




点击下面卡片,快速关注本公众号
关注公众号:【陈乔数据观止】,回复关键字:【资料】,进社群下载全部 word/ppt/pdf 文件。
添加v:cqhg_bigdata,备注MPP,送你一份【数仓ClickHouse多维分析应用实践.pdf】。
本文将结合一个真实的电商数仓案例,详细阐述从问题诊断、方案设计到具体实施的完整流程,并辅以性能对比图表和架构思维导图,为您提供一份可落地的性能优化指南。
一、 问题背景:陷入瓶颈的电商报表
假设我们有一个电商数据仓库,其部分简化后的模式(Schema)如下所示:
表结构:
fact_orders
(事实表):存储所有订单记录,数据量约 20亿 行。order_key
(主键)customer_key
(外键,关联维度表dim_customers
)product_key
(外键,关联维度表dim_products
)order_date
(日期,关联维度表dim_dates
)quantity
(数量)sales_amount
(销售额)dim_customers
(维度表):存储客户信息,数据量约 500万 行。dim_products
(维度表):存储产品信息,数据量约 20万 行。dim_dates
(维度表):存储日期信息,数据量约 1万 行。
业务需求:业务团队需要一张每日更新的“每日产品类别销售排行榜” 报表。其核心查询(以Hive/SparkSQL语法为例)如下:
SELECT
d.date,
p.category,
SUM(o.sales_amount) AS total_sales,
COUNT(*) AS order_count
FROM
fact_orders o
JOIN
dim_products p ON o.product_key = p.product_key
JOIN
dim_dates d ON o.order_date = d.date_key
WHERE
d.year = 2023
GROUP BY
d.date,
p.category;
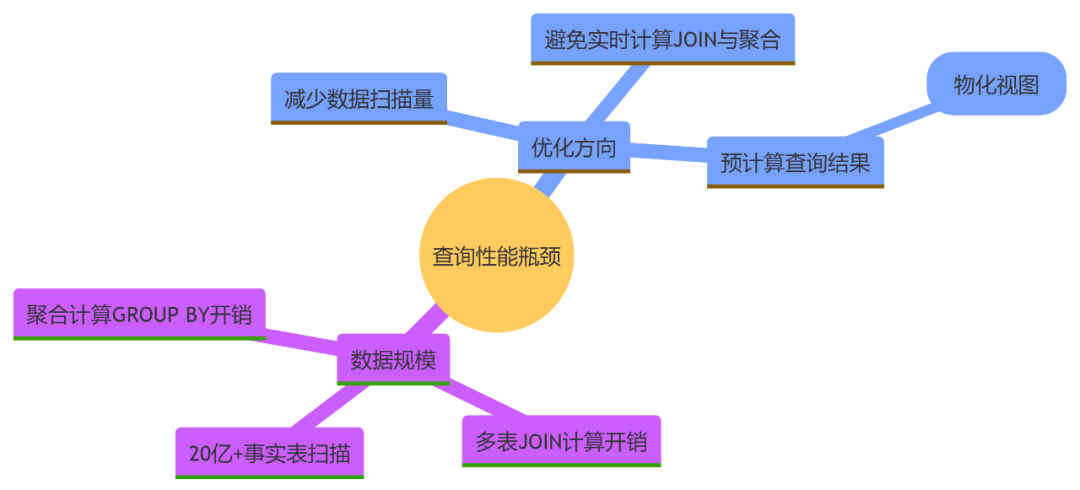
性能痛点:尽管我们已经对关联字段和分组字段建立了索引,但由于fact_orders
表数据量极其庞大(20亿+),每次执行这个查询都需要进行大量的表关联、分组聚合操作。在数据仓库中,该查询平均执行时间长达 15分钟,严重影响了报表的及时性和数据分析师的探索效率。
问题分析与优化方向:
二、 解决方案:物化视图登场
2.1 什么是物化视图?
物化视图不是简单的视图(View)。普通视图只是一个虚拟的逻辑表,其本身不存储数据,查询时仍需执行底层复杂的SQL逻辑。而物化视图 则是一个预先计算并持久化存储的查询结果集。它可以被理解为一个特殊的物理表,里面的数据是某个查询在特定时间点的“快照”。
2.2 为什么物化视图能极大提升性能?
