




互联自动驾驶车辆(CAVs)轨迹数据的压缩是轨迹数据存储和传输的基础。在CAVs的大多数应用场景中,每个CAV都会收集的数据为自动识别自己的位置、速度和加速度,并通过无线通信范围与其他CAV和路旁单元(RSUs)交换这些数据。这些轨迹数据以高频方式收集和交换。因此,CAV的轨迹数据量是巨大的。这对CAV和RSUs的数据存储和传输都提出了挑战。对轨迹数据进行压缩是在保留数据价值的同时解决这一挑战的有效方法。CAV轨迹数据无损压缩的典型算法包括运动学-运动预测辅助算法、差分编码、BCD编码和算术编码。将这些无损压缩算法有效集成起来是一个很好的提高压缩率和减少压缩时间的办法。本次为大家带来智能交通领域顶级期刊TITS 2024的文章《Compressing Vehicle Trajectory Data Using HybridCoding With Kinematic Motion Prediction》。

一. 算法介绍
1.1 差分编码
差分编码通过计算和保存相邻时间步长的数据点之间的差异,而不是原始数据点,来减少数据存储空间。因为这种差异的长度小于原始数据。Subhra J. Sarkar等人提出了一种差分编码算法,用于压缩与电力系统相关的数据。Jong-hak Kim提出了一种用于高分辨率视频数据的差分编码算法。该算法的压缩率达到18-26%。在航空航天领域,Xuesen Shi等人结合了差分编码算法和聚类算法来进行数据压缩。
1.2 BCD编码
BCD编码将十进制数转换为相同长度的二进制数,以便数据在解压缩后能够正确重现。由于字符序列中数据点的长度可能不同,如果没有BCD编码,计算机无法区分一个数字属于哪个数据点。对于车辆轨迹数据压缩,P. Cudre-Mauroux等提出了一种集成了BCD编码的差分编码算法,名为TrajStore。此外,还将距离小于给定阈值的轨迹进行聚类,仅存储聚类中的一条轨迹。然而,这种方法是一种有损压缩方法。此外,TrajStore不适合与算术编码集成,因为相邻数据点之间的很多差值不是零。在这种情况下,通过算术编码获得的小数的有效位数很大,所需的存储空间也很大。
1.3 算术编码
算术编码的核心思想是将一个字符序列表示为一个从区间内随机选择的十进制数。该区间根据字符的顺序和每个字符出现的概率来确定。香农提出了一个早期的算术编码算法。该算法通过按照字符出现概率的降序对字符进行排序,并使用每个字符的累积概率的二进制值作为编码结果来压缩字符序列。David Barina提出了一种通过使用算术编码和字典编码的无损压缩算法。
