1.确认备份信息
确保生产库备份(数据文件、控制文件、归档日志)已注册到catalog目录库;确认恢复的数据文件号
rman target / catalog rasys/welcome1@ra
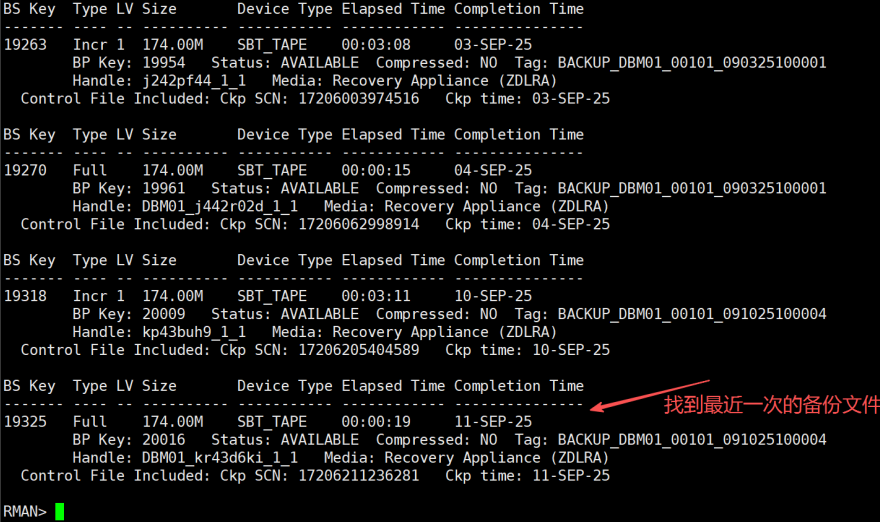
list backup of datafile 1,2,3,4,12;
2.测试库软件已安装,数据库已安装;现在把数据库关闭并删除相关路径
删除审计(2个节点操作):rm -rf /u01/oracle/admin/dbm01/adump/*.aud
删除asm下dbm01相关目录:
cd +datac1/dbm01
rm -rf datafile
rm -rf onlinelog
rm -rf tempfile
rm -rf controlfile
rm -rf changetracking
rm -rf spfile/spfilehfkdb.ora
cd +recoc1/dbm01
rm -rf archivelog
rm -rf onlinelog

3.测试库创建参数文件
vi /home/oracle/dbm01.ora
*.MEMORY_TARGET=10G
*._clusterwide_global_transactions=FALSE
*.audit_file_dest='/u01/oracle/admin/dbm01/adump'
*.audit_trail='db'
*.cluster_database=FALSE #创建库这个要为false,否则会报错
*.compatible='11.2.0.4.0'
*.control_files='+DATAC1','+DATAC1'
*.db_block_size=8192
*.db_create_file_dest='+DATAC1'
*.db_domain=''
*.db_name='dbm01'
*.db_recovery_file_dest='+DATAC1'
*.db_recovery_file_dest_size=21474836480
*.diagnostic_dest='/u01/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=dbm01XDB)'
*.enable_goldengate_replication=TRUE
dbm012.instance_number=2
dbm011.instance_number=1
*.log_archive_dest_1='location=+RECOC1'
*.log_archive_format='arch_%t_%s_%r.log'
*.open_cursors=300
*.processes=2000
*.remote_listener='ceshidb-scan:1521'
*.remote_login_passwordfile='exclusive'
*.sessions=2205
dbm012.thread=2
dbm011.thread=1
dbm012.undo_tablespace='UNDOTBS2'
dbm011.undo_tablespace='UNDOTBS1'export ORACLE_SID=dbm012
sqlplus / as sysdba
create spfile='+DATAC1/dbm01/spfile/spfiledbm01.ora' from pfile='/home/oracle/dbm01.ora';
两个节点创建pfile内容指向共享设备的spfile文件
[oracle@ceshidb01 dbs]$ cat initdbm011.ora
SPFILE='+datac1/dbm01/spfile/spfiledbm01.ora'
[oracle@ceshidb02 dbs]$ cat initdbm012.ora
SPFILE='+datac1/dbm01/spfile/spfiledbm01.ora'4.创建口令文件,两个节点都操作
cd $ORACLE_HOME/dbs
orapwd file=orapwdbm011 password=oracle entries=10
orapwd file=orapwdbm012 password=oracle entries=105.恢复控制文件(在节点2上操作)
