





本文字数:13006;估计阅读时间:33 分钟
作者:ClickHouse Team

Meetup活动
ClickHouse 北京第三届 Meetup 火热报名中,详见文末海报!

又到了发布新版本的时刻!
发布概要
ClickHouse 25.8 版本共带来了 45 项新功能 🌻、 47 项性能优化 🏍、 以及 119 个bug修复 🐝。
这一版本的亮点包括:全新的高速 Parquet 读取器、Data Lake 相关的功能增强、支持 Hive 风格分区写入、初步支持 PromQL 查询语法等众多更新!

热烈欢迎所有在 25.8 版本中首次贡献的开发者!ClickHouse 社区的蓬勃发展令人感动,我们始终感谢每一位为 ClickHouse 增添力量的贡献者。
以下是本次版本中新加入的贡献者名单:
Alexei Fedotov、Bulat Sharipov、Casey Leask、Chris Crane、Dan Checkoway、Denny(Innervate 的 DBA)、Evgenii Leko、Felix Mueller、Huanlin Xiao、Konstantin Dorichev、László Várady、Maruth Goyal、Nick、Rajakavitha Kodhandapani、Renat Bilalov、Rishabh Bhardwaj、RuS2m、Sahith Vibudhi、Sam Radovich、Shaohua Wang、Somrat Dutta、Stephen Chi、Tom Quist、Vladislav Gnezdilov、Vrishab V Srivatsa、Yunchi Pang、Zakhar Kravchuk、Zypperia、ackingliu、albertchae、alistairjevans、craigfinnelly、cuiyanxiang、demko、dorki、mlorek、rickykwokmeraki、romainsalles、saurabhojha、somratdutta、ssive7b、sunningli、xiaohuanlin、ylw510
贡献者:Michael Kolupaev
虽然 ClickHouse 是围绕其原生 MergeTree 表设计的,但它同样支持直接查询超过 70 种外部数据格式,包括 Parquet、JSON、CSV 和 Arrow 等,无需先导入数据。与多数数据库需要先将外部文件加载成原生格式不同,ClickHouse 可跳过这一步,依然支持完整的 SQL 功能,比如连接查询、窗口函数、170 多种聚合函数等。
在所有这些格式中,Parquet 占据着特殊的位置。它是现代 Lakehouse 表格式(如 Iceberg 和 Delta Lake)的核心存储格式。因此,近年来我们在 Parquet 支持方面持续加大优化力度,目标是让 ClickHouse 成为全球最快的 Parquet 查询引擎。