1.4 运动学辅助的车辆轨迹数据压缩
运动学运动预测是指基于某些时间步的测量值,预测车辆在这些时间步之后的位置、速度和加速度。通过这样做,仅保存先前时间步的测量值和与运动学运动预测相关的方程,而不是所有时间步的测量值。Rajamani提出了一个运动学运动预测模型,该模型假设车辆的速度和加速度在每个时间间隔内是恒定的。Lovell将这种运动学运动预测与差分编码算法相结合。这种方法能够实现13:1的压缩率。然而,在这一假设下,存储预测值与原始值之间的差值仍然需要大量空间,因为运动学运动预测的许多误差并非为零。这些误差也导致了将预测与由差分编码、BCD编码和算术编码算法组成的混合编码算法相结合所带来的收益有限。Kang等人提出了一种结合神经网络的图像无损压缩算法。与Lovell 提出方法中使用的运动学运动预测模型相比,LSTM神经网络实现了该假设,并且更擅长预测车辆轨迹。
所以本文的主要贡献和研究是:提出了一种使用LSTM的运动学运动预测模型FC-LSTM预测模型,以提高预测精度和压缩性能,并减少预测时间;开发结合差分编码、BCD编码和算术编码算法的混合编码算法并结合改进的运动预测模型与混合编码算法,进一步提高压缩性能。
二. 基于LSTM的运动预测
使用LSTM的运动学运动预测有利于车辆轨迹数据压缩。因为通过保存预测值和原始值之间的差异,可以显著减少保存数据所需的空间。该预测利用了轨迹数据的两个特征。以下将分别介绍位置数据、速度数据和加速度数据的预测方法。
2.1 车辆位置预测
由于NGSIM数据集中全局x坐标数据、全局y坐标数据、局部x坐标数据和局部y坐标数据具有相同的特征,本节将以局部x坐标数据为例,介绍这四种数据的预测模型。对于NGSIM数据集,全局坐标是在NAD83的CA状态平面坐标系中定义的。全局y坐标轴定义为与通过最西端位置的经度重叠的线。全局x坐标轴定义为与通过最南端位置的纬度重叠的线。原点定义为全局y坐标轴和全局x坐标轴的交点。局部y和x坐标轴系统分别由相机组视场的左边线和下边线定义。原点定义为两条边线的交点。
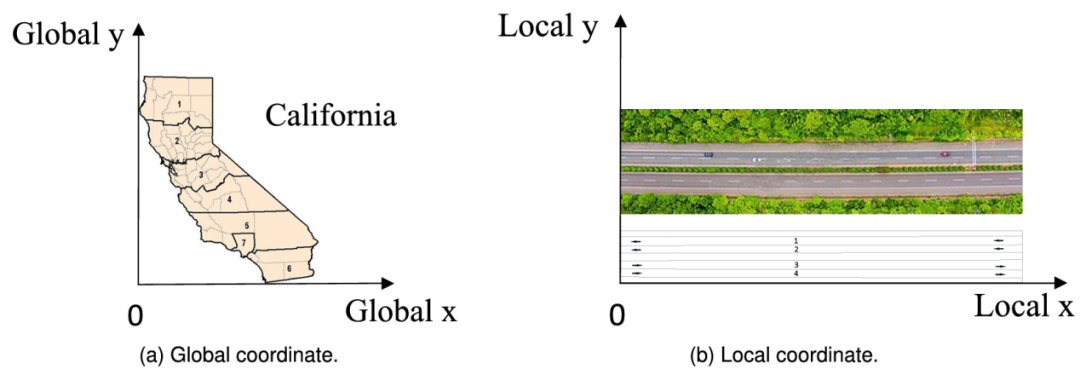
图1 全局坐标与局部坐标的比较
