




本文对华为和清华大学联合发表的VLDB 2025论文《GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications》进行深度解读。该论文介绍了一个名为GaussDB-Vector的高性能、持久化、实时的向量数据库系统,旨在解决大语言模型(LLM)应用中的核心挑战,并为企业级AI应用提供坚实的“长时记忆”基础。全文共6001字,阅读需要25-30分钟。
一、引言:为LLM应用打造高性能、可持久化的“长时记忆”
大语言模型(LLM)是现代人工智能应用的基石,但其在实际应用中面临两大核心挑战:一是幻觉(从Hallucination)——即模型生成看似合理但与事实不符的内容;二是高昂的推理成本(Inference Cost)。为应对这些挑战,业界普遍采用向量数据库作为LLM的“长时记忆”系统。例如,通过检索增强生成(Retrieval-Augmented Generation, RAG)技术,可以从一个填充了可靠知识嵌入的向量数据库中检索相关信息,从而使LLM的回答更具可控性和可解释性,有效减少幻觉。同时,语义记忆(Semantic Memory)技术可将推理过程的各个阶段以嵌入形式缓存于向量数据库中,供未来查询复用,从而显著降低推理成本。
然而,要支撑这些企业级的LLM应用,向量数据库必须满足一系列严苛的要求:高效存储和检索数十亿级别的嵌入向量、支持高频的实时数据更新、应对高并发用户访问、具备高可用性和用户隔离能力,并能执行向量相似度与传统标量过滤相结合的混合搜索(Hybrid Search)。
现有的商业向量数据库系统在满足这些综合性需求方面存在明显瓶颈:
· Milvus与ElasticSearch:这类系统通常基于类似日志结构合并树(LSM-Tree)的架构。数据被组织在段(Segment)中,导致其固有缺陷:查询延迟较高,因需搜索所有相关段并合并结果;更新成本高昂,因段的合并与分裂会触发索引重建;数据新鲜度低,新插入的数据无法立即被索引和检索。
· PGVector:作为PostgreSQL的扩展,PGVector虽然继承了关系型数据库的成熟功能,但其核心的HNSW(Hierarchical Navigable Small World)图索引在基于磁盘的系统上会产生大量I/O开销,性能不及DiskANN等专为磁盘设计的算法。此外,其仅支持单机部署,无法扩展至处理数十亿级别的海量向量数据集。