export ORACLE_SID=dbm012
startup nomount;
lsnrctl status #查看监听,nomount下状态为blocked

set dbid不会改变实际连接的数据库实例,只是告诉rman知道后续操作应该关联到哪个dbid的备份记录。如果恢复目录中有生产库的控制文件备份,rman会根据当前设置的dbid(即生产库的dbid)查找对应的控制文件备份,并将其恢复到目标数据库(也就是当前通过target /连接的测试库)。
所有操作都是在测试库上进行,设置dbid只是让rman从恢复目录获取对应生产库的备份信息。
export ORACLE_SID=dbm012
rman target / catalog rasys/welcome1@ra
SET DBID=1123023669; #设置生产库的dbid,让rman识别catalog中的生产库备份
--从catalog恢复生产库的控制文件
run {
allocate channel c1 device type 'SBT_TAPE' parms "SBT_LIBRARY=/u01/oracle/product/11.2.0/dbhome_1/lib/libra.so, ENV=(RA_WALLET='location=file:/u01/oracle/product/11.2.0/dbhome_1/dbs/zdlra credential_alias=za01ingest-scan:1521/zdlra:dedicated',_RA_AUTH_SCHEME=BASIC)";
restore controlfile from 'DBM01_kr43d6ki_1_1';
release channel c1;
}
--挂载数据库
RMAN> ALTER DATABASE MOUNT;
--检查控制文件内容
report schema;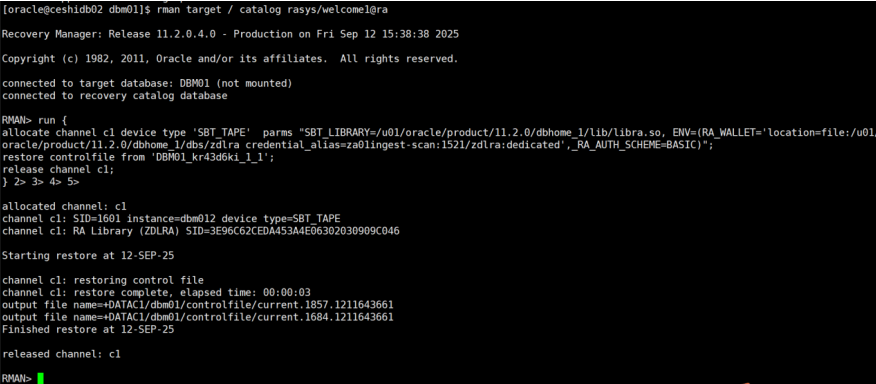
6.执行数据文件的还原和恢复(在节点2上操作)
注意点:
1)恢复时如果存在增量备份,rman会先应用增量备份,而不是仅仅使用归档日志,因为增量备份可能包含更少的数据块变化,从而加快数据恢复过程。
2)restore 0级备份后,如果有可用的1级备份,先recover 1级备份,然后应用剩余的归档日志。
3)增量备份通过物理块的直接覆盖,跳过了大量日志解析,相比应用归档要快的多
4)恢复时主要依据数据文件头的scn,当进行介质恢复时,rman会根据数据文件头的scn来确定需要应用的日志起点,因为恢复的目的是将数据文件推进到某一致点。
5)如果控制文件scn高于数据文件头scn,恢复时要将数据文件头scn提升到控制文件记录的scn,或者选择中间的scn,以免数据不一致。
6)若控制文件和数据文件SCN不匹配,Oracle会自动调整恢复终点。
7)控制文件:scn来自备份时的控制文件快照,表示备份时刻的全局一致性点
8)数据文件头:scn来自数据文件备份时的检查点scn,表示该文件最后一次被正确写入的时间点。此处控制文件比数据文件新,是因为后面备份的控制文件
9)recover后,不管是数据文件scn还是控制文件scn都会追加归档日志到until时刻对应的scn位置;所有数据文件头和控制文件记录的scn要完全一致(等于until时刻scn);
export ORACLE_SID=dbm012
rman target / catalog rasys/welcome1@ra
设置zdlra备份参数(也可在run块里分配通道)
CONFIGURE CHANNEL DEVICE TYPE 'SBT_TAPE' PARMS "SBT_LIBRARY=/u01/oracle/product/11.2.0/dbhome_1/lib/libra.so, ENV=(RA_WALLET='location=file:/u01/oracle/product/11.2.0/dbhome_1/dbs/zdlra credential_alias=za01ingest-scan:1521/zdlra:dedicated',_RA_AUTH_SCHEME=BASIC)";
--从catalog还原restore生产库的指定数据文件
--还原前可以先查看相关数据文件有哪些日期的备份,
如果没有连接catalog,查看相关数据文件是恢复的控制文件所在时间的文件!!
