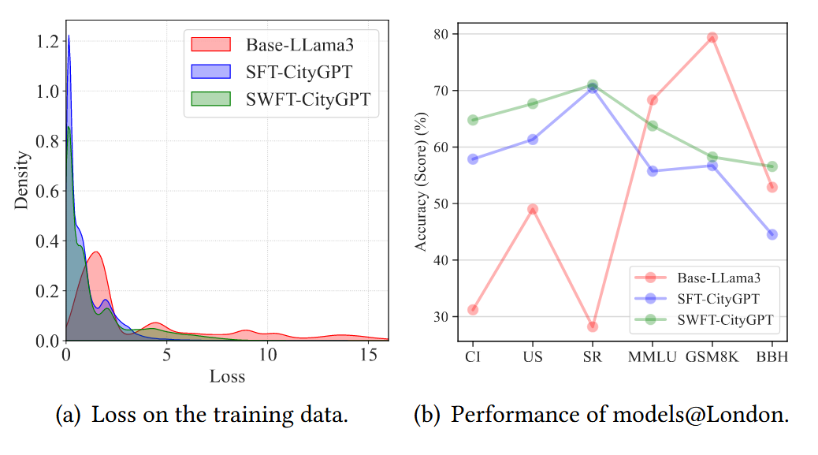
图4 SWFT的实验结果
然而同样明显的是,与 Base-LLama3 模型相比,CityGPT-SWFT 在GSM8K任务上仍然有所下降,这个结果表明文章提出的训练策略帮助模型在较简单的任务上保留了其通用能力,但要在更具挑战性的基准测试上维持同等性能,仍需进一步改进。
3.4 可迁移性和下游任务适用性
文章评估了CityGPT在空间知识和推理能力上的可迁移性。结果(表3)显示,在北京数据上训练的CityGPT在其他三个不同城市的CityEval评估中显著优于基础模型,这表明CityGPT确实学到了可以跨城市迁移的通用城市空间认知知识。在下游复合任务中(表4),CityGPT在没有任何与任务相关的指令数据训练的情况下,在移动性预测、轨迹生成和街道导航这三个任务中均显著优于ChatGLM3-6B,证明了CityGPT能够提高下游任务的性能。
表3 不同城市的CityEval评估结果
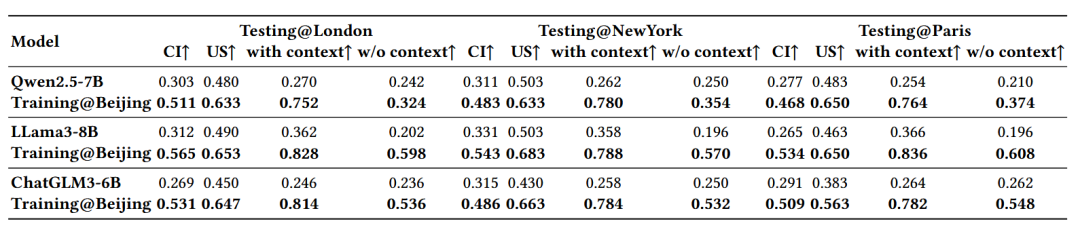
表4 下游任务评估结果

3.5 对于训练数据的消融实验
作者使用消融实验研究了CityInstruction中数据构成的影响,如图5所示,随着使用的数据量增多,所有任务的性能都得到了提升。