这些现有方案的局限性揭示了市场的演进趋势。向量数据库的发展已从解决“如何搜索向量”的第一代问题(由Faiss等内存库解决)和“如何规模化服务向量”的第二代问题(由Milvus等系统解决),进入了第三代挑战:如何在一个系统中同时提供极致的向量检索性能、企业级的数据库可靠性(如ACID事务、实时数据可见性)、以及处理复杂查询的能力。
正是在这一背景下,GaussDB-Vector被提出。它旨在通过创新的架构设计,克服现有方案的不足,成为一个集高性能(High Performance)、高可用性(High Availability)、高可扩展性(High Scalability)、零延迟数据新鲜度(Zero-Delay Data Freshness)和高效混合搜索(Hybrid Search)于一体的持久化实时向量数据库,为LLM应用提供坚实可靠的基础设施。
二、 GaussDB-Vector系统概览:一个双层分布式架构
为实现其设计目标,GaussDB-Vector采用了一个经典的双层分布式数据库架构,该架构在传统数据库领域已被证明是实现负载均衡、并行处理和高可扩展性的成熟模型。
该架构主要由两类节点组成:
· 协调节点(Coordinate Nodes, CNs):负责接收客户端连接、解析SQL、进行查询优化并规划执行路径。
· 数据节点(Data Nodes, DNs):负责执行CN下发的计划,包括算子执行和数据操作,并内含存储管理和硬件加速模块。
此外,系统还包括一个集群管理器(Cluster Manager)用于协调集群执行,以及一个全局事务管理器(Global Transaction Manager)来追踪分布式事务。这种架构选择的背后,体现了一种更宏大的战略思考:向量数据不应被视为一个需要孤立系统解决的特殊问题,而应作为一种与文本、数字同等重要的一等公民数据类型,无缝融入主流的、企业级的操作型数据平台中。通过采用企业熟悉的SQL接口和CN-DN架构,GaussDB-Vector极大地降低了企业集成和使用的门槛,使其不仅仅是一个“向量数据库”,而是一个能够原生处理向量的“下一代操作型数据库”。
核心组件剖析:
· SQL接口:GaussDB-Vector的一个核心特性是扩展了标准的SQL接口。这不仅是为了方便用户,更是一项战略决策,它使得系统能够处理包含向量搜索的复杂查询(如连接、子查询),并利用成熟的、基于成本的优化器来生成高效的执行计划。例如,用户可以使用扩展的DDL(如 CREATE TABLE... (vec floatvector(128)))和DML(如 ORDER BY vec <cos> '')进行操作。