图1分别展示了全局坐标和局部坐标的一个示例。给定一个点P(localx, local y)在局部坐标轴系统中,点P在全局坐标轴系统中的全局坐标可由式(1)和式(2)求得:
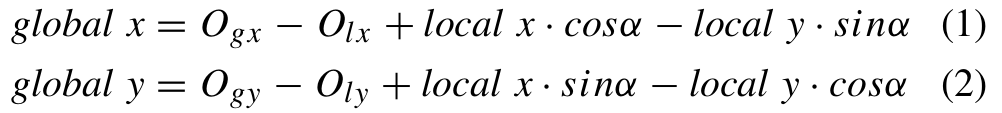
其中,Ogx和Ogy分别是全局坐标轴系原点的x坐标和y坐标;Olx和Oly分别是局部坐标轴系原点的x坐标和y坐标;α是旋转角度。这些参数由相机的位置决定。
局部坐标系可应用于任何情况。当数据采集区域较大时,地球曲率会导致基于局部坐标系的速度预测产生显著误差。对于NGSIM数据集,地球曲率的影响可以忽略不计。因此,局部坐标系和全局坐标系都可用于运动学运动预测。vt、st和st−1之间的关系由公式(3)描述:
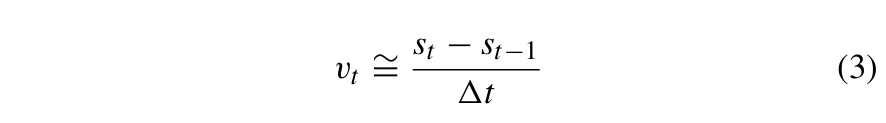
其中vt为t时刻的速度,st和st−1分别为t时刻和t−1时刻的局部x坐标,∆t为t与t−1之间的时间间隔。根据式(3),连续三个时间步长的局部x坐标之间的的关系可以用公式 (4) 描述:
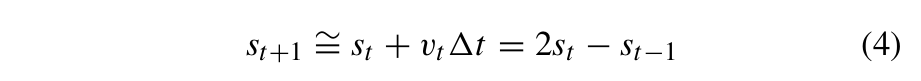
其中st+1为t + 1时刻预测的局部x坐标。
由式(4)可以看出,只要保存前两个时间步的局部x坐标以及预测值与其他局部x坐标原值的差值,就可以在解压缩时完全再现所有的局部x坐标。
2.2 车辆速度预测
车辆速度是使用全连接LSTM(FC-LSTM)进行预测的。FC-LSTM的结构如图2所示。FC-LSTM由输入、遗忘门、输入门、输出门、记忆单元和输出组成。
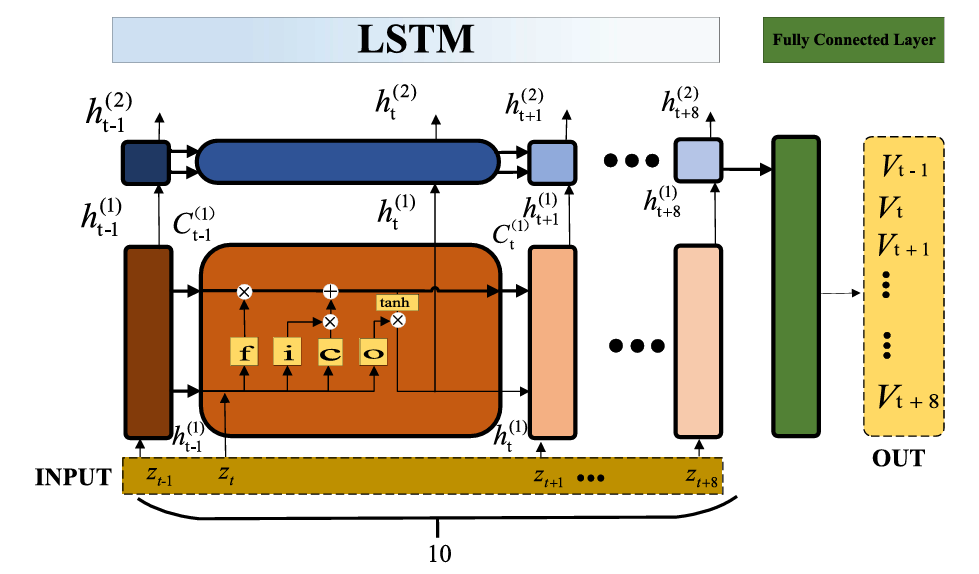
图2. FC-LSTM运动学运动预测模型的结构
FC-LSTM 的输入 Zt 是一个包含10个时间步长的序列。选择 10 个时间步长是为了平衡预测准确性和预测速度。考虑到车辆的运动学特性,前一个时间步长、当前时间步长和下一个时间步长的位置被选为每个时间步长的特征。FC-LSTM 的输入由公式 (5) 和 (6) 定义:
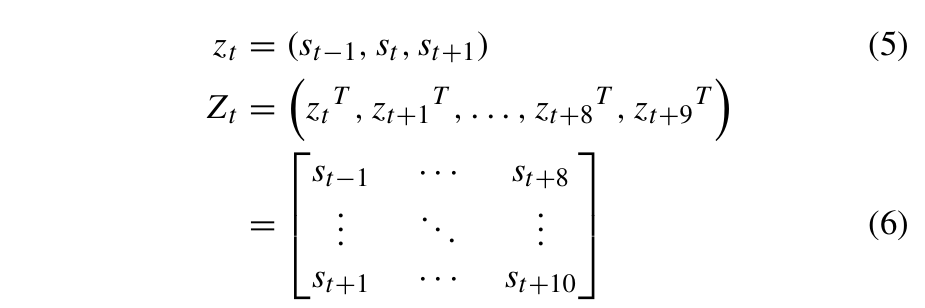
遗忘门、输入门、输出门从当前时间步的输入和前一时间步FC-LSTM的输出中选择有用的信息。当前时间步遗忘门、输入门、输出门的状态,即ft、it和ot,由公式(7)-(9)定义:
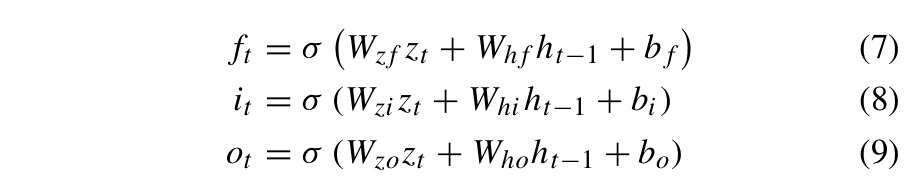
