




大家好,我是JiekeXu,江湖人称“强哥”,青学会MOP技术社区主席,荣获Oracle ACE Pro称号,金仓最具价值倡导者KVA,崖山最具价值专家YVP,IvorySQL开源社区专家顾问委员会成员,墨天轮MVP,墨天轮年度“墨力之星”,拥有 Oracle OCP/OCM 认证,MySQL 5.7/8.0 OCP 认证以及金仓KCA、KCP、KCM、KCSM证书,PCA、PCTA、OBCA、OGCA等众多国产数据库认证证书,欢迎关注我的微信公众号“JiekeXu DBA之路”,然后点击右上方三个点“设为星标”置顶,更多干货文章才能第一时间推送,谢谢!
前 言
这几天总是能遇到一些莫名其妙的 Oracle 备库出现的问题,也许是自己能力和知识面不够,出现问题没有找到根因,亦或者是 Oracle 的 BUG,但都没法求证,本着首先恢复业务的原则,也不能刨根问底,时间也不允许,只能按照目前的经验处理。最近又遇到一级联备库在断开同步激活成读写库的时候导致其他两个备库 MRP 进程中断无法正常启动,导致同步中断,下面来一起看看问题排查过程及解决办法。
操作过程
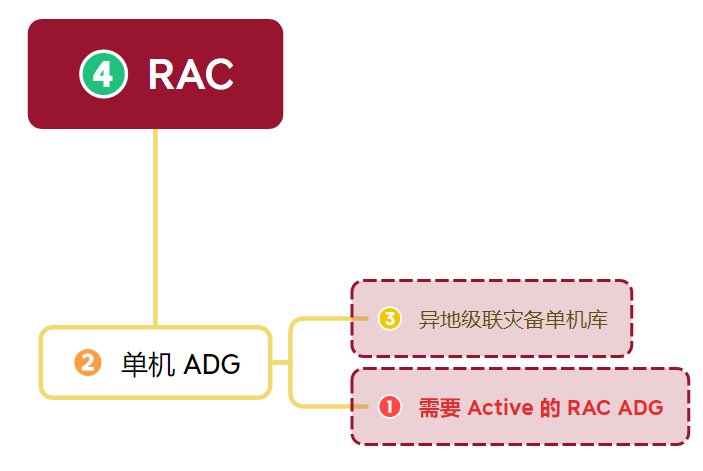
如下图,我们简单介绍一下这套环境的架构,1 号库是我们本次操作的级联 ADG 备库 RAC 架构,需要将其激活成读写模式,然后 2 号库相当于他的原库,2 号库还有一个单机级联 ADG 3 号库,2 号库的源库是 4 号库 RAC,业务主库。
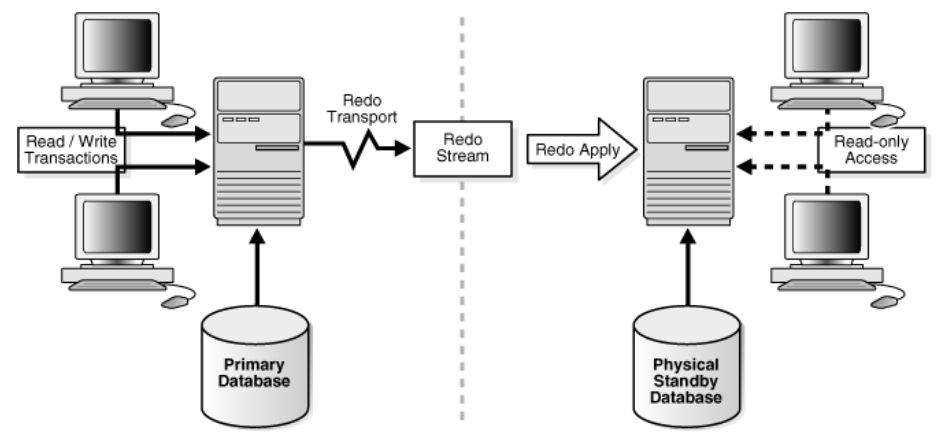
下图是官网 ADG 架构示意图:
根据我们上面介绍的架构示意图,在 2 号库上断开主备同步,禁用日志传输,在 1 号库上激活级联备库为读写库。
--2 号库
show parameter arch
show parameter db_file_name_convert
show parameter log_file_name_convert
show parameter standby_file_management
show parameter fal_client
show parameter fal_server
show parameter log_archive
show parameter log_archive_config
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_config string DG_CONFIG=(jieke,jxrtadg,jiekeot)
--禁用日志传输及取消DG备库配置
alter system set log_archive_dest_state_3=defer;
alter system set log_archive_config ='DG_CONFIG=(jieke,jiekeadg)';
这里指的 1 号库就是我们需要激活为读写库的数据库,一条命令就搞定!