· 存储管理器:系统性能的基石是其基于页面的存储管理器。为了最大化I/O效率,它将距离相近的向量在物理上聚集存储,从而最小化随机磁盘读取。向量数据与其它关系型列一同以行存格式存储,实现了无缝集成。系统支持为向量和标量列构建索引,以加速查询。
· 硬件加速器:该架构设计旨在将计算密集型操作(如距离计算、聚类、量化)卸载到专用硬件上,如华为昇腾(Ascend)NPU和鲲鹏(Kunpeng)CPU。在鲲鹏CPU上,系统利用SIMD指令集执行并行浮点运算;在昇腾NPU上,则通过将向量批处理为矩阵,利用张量核心进行加速。
三、核心技术一:面向持久化存储优化的向量索引
向量索引是向量数据库的核心。GaussDB-Vector实现了两种主要的索引类型:IVF索引和专为磁盘I/O优化的Vamana图索引。
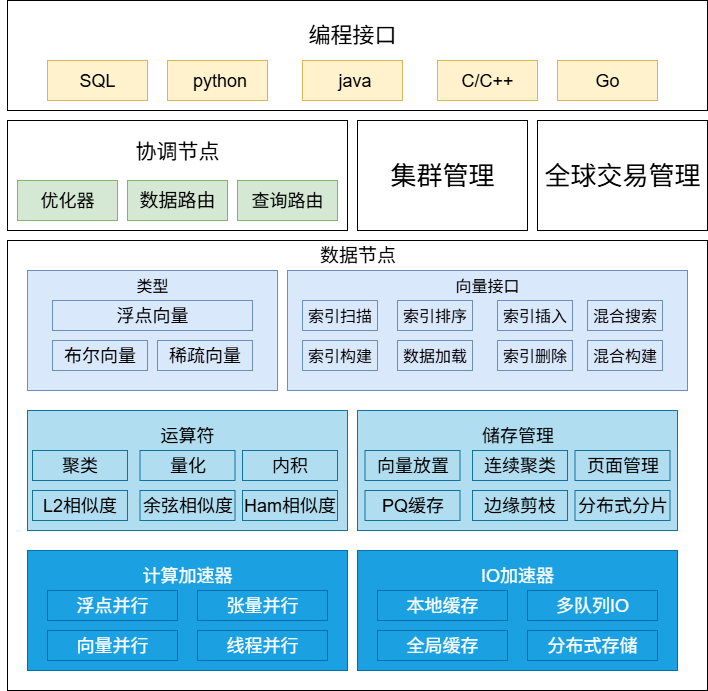
图1 :GaussDB-Vector的整体架构
3.1 IVF索引:平衡高效的基础选择
IVF(Inverted File)索引是一种基础而高效的向量索引方法,通过对向量空间进行聚类划分来缩小搜索范围。GaussDB-Vector的实现包含以下特点:
· 结构与原理:为了更好地平衡每个聚类中的数据负载,系统采用了一个结构。索引文件在逻辑上组织为一个三层树状结构,包括元数据页、一级聚类页和二级聚类页。
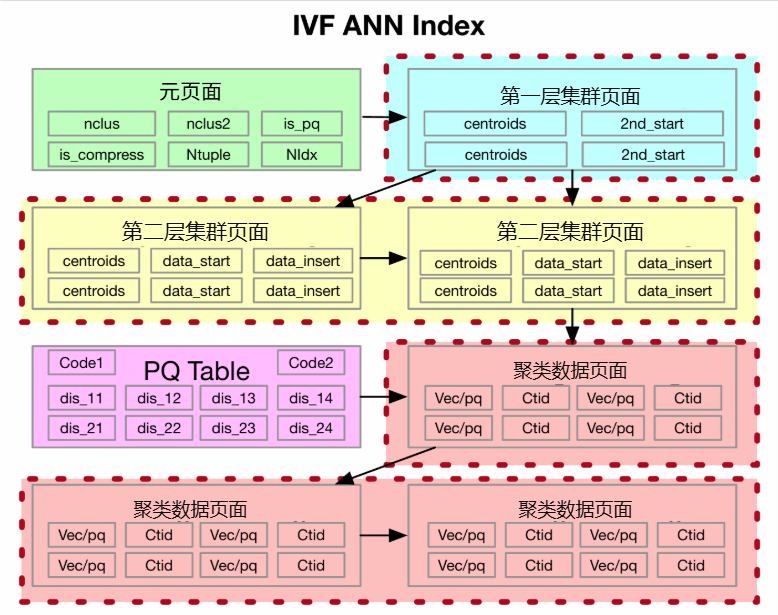
图2:IVF索引的结构
· 乘积量化(Product Quantization, PQ):为了压缩向量以减少存储空间并加速离计算,GaussDB-Vector采用了PQ技术。具体来说,它使用PQ-ADC(Asymmetric Distance Computation)方法,仅对索引中的数据向量进行量化,而查询向量保持不变,从而在保持较高精度的同时提升计算效率
· 操作流程:
o 索引构建:通过蓄水池抽样采集样本,进行k-means聚类构建聚类页,然后扫描全量数据,按聚类ID排序后顺序构建数据页,确保物理存储的连续性。
o Top-k搜索:首先在聚类中心中找到最近的N个一级聚类和M个二级聚类,然后扫描这些聚类中的候选向量,通过优化的二分排序方法高效找出Top-k结果。