其中σ是sigmoid激活函数,WZf、Whf和bo分别是遗忘门中Zt、ht−1的权重和偏置。WZi和bi分别是输入门中Zt、ht−1的权重和偏置。Wzo、Who和bo分别是输出门中Zt、ht−1的权重和偏置。
记忆单元Ct从多个过去时间步和当前时间步的遗忘门和输入门中选择有用的信息。它通过公式(10)进行更新:
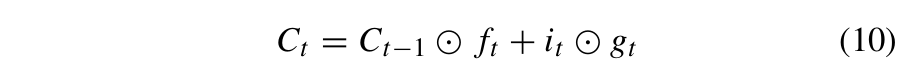
其中 ⊙ 表示 Hadamard 积,而gt是单元输入激活向量。gt 由公式 (11) 定义:
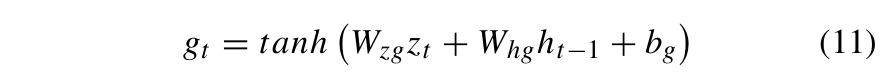
其中WZg、Whg和bg分别是细胞输入激活向量中Zt、ht−1的权重和偏置。
此时刻的输出由公式 (12) 计算得出:
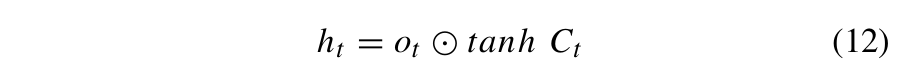
输出ht是一个10*10矩阵。为了预测连续10个时间步长的速度,它被重塑成一个1*10的向量。这是通过用一个有10个神经元的全连接层来处理它来实现的。FC-LSTM的输出由式(13)计算:
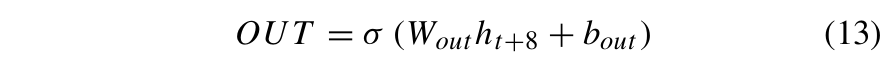
总结来说,预测车辆速度的步骤为:首先计算车辆位置。车辆位置s计算为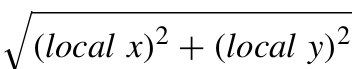 ;然后进行车辆速度,预测每10个连续时间步长的车辆位置被分组为一个向量,这些向量作为FC-LSTM的输入;最后进行预测速度修正,如果预测速度为负,则将其设置为 0,如果预测速度大于最大实际速度,则将其设置为最大值。
;然后进行车辆速度,预测每10个连续时间步长的车辆位置被分组为一个向量,这些向量作为FC-LSTM的输入;最后进行预测速度修正,如果预测速度为负,则将其设置为 0,如果预测速度大于最大实际速度,则将其设置为最大值。
而预测加速度的方法与预测速度的方法类似。主要的区别在于前者基于车辆速度,而不是车辆位置。
三. 混合编码算法
用于压缩CAV轨迹数据的混合编码算法充分利用数据的特性增强压缩性能,将位置数据、速度数据和加速度数据分别进行压缩。
3.1 车辆位置数据压缩
车辆位置数据的压缩算法建立在其时空分布的基础上。由于车辆的物理条件限制,局部 x 坐标的变化不会突然改变。这样可以利用位置数据的连续性和预测模型的准确性减少存储需求。