--1号库 备库激活读写
srvctl stop database -d jiekeot
sqlplus / as sysdba
startup mount
--alter system set log_archive_dest_state_2=defer;
create restore point flashback_20250901 guarantee flashback database;
select SCN,name from v$restore_point;
--drop restore point flashback_20250901;
--激活为读写模式
alter database activate standby database;
select NAME,OPEN_MODE,LOG_MODE,DATABASE_ROLE from gv$database;
--1号库 RAC节点2
startup
问题现象
如上,操作也算是属于正常操作流程,一时半会看不出有何问题,但过了一会儿,2 号库和 3 号库的 MRP 进程不存在了,出现了告警。立马登录 2 号库(生产库的备库)查看,alert 日志如下:
2025-09-01T15:59:59.316300+08:00
TT00 (PID:20443): Error ORA-235 occurred during an un-locked control file <--可忽略
TT00 (PID:20443): transaction. This error can be ignored. The control
TT00 (PID:20443): file transaction will be retried.
2025-09-01T15:59:59.341296+08:00
TT02 (PID:24613): Cannot find SRL for T-1.S-2
2025-09-01T15:59:59.379866+08:00
rfs (PID:78114): krsr_rfs_atc: Identified database type as 'PHYSICAL STANDBY': Client is Foreground (PID:2463801)
2025-09-01T15:59:59.873310+08:00
**ORA-205:**从 Oracle 12c 开始,控制文件事务得到了增强。在扫描特定的控制文件段(controlfile section)之前,我们不再需要请求控制文件队列。这样做的目的是最大限度地减少锁定问题(locking issues),并提升性能与可扩展性(scalability)。由于这一变更,当某个控制文件段正被另一个进程修改时,读取该控制文件段的进程有时可能会遇到 ORA-235 错误。出现这种情况时,读取进程会直接重新读取该段。您可以安全地忽略此错误信息,它并非实际问题。无法通过设置任何事件或初始化参数在数据库层面抑制(suppress)这类错误。原因在于,尽管这些错误无害,但它们能反映出控制文件上的并发情况,且有助于排查与控制文件 I/O 缓慢等相关的问题 —— 因此,开发团队专门新增了这一增强功能。最佳做法是修改所有监控脚本,让其忽略或排除此错误。由于这是符合设计预期的正常行为,且这些错误仅为提示性信息(informational),因此完全可以忽略。接着往下看日志。
Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_78114.trc:
ORA-00316: log 15 of thread 1, type 0 in header is not log file <---有 Bug 37555741 会出现这种情况
ORA-00312: online log 15 thread 1: '/data/jieke/fra/jiekedg/onlinelog/o1_mf_15_kz74bht7_.log'
2025-09-01T16:00:01.191910+08:00
Clearing online log 16 of thread 1 sequence number 0
2025-09-01T16:00:01.313156+08:00
rfs (PID:78515): krsr_rfs_atc: Identified database type as 'PHYSICAL STANDBY': Client is ARCH (PID:900202)
rfs (PID:78515): New archival redo branch: 1210694362 current: 1129114545
2025-09-01T16:00:01.330323+08:00
rfs (PID:78526): krsr_rfs_atc: Identified database type as 'PHYSICAL STANDBY': Client is ASYNC (PID:900208)
rfs (PID:78526): New archival redo branch: 1210694362 current: 1129114545
rfs (PID:78526): Primary database is in MAXIMUM PERFORMANCE mode
2025-09-01T16:00:01.436794+08:00
rfs (PID:78540): krsr_rfs_atc: Identified database type as 'PHYSICAL STANDBY': Client is Foreground (PID:899936)