o 实时更新:插入操作通过查找最近的聚类并将向量的ctid(物理位置标识)追加到对应的数据页来实现;删除操作则采用惰性删除(lazy deletion),仅标记删除位,由后台任务进行物理清理,保证了低延迟。
3.2 Vamana图索引:专为I/O效率设计的核心创新
Vamana图是一种先进的图索引算法,以高召回率著称。然而,其设计通常假设数据在内存中。GaussDB-Vector的核心创新在于将其成功地改造并优化,使其在I/O受限的磁盘环境中也能发挥出卓越性能。
这种创新的根源在于从数据库存储管理的第一性原理出发,深刻理解到磁盘性能的瓶颈在于随机I/O次数,而非CPU周期。一个朴素的磁盘图索引实现,在图遍历的每一步都可能触发多次随机I/O(一次读取当前节点,N次读取其邻居节点),这将导致性能灾难。GaussDB-Vector的设计正是为了攻克这一核心难题。
· 自适应页面存储结构:这是GaussDB-Vector最关键的创新之一。它设计了三种不同的磁盘页面布局,根据向量维度动态选择,以最小化I/O开销:
1. 低维向量(dim≤130):将一个节点的向量、PQ编码及其所有邻居节点的PQ编码共同存储在同一个数据页上。这种数据协同定位(co-location)策略,使得一次磁盘读取就能获取图遍历下一步所需的所有信息,极大地减少了随机I/O次数。
2. 中维向量(130<dim<1565):为避免邻居数据过多导致页面膨胀,将PQ编码移至一个独立的、可被高效缓存的区域。主节点页只存储邻居的ID,查询时再从缓存或磁盘中获取PQ编码。
3. 高维向量/压缩模式:对于超高维度或海量数据场景,将节点和边完全分离存储,以实现最高的存储密度。在此模式下,如果启用了PQ,甚至可以从索引中移除原始向量,进一步节约存储空间。
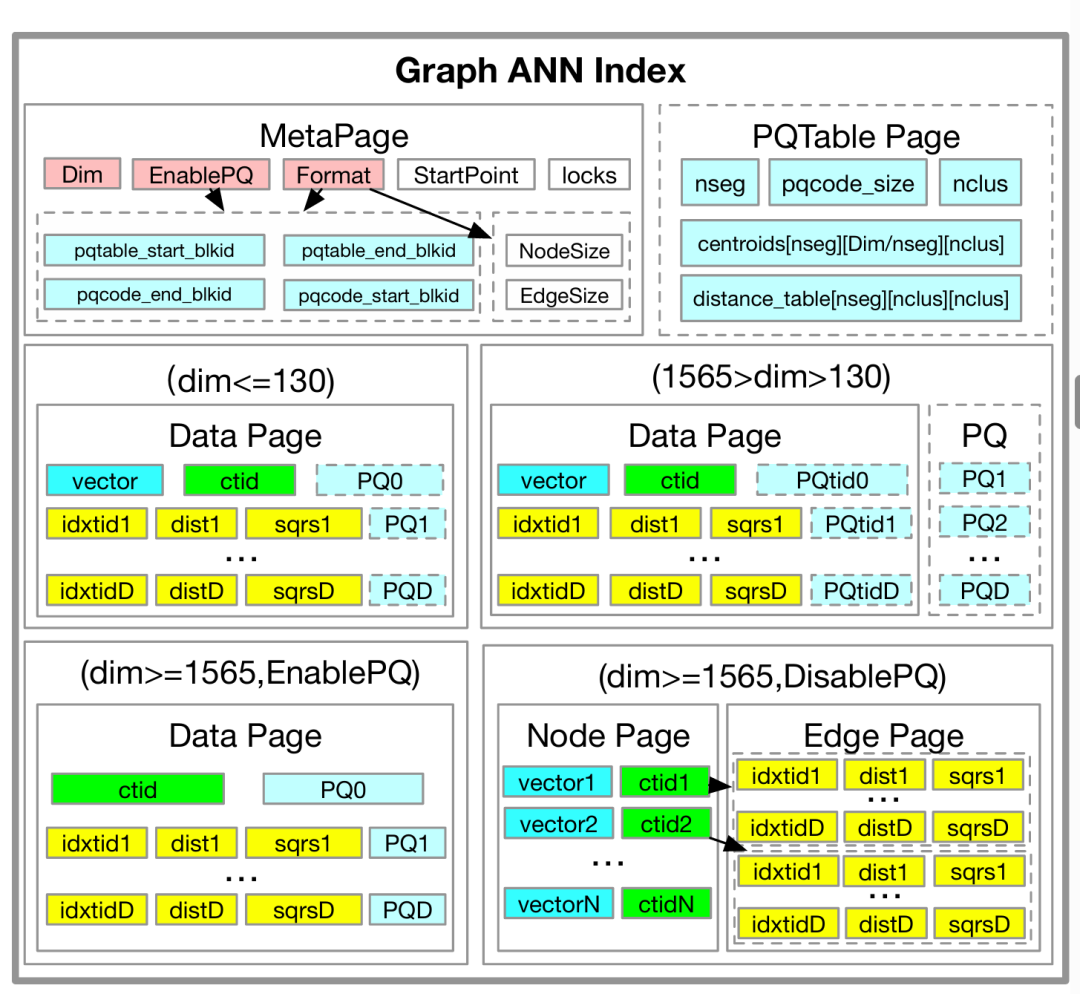
图3:基于图的索引结构
· 高效索引构建(Algorithm 1-3): GaussDB-Vector通过在重叠的子图上并行构建来解决这个问题,每个向量都属于两个最近的子图,从而在分治构建的同时保证了全局连通性。此外,论文提出了一种创新的邻居剪枝启发式算法,将插入操作中邻居选择的计算复杂度从DiskANN的O(m3)降低到O(m2),显著提升了索引构建和数据插入的速度。
· 搜索与实时更新(Algorithm 4):图搜索采用贪心算法,并结合了系统级优化,如热点节点缓冲和多线程I/O来并行获取邻居节点数据。实时更新机制同样高效:插入操作通过一次图搜索和优化的邻居剪枝完成;删除操作采用惰性标记,并通过一个专门的ctid到tid(索引内ID)的倒排列表来快速定位节点,避免了全表扫描。
