




本文对PingCAP与华东师范大学联合发表的VLDB 2025论文《Towards Automated Cross-domain Exploratory Data Analysis through Large Language Models》进行解读。该论文介绍了一个名为TiInsight的自动化、跨领域的探索性数据分析(EDA)系统,旨在通过大语言模型(LLMs)解决真实世界数据分析中的核心挑战。全文共4934字,阅读需要15-20分钟。
一、引言:利用大语言模型自动化数据探索
探索性数据分析(EDA)是数据驱动决策的基石,但长期以来严重依赖能熟练编写高效SQL查询的人类专家,这限制了数据分析的效率和普及。其核心挑战在于用户不仅需要高水平的SQL技能,还需要为查询结果选择合适的可视化类型。
为应对这些挑战,论文提出了TiInsight——一个旨在自动化整个EDA工作流程的端到端系统,能将用户的自然语言问题无缝转化为富有洞察力的可视化结果。TiInsight 的设计理念标志着一种范式转变:系统不再是被动的辅助工具,而是一个能自主理解数据库结构和用户意图的智能代理,将数据分析师的角色从“SQL程序员”转变为与AI协作的“战略提问者”。
二、真实世界探索性数据分析的核心挑战
TiInsight旨在解决现有方法在真实EDA任务中面临的四大核心挑战,这些挑战相互关联,共同导致自动化分析流程的失败。
1. 复杂的数据库模式
真实世界的数据库模式包含数百个表和数千个字段,命名充满行业术语且缺乏清晰文档,这远超现有Text-to-SQL模型的上下文窗口限制,并增加了模式链接的难度。
2. 模糊的用户意图
用户问题往往是开放式的,缺少关键上下文(如时间范围、衡量指标)。通用LLM因缺乏特定领域知识,难以准确推断用户真实意图,导致查询偏离目标。
3. 有限的跨领域泛化能力
许多现有方法依赖于在特定领域数据集上的微调,缺乏泛化能力。为每个新业务领域重新训练模型在成本和时间上不现实,因此开发无需微调的零样本跨领域能力至关重要。
4. 割裂的文本到可视化流程
当前的数据可视化方法通常与SQL生成过程脱节,破坏了EDA流程的连贯性。理想的系统应提供从自然语言问题到可视化图表的无缝端到端体验。
这些挑战共同构成了一个恶性循环:复杂的模式加剧了对模糊意图的困惑,而泛化能力的缺失又导致错误的SQL生成,最终使下游的可视化毫无意义。TiInsight的架构设计正是为了打破这一循环。
三、TiInsight系统:架构概览
TiInsight 设计为一个包含四个核心阶段的逻辑流水线,以“分层数据上下文(Hierarchical Data Context, HDC)”为中心,HDC作为共享知识库为所有处理阶段提供语义基础。
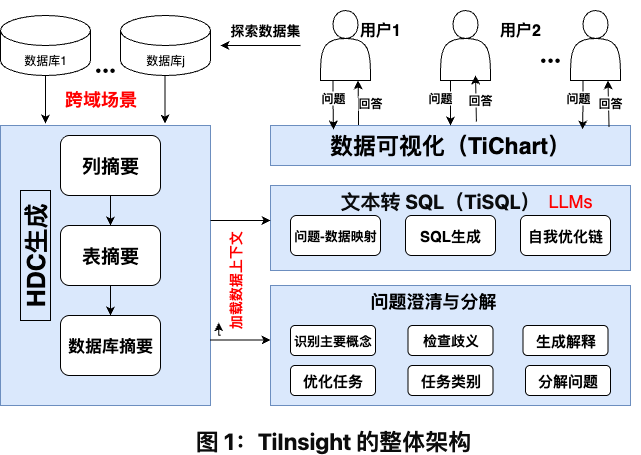
TiInsight的四个核心组件按顺序协同工作:
1. HDC生成(HDC Generation):分析原始数据库,利用LLM构建一个多层次的语义上下文,作为后续智能决策的基石。
2. 问题澄清与分解(Question Clarification and Decomposition):接收用户输入,利用HDC解决意图模糊问题,并将复杂任务分解为可处理的子问题。
3. 文本到SQL生成(TiSQL):系统的核心翻译引擎,将清晰的任务生成为准确、可执行的SQL代码。
4. 数据可视化(TiChart):系统的最终输出层,自动为SQL查询结果选择最合适的图表进行展示。
这种分阶段的设计确保了系统处理流程的清晰和高效,HDC的中心化设计则极大地提升了系统整体的智能水平和决策一致性。
四、分层数据上下文(HDC):系统的语义基础
分层数据上下文(HDC)是TiInsight最具创新性的核心技术。它通过构建一个多层次的语义抽象层,将对机器不友好的物理模式转化为LLM擅长理解的自然语言描述,从而实现无需微调的跨领域泛化能力。
1.列摘要(Column Summary)
