




在日常的数据分析场景中,我们经常会向 Apache Doris 写入大量数据,无论是实时导入、批量导入,还是通过流式写入。但你是否想过:一条数据从客户端发出,到最终稳定落盘,中间到底经历了哪些步骤?
今天我们就来全面拆解 Doris 写入原理,带你走进它的内部世界。
1. 整体脉络
一条写入数据在 Doris 的“旅程”可以分成若干层次:
入口:客户端通过 HTTP(Stream Load)、JDBC/SQL(INSERT)、Broker/Spark(批量)、Routine Load(Kafka)等方式把数据送入系统。各种 Load 方法的分类和用途说明链接。
FE 层(协调):SQL 解析、计划、事务分配、路由与元数据管理(表/分区/Tablet 信息由 FE 管理并存储)。
BE 层(执行):负责真实的数据写入、内存结构、落盘(Segment)、索引构建、Compaction、查询执行。
2. 写入模式
选择合适的写入模式是发挥 Doris 性能的前提。不同模式的事务粒度、资源占用、延迟表现差异显著,需根据业务需求精准选型。
| Stream Load | |||||
| Routine Load | |||||
| Broker Load | |||||
| Spark Load | |||||
| Insert Into |
3. 写入流程关键内容解析
3.1 数据接收与请求解析
流程细分:
客户端通过 HTTP MySQL 协议向 FE 或 BE 发起写入请求。 如果请求到 FE:FE 做 SQL 解析(SQL parser)、语义校验(列类型、分区存在性等)、权限校验。 FE 根据目标表的分区/分桶/Distribution 信息,执行 路由决策:确定目标 Tablet(或者多个 Tablet)。 FE 为该写入分配一个 事务 ID(Txn ID) 或者在批量场景下分配批次标识,用来跟踪后续的各个 BE 写入结果与可见性。
3.2 BE 的内存写入 — MemTable
核心流程:
BE 在接收到写入行后,会采用了类 LSM 树的结构,将数据先写到 Memtable 中,当 Memtable 数据写满后,才会进行下一步数据写入。 MemTable 在逻辑上做去重/聚合/排序(取决于表类型:Duplicate/Unique/Aggregate)。如主键表会在内存阶段做主键合并或覆盖逻辑。
内部细节:
数据格式化:将网络序列化数据解析为内部列式/行式表示(列式更利于压缩与向量化)。 短键索引构建(Short key MinMax):MemTable 会收集用于快速定位的小索引信息(比如每个块的最小/最大值、短键)。 锁与并发控制:写入到同一个 Tablet 的并发写请求需要合适的并发控制(同 Tablet 同步或分区内并发写控制),以保证事务语义。
3.3 Flush 到磁盘 — 生成 Segment 文件
Flush 过程:
当Memtable数据写满后,会异步flush生成一个Segment进行持久化,同时生成一个新的Memtable继续接收新增数据导入
在写入磁盘前会做最终的编码、压缩、索引构建(如短键索引、列级统计信息、ZoneMap/MinMax),并生成元数据描述该 Segment(如行数、列偏移、压缩方式)。
3.4 事务管理与元数据发布
事务与可见性:
FE 为写入分配 Txn ID Version,用来保证原子性和版本管理。 BE 在本地成功写入 Segment 后,会向 FE 汇报“写入完成并持久化”的消息(包含生成的 Segment 元信息)。 FE 收到足够的确认(通常基于多数副本策略)后,会发 Publish 任务使导入的 Rowset 版本生效。任务中指定了发布的生效 version 版本信息。之后 BE 存储层才会将这个版本的 Rowset 设置为可见。最后Rowset 加入到 BE 存储层的 Tablet 进行管理。
元数据更新:
FE 在提交时更新元数据(Tablet 的版本、Segment 列表、事务日志),并把新的元信息持久化到元存储。
3.5 后台优化:Compaction(合并)
为什么需要 Compaction:
写入产生许多小的 rowset(小文件),长期积累会: 增加查询时需要扫描的文件数(查询随机 IO 增多)。 增大元数据开销。
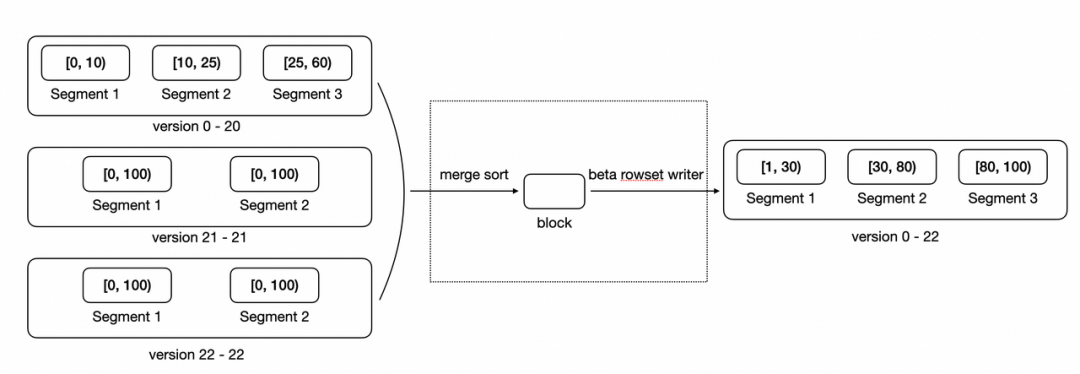
常见 Compaction 策略:
Cumulative Compaction:优先合并新写入的小 Rowset,避免直接与大 Rowset 合并导致效率低下。新导入的零散数据(如实时写入的小批次数据 ),先通过Cumulative Compaction逐步 “攒大”,减少后续 Base Compaction 的压力。。 Base Compaction:当Cumulative Rowset 合并到一定规模后,再与 历史大 Rowset(Base Rowset)合并,最终形成更紧凑的大 Rowset。
4. 总结
一条数据写入到 Doris 的旅程包含多个环节,理解数据写入的每个环节(MemTable、Flush、Compaction、FE 事务等),能够更好的帮助我们优化写入性能与稳定性。
往期推荐
完
Apache Doris社区是目前国内最活跃的开源社区(之一)。Apache Doris(Apache 顶级项目) 聚集了世界全国各地的用户与开发人员,致力于打造一个内容完整、持续成长的互联网开发者学习生态圈!
如果您对Apache Doris感兴趣,可以通过以下入口访问官方网站、社区论坛、GitHub和dev邮件组:
PowerData是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的数据开源社区。
社区群内会定期组织模拟面试、线上分享、行业研讨、线下Meetup、城市聚会、求职内推等活动,同时在社区群内你可以进行技术讨论、问题请教,结识更多志同道合的数据朋友。
社区整理了一份每日一题汇总及社区分享PPT,内容涵盖大数据组件、编程语言、数据结构与算法、企业真实面试题等各个领域,帮助您提升自我,成功上岸。
可以加作者微信(Faith_xzc)直接进PowrData官方社区群
叮咚✨ “数据极客圈” 向你敞开大门,走对圈子跟对人,行业大咖 “唠” 数据,实用锦囊天天有,就缺你咯!快快关注数据极客圈,共同成长!

点击上方公众号关注我们