此次发布带来了全新原生实现的 Parquet 读取器(目前处于实验阶段),相比旧版大幅提速。此前,ClickHouse 的 Parquet 读取依赖 Apache Arrow 库:Parquet 文件会先被解析为 Arrow 格式,然后通过流式传输转换为 ClickHouse 的内存格式进行执行。而新版读取器跳过了这一步,能够直接将 Parquet 文件读取为 ClickHouse 内存格式,从而提升了并发能力和 I/O 效率。
在我们内部,这个项目被戏称为“另一个 Parquet 读取器”,因为这已经是第三个版本。第一次尝试(input_format_parquet_use_native_reader)启动后未能完成;第二次(v2)提交了 Pull Request 但没有合并。而这次,v3 终于正式落地,实现了完整集成的原生 Parquet 读取器。
那么这个新版读取器到底带来了什么?答案是:更强的并行能力与更高效的 I/O 性能。
并行能力提升
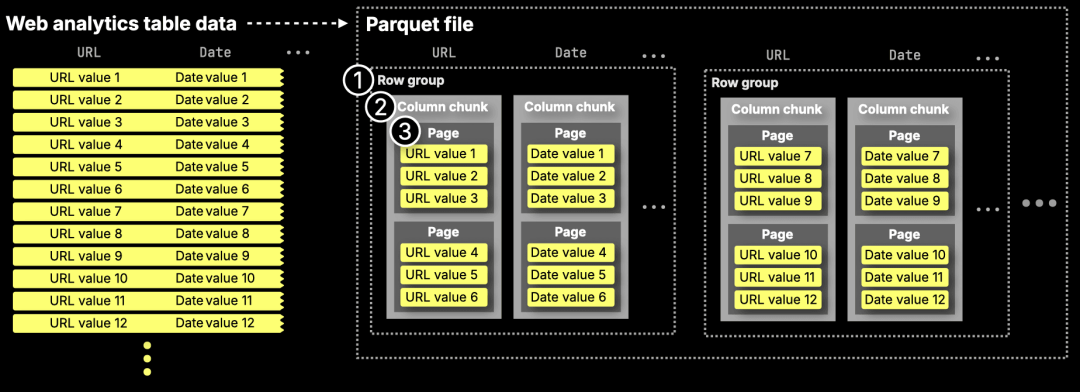
下图(摘自我们之前的深度解析(https://clickhouse.com/blog/clickhouse-and-parquet-a-foundation-for-fast-lakehouse-analytics))展示了 Parquet 文件在磁盘上的物理结构:
我们在这里不会展开太多细节(建议阅读我们的深度解析了解更多),这里只做简要说明:
Parquet 文件采用分层结构:
① 行组(Row groups)—— 水平分区,通常包含约 100 万行,或约 500 MB 的数据。
② 列块(Column chunks)—— 垂直切片,每个行组中每一列对应一个列块。
③ 页面(Pages)—— 最小的存储单元,约为 1 MB 大小,存储经过编码的值。
基于这种结构,ClickHouse 能够将 Parquet 查询任务在多个 CPU 核心上并行执行。
旧版读取器已经支持并行扫描多个行组,但新版进一步优化:它不仅可以并行处理整个行组,还能在同一个行组内部并发读取多个列,在行组数量较少的情况下也能充分利用 CPU 资源。
此外,ClickHouse 引擎在查询执行的每个阶段(如过滤、聚合、排序)都已实现并行化,因此新版读取器能够自然融入整个端到端的并行执行模型:
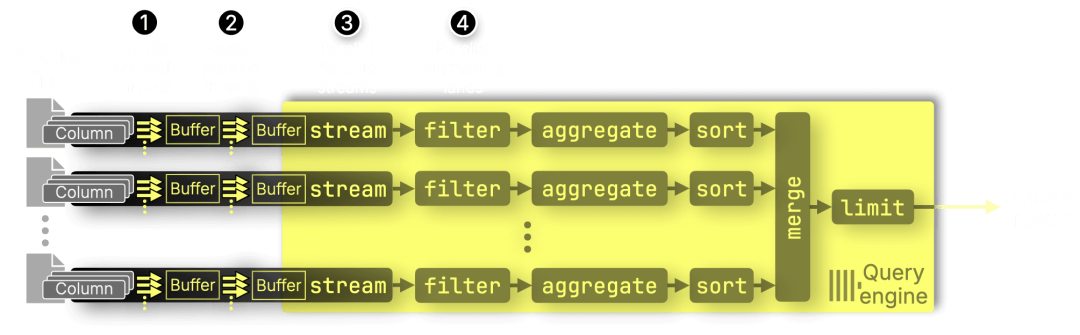
① 预取线程(Prefetch threads)—— 并行加载多个列
② 解析线程(Parsing threads)—— 并行解码各列数据
③ 文件流处理(File streams)—— 同时处理多个 Parquet 文件
④ 执行通道(Processing lanes)—— 多核并行执行过滤、聚合和排序操作
需要特别指出的是,新版读取器的预取机制更加智能:它运行在独立的线程池中,仅加载真正需要的数据。例如,非 PREWHERE 子句所涉及的列会在 PREWHERE 执行完成、明确哪些页面需要读取之后再进行预取,从而避免了无效的数据读取。(下一节我们将详细讲解 PREWHERE。)
Parquet 数据的并行处理显著提升了查询性能,但影响性能的另一个关键因素是读取数据的总量。在这方面,新版 Parquet 读取器也做得更高效!