如果连接catalog,即使恢复的控制文件是旧的,查看里面相关数据文件备份依然是有最新的!!
如果想恢复旧的数据文件,需要指定时间如下
list backup of datafile 1;
RESTORE DATAFILE 1 until time "to_date('2025-04-04 00:00:00', 'YYYY-MM-DD HH24:MI:SS')";
默认情况下,restore会使用最新的备份,而recover会尝试恢复到最新的时间点,可能导致数据不一致。
因此,在时间点恢复时,明确指定SET UNTIL TIME是必要的。
RUN {
SET UNTIL TIME "TO_DATE('2025-09-11 16:00:00', 'YYYY-MM-DD HH24:MI:SS')";
allocate channel c1 device type 'SBT_TAPE' parms "SBT_LIBRARY=/u01/oracle/product/11.2.0/dbhome_1/lib/libra.so, ENV=(RA_WALLET='location=file:/u01/oracle/product/11.2.0/dbhome_1/dbs/zdlra credential_alias=za01ingest-scan:1521/zdlra:dedicated',_RA_AUTH_SCHEME=BASIC)";
SET NEWNAME FOR DATAFILE 1 TO '+DATAC1/dbm01/datafile/system.259.954678405';
SET NEWNAME FOR DATAFILE 2 TO '+DATAC1/dbm01/datafile/sysaux.260.954678407';
SET NEWNAME FOR DATAFILE 3 TO '+DATAC1/dbm01/datafile/undotbs1.261.954678409';
SET NEWNAME FOR DATAFILE 4 TO '+DATAC1/dbm01/datafile/undotbs2.263.954678415';
SET NEWNAME FOR DATAFILE 12 TO '+DATAC1/dbm01/datafile/ybptfw_data.305.955381567';
RESTORE DATAFILE 1;
RESTORE DATAFILE 2;
RESTORE DATAFILE 3;
RESTORE DATAFILE 4;
RESTORE DATAFILE 12;
SWITCH DATAFILE all;
release channel c1;
}--从catalog恢复应用归档 跳过没有还原的表空间
RUN {