为应对列名缩写和海量列数的挑战,HDC通过并行化、分组的方式生成列摘要。它利用检索增强生成(RAG)机制整合领域知识以消除歧义,并通过并行处理提升摘要生成速度。
2.表摘要(Table Summary)
在列摘要的基础上,HDC进一步生成表级别的摘要,包括表描述和表关系。
· 表描述生成:对于包含数千列的宽表,TiInsight设计了一个Map-Reduce框架来生成描述。Map阶段将宽表的列垂直切分成多个块,并行生成块级摘要;Reduce阶段则以迭代方式将这些摘要合并,最终浓缩成一个全面的表描述。
· 表关系识别:为避免对数千个表进行全量两两比较,HDC采用高效的两阶段方法。首先通过相似性搜索进行粗粒度召回,快速筛选出一小组最相关的候选表;然后仅让LLM对这小组候选表进行细粒度探索,从而精确识别外键关系,显著降低了计算复杂度。
3.数据库摘要(Database Summary)
为获得数据库的宏观理解,HDC在表摘要的基础上提取核心实体并生成数据库级摘要。它基于“影响力最大化”原则,通过表的关联关系数量识别出核心表,并让LLM基于这些表推断出核心业务实体(如“用户”、“订单”),最终生成一份高度概括的数据库摘要。
五、智能查询处理:从模糊到清晰
在生成SQL前,TiInsight利用HDC提供的上下文,将用户模糊的自然语言问题转化为清晰、可执行的分析任务。
1.问题澄清(Question Clarification)
为解决用户输入的歧义,TiInsight采用基于思维链(Chain-of-Thought,CoT)的系统性澄清流程。该流程引导LLM执行一系列逻辑步骤:识别核心概念、利用HDC检查模糊性、生成解释并提出澄清性问题,最后根据反馈优化原始任务。

图2: 问题澄清的提示片段
2.问题分解(Question Decomposition)

对于复杂的分析任务,TiInsight能够将其智能分解为多个逻辑独立的子任务。系统采用基于少量样本(Few-shot)的方法,从案例库中检索相似的成功分解案例作为示例,引导LLM生成更合理、更具逻辑性的分解计划。
图3:问题分解的提示片段
六、TiSQL:一个鲁棒的文本到SQL生成框架
TiSQL是TiInsight的核心引擎,负责将清晰的任务准确翻译成SQL查询。它通过一个多阶段流程确保SQL的准确性,其创新的自优化链机制尤为关键。
1.基于Map-Reduce的模式筛选
在生成SQL前,TiSQL采用基于Map-Reduce的两阶段框架高效筛选相关表和列。首先,通过向量数据库进行粗粒度召回,检索出最相关的N个候选表;随后,在细粒度筛选阶段,LLM分析每一组候选表的HDC摘要,精确判断任务必需的表和列,从而得到精简的模式信息。

图4:模式筛选的提示片段
2.SQL生成与自优化链
获得精简模式后,TiSQL利用CoT提示引导LLM生成SQL。为解决LLM生成中可能出现的错误,TiSQL引入了创新的自优化链(Self-Refinement Chain)机制。
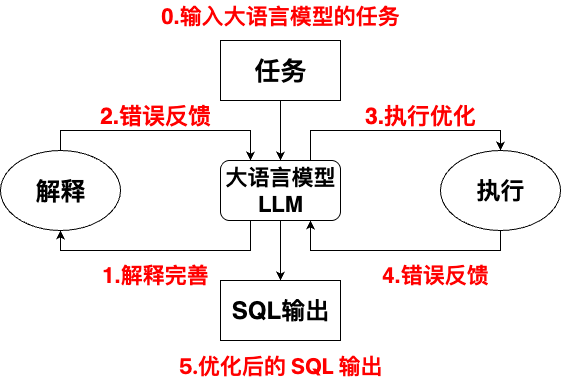
图5:TiSQL的自优化链
七、TiChart:基于规则的自动化可视化
TiChart采用务实、可靠的基于规则的自动化可视化方法,将SQL查询结果转化为直观的视觉洞见。
其工作流程包括三个步骤:
1. 数据类型识别:分析查询结果中每一列的数据类型(如类别型、数值型、时间序列型)。
2. 规则匹配与图表选择:应用一套预定义的启发式规则选择最合适的图表类型。例如,一个类别型字段和一个数值型字段适合使用条形图;一个时间序列字段和一个数值型字段适合使用折线图。
3. LLM验证与兜底策略:选定的图表类型会提交给LLM进行最终验证。如果没有任何图表能清晰展示数据,TiChart会选择以表格形式展示,确保信息的完整性。
八、实验评估:验证TiInsight的性能
论文进行了一系列实验评估,验证了TiInsight在准确率、可用性、性能和成本等方面的表现。
1.TiSQL的基准准确率
在权威的Text-to-SQL基准测试中,TiSQL表现出色。