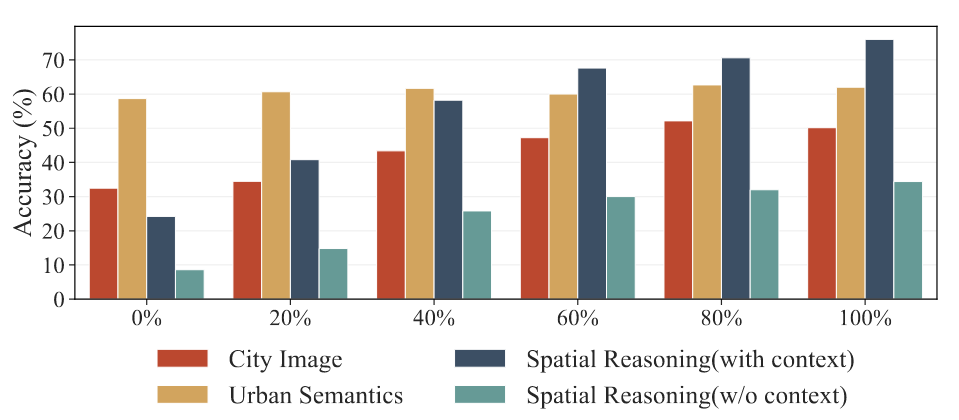
图5 不同数据量下CityGPT的表现
如表5所示,与在简单的静态城市知识上微调LLMs相比,使用CityInstruction训练的CityGPT表现更优,图6表明使用所有数据进行训练时取得了最佳性能,表明CityInstruction对多种数据集类型进行混合是取得优异结果的关键。
表5 CityInstruction与常规训练数据的实验结果
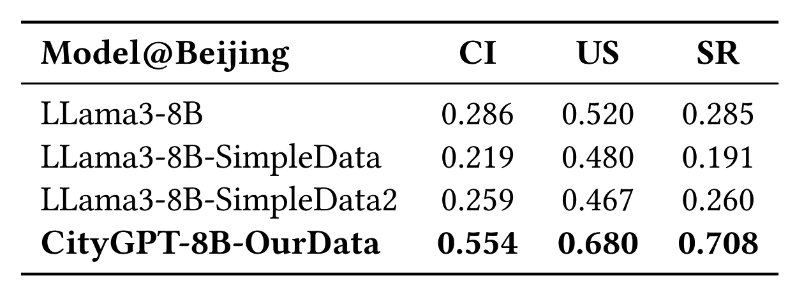
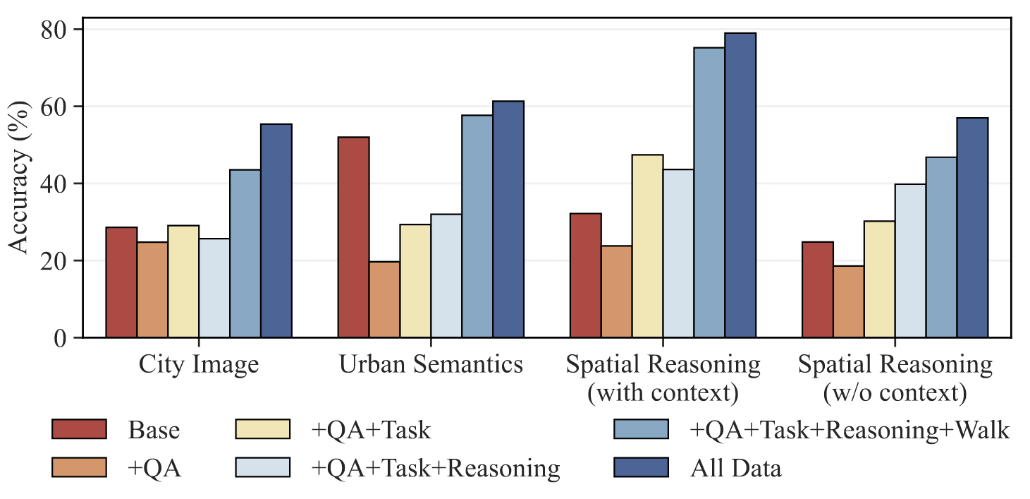
图6 不同数据集组成下CityGPT的表现
四.总结
在本文中,作者提出了一个用于评估和增强LLMs理解城市空间及解决相关城市任务能力的系统性框架。具体来说,作者构建了CityEval基准以全面评估LLMs的能力,并通过模拟人类空间经验构建了CityInstruction数据集来增强小型LLMs的能力。最后提出了SWFT方法,将数据质量纳入损失函数,以在增强领域特定能力的同时缓解遗忘问题。
-End-
 |

图文|高研盛
校稿|徐小龙
编辑|周钦钦
审核|李瑞远
审核|杨广超