allocate channel c1 device type 'SBT_TAPE' parms "SBT_LIBRARY=/u01/oracle/product/11.2.0/dbhome_1/lib/libra.so, ENV=(RA_WALLET='location=file:/u01/oracle/product/11.2.0/dbhome_1/dbs/zdlra credential_alias=za01ingest-scan:1521/zdlra:dedicated',_RA_AUTH_SCHEME=BASIC)";
recover database until time "to_date('2025-09-11 16:00:00', 'YYYY-MM-DD HH24:MI:SS')" skip tablespace USERS,USER_R ;
release channel c1;
}7.目录库查看restore备份集信息
select *
from RC_BACKUP_PIECE a
where a.handle in ('VB$_4102852858_38350372_1',
'VB$_4102852858_38350310_2',
'VB$_4102852858_38354973_3',
'VB$_4102852858_38351295_4',
'VB$_4102852858_38350514_12');

8.修改redo日志文件路径(在节点2上操作)
可以直接从源库查询相关redo,并在恢复库上进行alter。也可以直接在恢复库上重建redo。
--源库查询并修改语句
select 'alter database rename file ''' || member ||'''' || ' to '''|| substr(member,0,instr(member,'/',-1) -1)|| '' || substr(member,instr(member,'/',-1)) ||''';'
from v$logfile;
--目标库执行,如果两边路径一致可不操作
alter database rename file '+DATAC1/dbm01/onlinelog/group_6.269.954678833' to '+DATAC1/dbm01/onlinelog/group_6.269.954678833'; 9.打开数据库(在节点2上操作)
ALTER DATABASE OPEN RESETLOGS;
如果出现如下报错:
ERROR at line 1:
ORA-19809: limit exceeded for recovery files