I/O 效率提升
并行处理可以提升查询速度,而更智能的过滤机制则能在源头减少需要处理的数据量。
下图展示了 Parquet 文件中用于数据过滤的元数据结构:
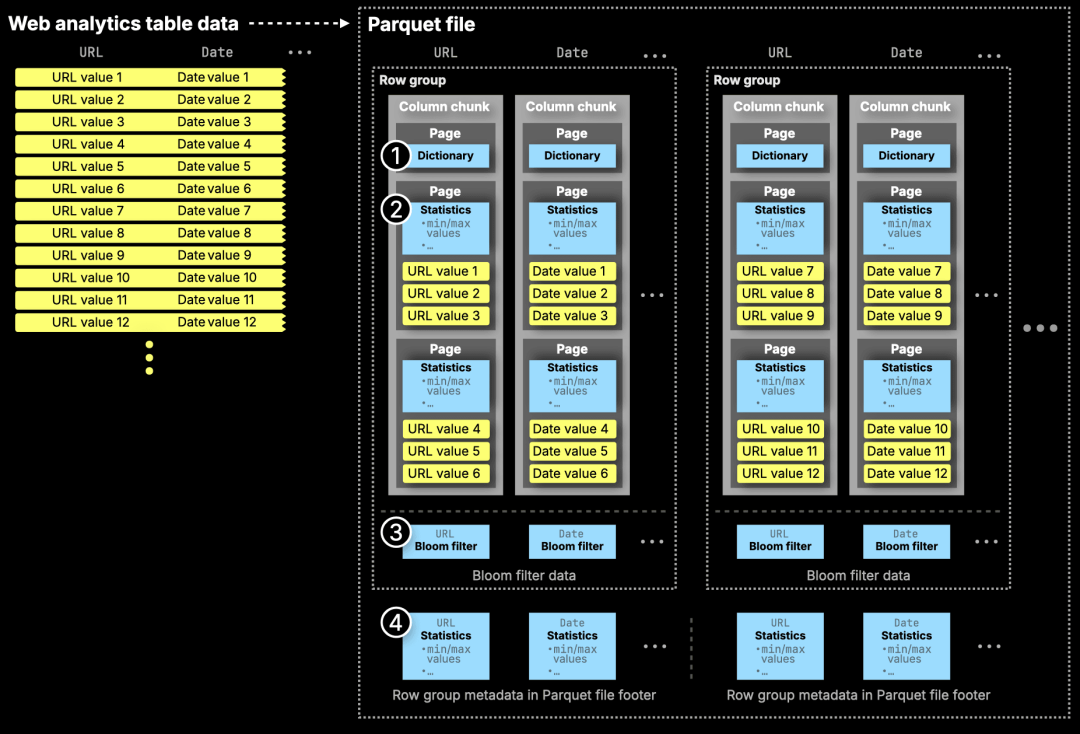
① 字典(Dictionaries)—— 用于低基数字段的唯一值映射
② 页面级统计信息(Page stats)—— 每个页面的最小值和最大值
③ 布隆过滤器(Bloom filters)—— 每列的辅助信息,用于跳过无关数据
④ 行组统计信息(Row group stats)—— 整个行组的最小值和最大
此前的 ClickHouse Parquet 读取器已经支持基于行组级最小/最大值和布隆过滤器进行跳过读取操作,以减少无效扫描。
而新版原生读取器则进一步加入了页面级最小/最大值过滤支持,并首次引入了 PREWHERE 子句优化,使得数据读取更加精准高效。我们将在下一节中演示这一点。
Parquet 读取器性能
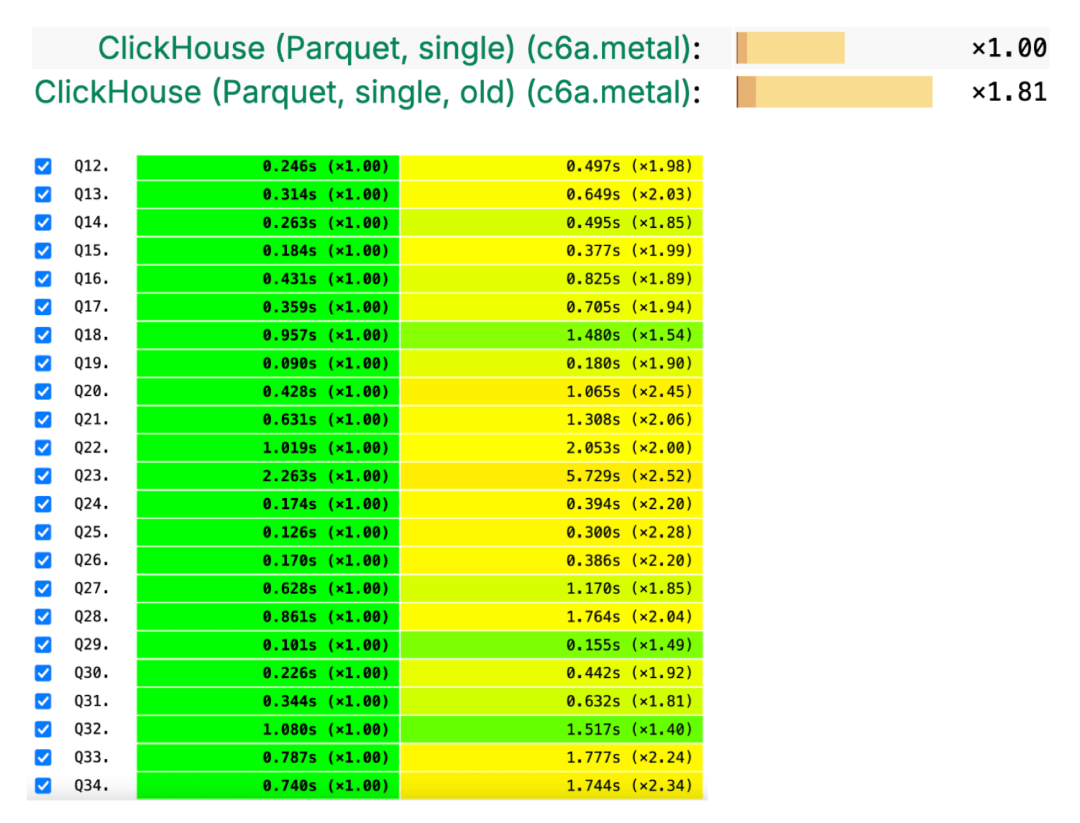
总体来看,新版 Parquet 读取器使 ClickBench (https://benchmark.clickhouse.com/)查询的平均性能提升了 1.81 倍,也就是说,在直接读取 Parquet 文件时的执行速度几乎提升了近一倍:
Demo
为了展示改进后的 parquet 读取器性能,我们将在 ClickBench 使用的数据集上运行一个查询。
Step 1: 创建一个目录,用来存放 ClickBench 匿名化的网站分析数据集(Parquet 格式)(https://clickhouse.com/docs/getting-started/example-datasets/metrica)
mkdir ~/hits_parquetcd ~/hits_parquet
Step 2: 下载 Parquet 格式的数据集:
wget --continue --progress=dot:giga 'https://datasets.clickhouse.com/hits_compatible/hits.parquet'
Step 3: 下载最新版本的 ClickHouse:
curl https://clickhouse.com/ | sh
Step 4: 以交互模式运行 clickhouse-local:
./clickhouse local
首先,我们用旧版本的 parquet 读取器来运行一个典型的分析查询,该查询涉及 URL 和 EventTime 列:
SELECT URL, EventTimeFROM file('./hits_parquet/hits.parquet')WHERE URL LIKE '%google%'ORDER BY EventTimeLIMIT 10FORMAT Null;
0 rows in set. Elapsed: 1.513 sec. Processed 99.57 million rows, 14.69 GB (65.82 million rows/s., 9.71 GB/s.)Peak memory usage: 1.36 GiB.
可以看到,这次查询扫描并处理了 9957 万行数据,14.69 GB,总耗时 1.513 秒。
接着,我们启用新的 parquet 读取器,再次运行相同的查询:
SELECT URL, EventTimeFROM file('./hits_parquet/hits.parquet')WHERE URL LIKE '%google%'ORDER BY EventTimeLIMIT 10FORMAT NullSETTINGSinput_format_parquet_use_native_reader_v3 = 1
0 rows in set. Elapsed: 0.703 sec. Processed 14.82 thousand rows, 6.67 MB (21.07 thousand rows/s., 9.48 MB/s.)Peak memory usage: 1.91 GiB.
这次查询只处理了 4.82K 行数据,6.67 MB,用时 0.703 秒,性能提升约 2 倍。
这种加速得益于页面级别的 min/max 过滤与 PREWHERE 的结合。
利用页面级统计信息,ClickHouse 可以直接跳过那些不可能满足 URL 列 WHERE 条件的整个 Parquet 页面。
而通过 PREWHERE(https://clickhouse.com/docs/optimize/prewhere),ClickHouse 只会在页面粒度上扫描 EventTime 值,用于匹配 URL。
为什么这很重要?
