




上篇文章介绍了,利用ELK实现MySQL审计日志可视化,其核心在于logstash的pipeline的配置,本篇将介绍如何编写采集MySQL慢日志的pipeline配置文件。相对于审计日志来说,慢日志的配置要更复杂一些,因为审计日志的每一行记录都是json格式,而慢日志文件中一条慢日志记录会跨越多行,需要把多行合并成一个事件,这时候codec需要用到grok。
mysql_slowlog.conf
input {
file {
path => "/data/mysql/log/slow.log" # 慢日志路径
start_position => "beginning"
sincedb_path => "/var/lib/logstash/sincedb_mysql_slowlog"
codec => multiline {
pattern => "^# Time:" # 遇到 # Time 开始新事件
negate => true
what => "previous"
}
}
}
filter {
# 提取时间
grok {
match => { "message" => "# Time: %{TIMESTAMP_ISO8601:log_time}" }
add_tag => ["mysql_slow"]
}
# 提取用户和 host 信息
grok {
match => { "message" => "# User@Host: %{DATA:user}\[%{DATA:username}\] @ *\[?(%{IP:host})?\]? *Id:\s*%{NUMBER:thread_id}" }
}
# 提取执行信息
grok {
match => { "message" => "# Query_time:\s*%{NUMBER:query_time:float}\s*Lock_time:\s*%{NUMBER:lock_time:float}\s*Rows_sent:\s*%{NUMBER:rows_sent:int}\s*Rows_examined:\s*%{NUMBER:rows_examined:int}" }
}
# 去掉注释和 SET timestamp,保留 SQL
mutate {
gsub => [
"message", "^#.*\n", "", # 去掉 # 开头的注释
"message", "^SET timestamp=.*;\n", "" # 去掉 SET timestamp
]
}
mutate {
rename => { "message" => "sql" }
}
# 时间字段映射为 @timestamp
date {
match => ["log_time", "ISO8601"]
target => "@timestamp"
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["http://xxx:9200"]
user => "elastic"
password => "xxx"
index => "mysql_slowlog-%{+YYYY.MM.dd}"
ilm_enabled => false
}
}
MySQL慢日志的格式如下所示:
# Time: 2025-09-12T07:32:37.543801Z
# User@Host: root[root] @ [10.xxx.xxx.xxx] Id: 94
# Query_time: 4.000326 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
SET timestamp=1757662353;
select sleep(4);
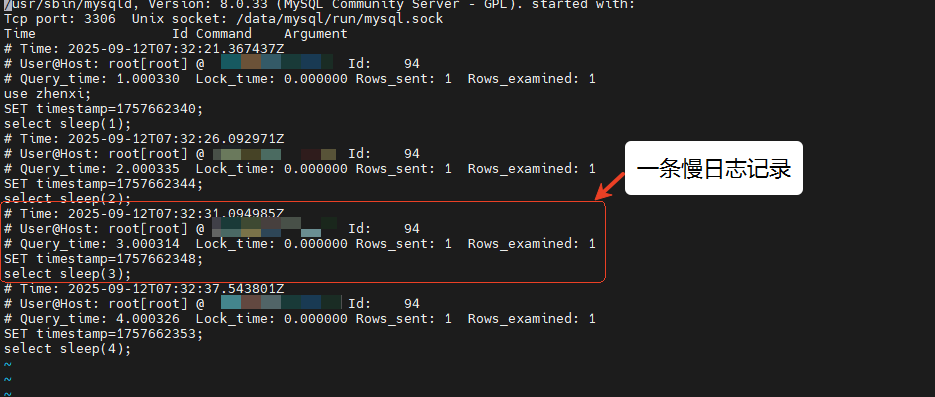
以下内容是对配置内容的解析。
Input部分
input {
file {
path => "/data/mysql/log/slow.log" # 慢日志路径
start_position => "beginning"
sincedb_path => "/var/lib/logstash/sincedb_mysql_slowlog"
codec => multiline {
pattern => "^# Time:" # 遇到 # Time 开始新事件
negate => true
what => "previous"
}
}
}
file{...}: 告诉Logstash从文件读取数据,这里是Path配置的路径:/data/mysql/log/slow.log start_position => "beginning": 第一次启动,从文件开头读取。 sincedb_path: 记录审计文件的读取进度,防止重复发送。 codec => multiline { ... }: 指定多行合并逻辑:从 # Time:
开始,到下一个# Time:
开始前的所有行被合并为一个事件。pattern => "^# Time:":匹配以开头 # Time:
的行。negate => true:表示不匹配正则表达式的行属于前一行内容的一部分。如果一行不是以 # Time:
开头,那它就属于上一行的内容。what => "previous":表示匹配到的行应该拼接到 上一行。
Filter部分
filter {
# 提取时间
grok {
match => { "message" => "# Time: %{TIMESTAMP_ISO8601:log_time}" }
add_tag => ["mysql_slow"]
}
# 提取用户和 host 信息
grok {
match => { "message" => "# User@Host: %{DATA:user}\[%{DATA:username}\] @ *\[?(%{IP:host})?\]? *Id:\s*%{NUMBER:thread_id}" }
}
# 提取执行信息
grok {
match => { "message" => "# Query_time:\s*%{NUMBER:query_time:float}\s*Lock_time:\s*%{NUMBER:lock_time:float}\s*Rows_sent:\s*%{NUMBER:rows_sent:int}\s*Rows_examined:\s*%{NUMBER:rows_examined:int}" }
