




写这篇的缘起是,我要在腾讯云上一台配置为2c4g的云服务器上下载一个比较大的文件,走内网下载。
开始的时候,我使用的工具是wget,wget显示的网速是25MB/s左右。

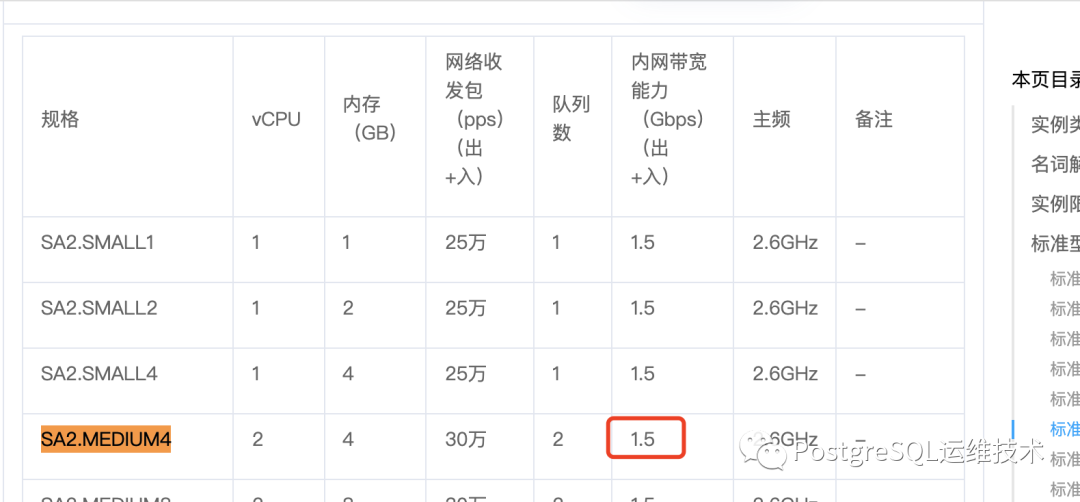
但是2c4g的机器官方标示的内网带宽是1.5Gbps,按说我的内网网速理应可以达到1.5*1024/8=192MB/s的。
扩展:
1.Gbps和MB/s的关系。
Gbps是gigabit per second的缩写,即千兆比特每秒。是一种传输速率的单位,指每秒传输的位(比特数量),也叫带宽。除此之外,还有Mbps(兆比特每秒)和Kbps(kbps)。
三者之间的换算公式是:1Gbps=1024Mbps, 1Mbps=1024Kbps。
2.Mb/s和MB/s也是表示传输速率的单位。它们和Mbps有什么区别呢?
首先是Mbps,其全称是megabits per second, 表示兆比特每秒。这里的bit是表示数字信号数据的最小单位。Mb/s的含义与其相同,均表示兆比特每秒,指每秒传输的位数量。而对于MB/s,其中的B,是Byte,字节。MB/s的含义是兆字节每秒,指每秒传输的字节数量。我们知道1Byte=8bit。综上,就有了1MB/s=8Mbps=8Mb/s。
内网下载的速率远没有达到预期,我就猜想是不是wget工具的问题,在网上搜索了一番,就找到一个替代工具axel。
axel
github地址:https://github.com/axel-download-accelerator/axel/releases
axel是一个多线程下载工具,支持http、https、ftp和ftps协议。
centos安装
采用源码安装, 在网站下载release包, axel-2.4.tar.bz2。
yum install bzip2 gcc-c++ openssl-devel intltool -y
bzip2 -d axel-2.4.tar.bz2
tar -xvf axel-2.4.tar.gz
cd axel-2.4
./configure && make && make install
axel的用法
axel -a -n [Num_of_Thread] url -o [output_file]
其中-n [Num_of_Thread],表示并发线程数。
测试情况
通过不断调整num_of_thread的数量,下载速度得到了明显的提升,达到了174MB/s(n=12), 接近于官网的内网宽带大小。
🐂🐂🐂

python多线程下载大文件
上面我们也看到axel用了多线程,下载速度得到了大幅提升。如果我们用python实现一个多线程下载器应该怎么做?
我们使用python下载文件,一般使用单线程下载。为防止文件过大,直接载入内存从而导致内存不足,一般采用requests的stream模式。比如如下的代码:
import requests
from tqdm import tqdm
def download_file(url, file_path, chunk_size):
with requests.get(url, stream=True) as r:
r.raise_for_status()
file_size = r.headers['Content-length']
# pbar = tqdm(total=int(file_size), unit='B', unit_scale=True, desc=file_path)
with tqdm(total=int(file_size), unit='B', unit_scale=True, desc=file_path) as pbar:
with open(file_path, 'wb') as f:
for chunk in r.iter_content(chunk_size=chunk_size):
f.write(chunk)
pbar.update(chunk_size)
写一个多线程的版本,其实就是根据总大小,对数据进行分片下载,每个下载交由一个线程异步下载。指定range请求。Range 请求头的语法:Range: bytes=start-end。注:为防止出现数据损坏或不一致的问题,请对文件进行有效性验证。代码仅做测试用。
class MultiThreadDownload:
def __init__(self, url, total, file_name, num=10):
self.num = num # 线程数,默认10
self.url = url # url
self.total = total # 文件大小
self.file_name = file_name # 文件名
def calc_divisional_range(self):
step = self.total // self.num
arr = list(range(0, self.total, step))
result = []
for i in range(len(arr) - 1):
s_pos, e_pos = arr[i], arr[i + 1] - 1
result.append([s_pos, e_pos])
result[-1][-1] = self.total - 1
return result
# 下载方法
def range_download(self, s_pos, e_pos):
headers = {"Range": f"bytes={s_pos}-{e_pos}"}
res = requests.get(self.url, headers=headers, stream=True)
with open(self.file_name, "rb+") as f:
f.seek(s_pos)
for chunk in res.iter_content(chunk_size=64 * 1024):
if chunk:
f.write(chunk)
def download(self):
divisional_ranges = self.calc_divisional_range()
# 先创建空文件
with open(self.file_name, "wb") as f:
pass
with ThreadPoolExecutor() as p:
futures = []
for s_pos, e_pos in divisional_ranges:
futures.append(p.submit(self.range_download, s_pos, e_pos))
# 等待所有任务执行完毕
as_completed(futures)
参考:
https://blog.csdn.net/qq_44291044/article/details/98798442
https://blog.csdn.net/as604049322/article/details/119847193