高效的 Parquet 处理是 ClickHouse 作为 Lakehouse 引擎的核心基础。像 Apache Iceberg(以及 Delta Lake、Hudi 等)这样的开放表格式,都依赖 Parquet 作为存储层:
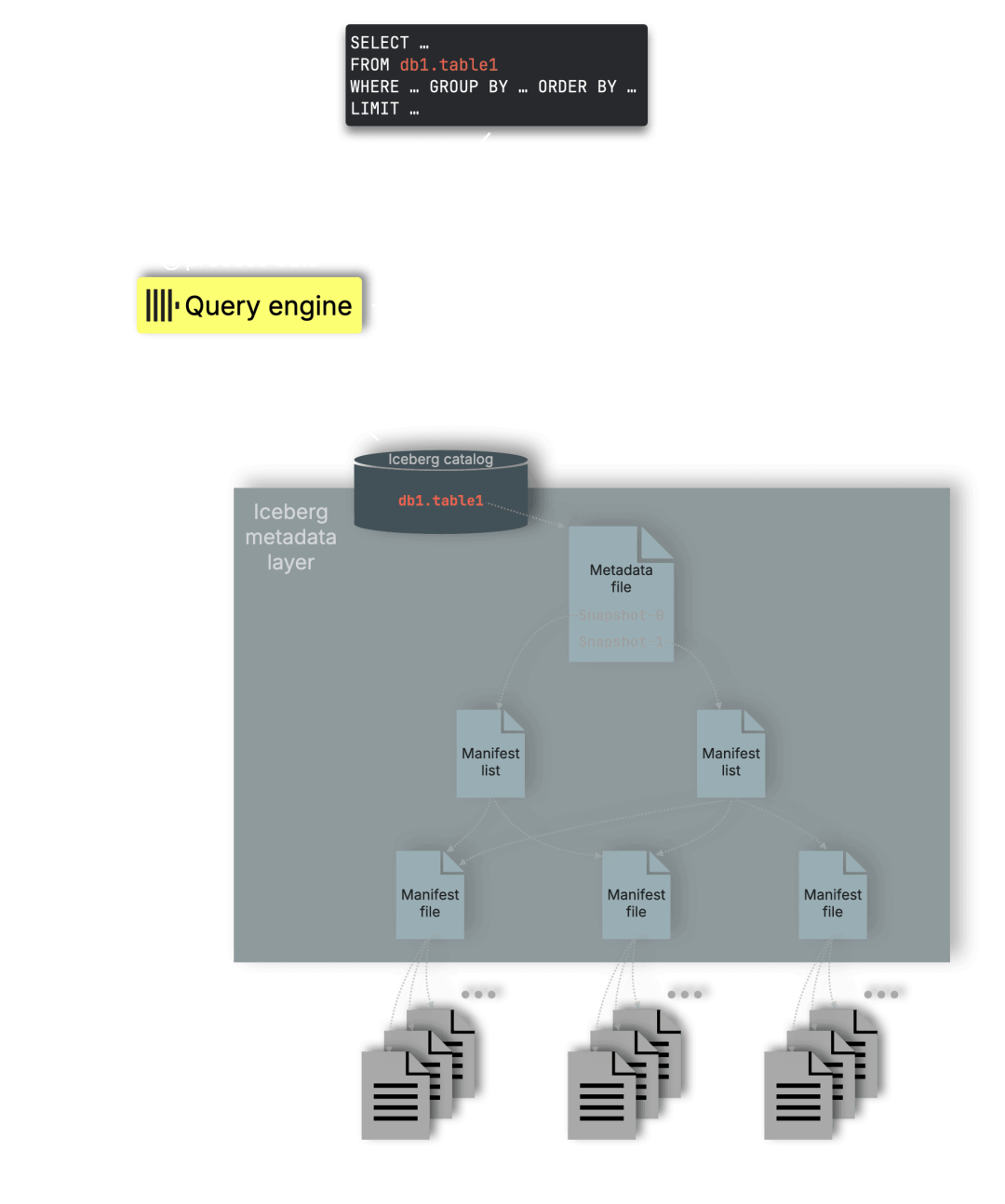
这意味着,每次查询 Iceberg 表时,最终都取决于引擎能否高效地读取和处理 Parquet 文件。
通过加速和优化 Parquet 的读取能力,我们让 ClickHouse 成为数据湖场景的高性能选择:能够在开放格式上,直接发挥出我们原生引擎的极速优势。
贡献者:Arthur Passos
ClickHouse 现在支持 Hive 风格的分区写入。这意味着数据会按目录进行拆分,目录结构对应分区键的值。
我们来看看它在 S3 表引擎(https://clickhouse.com/docs/engines/table-engines/integrations/s3#partition-by)中的使用方式。这里我们用 MinIO 在本地测试,所以先安装 MinIO 客户端和服务端:
brew install minio/stable/miniobrew install minio/stable/mc
接着启动服务器:
minio server hive-data
然后创建一个 bucket:
mc alias set minio http://127.0.0.1:9000 minioadmin minioadminmc mb minio/taxis
Added `minio` successfully.Bucket created successfully `minio/taxis`.