}
# 去掉注释和 SET timestamp,保留 SQL
mutate {
gsub => [
"message", "^#.*\n", "", # 去掉 # 开头的注释
"message", "^SET timestamp=.*;\n", "" # 去掉 SET timestamp
]
}
mutate {
rename => { "message" => "sql" }
}
# 时间字段映射为 @timestamp
date {
match => ["log_time", "ISO8601"]
target => "@timestamp"
}
}
1.第一条grok:提取时间
grok {
match => { "message" => "# Time: %{TIMESTAMP_ISO8601:log_time}" }
add_tag => ["mysql_slow"]
}
match:匹配# Time: 后面的ISO8601时间,提取数据到log_time字段。 add_tag:给事件加上标签mysql_slow,也就是在对象中加一个tags字段。
2.第二条grok:提取用户和 host 信息
# 提取用户和 host 信息
grok {
match => { "message" => "# User@Host: %{DATA:user}\[%{DATA:username}\] @ *\[?(%{IP:host})?\]? *Id:\s*%{NUMBER:thread_id}" }
}
match: 正则匹配以 # User@Host
开头的整体结构,从中提取user、username、host、thread_id。日志行类似: # User@Host: root[root] @ [10.xxx.xxx.xxx] Id: 94
3.第三条grok:提取执行信息
# 提取执行信息
grok {
match => { "message" => "# Query_time:\s*%{NUMBER:query_time:float}\s*Lock_time:\s*%{NUMBER:lock_time:float}\s*Rows_sent:\s*%{NUMBER:rows_sent:int}\s*Rows_examined:\s*%{NUMBER:rows_examined:int}" }
}
match: - 匹配 # Query_time: ... Lock_time: ... Rows_sent: ... Rows_examined: ...
,从中提取query_time、lock_time、rows_sent、rows_examined。日志行类似: # Query_time: 4.000326 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 SET timestamp=1757662353;
4.mutate+gsub:去除注释和SET timestamp
# 去掉注释和 SET timestamp,保留 SQL
mutate {
gsub => [
"message", "^#.*\n", "", # 去掉 # 开头的注释
"message", "^SET timestamp=.*;\n", "" # 去掉 SET timestamp
]
}
5. mutate rename:重命名字段
mutate {
rename => { "message" => "sql" }
}
rename: message
字段改名为sql
6. date:把log_time映射到@timestamp
# 时间字段映射为 @timestamp
date {
match => ["log_time", "ISO8601"]
target => "@timestamp"
}
match: 匹配log_time字段 target: 将它映射到@timestamp字段。在Logstash中,每个事件都有一个默认的事件字段:@stimestamp字段。如果不处理,Logstash存的@timestamp就是”日志到达Logstash的时间“ ,而不是SQL执行时间。
Output部分
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["http://xxx:9200"]
user => "elastic"
password => "xxx"
index => "mysql_slowlog-%{+YYYY.MM.dd}"
ilm_enabled => false
}
}
stdout { codec => rubydebug } 在终端输出每条事件的完整内容,方便调试 elasticsearch { ... } 输出到 Elasticsearch hosts
→ ES 地址user
/password
→ 认证index
→ 索引名,按日期创建,例如mysql_slowlog-2025.09.12ilm_enabled => false
→ 不启用 Elasticsearch 的 Index Lifecycle Management(ILM)
多pipeline
如笔者在开篇提到的,我们之前已经添加过采集MySQL审计日志的pipeline,现在要再添加采集MySQL慢日志的pipeline,我们就需要使用多pipeline配置,否则可能出现mysql_slowlog中写入的是audit.log的内容这样错乱的日志。 在/etc/logstash/pipelines :
- pipeline.id: mysql_slow
path.config: "/etc/logstash/conf.d/mysql_slow.conf"
- pipeline.id: mysql_audit
path.config: "/etc/logstash/conf.d/mysql_audit.conf"
参考:
https://www.elastic.co/cn/support/matrix#matrix_compatibility https://www.elastic.co/guide/en/kibana/7.17/setup.html
推荐阅读:

点个“赞 or 在看” 你最好看!
👇👇👇 谢谢各位老板啦!!
文章转载自PostgreSQL运维技术,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