论文将其拆分为首个位置点、第二个位置点、其余位置点三类分别编码,原因是这三类点在解码中作用不同,信息冗余度也不同。
1)首个位置点:首个局部x坐标的数据通过一阶差分编码进行压缩。具体而言,为了将初始局部x坐标Xlocalstart表示为整数,它们乘以1000。通过使用差分编码,从所有初始局部x坐标Xlocalstart中减去最小值Xlocalstart,min,从而获得偏移局部x坐标序列X′localstart。由于初始位置之间的数据差异小,差分编码在初始位置数据的压缩上效果很好。存储偏移量序列的最短二进制位长WLlocalstart按式(14)计算:
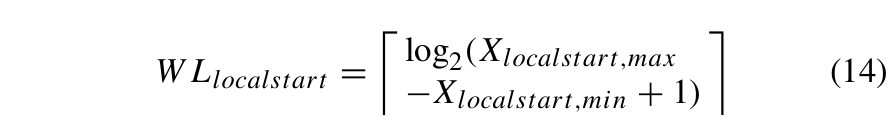
其中 Xlocalstart,max 是偏移序列中的最大值,而⌈•⌉是向上取整运算符。最短二进制位长度是指存储 X′localstart 的最大元素所需的二进制位长度。最短二进制位长度用于存储X′localstart 的每个元素。这使得用于存储X′localstart 的元素的二进制位长度相同,并且可以正确解码X′localstart。局部 x 坐标序列的最小值 Xlocalstart,min、偏移局部 x 坐标序列 X′localstart 和最短二进制位长度WLlocalstart均使用BCD编码存储。
相应的,经过BCD编码变换的数所需要的二进制位长度由式(15)计算:
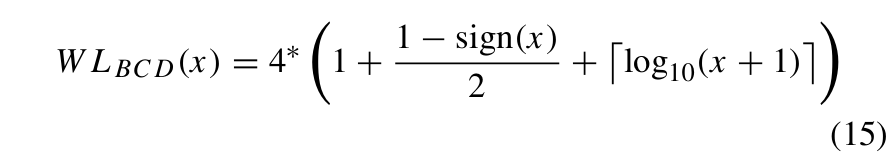
其中 x 是车辆位置或速度的数据,sign(x) 在 x 为正时为1,在 x 为负时为−1。
2)第二个位置点:第二车辆位置数据的压缩:车辆的第二个局部x坐标 Xlocalsecond 的数据也通过一阶差分编码进行压缩。在乘以1000后,初始局部x坐标 Xlocalstart 和第二个局部x坐标 Xlocalsecond 之间的差值序列 XlocSt−Se,XlocSt−Se,以最短的二进制长度 WLlocSt-Se 存储。
3)其余位置点:其他局部x坐标的数据使用二阶差分编码进行压缩。具体而言,与轨迹相关的一阶偏移局部x坐标序列Xlx,diff是通过从其预测的局部x坐标中减去所有实际的局部x坐标来计算的。为了进一步压缩数据,二阶偏移局部x坐标X′lx,diff是通过从Xlx,diff中的Xlx,diff中减去最小Xlx,diff,min获得的。