接下来,从纽约出租车数据集中下载一些 Parquet 文件:
curl "https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2023-06.parquet" -o yellow_tripdata_2023-06.parquet
现在,我们创建一张表,并按照 PULocationID 和 DOLocationID 进行分区,分别表示上车和下车地点。
CREATE TABLE taxis(VendorID Int64,tpep_pickup_datetime DateTime64(6),tpep_dropoff_datetime DateTime64(6),passenger_count Float64,trip_distance Float64,RatecodeID Float64,store_and_fwd_flag String,PULocationID Int64,DOLocationID Int64,payment_type Int64,fare_amount Float64,extra Float64,mta_tax Float64,tip_amount Float64,tolls_amount Float64,improvement_surcharge Float64,total_amount Float64,congestion_surcharge Float64,airport_fee Float64)ENGINE = S3('http://127.0.0.1:9000/taxis','minioadmin', 'minioadmin',format='Parquet', partition_strategy = 'hive')PARTITION BY (PULocationID, DOLocationID);
接着插入这些 Parquet 文件:
INSERT INTO taxisSELECT *FROM file('*.parquet');
然后我们就可以像下面这样查询表了:
SELECT DOLocationID, _path, avg(fare_amount)FROM taxisWHERE PULocationID = 199GROUP BY ALL;
┌─DOLocationID─┬─_path───────────────────────────────────────────────────────────────┬─avg(fare_amount)─┐│ 79 │ taxis/PULocationID=199/DOLocationID=79/7368231474740330498.parquet │ 45.7 ││ 163 │ taxis/PULocationID=199/DOLocationID=163/7368231447649320960.parquet │ 52 ││ 229 │ taxis/PULocationID=199/DOLocationID=229/7368231455001935873.parquet │ 37.3 ││ 233 │ taxis/PULocationID=199/DOLocationID=233/7368231484399812609.parquet │ 49.2 ││ 41 │ taxis/PULocationID=199/DOLocationID=41/7368231474941657088.parquet │ 31.7 ││ 129 │ taxis/PULocationID=199/DOLocationID=129/7368231437356498946.parquet │ 10 ││ 70 │ taxis/PULocationID=199/DOLocationID=70/7368231504532471809.parquet │ 3 ││ 186 │ taxis/PULocationID=199/DOLocationID=186/7368231493912494080.parquet │ 44.3 │└──────────────┴─────────────────────────────────────────────────────────────────────┴──────────────────┘
贡献者:Konstantin Vedernikov #
ClickHouse 的数据湖功能也有所提升。借助 IcebergS3 表引擎,你现在可以创建 Apache Iceberg 表,执行插入、删除、更新操作,并调整 schema。
首先,使用 IcebergLocal 表引擎创建一张表:
CREATE TABLE demo (c1 Int32)ENGINE = IcebergLocal('/Users/markhneedham/Downloads/ice/');
目前对 Iceberg 的写入还处于实验阶段,因此需要设置如下配置:
SET allow_experimental_insert_into_iceberg=1;
插入一些数据:
INSERT INTO demo VALUES (1), (2), (3);
查询这张表:
SELECT *FROM demo;
结果如预期,共有三行数据:
┌─c1─┐│ 1 ││ 2 ││ 3 │└────┘
接下来,删除 c1=3 的那一行:
DELETE FROM demo WHERE c1=3;
再次查询表:
┌─c1─┐│ 1 ││ 2 │└────┘
很好,那一行已经被删除了!然后修改表的 DDL,新增一列:
ALTER TABLE demoADD column c2 Nullable(String);
再次查询:
┌─c1─┬─c2───┐│ 1 │ ᴺᵁᴸᴸ ││ 2 │ ᴺᵁᴸᴸ │└────┴──────┘
很好,新列已经创建,所有值都是 null。接着插入一条新数据:
INSERT INTO demo VALUES (4, 'Delta Kernel');
然后第三次查询表:
┌─c1─┬─c2───────────┐│ 4 │ Delta Kernel ││ 1 │ ᴺᵁᴸᴸ ││ 2 │ ᴺᵁᴸᴸ │└────┴──────────────┘
接下来我们更新 c1=1 那一行的 c2 值:
ALTER TABLE demo(UPDATE c2 = 'Equality delete' WHERE c1 = 1);
最后再查询一次表:
┌─c1─┬─c2──────────────┐│ 1 │ Equality delete ││ 4 │ Delta Kernel ││ 2 │ ᴺᵁᴸᴸ │└────┴─────────────────┘