· 鲁棒的空间回收(Vacuum, Algorithm 5):为了保证长期运行下的性能稳定,GaussDB-Vector设计了强大的空间回收机制。该机制不仅是简单的垃圾回收,更重要的是,它会将被删除节点的邻居节点重新插入图中,以“修复”图结构,防止因大量更新导致图的连通性下降和查询质量退化。整个过程通过锁机制来保证并发安全。
四、核心技术二:高效稳定的标量-向量混合查询
混合查询是向量数据库在真实业务场景中的刚需。传统的“后过滤”(post-filtering)方法——即先执行向量搜索再用标量条件过滤结果——在标量过滤选择性高时效率极低。GaussDB-Vector为此设计了一种创新的混合索引结构。
· 混合索引结构:该结构的核心是一个构建在标量属性上的平衡树(B-Tree)。其精妙之处在于,每个非叶子节点(根节点或中间节点)都内嵌了一个自己的向量子索引(可以是IVF或图索引),该子索引是基于其下所有子节点包含的向量数据构建的。
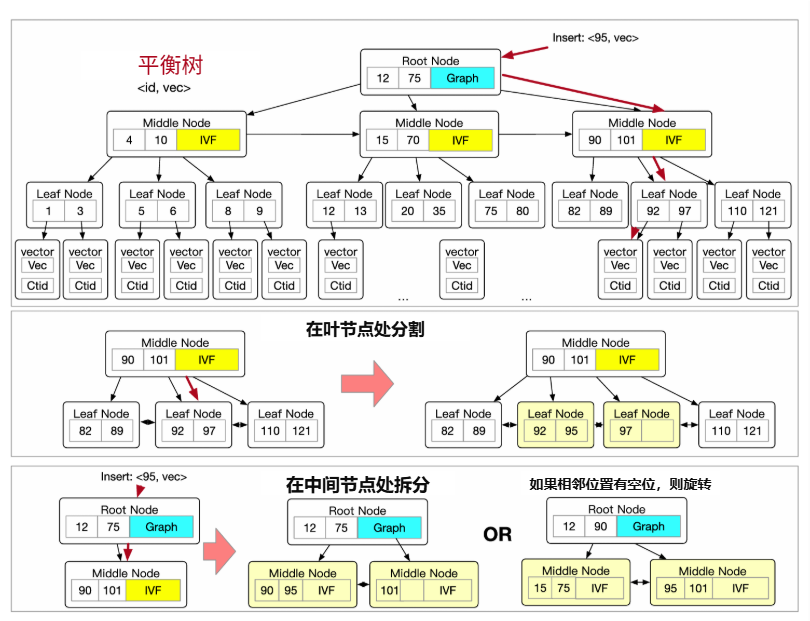
图4:标量-向量混合索引
· 自适应查询策略:这种设计使得查询计划可以根据标量条件的选择性(selectivity)进行自适应调整:
o 当标量条件选择性低时(例如,price>100,匹配大量数据):查询可以直接利用B树高层节点的向量子索引进行搜索。这个子索引覆盖了满足条件数据的最小超集,避免了对全量数据的扫描,效率极高。
o 当标量条件选择性高时(例如,id=12345,只匹配少量数据):查询会沿着B树一直遍历到叶子节点,直接获取少量候选向量,然后进行一次快速的内存排序。这完全绕过了大规模向量索引的搜索开销。
· 更新与权衡:该结构在查询性能上表现优异,但在数据更新时更为复杂,因为插入或删除可能触发B树的节点分裂或旋转,进而需要重建内嵌的向量子索引。为平衡读写性能,GaussDB-Vector采取了务实的策略:仅在数据量较大的高层节点使用构建成本较高的图索引,而在中低层节点使用更新更轻量的IVF索引。
五、核心技术三:支持万亿规模的分布式扩展能力
为了支持超越单机容量的万亿级向量数据,GaussDB-Vector设计了一套完善的分布式扩展机制。
· 数据分片策略:系统采用基于距离的数据分片策略。所有向量被聚类成多个簇,每个簇的数据被分配到一个数据节点(DN)上。该策略的生命周期包括:
1. 随机阶段:初始数据随机分布。
2. 完全重分布阶段:当数据量达到阈值时,进行一次全局聚类和数据迁移。
3. 聚类阶段:稳定运行阶段,新数据被路由到距离最近的簇。
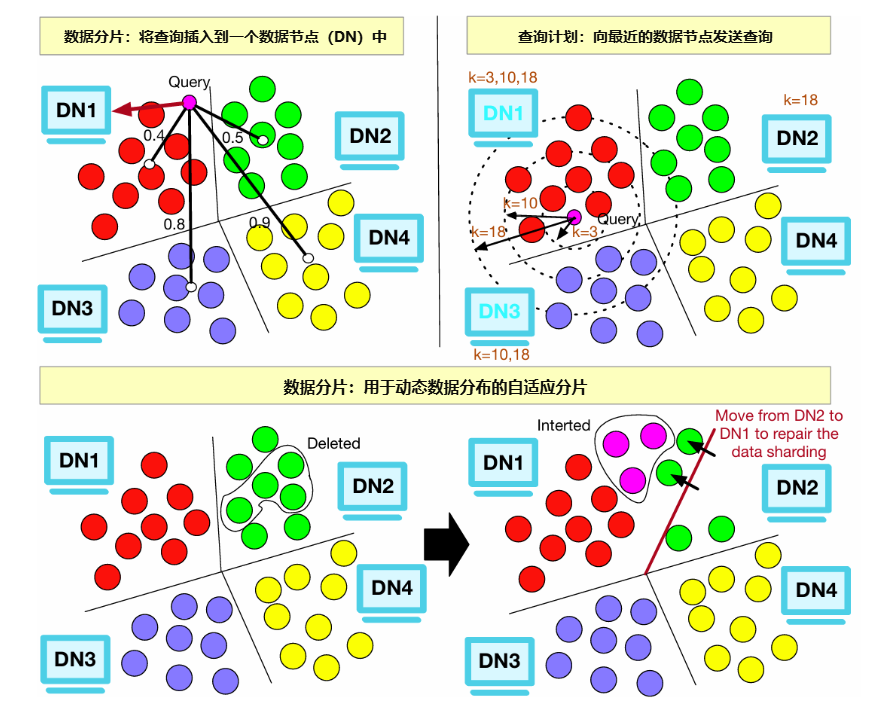
图5:分布式数据分片与查询调度
· 自适应重分布:为了应对数据分布随时间变化可能导致的负载不均,系统包含一个周期性的、增量的重分布机制。它能自动检测数据分布的“漂移”,并在后台更新簇中心并迁移数据,以维持长期的负载均衡。
· 智能查询路由:当一个查询到达协调节点(CN)时,系统不会将其盲目广播到所有DN。相反,它利用一个基数估算(Cardinality Estimation)模型来预测哪些DN(簇)最有可能包含查询结果。对于Top-k查询,它通过对距离阈值进行二分查找,来确定需要查询的最小DN集合。此外,为了保证高召回率,该策略还会主动查询那些位于分片边界附近的簇,以覆盖可能跨越多个分片的近邻结果。
六、硬件加速:充分利用现代计算资源
为了极致的性能,GaussDB-Vector充分利用现代硬件的计算能力。其核心思想是将向量距离计算(如欧氏距离或内积)转换为高度并行化的矩阵运算,例如利用公式 D(x,y)=x2−2⋅(x×yT)+y2 。这种加速主要应用于两个计算密集型场景:
1.索引构建过程中的批量距离计算,如IVF的k-means聚类和图索引的构建;
2.查询过程中扫描IVF分区时的批量距离计算。同时,系统也会利用CPU级的SIMD指令集进行小规模并行计算,充分挖掘硬件性能。
七、实验评估:全方位性能验证
论文通过一系列详尽的实验,将GaussDB-Vector与Milvus、ElasticSearch和PGVector等主流系统进行了对比,全面验证了其设计优势。
数据集 | 行数 | 维数 | 列数 | 标量无数据值 | 距离 |
SIFT | 10M | 128 | 1 | / | Euclidean |
GIST | 1M | 960 | 1 | / | Euclidean |
HUAWEINet | 15M | 1024 | 1 | / | Cosine |
SIFT-H | 10M | 128 | 2 | 1M | Euclidean |
GIST-H | 1M | 960 | 2 | 500K | Euclidean |
HUAWEINet-H | 10M | 1024 | 2 | 1M | Cosine |