最小值Xlx,diff,min通过BCD编码进行压缩,而X′lx,diff通过算术编码进行压缩。通过算术编码获得的浮点数通过乘以10N转换为整数,其中N是浮点数的精度。整数被转换为二进制数以进行保存和传输。通过算术编码获得的浮点值对于不同的数据集可能具有不同的精度N。即便如此,这并不影响所提出算法的适用性。在压缩过程中,当使用算术编码将浮点值转换为二进制数时,会在最后一个二进制位上添加一个空格。因此,浮点值可以被正确解压缩。
算术编码适用于压缩由许多相同字符组成的数据。因为在这种情况下,通过算术编码获得的十进制数的小数位数很少,因为经过前面处理之后得到的整数序列分布高度集中。
总结来看,局部x坐标数据压缩的伪代码如算法1所示:

图3 局部x坐标数据压缩算法
其中 X 指的是NGSIM数据集中所有车辆的局部x坐标矩阵。xij 是指ith个车辆在ith个时间步的位置。为了说明目的,在算法1的描述中,X被分为 XStart , XSecond , XOthers。他们分别指所有车辆的初始、第二个和其他局部x坐标。
3.2 车辆速度数据压缩
对位置数据的统计表明,位置数据的每个初始位置之间的差异很小。为了利用此特性,可以通过差分编码进一步降低压缩率。然而,对于速度和加速度数据,此特性并不明显。车辆速度数据的压缩是基于速度的预测。预测的车辆速度乘以1000,以便将所有数据转换为整数。因为存储整数比存储小数需要更少的空间。一阶偏移速度序列Vdiff计算为预测速度和实际速度之间的差值。偏移速度序列V′diff是通过从所有Vdiff中减去Vdiff,min而获得的。用于存储Vdiff,min的最短二进制位长度WLV,diff,min的计算类似于Xlocalstart的计算,并且Vdiff通过使用算术编码来存储。
3.3 车辆加速数据的压缩
压缩车辆加速数据的方法与压缩车辆速度数据的方法类似。所提算法的不同关键模块之间的关系总结如图4所示。该算法可用于压缩从相机、GPS、惯性导航系统(INS)、激光雷达(LiDAR)和毫米波雷达等设备中提取的轨迹数据。尽管在拟议的系统中使用的不同传感器所获取的数据的性质可能不同,但这些数据被转换为文本格式并输入到拟议的算法中。但是,所提出的算法不能用于将各种设备收集的数据转换为文本格式。
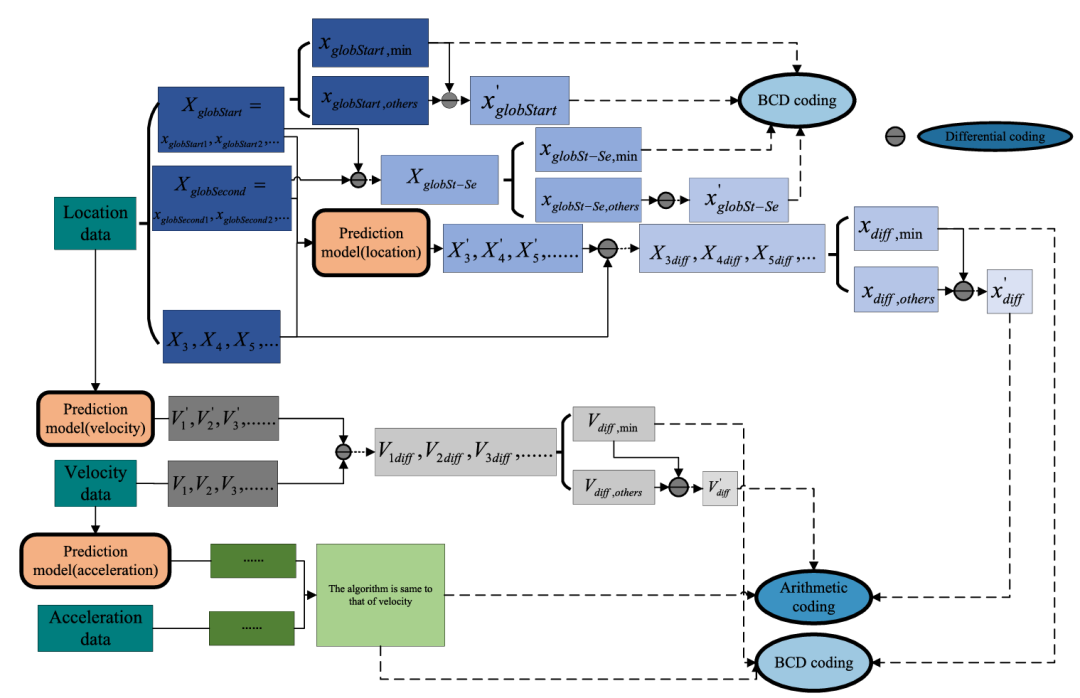
图4 所提出的算法中不同关键模块之间的关系