ORA-19804: cannot reclaim 4296015872 bytes disk space from 21474836480 limit解决方法:
alter system set db_recovery_file_dest_size=600G scope=both;
10.重建temp表空间(也可不操作,打开数据库时会自动创建)(在节点2上操作)
select name from v$tempfile;
create temporary tablespace TEMP1; OMF管理
SQL> create temporary tablespace TEMP1 tempfile '+datac1/dbm01/tempfile/temp01.dbf' size 50M;
SQL> alter database default temporary tablespace TEMP1;
SQL> drop tablespace TEMP including contents and datafiles;11.检查控制文件和数据文件头记录的scn是否一致(在节点2上操作)
set numw 15
select checkpoint_change# from v$datafile;
select checkpoint_change# from v$datafile_header;
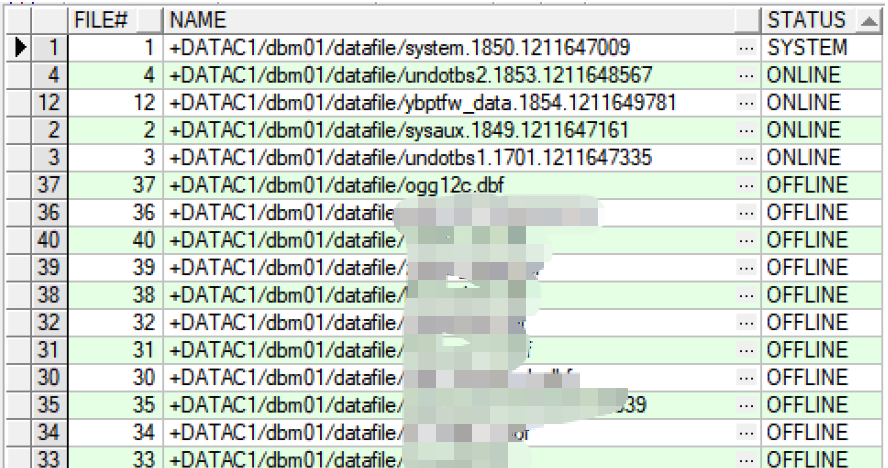
12.验证恢复结果,除了恢复的数据文件,别的都是offline
SELECT FILE#, NAME, STATUS FROM V$DATAFILE;
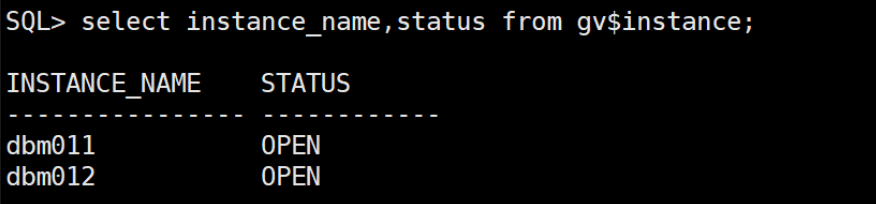
13.修改rac参数,并启动节点1实例
--节点2
alter system set cluster_database=true scope=spfile;
alter system set cluster_database_instances=2 scope=spfile;
shutdown immediate;
startup
--节点1
export ORACLE_SID=dbm011
startup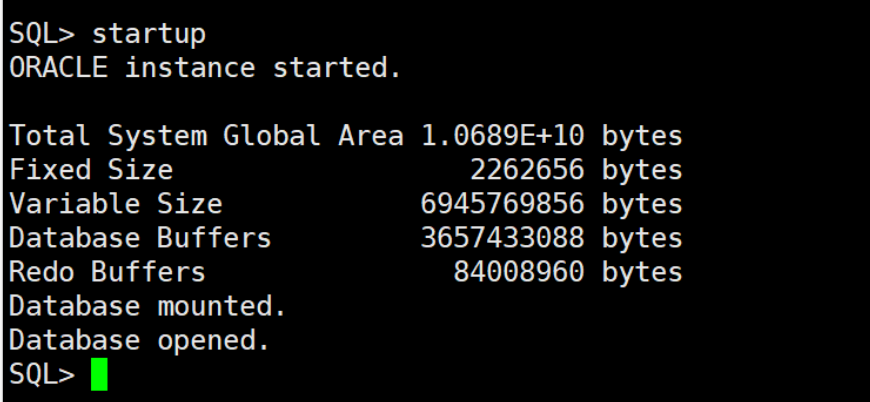
14.注册database、instance
由于rac是基于crs管理的,需要把database和instance注册到crs里管理
--注册数据库
srvctl add database -d dbm01 -o $ORACLE_HOME
--注册实例
srvctl add instance -d dbm01 -i dbm011 -n ceshidb01
srvctl add instance -d dbm01 -i dbm012 -n ceshidb02