第一个错误 ORA-00316, type 0 in header is not log file 联机日志已损坏或为旧版本,这里什么也没做,怎么会有这个错误呢?当时没想通,事后查 MOS 说可能是 Bug 37555741 - Enhance the ORA-316 error message with more description and solutions (Doc ID 37555741.8) ,在新发布的 23ai 版本 23.9.0.25.07 DBRU 中修复了,但我这里不是 bug,下文有详细说明。接着往下看:
2025-09-01T16:00:01.596280+08:00 rfs (PID:78515): Selected LNO:27 for T-2.S-1 dbid 657075540 branch 1210694362 2025-09-01T16:00:01.655925+08:00 rfs (PID:78526): No SRLs available for T-2 2025-09-01T16:00:01.693947+08:00 rfs (PID:78515): A new recovery destination branch has been registered <--已注册新的恢复目标分支 rfs (PID:78515): Standby in the future of new recovery destination branch(resetlogs_id) 1210694362 rfs (PID:78515): Incomplete Recovery SCN:0x00000000ad6c46ef <--完成恢复并 Resetlogs rfs (PID:78515): Resetlogs SCN:0x00000000ad65f284 rfs (PID:78515): SBPS:0x00000000ad65f281 rfs (PID:78515): Flashback database to SCN:0x00000000ad65f281 (-1385827711) to follow new branch <--闪回数据库到指定的 SCN rfs (PID:78515): New Archival REDO Branch(resetlogs_id): 1210694362 Prior: 1129114545 rfs (PID:78515): Archival Activation ID: 0x381cb7fa Current: 0x37d48dcf rfs (PID:78515): Effect of primary database OPEN RESETLOGS <---主库 OPEN RESETLOGS 的效果 rfs (PID:78515): Managed Standby Recovery process is active <--MRP0还是 active 2025-09-01T16:00:01.909730+08:00 PR00 (PID:73250): MRP0: Incarnation has changed! Retry recovery... <--MRP0出现Incarnation 分身 2025-09-01T16:00:01.909992+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_pr00_73250.trc: ORA-19906: recovery target incarnation changed during recovery <--恢复过程中恢复目标 incarnation 发生了变化 PR00 (PID:73250): Managed Standby Recovery not using Real Time Apply 2025-09-01T16:00:02.178418+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_78540.trc: ORA-00316: log 16 of thread 1, type 0 in header is not log file ORA-00312: online log 16 thread 1: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_16_kz74ckbv_.log' 2025-09-01T16:00:02.178507+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_78540.trc: ORA-00316: log 16 of thread 1, type 0 in header is not log file ORA-00312: online log 16 thread 1: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_16_kz74ckbv_.log' 2025-09-01T16:00:02.835458+08:00 TT02 (PID:24613): Cannot find SRL for T-1.S-435988 2025-09-01T16:00:03.616687+08:00 Recovery interrupted! 