四.实验
4.1实验设置
NGSIM数据集. 它包含在美国101南行(加利福尼亚州)、兰克希姆大街(加利福尼亚州洛杉矶)、I-80东行(加利福尼亚州埃默里维尔)和桃树街(佐治亚州亚特兰大)上收集的车辆轨迹数据。US 101和I-80是高速公路。Lankershim Boulevard和Peachtree Street是城市道路。原始数据由放置在相应路段附近建筑物上的摄像头和雷达传感器收集。车辆轨迹数据是通过融合来自摄像头和雷达传感器的数据获得的。I-80和US 101数据集均包含三个文件。每个文件记录15分钟的车辆轨迹数据。Lankershim Boulevard 和Peachtree Street数据集均包含两个文件。每个文件记录15分钟的车辆轨迹数据。NGSIM数据集的概述如表II所示。每个数据点有24个属性,包括车辆ID、帧ID、车辆位置、车辆速度、车辆加速度等。
基线方法. 为了验证所提出的方法的优越性,本实验将其与四种基线算法进行比较:Trajstore、X3、无运动学运动预测的混合编码算法 (HC)、基于线性一阶微分方程的运动学运动预测的混合编码算法 (HCWL)。
度量标准. 数据的压缩时间、解压缩时间和传输时间之和,压缩比 (CRO) 和压缩率 (CRE) 被用作评估指标。
4.2 实验结果与讨论
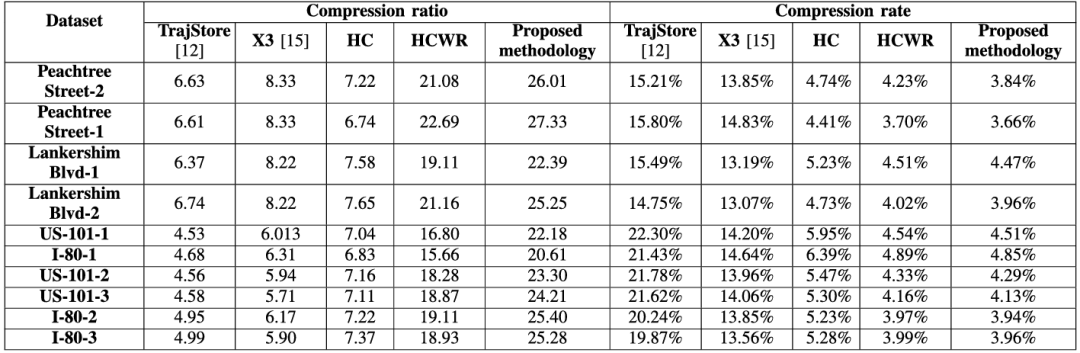
图5、图6、表IV和表V表明,所提算法的压缩性能优于TrajStore、X3、HC和HCWL。具体而言,所提算法的压缩率分别比以下算法高18.73、17.28、16.94、4.82。分别与基线算法相关的那些。所提算法的压缩率分别比基线算法低14.66%、10.67%、9.65%、1.06%。此外,可以观察到,将运动学运动预测纳入轨迹数据压缩可以显著提高压缩率。此外,从图6可以看出,有趣的是,在高速公路场景中,所提出的算法在压缩率方面相对于基线算法的优势大于城市场景。
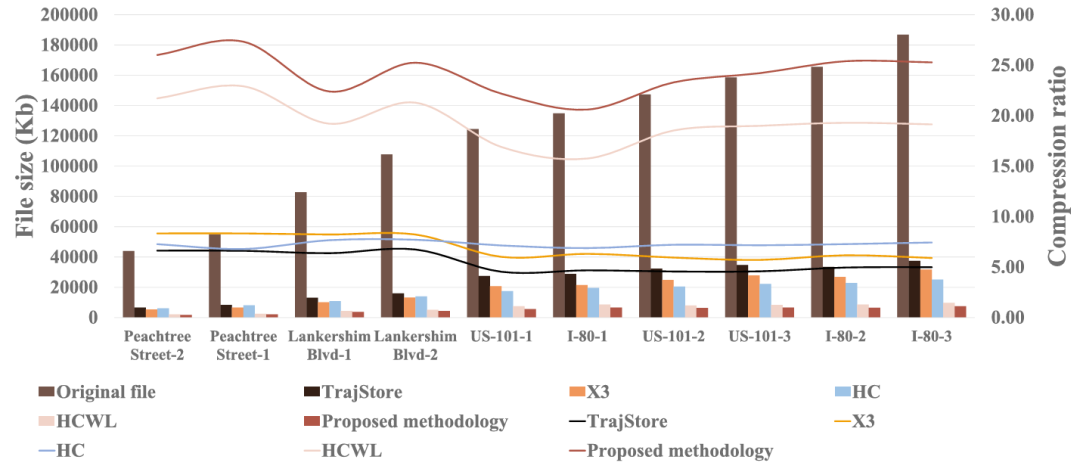
图5 压缩比比较
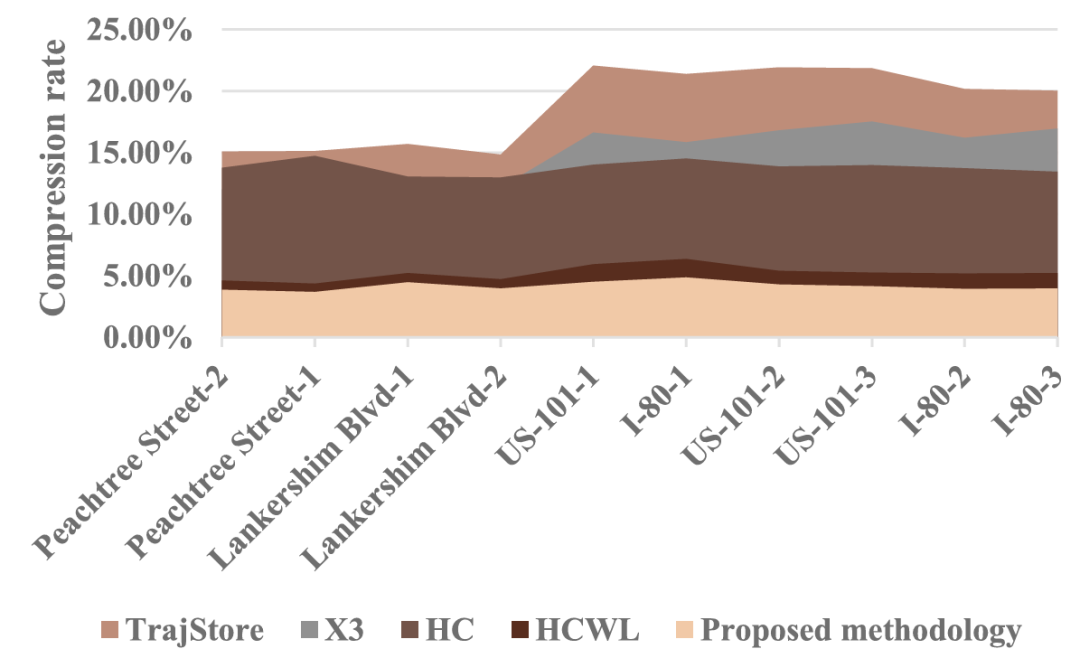
图6 压缩率比较
表1 提出的方法和基线算法获得的文件大小的比较
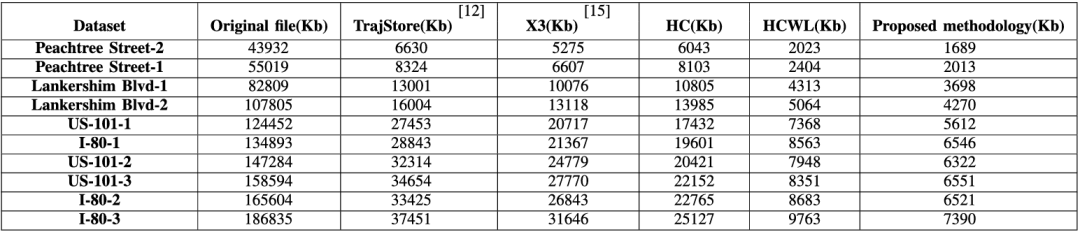
表2 压缩率和压缩比的比较