SIFT-10B | 10B | 128 | 1 | / | Euclidean |
表1:数据集
7.1 向量查询性能分析
· 延迟、召回率与吞吐量:在所有数据集上,无论是在单连接还是50并发连接下,GaussDB-Vector都展现出最低的查询延迟和最高的吞吐量(QPS)。例如,在SIFT数据集和50并发下,GaussDB-Vector在95%召回率下的延迟约为12 ms,峰值QPS接近30,000,显著优于基线系统。这直接证明了其专为磁盘优化的索引结构和高效的并发控制机制的优越性。
数据集 | 场景 | 系统 | 95%召回率下延迟(ms) | 峰值QPS |
SIFT | 50并发 | GaussDB-Vector | ~12 | ~30,000 |
SIFT | 50并发 | PGVector | ~25 | ~15,000 |
GIST | 50并发 | GaussDB-Vector | ~10 | ~4,500 |
GIST | 50并发 | Milvus | ~13 | ~3,500 |
表2:在不同数据集上的延迟、召回率与吞吐量
· 插入性能:实验结果显示,GaussDB-Vector实现了真正的实时索引更新,其插入延迟远低于同为实时系统的PGVector,并且避免了Milvus等批处理系统因缓存刷盘而产生的高昂的P99延迟。
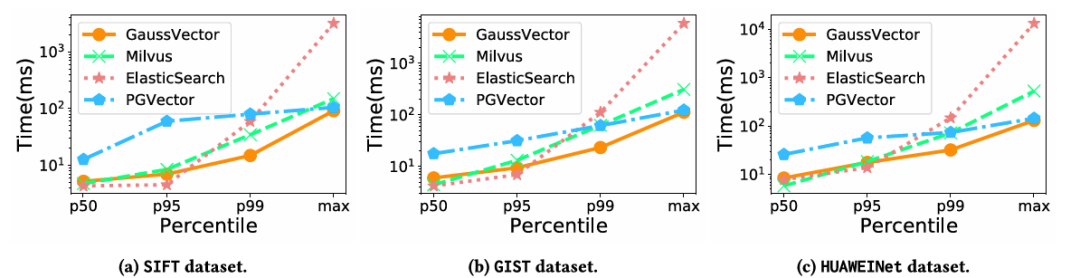
图6:插入延迟
7.2 混合查询性能分析
· 选择率影响:这是验证混合索引设计的关键实验。结果表明,GaussDB-Vector的查询延迟在不同标量选择率(10%、50%、90%)下保持高度稳定。相比之下,基线系统(尤其是PGVector)的性能在标量过滤器选择性变高(即过滤掉大部分数据)时急剧下降。这充分证明了GaussDB-Vector自适应查询策略的有效性。
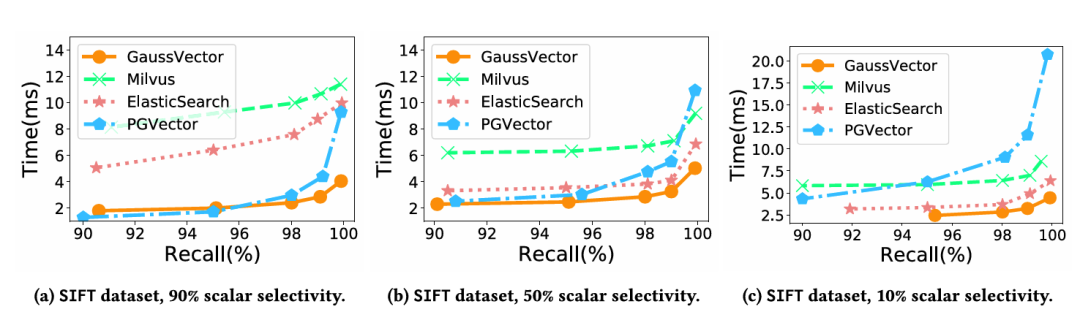
图7:标量 - 向量查询的搜索延迟
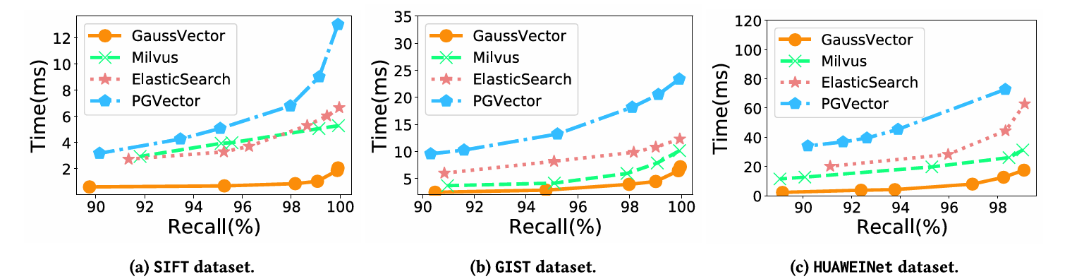
图8:混合搜索延迟对比
· 插入性能:在混合索引的插入性能测试中,GaussDB-Vector同样表现出具有竞争力的延迟,证明其设计在读写性能之间取得了良好的平衡。
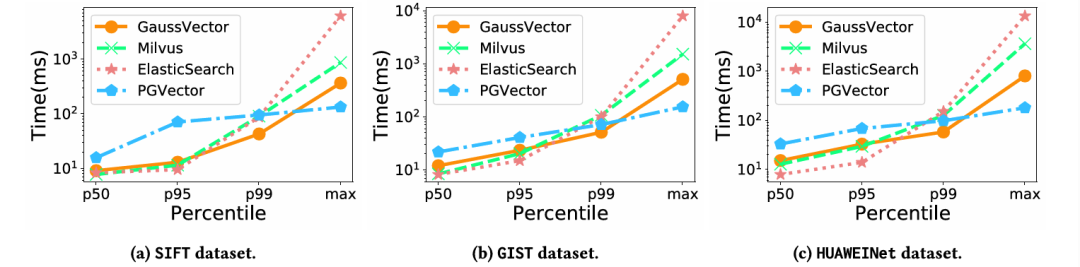
图9:带有自动递增 ID 的插入操作对比
7.3 系统可扩展性与更新吞吐量