2025-09-01T16:00:04.548867+08:00 Clearing online log 25 of thread 2 sequence number 0 2025-09-01T16:00:05.195481+08:00 Recovered data files to a consistent state at change 123168755979 Stopping change tracking 2025-09-01T16:00:05.215300+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_pr00_73250.trc: ORA-19906: recovery target incarnation changed during recovery <--恢复过程中恢复目标 incarnation 发生了变化 2025-09-01T16:00:05.908878+08:00 TT02 (PID:24613): Cannot find SRL for T-1.S-0 2025-09-01T16:00:05.929365+08:00 Started logmerger process 2025-09-01T16:00:05.931772+08:00 TT02 (PID:24613): Cannot find SRL for T-1.S-435988 2025-09-01T16:00:05.942115+08:00 IM on ADG: End of Empty Journal PR00 (PID:79396): Managed Standby Recovery starting Real Time Apply Warning: Recovery target destination is in a sibling branch of the controlfile checkpoint. Recovery will only recover changes to datafiles. <--恢复目标位置位于同级分支中控制文件检查点。恢复操作仅恢复对数据文件的更改。 Datafile 1 (ckpscn 123168755979) is orphaned on incarnation#=5 <--数据文件1(ckpscn 123168755979)在化身#=5时成为孤立文件 PR00 (PID:79396): MRP0: Detected orphaned datafiles! <--MRP0:检测到孤立的数据文件! 2025-09-01T16:00:06.033747+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_pr00_79396.trc: ORA-19909: datafile 1 belongs to an orphan incarnation <--数据文件1属于一个孤立的化身 ORA-01110: data file 1: '/data/jieke/datafile/system.378.1128999715' PR00 (PID:79396): Managed Standby Recovery not using Real Time Apply Stopping change tracking 2025-09-01T16:00:06.170633+08:00 Recovery Slave PR00 previously exited with exception 19909 2025-09-01T16:00:06.170873+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_mrp0_72231.trc: ORA-19909: datafile 1 belongs to an orphan incarnation <--数据文件1属于一个孤立的化身,Oracle 仅报告遇到的第一个数据文件问题(文件#1)。此时所有数据文件都属于一个孤立的实例 ORA-01110: data file 1: '/data/jieke/datafile/system.378.1128999715'
通常情况下,当备库 resetlogs 打开后会出现这种情况。由于各种原因,备库是以 resetlogs 模式打开的,且相关信息驻留在 FRA 中。RMAN 会隐式地对 FRA 进行编目,从而导致有关此实例的信息被插入到已装载的备用控制文件中,因此,存在有关新实例的信息。 接下来的日志基本上都是“ORA-00316”和“ORA-00312”的关于 redo 文件头损坏的错误,省略部分无关信息。
2025-09-01T16:00:07.046914+08:00 Clearing online log 26 of thread 2 sequence number 0 2025-09-01T16:00:08.178531+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_78540.trc: ORA-00316: log 26 of thread 2, type 0 in header is not log file ORA-00312: online log 26 thread 2: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_26_kz74j9k5_.log' 2025-09-01T16:00:08.178585+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_78114.trc: ORA-00316: log 26 of thread 2, type 0 in header is not log file ORA-00312: online log 26 thread 2: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_26_kz74j9k5_.log' 2025-09-01T16:00:08.571603+08:00 rfs (PID:78515): Opened log for T-1.S-435984 dbid 657075540 branch 1129114545 2025-09-01T16:00:08.813186+08:00 rfs (PID:78515): Archived Log entry 1371162 added for B-1129114545.T-1.S-435984 ID 