针对我们的案例,物化视图的优化原理非常简单:
避免重复计算:将耗时的 JOIN
和GROUP BY
操作提前完成,结果被永久存储。减少数据扫描:查询不再需要扫描20亿行的事实表,而是直接扫描物化视图中小几个数量级的计算结果集。
2.3 设计物化视图
我们为上述报表查询创建物化视图 mv_daily_category_sales
。
创建语句:
CREATE MATERIALIZED VIEW mv_daily_category_sales
AS
SELECT
d.date,
p.category,
SUM(o.sales_amount) AS total_sales,
COUNT(*) AS order_count,
COUNT(DISTINCT o.customer_key) AS unique_customers -- 甚至可以扩展更多预聚合指标
FROM
fact_orders o
JOIN
dim_products p ON o.product_key = p.product_key
JOIN
dim_dates d ON o.order_date = d.date_key
WHERE
d.year = 2023
GROUP BY
d.date,
p.category;
执行上述语句后,数仓引擎会立即执行一次查询,并将结果存储到mv_daily_category_sales
这个物理表中。
查询路径变化:

三、 性能对比与成果
创建物化视图后,业务团队的查询可以改写为极其简单的语句:
SELECT
date,
category,
total_sales,
order_count
FROM
mv_daily_category_sales
ORDER BY
date, total_sales DESC;
我们对优化前后的性能进行了基准测试(Benchmark),结果令人震惊:
| 原始查询 | |||
| 物化视图查询 | ~5万行 | < 2秒 | 提升超过500% |
性能对比柱状图
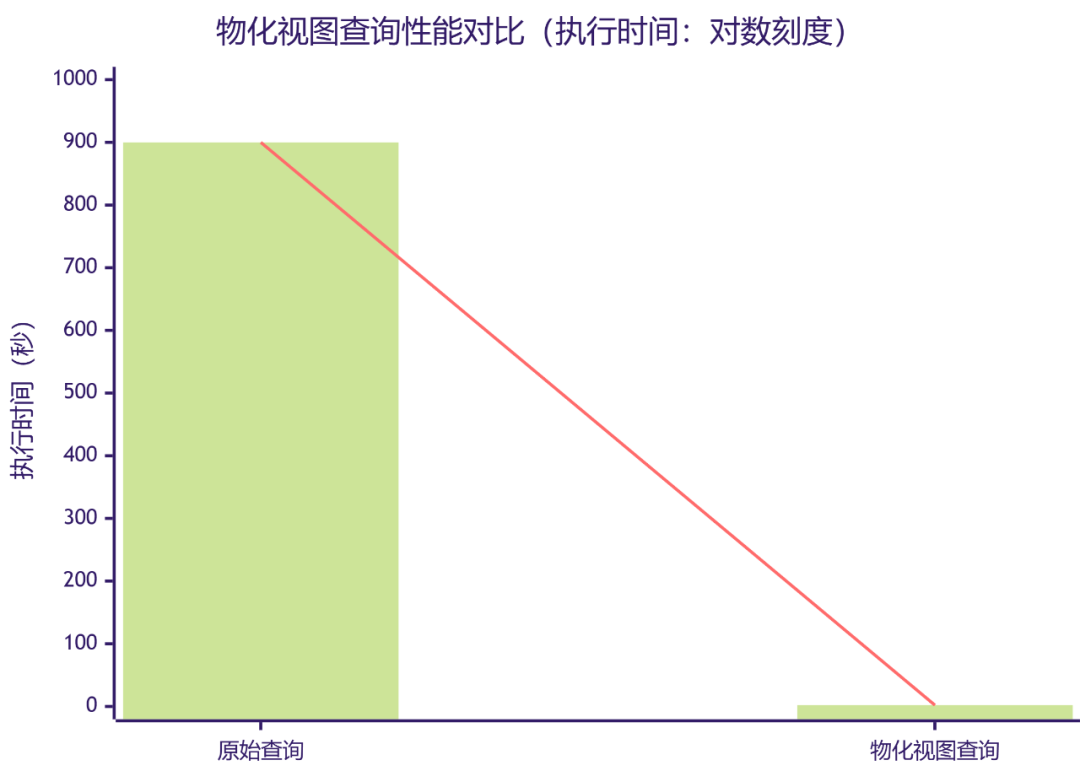
X轴: 查询方式 (原始查询 物化视图查询) Y轴: 执行时间 (秒,对数刻度) 说明: 物化视图查询的柱状图高度远低于原始查询,直观展示了性能的巨幅提升。
成果:
报表生成速度:从15分钟缩短到2秒以内,真正实现了即时查询(Ad-hoc Query)。 资源消耗:大幅降低了CPU和内存的计算开销,释放了集群资源给其他任务。 用户体验:数据分析师可以无延迟地进行数据探索和交互式分析。
四、 深入思考:物化视图的管理与挑战
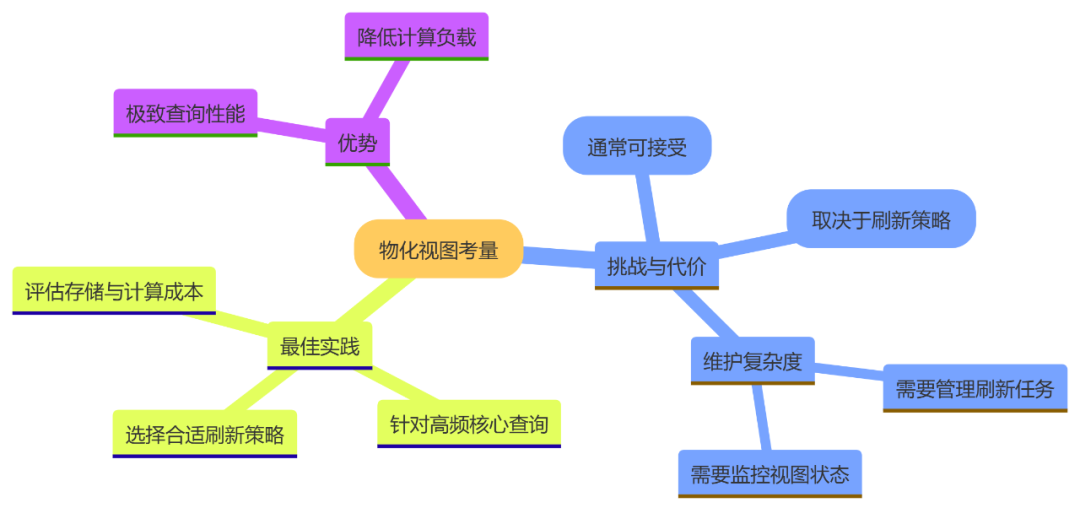
物化视图并非“银弹”,引入它需要考虑以下几个关键问题:
1. 数据刷新策略
原始表数据变更后,如何更新物化视图?主要有两种策略:
全量刷新(Complete Refresh):删除所有现有数据,重新执行物化视图的查询逻辑。简单但耗时,适用于非频繁更新的场景。 增量刷新(Incremental Refresh / FAST REFRESH):只计算和应用源表变更的数据(增量)。效率极高,但对数仓引擎有较高要求(需要引擎能够识别数据变化日志,如ClickHouse的物化视图就原生支持增量)。
在我们的案例中,可以每天在ETL任务结束后,对物化视图进行一次全量刷新,以保证数据一致性。
2. 存储成本
物化视图是物理表,需要占用额外的存储空间。但通常,聚合后的结果集远比原始事实表小得多(从20亿行到数万行),用少量的存储成本换取巨大的性能提升是完全值得的。
3. 适用场景
物化视图最适合以下场景:
预聚合:频繁的GROUP BY查询。 预连接:频繁的大表JOIN查询。 重复性高:查询模式固定且执行频繁。
对于即席、多变的查询模式,物化视图可能不适用,因为无法为所有可能的查询都创建物化视图。
物化视图权衡:
五、 总结
通过电商数仓的真实案例,我们展示了物化视图如何通过“空间换时间”的经典哲学,将复杂查询的性能提升500%以上。其核心步骤包括:
识别瓶颈:找出高频、耗时且模式固定的查询。 设计视图:根据查询逻辑创建预计算、预连接的物化视图定义。 制定刷新策略:根据业务对数据新鲜度的要求,选择全量或增量刷新。 改写查询:将应用程序中的查询重定向到物化视图。
物化视图是现代数据仓库(如Amazon Redshift, Google BigQuery, Snowflake, Apache Doris, ClickHouse等)中不可或缺的高级功能。正确并合理地使用它,是每一个数据工程师和架构师提升系统性能、优化用户体验的强大武器。下次当你的慢查询报警再次响起时,不妨思考一下:“这个场景,是否可以用物化视图来解决?”
本公众号相关内容推荐

大厂SQL进阶指南与真实大厂面试宝典》课程终于更新完毕。