· 可扩展性:在100亿规模的SIFT-10B数据集上,分布式GaussDB-Vector展现出近乎线性的性能扩展能力。随着机器数量增加到40台,系统达到了99%的召回率、约60 ms的延迟和1,500 QPS的吞吐量,验证了其分布式架构和智能查询路由的有效性。
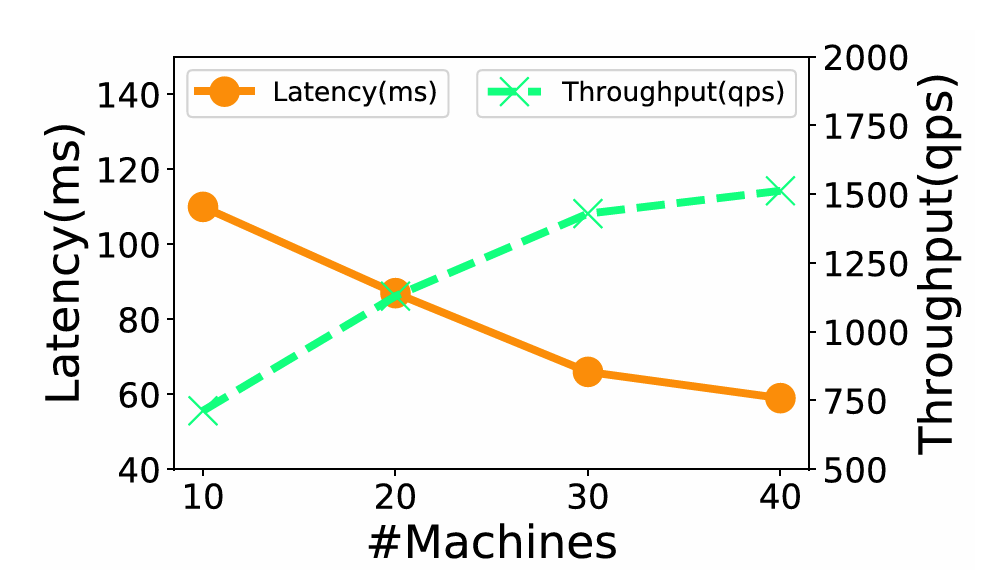
图10:可扩展性
· 更新吞吐量:实验显示,系统在持续更新负载下吞吐量保持稳定。即使因为数据删除产生碎片导致性能略有下降,定期的Vacuum操作也能及时恢复系统性能,证明了其长期运行的鲁棒性。
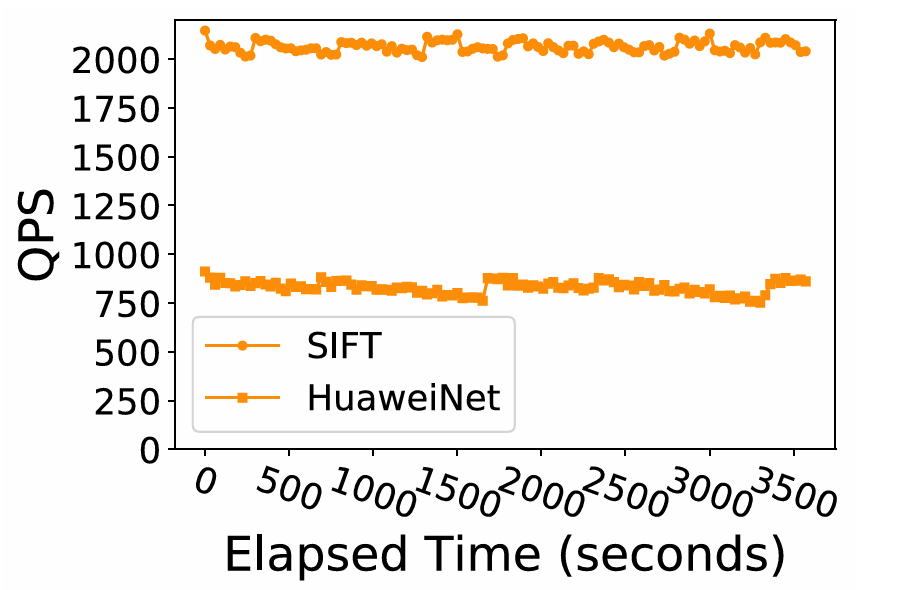
图11:更新吞吐量
7.4 硬件加速效果
· 实验量化了NPU带来的性能提升。对于索引构建和IVF扫描这类批处理任务,NPU带来了1到2个数量级的加速。同时,论文也客观地指出,对于图索引搜索这类受延迟限制的遍历任务,由于跨设备数据传输的开销,NPU带来的增益有限。
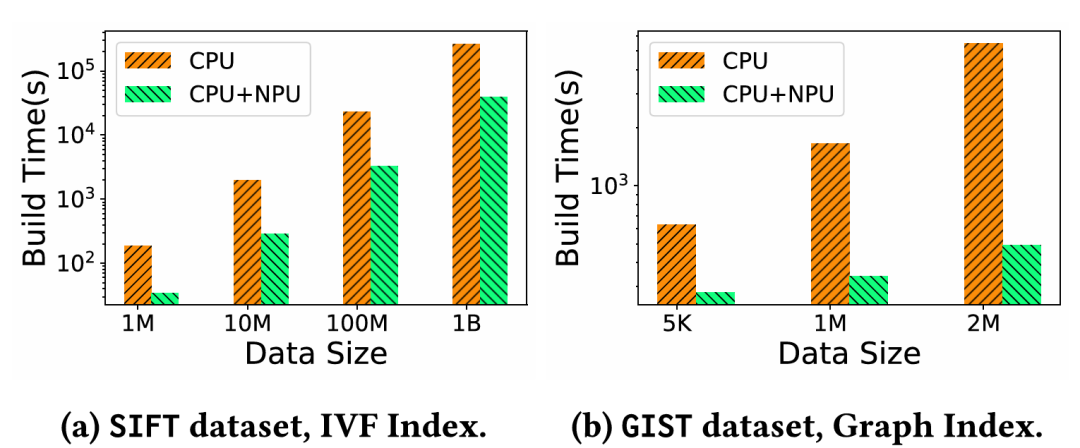
图12:通过使用昇腾 NPU 实现加速
八、结论与启示
GaussDB-Vector的提出,为面向LLM应用的大规模向量数据管理树立了新的标杆。
论文的核心贡献可以总结为:
1. 提出了一套完整的持久化实时向量数据库架构,成功证明了在磁盘常驻索引上也能实现极低的查询和更新延迟。
2. 设计了专为I/O优化的Vamana图索引物理结构,通过自适应页面布局和高效的更新算法,解决了高性能图索引在磁盘环境下的核心挑战。
3. 创新地提出了基于B树的自适应混合索引,高效且稳定地支持了任意选择性的标量-向量混合查询。
4. 实现了一套动态的分布式分片与智能路由系统,使其具备了扩展至万亿规模向量数据的能力。
这项工作所展示的设计和工程实践,为业界提供了宝贵经验。它清晰地指明,未来AI基础设施的数据库底座,可能并非是众多功能单一的专用系统,而是演化为强大的、一体化的数据平台。在这个平台中,向量将作为一种与结构化数据同等重要数据被高效管理。GaussDB-Vector不仅为构建强大、可扩展的AI应用提供了坚实的基础,更为重要的是,它提供了一个蓝图,描绘了如何构建一个真正健壮、可靠、能够胜任企业最关键任务的下一代数据管理系统。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