0x37d48dcf LAD:2 2025-09-01T16:00:08.944878+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_78540.trc: ORA-00316: log 26 of thread 2, type 0 in header is not log file ORA-00312: online log 26 thread 2: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_26_kz74j9k5_.log' 2025-09-01T16:00:16.394238+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_6383.trc: ORA-00316: log 14 of thread 1, type 0 in header is not log file ORA-00312: online log 14 thread 1: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_14_kz749cd6_.log' 2025-09-01T16:00:16.412872+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_85016.trc: ORA-00316: log 14 of thread 1, type 0 in header is not log file ORA-00312: online log 14 thread 1: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_14_kz749cd6_.log' 2025-09-01T16:00:17.235144+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekedg/jieke/trace/jieke_rfs_78114.trc: ORA-00316: log 14 of thread 1, type 0 in header is not log file ORA-00312: online log 14 thread 1: '/data/jieke/fra/jiekeDG/onlinelog/o1_mf_14_kz749cd6_.log' 2025-09-01T16:00:17.398664+08:00 rfs (PID:23835): Opened log for T-1.S-435985 dbid 657075540 branch 1129114545 2025-09-01T16:00:17.659551+08:00 rfs (PID:8672): Opened log for T-2.S-440963 dbid 657075540 branch 1129114545
问题解决
由于也是生产环境,需要优先恢复同步,启动 MRP0 进程,然后再查原因,所以解决办法就是去还原到原来的 incarnation,在以前 duplicate 的时候也遇到过类似的情况,处理也比较简单。 然后分别登录主备库 Rman,查看化身 incarnation,status 列显示当前化身的状态,化身状态一般有如下三种:
ORPHAN- 孤儿化身CURRENT- 数据库的当前化身PARENT- 当前化身的父母

如上图,数据库的 incarnation 化身 1 从 SCN 1 开始,一直持续到 SCN 1000,然后到 SCN 2000。假设在化身 1的 SCN 2000 时,执行了一次时间点恢复到 SCN 1000,然后使用 RESETLOGS 选项打开数据库。化身 2 现在从 SCN 1000 开始,一直持续到 SCN 3000。在这个例子中,化身 1 是化身 2 的父化身。
假设在化身 2 中的 SCN 3000,您执行了到 SCN 2000 的时间点恢复,并使用 RESETLOGS 选项打开了数据库。在这种情况下,化身 2 是化身 3 的父化身。化身 1 是化身 3 的祖先。
当数据库中发生 DBPITR 或闪回数据库时,根据当前版本的不同,一个SCN(系统变更号)可以引用多个时间点。例如,图中的 SCN 1500 可以引用版本 1 或版本 2 中的一个 SCN。
您可以使用 RESET DATABASE TO INCARNATION 命令来指定在特定数据库版本的参照系中解释 SCN。当您使用FLASHBACK、RESTORE 或 RECOVER 返回至非当前数据库版本的某个 SCN 时,需要使用 RESET DATABASE TO INCARNATION 命令。但是,如“在恢复目录中重置数据库版本”所述,RMAN 在执行 FLASHBACK 时会自动执行RESET DATABASE TO INCARNATION 命令。
所以我们通过 rman reset database 设置一下就好,但这次执行 reset 却报错了,说已经存在于控制文件中无法删除,无奈还是提紧急变更,重启数据库到 mount 后 reset database 得到恢复。
--主库 select * from v$database_incarnation;
RMAN> list incarnation of database;
List of Database Incarnations
DB Key Inc Key DB Name DB ID STATUS Reset SCN Reset Time
------- ------- -------- ---------------- --- ---------- ----------
1 1 JIEKEXU 657075540 PARENT 1 2013-08-24 11:37:30