我们还可以通过运行以下命令,查看在执行这些操作时 bucket 中生成的底层文件:
$ tree ~/Downloads/ice
/Users/markhneedham/Downloads/ice├── data│ ├── 8ef82353-d10c-489d-b1c4-63205e2491e4-deletes.parquet│ ├── c5080e90-bbee-4406-9c3f-c36f0f47f89f-deletes.parquet│ ├── data-369710b6-6b9c-4c68-bc76-c62c34749743.parquet│ ├── data-4297610d-f152-4976-a8aa-885f0d29e172.parquet│ └── data-b4a9533f-2c6d-4f5f-bff9-3a4b50d72233.parquet└── metadata├── 50bb92f9-1de1-4e27-98bc-1f5633b71025.avro├── 842076c9-5c9a-476c-9083-b1289285518d.avro├── 99ef0cd6-f702-4e5a-83e5-60bcc37a2dcf.avro├── b52470e3-2c24-48c8-9ced-e5360555330a.avro├── c4e99628-5eb8-43cc-a159-3ae7c3d18f48.avro├── snap-1696903795-2-4ca0c4af-b3a8-4660-be25-c703d8aa88be.avro├── snap-2044098852-2-e9602064-a769-475c-a1ae-ab129a954336.avro├── snap-22502194-2-86c0c780-60a7-4896-9a29-a2317ad6c3f6.avro├── snap-227376740-2-37010387-0c95-4355-abf7-1648282437cd.avro├── snap-326377684-2-0d0d0b37-8aec-41c0-99ce-f772ab9e1f6b.avro├── v1.metadata.json├── v2.metadata.json├── v3.metadata.json├── v4.metadata.json├── v5.metadata.json├── v6.metadata.json└── v7.metadata.json
如果要删除 ClickHouse 中的表,可以运行 DROP TABLE demo,但要注意,这不会删除存储 bucket 中的底层表。
此外,数据湖功能还有以下更新:
支持通过 REST 和 Glue catalog 向 Iceberg 表写入数据。
支持在 REST 和 Glue catalog 中对 Iceberg 执行 DROP TABLE。
支持对 Delta Lake 表进行写入和时光回溯。
Unity、REST、Glue 和 Hive Metastore catalog 已经从实验性升级为 beta 状态。
贡献者:Xiaozhe Yu
Merge 表函数可以同时查询多张表,并提供 _table 虚拟列,用于跟踪每一行结果来自哪个底层表。现在,这个虚拟列也能在其他查询中使用了。
比如说,我们定义了一张表 foo,如下所示:
CREATE TABLE foo(c1 Int,c2 String,c3 String)ORDER BY c1;INSERT INTO foo VALUES (7, 'ClickHouse', 'ClickStack');
然后对这张表和 icebergLocal 表函数执行一个查询:
SELECT c1, c2,FROM icebergLocal('/Users/markhneedham/Downloads/ice')UNION ALLSELECT c1, c2FROM foo;
┌─c1─┬─c2──────────────┐│ 1 │ Equality delete ││ 7 │ ClickHouse ││ 4 │ Delta Kernel ││ 2 │ ᴺᵁᴸᴸ │└────┴─────────────────┘
此时我们就可以使用 _table 虚拟列,清楚地知道 UNION ALL 查询中的每一行数据分别来自哪一部分:
SELECT c1, c2, _tableFROM icebergLocal('/Users/markhneedham/Downloads/ice')UNION ALLSELECT c1, c2, _tableFROM foo;
┌─c1─┬─c2──────────────┬─_table───────┐│ 7 │ ClickHouse │ foo ││ 1 │ Equality delete │ icebergLocal ││ 4 │ Delta Kernel │ icebergLocal ││ 2 │ ᴺᵁᴸᴸ │ icebergLocal │└────┴─────────────────┴──────────────┘
贡献者:Artem Brustovetski
本次版本在处理存储于 S3 的数据时,增加了更多安全功能。
你现在可以在 s3 表函数中使用自定义的 IAM 角色:
SELECT *FROM s3('s3://mybucket/path.csv', CSVWithNames,extra_credentials(role_arn ='arn:aws:iam::111111111111:role/ClickHouseAccessRole-001'));
同时,也可以针对 S3 中的特定 URL 定义 GRANTS,而不仅仅是针对所有的 S3 bucket:
GRANT READ ON S3('s3://foo/.*')TO user;
贡献者:zakr600, Vitaly Baranov
Arrow Flight(https://arrow.apache.org/docs/format/Flight.html) 是一种高性能数据交换协议,基于 Apache Arrow 的列式内存格式,并通过 gRPC 进行传输。不同于传统的行式协议,Arrow Flight 在传输过程中保持原生的列式存储格式,避免了昂贵的序列化开销,因此尤其适用于分析型工作负载。可以把它看作是 ODBC 或 JDBC 等协议的现代高效替代方案,专门为列式数据处理时代而设计。
