




一、引言
⚠️ 1.1 数据库模型评审的五大挑战
🔸 命名混乱:大小写/下划线混用,影响可读性
🔸 术语不统一:同一概念不同命名(如order vs purchase)
🔸 语义歧义:表名与描述不符(如user_info描述为"订单记录")
🔸 维护困难:不规范设计导致后期优化成本高
🔸 效率低下:200张表评审需2-3天
✨ 1.2 智能评审四大优势
✅ 极速高效:1小时完成传统2天工作量
✅ 精准可靠:98%+准确率(基于Dify+大模型)
✅ 无缝对接:完美兼容现有流程(Excel输入/标准化报告)
✅ 持续学习:基于反馈不断优化评审规则
二、技术实现
2.1 智能审核流程图
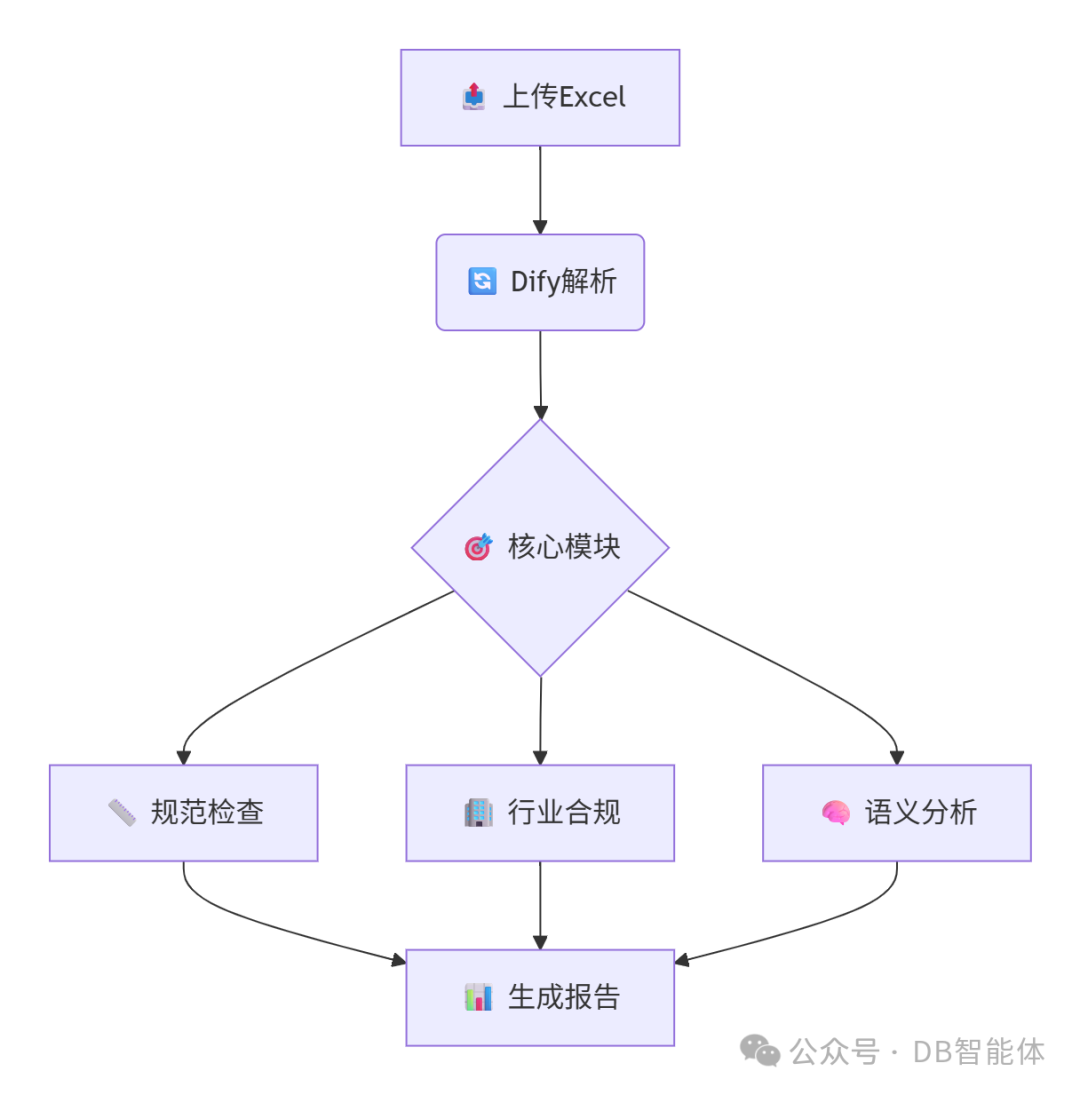
🔍 2.2 核心功能详解
(1)规范检查:从基础规则到智能建议
命名规范检测:
✅ 表名规范:强制snake_case格式
✅ 字段名检测:禁止使用保留字(如select, group)
智能动态建议:
✅ 检测到usr→ 建议改为user
✅ 发现amt→ 提示"建议使用完整术语amount"
✅ 位置校验:主键字段必须位于前3列
(2)行业合规:知识库驱动的专业评审
术语库智能匹配:
行业 | 标准术语 | 常见错误 |
|---|---|---|
🏦 金融 | amount | amt |
🛒 电商 | order | ord |
🏥 医疗 | patient | pt |
缩写校验规则:
✅ 允许标准缩写:id, num, desc
❌ 禁止非标准缩写:cust代替customer
(3)语义分析:大模型的深度应用
表名与描述一致性检测:
✅ 计算user_info与"用户基本信息"的语义相似度(阈值>90%)
✅ 自动识别描述与表名不符的异常情况
多场景歧义检测:
✅ 金融场景:account应解释为"资金账户"而非"登录账号"
✅ 社交场景:friend需明确是"单向关注"还是"双向好友"
三、实战展示
📥 3.1 输入Excel示例
📊 3.2 结果报告

四、实际效益
维度 | 传统人工审核 👨💻 | AI自动化审核 🤖 | 提升效果 📊 |
|---|---|---|---|
效率 | 慢,串行,依赖专家时间 | 极快,并行,7x24小时 | ⚡ 指数级提升 |
成本 | 高(资深专家人力成本) | 低(一次建设,长期复用) | 💰 降本90%+ |
质量 | 依赖个人能力,标准不一 | 标准统一,客观全面 | ✅ 质量稳定性100% |
知识沉淀 | 经验存在于专家头脑中 | 规则固化在系统中 | 🏛️ 企业资产化 |
流程 | 事后检查,返工成本高 | 左移前置,即时反馈 | 🛡️ 防患于未然 |
五、扩展
1. 企业级定制方案
⚡ 电力行业:合规字段检测与安全校验
🏥 医疗行业:敏感字段自动脱敏规则
🏦 金融行业:监管合规性自动检查
🛒 电商行业:业务术语一致性验证
2. 生成大模型训练素材,助力text-to-sql的成长
json
{"question":"查询未对账的VIP客户交易","sql":"SELECT * FROM transaction WHERE customer_level='VIP' AND is_reconciled=0"}
更多数据库AI落地场景
🌐 请关注:https://github.com/zqf20096327/dify_for_db