2 2 JIEKEXU 657075540 PARENT 925702 2016-10-27 10:24:22
3 3 JIEKEXU 657075540 PARENT 1682404406 2019-08-24 12:12:47
4 4 JIEKEXU 657075540 ORPHAN 71803922170 2023-02-07 16:31:34
5 5 JIEKEXU 657075540 CURRENT 72450305224 2023-02-18 10:55:45
备库和级联备库操作如下:
--级联备库和备库操作
SQL> shu immediate
SQL> startup mount
RMAN> list incarnation of database;
List of Database Incarnations
DB Key Inc Key DB Name DB ID STATUS Reset SCN Reset Time
------- ------- -------- ---------------- --- ---------- ----------
1 1 JIEKEXU 657075540 PARENT 1 2013-08-24 11:37:30
2 2 JIEKEXU 657075540 PARENT 925702 2016-10-27 10:24:22
3 3 JIEKEXU 657075540 PARENT 1682404406 2019-08-24 12:12:47
4 4 JIEKEXU 657075540 ORPHAN 71803922170 2023-02-07 16:31:34
5 5 JIEKEXU 657075540 PARENT 72450305224 2023-02-18 10:55:45
6 6 JIEKEXU 657075540 ORPHAN 77904788037 2023-07-15 11:19:45
7 7 JIEKEXU 657075540 CURRENT 123168223876 2025-09-01 15:59:22
RMAN> reset database to incarnation 5;
RMAN> list incarnation;
RMAN> sql'alter database open';
问题原因
事后通过排查 alert 日志发现,是由于要激活的这个备库上的 ARCn 进程将归档日志文件(包含实例变更)发送到他现在配置的备库,备库又配置了级联备库,级联备库能够识别备库上的实例变更,并停止MRP0进程,导致这两个备库均出现中断。下面来根据时间点看看日志内容就清楚了,通过查看 alert 日志 2025-09-01 15:59:22 执行激活读写命令,然后接着数据库自己执行了 resetlogs 命令,恢复到 SCN 123168223875 time 09/01/2025 15:52:15时。
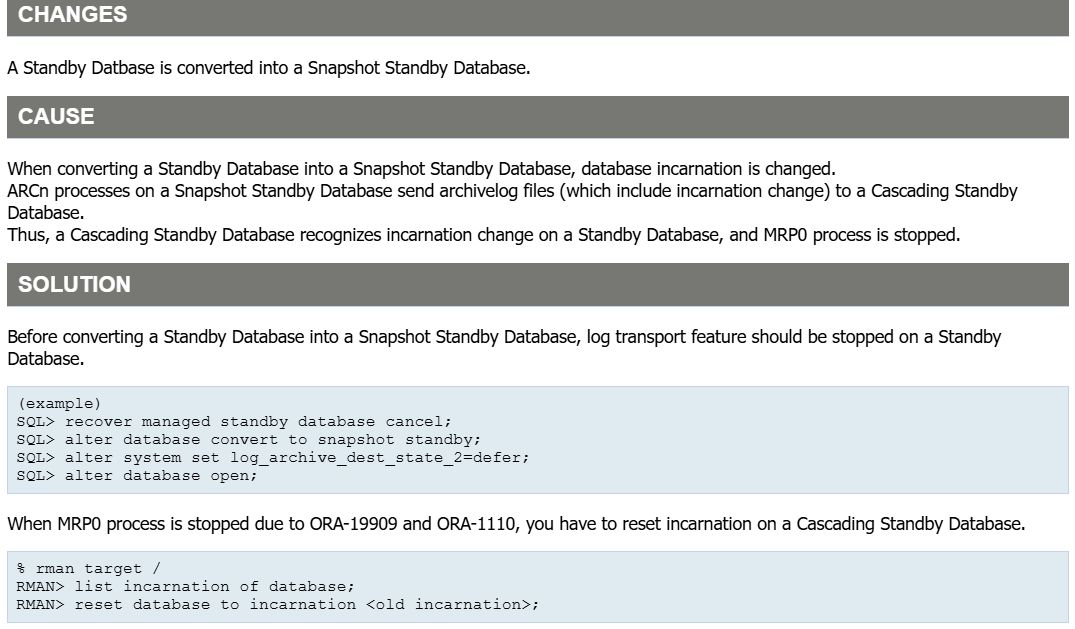
2025-09-01T15:58:49.980265+08:00 Created guaranteed restore point FLASHBACK_20250901 2025-09-01T15:59:22.048193+08:00 alter database activate standby database 2025-09-01T15:59:22.048238+08:00 ALTER DATABASE ACTIVATE [PHYSICAL] STANDBY DATABASE [Process Id: 2463823] (jiekeot1) 2025-09-01T15:59:22.056741+08:00 .... (PID:2463823): Begin: SRL archival .... (PID:2463823): End: SRL archival RESETLOGS after incomplete recovery UNTIL CHANGE 123168223875 time 09/01/2025 15:52:15 NET (PID:2463823): Disable RFS client [kcrlc.c:1526]
然后就出现了开头日志中的错误,这个时候我们激活的这个 1 号库就是读写模式的主库了,但他的配置中还有 DG 配置信息没有清除,导致归档日志传到了 2 号库。如下,log_archive_dest_2 配置的是 2 号库地址且配置为ONLINE_LOGFILES,PRIMARY_ROLE,所以当变为读写库时日志就传递到 2 号库,3 号库是正常的级联备库,所以归档日志也就传到了 3 号库,1 号库的激活过程 resetlogs 等操作就传到了这两个库,导致 MRP 发生化身,MRP0 进程全部挂掉。
SQL> show parameter log_archive_dest_2
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_dest_2 string SERVICE=jiekedg LGWR ASYNC VA
LID_FOR=(ONLINE_LOGFILES,PRIMA
RY_ROLE) DB_UNIQUE_NAME=jiekeDG
SQL> show parameter log_archive_dest_state_2
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_dest_state_2 string ENABLE
SQL> ! tnsping jiekeDG
TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 11-SEP-2025 17:36:31
Copyright (c) 1997, 2024, Oracle. All rights reserved.