为了评估所提出的算法是否能够支持实时CAV应用,图6比较了所提出的算法与基线算法以及无压缩传输相关的压缩时间、传输时间和解压缩时间之和。该比较是在CAV每次时间步长从其他300个CAV收集压缩数据并解压缩时进行的。图6中的解压缩时间是数据和多线程的解压缩时间。本次比较使用了IEEE 802.11协议。数据传输速率、每个广播站中退避计数器的退避窗口大小和时隙时间分别为20Mbps、128和50 μs [27]。结果表明:1) 总时间为0.02秒;2) 所提出的算法的执行速度可以支持时间步长为1秒和0.1秒的实时CAV应用;3) 它低于与大多数基线算法和无压缩传输相关的时间。对于先在CAVs、RSUs和云服务器上存储一段时间再传输的数据,这对于减少压缩时间、解压缩时间和传输时间的总和也是有价值的。因此,在NGSIM数据集上进行了类似的比较,如图7所示,结果也确认所提出算法在总时间上相对于基线算法和不压缩传输的优势。结果显示,与所提出算法相关的总时间小于大多数基线算法和不压缩传输的总时间。
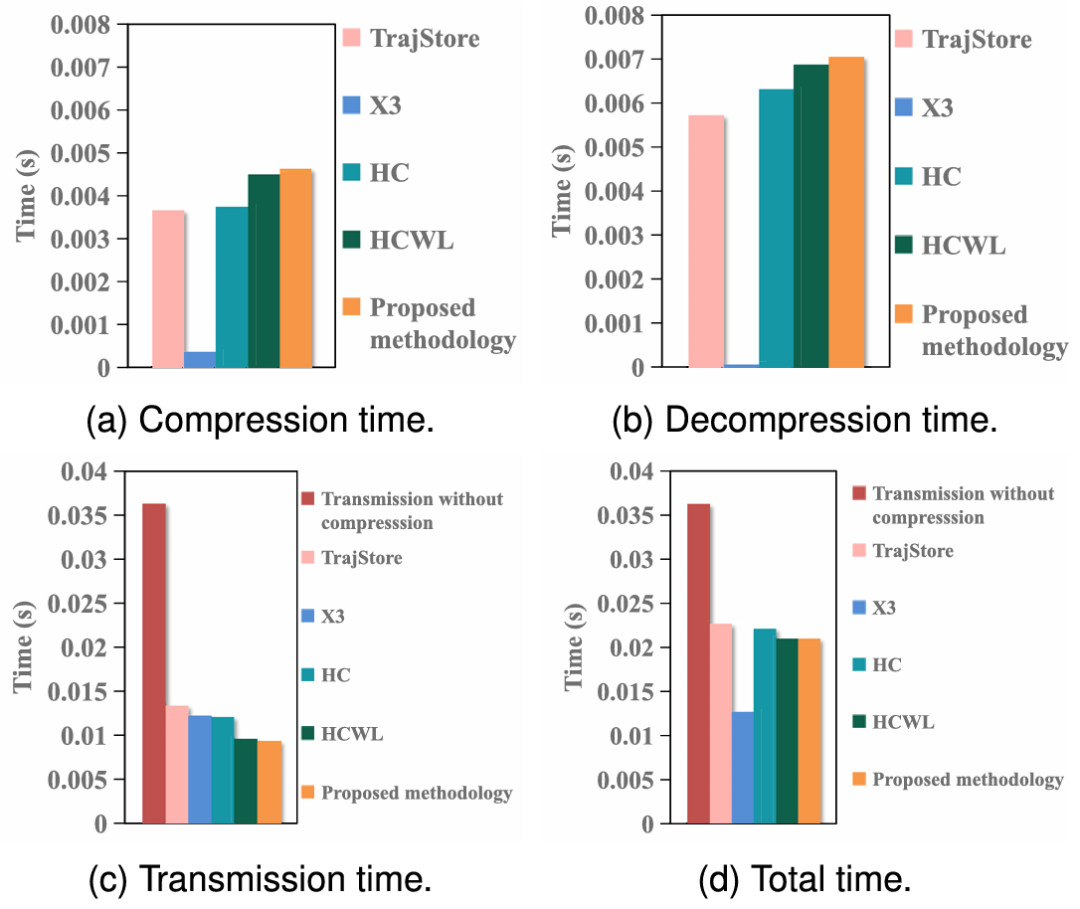
图7 CAV在每个时间步采集和压缩数据时的压缩时间、解压时间、传输时间和总时间的比较
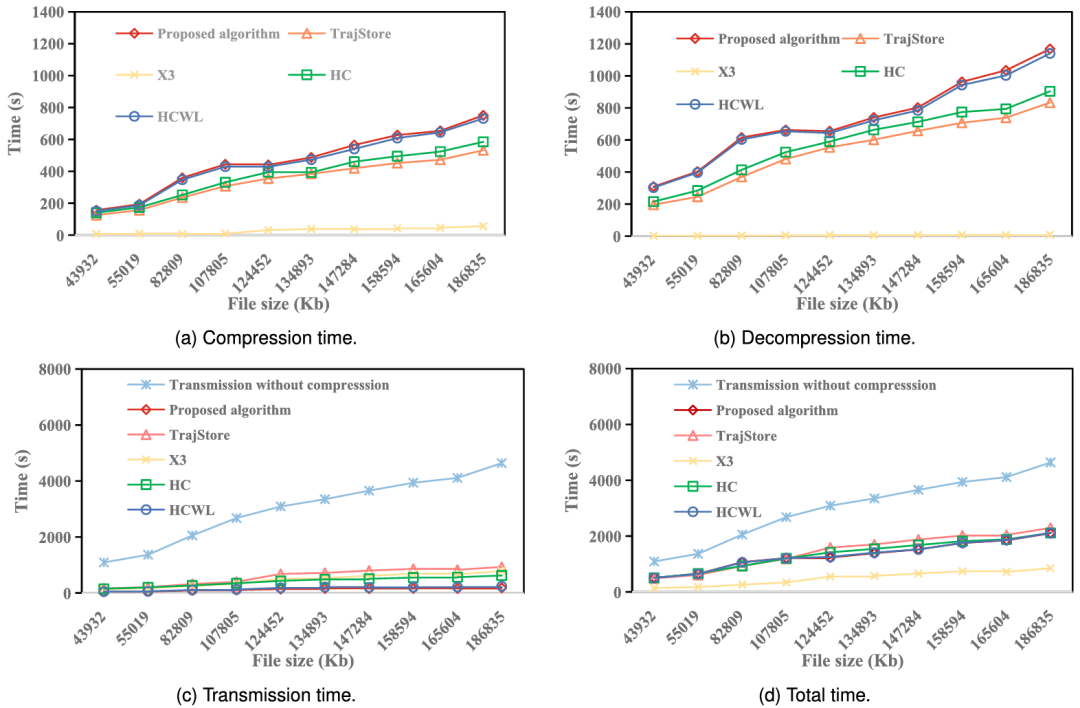
图8 NGSIM数据集下压缩时间、解压时间、传输时间和总时间的比较
四.总结
论文设计了一种新颖的方法,将运动学运动预测与混合编码算法相结合,用于压缩CAVs的轨迹数据。基于前两个时间步长的车辆位置以及运动学方程,预测前两个时间步长之后的车辆位置。基于车辆位置和FC-LSTM预测模型,预测车辆的速度和加速度。混合编码算法集成了差分编码、BCD编码和算术编码。差分编码通过将原始数据转换为原始数据与预测数据之间的差值来节省存储空间。BCD编码将所有不同长度的子序列转换为相同的长度,以便在解压缩后可以完全重现原始信息。算术编码通过将字符序列转换为大于0且小于1的小数来在小空间中表达信息。实验中,将提出的方法与四种基线方法进行了比较,结果表明提出的方法的压缩率低于四种基线方法。所提出算法的执行速度可以支持15秒和0.1秒时间步长的实时CAV应用。并且该算法对文件大小变化不敏感,在城市场景中,所提出的方法相对于基线方法的优势大于高速公路场景。
 |

图文|周钦钦
校稿|李佳俊
编辑|李佳俊
审核|李瑞远
审核|杨广超