crs_start -f ora.dbm01.db
--数据库启停
srvctl start database -d dbm01
srvctl stop database -d dbm0115.v$recovery_file_dest空间清理
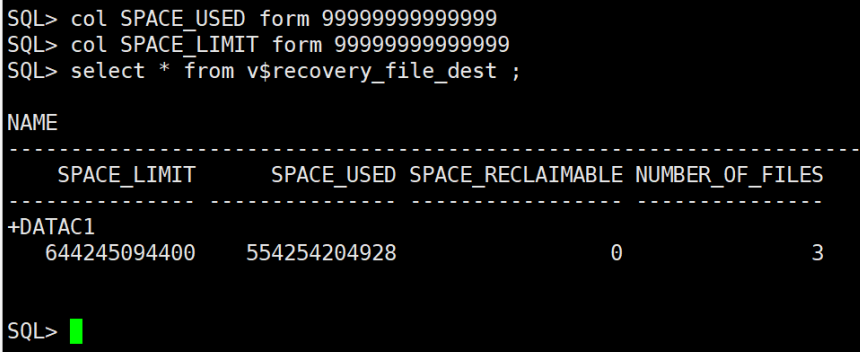
数据库打开的时候报错空间不足,查询v$recovery_file_dest视图发现已经使用了500多G,这个视图存放文件总数量、位置、磁盘限额、已用空间等;
通过查询v$flash_recovery_area_usage;包括控制文件、在线重做日志、备份片、镜像拷贝、闪回日志、外部归档文件,通过删除废弃或冗余的文件回收空间。
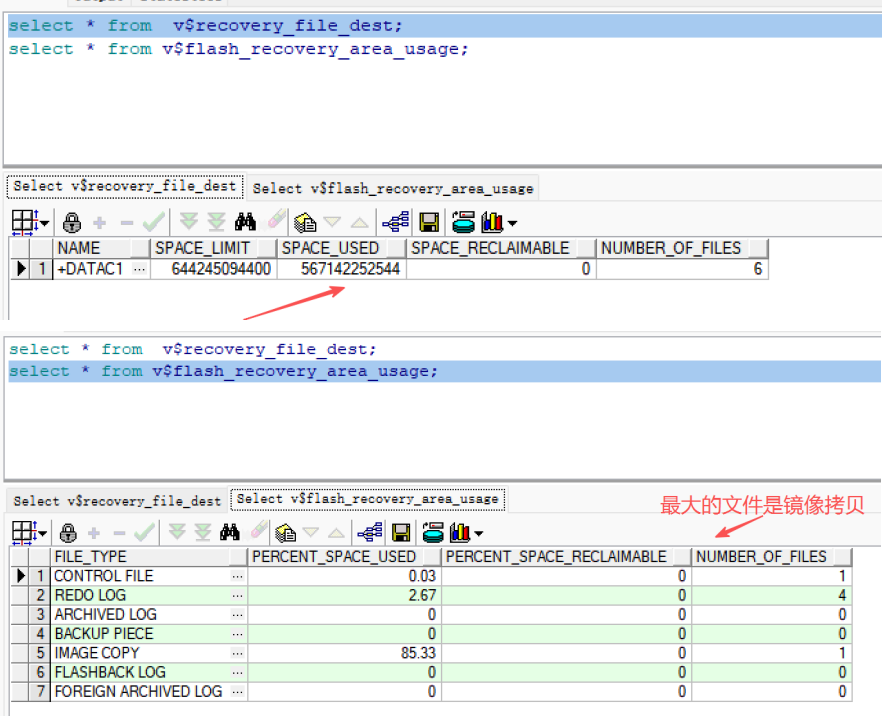
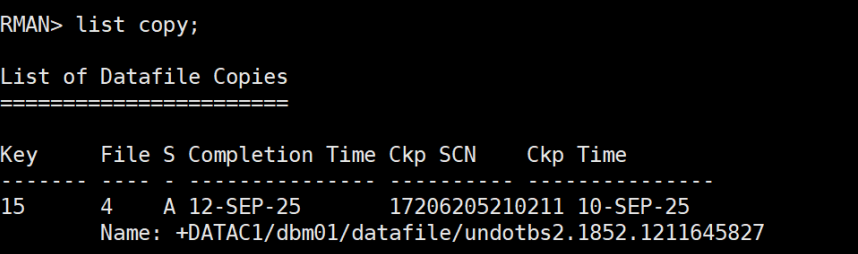
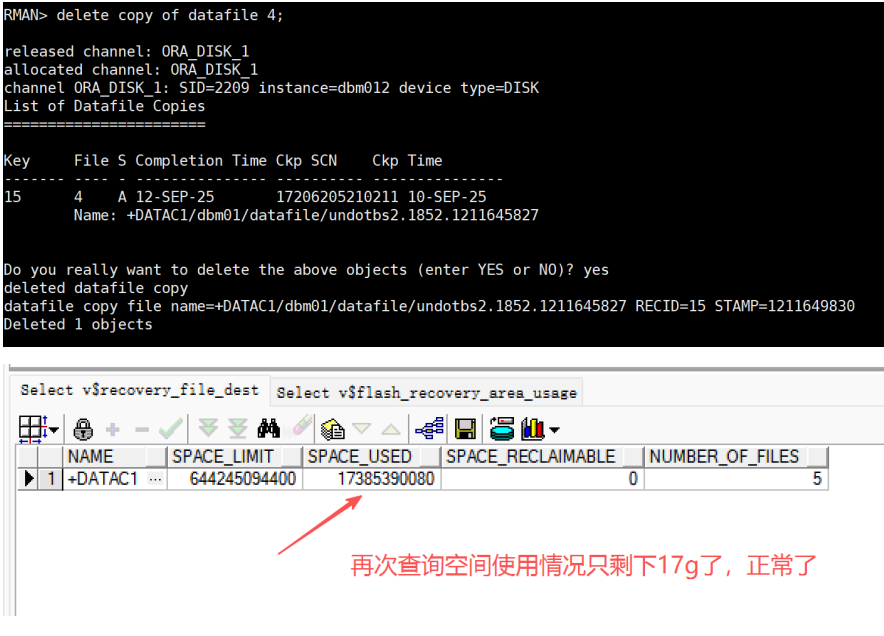
delete copy of datafile 4; #删除镜像拷贝
错误处理:
1)执行恢复报错,库链接失败
RMAN-03009: failure of allocate command on c1 channel at 03/05/2025 15:24:06
ORA-19554: error allocating device, device type: SBT_TAPE, device name:
ORA-27211: Failed to load Media Management Library
Additional information: 3983
原因:目标库的lib目录没有zdlra的库文件
处理:检查备份软件是否运行正常;检查备份目录是否访问正常;重新配置库链接
解决:chown -R oracle:oinstall libra.so
chmod 745 libra.so

2)wallet认证失败
RMAN-03009: failure of allocate command on c1 channel at 03/05/2025 15:49:40
ORA-19554: error allocating device, device type: SBT_TAPE, device name:
ORA-27023: skgfqsbi: media manager protocol error
ORA-19511: Error received from media manager layer, error text:
KBHS-01013: specified RA_WALLET alias ZDLRA2:1521/zdlra:dedicated not found in wallet