· Spider数据集:TiSQL与GPT-4的组合取得了86.3%的执行准确率,达到业界顶尖水平。
· Bird数据集:该数据集更贴近真实世界的复杂查询,TiSQL+GPT-4取得了60.98%的执行准确率,全面超越了同类方法。
数据集 | 方法 | 执行准确率 (EX, %) |
Spider | TiSQL + GPT-4 (本文) | 86.3 |
DAIL-SQL + GPT-4 | 86.6 | |
DIN-SQL + GPT-4 | 85.3 | |
RESDSQL-3B + NatSQL | 79.9 | |
Bird | TiSQL + GPT-4 (本文) | 60.98 |
SFT CodeS-15B | 60.37 | |
DAIL-SQL + GPT-4 | 57.41 | |
DIN-SQL + GPT-4 | 55.90 |
表1:TiSQL在Spider和Bird测试集上的执行准确率
2.系统的可用性与用户研究
在一项涉及20名数据分析师的用户研究中,参与者使用TiInsight、人类专家、Chat2Query和通用ChatGPT完成分析任务。结果显示,在相关性、完整性和可理解性三个维度上,TiInsight的得分均与人类专家相当,并显著优于其他AI工具。用户普遍认为TiInsight能有效帮助他们理解数据集,并对自动生成的SQL和可视化图表给予高度评价。
评估维度 | 人类专家 | TiSQL (本文方法) | Chat2Query | ChatGPT |
相关性 | 4.7 ± 0.2 | 4.5 ± 0.3 | 4.0 ± 0.4 | 2.8 ± 0.5 |
完整性 | 4.7 ± 0.2 | 4.5 ± 0.3 | 3.8 ± 0.4 | 2.6 ± 0.5 |
可理解性 | 4.9 ± 0.1 | 4.6 ± 0.2 | 4.0 ± 0.3 | 2.5 ± 0.6 |
表2:用户研究中不同方法的平均得分(5分制)
3.系统性能与经济可行性
· 延迟分析:HDC的生成是一次性预处理。单次Text-to-SQL的生成和执行延迟极低,使用GPT-4时通常在5秒以内,满足交互式分析的需求。
· 成本分析:实验揭示了性能与成本的权衡。GPT-4性能最佳但成本最高,而GPT-4o和GPT-4o mini等模型在成本上具有巨大优势,为企业根据场景选择模型提供了参考。
LLM 型号 | Spider测试集成本(美元) | Bird开发集成本(美元) |
GPT-4 | 238.0 | 192.5 |
Claude-3 Opus | 89.5 | 72.3 |
GPT-4o | 12.8 | 10.5 |
GPT-4o mini | 1.4 | 1.0 |
表3:不同LLM的API调用成本对比
4.生产环境表现
TiInsight已在金融和零售行业的商业客户生产环境中部署。在使用GPT-4时,系统SQL执行准确率超过85%,查询生成时间在5秒内,证明其架构能够成功应对真实、复杂的商业挑战。
九、结论与启示
TiInsight系统通过其创新的HDC框架和鲁棒的端到端架构,为自动化探索性数据分析领域树立了新的标杆。
核心贡献总结:
· 提出HDC框架:解决了LLM在复杂、跨领域数据库上进行Text-to-SQL任务的核心技术难题,实现了无需微调的强大泛化能力。
· 设计端到端的TiInsight系统:整合了从问题理解到最终可视化的完整流程,其自优化链机制为生成高质量SQL提供了可靠保障。
· 全面的实证评估:充分证明了TiInsight在准确性、可用性、性能和商业可行性方面的卓越表现。
这项工作所展示的设计模式,特别是HDC作为语义抽象层和自优化链作为一种上下文内强化学习的方法,为构建更广泛的AI代理系统提供了宝贵经验。TiInsight描绘了一个人与AI协同进行数据探索的未来,在这个未来中,数据分析的门槛被极大降低,人类专家的角色将转变为更高层次的战略思考者,从而将数据分析的创造力和影响力提升到新的高度。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