ClickHouse 现在已经支持 Arrow Flight 的初始功能,能够在 Arrow Flight 生态系统中同时作为客户端和服务器使用。作为客户端,ClickHouse 可以通过 arrowflight 表函数查询远程的 Arrow Flight 数据源;作为服务器,它可以将数据提供给支持 Arrow Flight 协议的客户端,比如 PyArrow 或其他兼容系统。
这一功能为集成提供了一条新的路径,使 ClickHouse 能够与日益增长的 Arrow 原生工具和应用生态系统互操作。虽然目前仍处于早期阶段,但 Arrow Flight 支持标志着 ClickHouse 正在向更广泛的列式数据处理工作流兼容性迈出第一步。
我们先来看看如何将 ClickHouse 作为 Arrow Flight 服务器来使用。需要先指定运行端口。如果不指定 listen_host,可能会默认尝试监听 IPv6 地址,而这在部分系统上并不受支持。
arrowflight_port: 6379arrowflight:enable_ssl: falselisten_host: "127.0.0.1"
接下来启动 ClickHouse Server:
./clickhouse server
你应该会看到类似下面的输出:
Application: Listening for Arrow Flight compatibility protocol: 127.0.0.1:6379
然后启动 ClickHouse Client:
./clickhouse client
基于纽约出租车数据集创建一张表:
CREATE TABLE taxisORDER BY VendorIDAS SELECT *FROM url('https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2023-06.parquet')SETTINGS schema_inference_make_columns_nullable = 0;
完成之后,启动 iPython REPL,并将 pyarrow 作为依赖:
uv run --with pyarrow --with ipython ipython
然后运行以下代码,计算平均小费和乘客数量:
import pyarrow.flight as flclient = fl.FlightClient("grpc://localhost:6379")token = client.authenticate_basic_token("default", "")ticket = fl.Ticket(b"SELECT avg(tip_amount), avg(passenger_count) FROM taxis LIMIT 10")call_options = fl.FlightCallOptions(headers=[token])try:reader = client.do_get(ticket, call_options)table = reader.read_all()print("Table shape:", table.shape)print("Schema:", table.schema)print("nData:")print(table)except Exception as e:print(f"Error: {e}")
Table shape: (1, 2)Schema: avg(tip_amount): double not nullavg(passenger_count): double not nullData:pyarrow.Tableavg(tip_amount): double not nullavg(passenger_count): double not null----avg(tip_amount): [[3.5949154187456926]]avg(passenger_count): [[1.327664447087808]]
正如前面提到的,ClickHouse 也可以作为 Arrow Flight 客户端使用。这可以通过 arrowFlight 表函数或 ArrowFlight 表引擎来实现。
接着我们就可以像下面这样去查询 Arrow Flight 服务器:
SELECT *FROM arrowflight('localhost:6379', 'dataset');
贡献者:Vitaly Baranov
本次版本新增了对 PromQL(Prometheus Query Language)的初步支持。你可以在 ClickHouse 客户端中设置 dialect='promql',并通过 promql_table_name='X' 指定一个时间序列表,然后就可以运行类似下面这样的查询:
rate(ClickHouseProfileEvents_ReadCompressedBytes[1m])[5m:1m]
你还可以在 SQL 语句中嵌入 PromQL 查询:
SELECT *FROM prometheusQuery('up', ...)
在 25.8 版本中,目前仅支持 rate、delta 和 increase 三个函数。
贡献者:Alexander Sapin
像 AWS S3、GCP 和 Azure Blob Storage 这样的对象存储,本质上都是复杂的分布式系统,各自也有一些“脾气”。延迟问题尤其容易带来麻烦——我们曾观测到偶发的延迟峰值,最高可达 5 秒、10 秒、甚至 15 秒……
几年前,我们通过自研的 HTTP 客户端解决了 AWS 和 GCP 的延迟问题,核心方法包括:
同时使用多个连接访问多个端点
轮换端点以实现更均衡的负载分布
一旦出现软超时,就立即发起第二个请求
通过积极的推测性重试来保障稳定性
现在,我们在 Azure SDK 中也替换了 HTTP 客户端,复用了与 AWS S3 相同的激进重试逻辑,从而解决了 Azure Blob Storage 的延迟问题。
结果是:延迟峰值不复存在!
该优化在默认情况下已启用,如果想切换回之前的实现,可以通过设置 zure_sdk_use_native_client=false 来实现。

好消息:ClickHouse Beijing User Group第 3 届 Meetup 火热报名中,将于2025年09月20日在北京海淀永泰福朋喜来登酒店(北京市海淀区远大路25号1座)举行,扫码免费报名


/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