原因:这个连接字符串没有在wallet中配置,检查凭证
mkstore -wrl /u01/app/oracle/oracle/product/11.2.0/dbhome_1/dbs/zdlra -listCredential
1: zaingest-scan:1521/zdlra:dedicated ravpc
解决:添加此ip的连接字符串到wallet中。
3)catalog找不到目标库信息
RMAN-06004: ORACLE error from recovery catalog database: RMAN-20001: target database not found in recovery catalog
原因:这时候连接的恢复库还没有在catalog注册
解决:设置dbid=生产库的dbid
SET DBID=1123023669;
4)打开数据库报错ora-00392
SQL> alter database open resetlogs;
alter database open resetlogs
*
ERROR at line 1:
ORA-00392: log 1 of thread 1 is being cleared, operation not allowed
ORA-00312: online log 1 thread 1:
'+DATAC1/dbm01/onlinelog/group_1.1697.1211904929'
ORA-00312: online log 1 thread 1: '+DATAC1'select group#,sequence#,bytes,members,status from v$log;
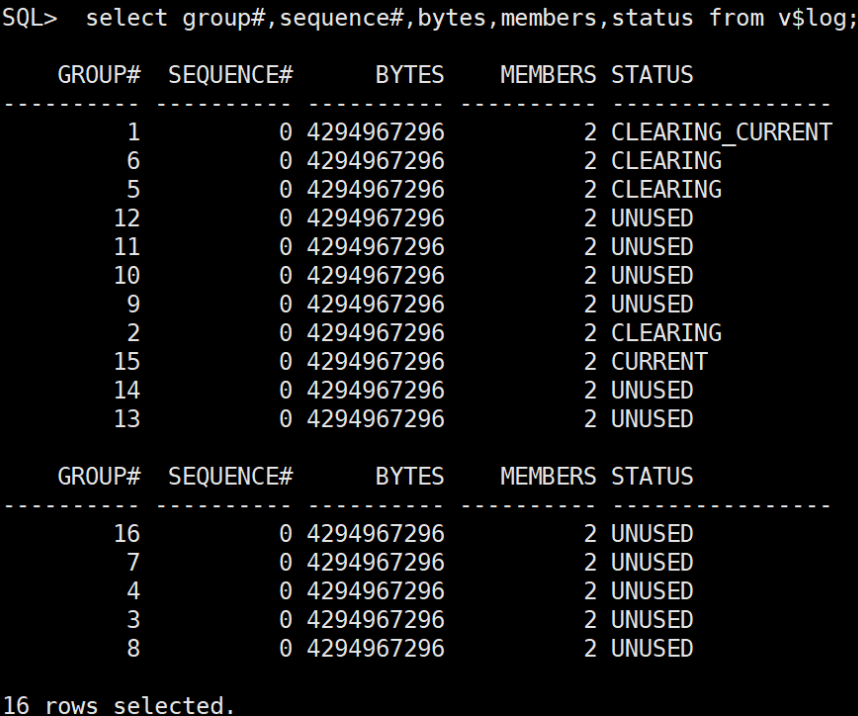
解决方法:ALTER DATABASE CLEAR LOGFILE GROUP 1;
5)清理日志组报错
ALTER DATABASE CLEAR LOGFILE GROUP 1;
ORA-19804: cannot reclaim 4296015872 bytes disk space from 10737418240 limit
原因:闪回区小了,查询发现已经使用了500G,之前修改的50、100g等都不行。
解决:修改闪回区大小
col SPACE_LIMIT form 99999999999999
col SPACE_USED form 99999999999999
select * from v$recovery_file_dest;
alter system set db_recovery_file_dest_size=600G scope=both;