Used parameter files:
/u01/app/oracle/product/19.0.0/dbhome_1/network/admin/sqlnet.ora
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.132.132)(PORT = 11522)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = jiekedg)))
OK (0 msec)
这里大概说一下log_archive_dest_2 VALID_FOR=(redo_log_type,database_role) 参数格式:
-
可用日志文件类型:online_logfile,standby_logfile, all_logfiles
-
可用的角色类型:primary_role, standby_role, all_roles
说明如下:
(1)redo_log_type 关键字表明该目的地产生归档的 redo 日志类型
- online_logfile:目的地只归档联机redo日志
- standby_logfile:目的地只归档standbyredo日志
- all_logfiles:目的地既归档联机redo日志,也归档standby redo日志
(2)database_role 表明该目的地产生归档的数据库角色
- primary_role:只有数据库是主库时,该目的地才会产生归档
- standby_role:只有数据库是备库时,该目的地才会产生归档
- all_role:当数据库不论是主库还是备库时,该目的地都会产生归档
其他参数可以查看官方文档或我之前写的一篇DG参数详解,[爆肝一万字终于把 Oracle Data Guard 核心参数搞明白了](https://mp.weixin.qq.com/s/m1S-ElWOYf_h2kcrre5HNA)。然后查看 alert 日志在 2025-09-03 09:07:35 时分,log_archive_dest_state_2 才被重置成 defer,清理掉了备库配置,所以之前都是一直在传递归档日志的。
ALTER SYSTEM SET log_archive_config='' SCOPE=BOTH; 2025-09-03T09:06:31.116758+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekeot/jiekeot1/trace/jiekeot1_ppa7_2475002.trc: ORA-16057: Data Guard 配置中没有服务器 2025-09-03T09:06:31.116795+08:00 NET (PID:2475002): krsg_check_connection: Error 16057 connecting to standby 'jiekedg' 2025-09-03T09:06:31.276741+08:00 Errors in file /u01/app/oracle/diag/rdbms/jiekeot/jiekeot1/trace/jiekeot1_ppa7_2475002.trc: ORA-16057: Data Guard 配置中没有服务器 NET (PID:2475002): krsg_check_connection: Error 16057 connecting to standby 'jiekedg' 2025-09-03T09:07:35.594029+08:00 ALTER SYSTEM SET log_archive_dest_state_2='DEFER' SCOPE=BOTH; 2025-09-03T09:07:57.366605+08:00 ALTER SYSTEM SET fal_server='' SCOPE=BOTH;
然而另外一套也是同样的操作却没有发生这样的问题,排查后发现 log_archive_dest_2 虽然配置了备库的地址,但是 tnsping 发现不通,日志没传递过去,也就避免了这样的事情发生。
log_archive_dest_2 string service=edstd ASYNC valid_for
=(online_logfiles,primary_role
) compression=enable db_unique
_name=edstd
SQL> ! tnsping edstd
TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 11-SEP-2025 17:38:19
Copyright (c) 1997, 2024, Oracle. All rights reserved.
Used parameter files:
/u01/app/oracle/product/19.0.0/dbhome_1/network/admin/sqlnet.ora
TNS-03505: Failed to resolve name
事后总结
细节决定成败,当任何细小的环节被忽略就会导致出错的概率增大,进而影响我们的判断,当在发生这种事情的时候,应该需要规划更具体的步骤,比如清理要激活的库的控制文件自动备份,FRA 里的闪回日志以及应用完的归档日志,再者修改此库的关于 DG 的一些参数配置,防止变成主库后传递归档日志到其他相关的主备库或级联库造成 incarnation 分身,MRP 进程中断无法继续同步数据。
--查看控制文件自动备份位置,进而删除
RMAN> show all;
-- 关闭闪回 清理归档日志
SQL> alter database flashback off;
--清理DG相关配置
SQL> alter system reset log_archive_dest_2 SCOPE=BOTH;;
SQL> alter system set log_archive_dest_2='' SCOPE=BOTH;;
SQL> alter system set log_archive_dest_state_2=‘defer’ SCOPE=BOTH;;
SQL> alter system set log_archive_config='' SCOPE=BOTH;
SQL> alter system set fal_server='' SCOPE=BOTH;
参考文章
ORA-19906 and ORA-19909 at standby site (Doc ID 1509932.1) MRP0 Process on Cascading Standby Database Is Stppped After Converting to Snapshot Standby By ORA-19909 ORA-1110 (Doc ID 2654140.1) https://docs.oracle.com/en/database/oracle/oracle-database/19/bradv/rman-data-repair-concepts.html#GUID-9942AC94-A35D-4A06-9A45-A5A43B82B23D https://docs.oracle.com/en/database/oracle/oracle-database/19/bradv/managing-recovery-catalog.html#GUID-304B2237-0921-422F-A084-D83E7B5C8D2B
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
——————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
——————————————————————————

