




上期内容 VexDB:源于清华的向量数据库 我们介绍了一款新向量数据库 VexDB。本期内容手把手带你快速完成 VexDB 的安装、使用,让 VexDB 先跑起来。
VexDB 是由数智引航全新推出的一款融合关系型数据库能力与多路语义检索能力的向量数据库,具备高性能、大容量、高精度、强一致性、高可用性、高安全性、易用性,支持千维向量、百亿级规模的数据毫秒级检索,召回准确度达 99% 以上。
数智引航,源于清华,专注人工智能基础设施领域。技术顾问:李国良教授。首席架构师:孙佶博士。
李国良 教授
清华大学教授,ACM/IEEE 会士,CCF数据库专委会常委,ACM SIGMOD China 副主席,VLDB Journal、IEEE TKDE、ACM Transaction on Data Science 编委,SIGMOD、VLDB、ICDE、KDD 程序委员会委员,VLDB、ICDE资深程序委员会委员。研究领域包括数据库系统、数据库机器学习、人机交互数据管理、AI 和 DB 的融合。

孙佶 博士
清华大学数据库组获得博士学位。研究兴趣包括分布式系统、相似性搜索和查询优化的机器学习。

安装 VexDB
数智引航全新发布了兼具关系型和向量功能的集中式数据库 VexDB V3.0.0,并且提供了开发版的一年免费试用期,你可以访问数智引航官网(https://vexdb.com/download)进行下载。

准备工作
本文在 x86 机器 Rocky Linux 9 系统进行安装演示。
[root@rl9 ~]# hostnamectl
Static hostname: rl9.shawnyan.cn
Operating System: Rocky Linux 9.6 (Blue Onyx)
Kernel: Linux 5.14.0-570.32.1.el9_6.x86_64
Architecture: x86-64
[root@rl9 ~]#
编辑 logind.conf 和 systemd-logind.service 文件,配置 IPC 参数。
[root@rl9 ~]# echo "RemoveIPC=no" >> /etc/systemd/logind.conf
[root@rl9 ~]# echo "RemoveIPC=no" >> /usr/lib/systemd/system/systemd-logind.service
[root@rl9 ~]#
[root@rl9 ~]# grep '^RemoveIPC' /etc/systemd/logind.conf
RemoveIPC=no
[root@rl9 ~]# grep '^RemoveIPC' /usr/lib/systemd/system/systemd-logind.service
RemoveIPC=no
修改完成后,重启 systemd-logind 服务,以重新加载配置。
systemctl daemon-reload
systemctl restart systemd-logind
调整内核参数,来分配数据库使用资源,以 4c10g 为例。
[root@rl9 ~]# free -h
total used free shared buff/cache available
Mem: 9.4Gi 1.2Gi 8.0Gi 21Mi 520Mi 8.2Gi
Swap: 5.0Gi 0B 5.0Gi
[root@rl9 ~]#
[root@rl9 ~]# grep -v '^#' /etc/sysctl.conf
fs.aio-max-nr=1048576
fs.file-max= 76724600
kernel.sem = 4096 2097152000 4096 512000
kernel.shmall = 632629248
kernel.shmmax = 10122067968
kernel.shmmin = 819200
net.core.netdev_max_backlog = 10000
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 4194304
net.core.somaxconn = 4096
net.ipv4.tcp_fin_timeout = 5
vm.dirty_background_bytes = 409600000
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 80
vm.dirty_writeback_centisecs = 50
vm.overcommit_memory = 0
vm.swappiness = 0
net.ipv4.ip_local_port_range = 40000 65535
fs.nr_open = 20480000
[root@rl9 ~]#
重新加载内核参数。
sysctl -p
安装单机开发版
VexDB 提供了交互安装脚本,你可以根据提示进行安装。以下为主要安装步骤。
上传安装包,并解压。
[shawnyan@rl9 ~]$ tar zxf VexDB-Developer-Edition-3.0_Build0_28146-Linux-x86_64-no_mot-202509011854.tar.gz
执行安装程序。
[shawnyan@rl9 ~]$ cd vexdb-installer/
[shawnyan@rl9 vexdb-installer]$ ls
locales VexDB-Developer-Edition-3.0_Build0_28146-Linux-x86_64-no_mot.tar.gz vexdb_installer
[shawnyan@rl9 vexdb-installer]$ ./vexdb_installer
===============================================================================
Welcome to the installation tool (V1.0) and start installing VexDB.
===============================================================================
Check whether the installation package is complete
---------------
ok
===============================================================================
Type <Enter> to continue:
接下来按 <Enter> 选择默认值继续进行安装即可。
这里选择 2- Custom installation 自定义安装,我们来修改一些配置参数。
Select installation type
Typical installation : Use default parameters to init database
Custom installation : Configure installation parameters and functions manually
-> 1- Typical installation
2- Custom installation
Select the installation type, or type <Enter> to select the default (1):
2
安装数据库过程会提示输入管理员初始口令。
Enter the password of database initialization user (shawnyan): **********
Please enter your password again: **********
将客户端最大连接数(``)设为 100 即可,默认为 500。把共享内存调整为 200 MB,默认为 2413 MB。其他参数默认。
Max Connections
---------------
Enter the maximum number of client connections, or type <Enter> to select the default (500):
100
===============================================================================
Shared buffers
---------------
Enter the shared memory size in MB, or enter <Enter> to select the default (2413):
200
VexDB V3.0.0 开发版提供了一年的免费试用,选择n跳过安装许可的步骤。
Loading an Official license
---------------
Whether to load an official license (Y/N): N
显示安装完成后,根据提示信息,初始化数据库运行环境:
source ~/.bashrc
到此,VexDB 安装完成。
启动数据库
可使用命令 vb_ctl <start/stop/restart> 来控制 VexDB 启停。
启动数据库。
[shawnyan@rl9 ~]$ vb_ctl start
[2025-09-16 09:38:35.263][6543][][vb_ctl]: vb_ctl started,datadir is /home/shawnyan/data/vexdb
[2025-09-16 09:38:35.545][6543][][vb_ctl]: waiting for server to start...
...
[2025-09-16 09:38:47.886][6543][][vb_ctl]: done
[2025-09-16 09:38:47.886][6543][][vb_ctl]: server started (/home/shawnyan/data/vexdb)
查看数据库运行状态。
[shawnyan@rl9 ~]$ vb_ctl status
[2025-09-16 09:41:07.441][6600][][vb_ctl]: vb_ctl status,datadir is /home/shawnyan/data/vexdb
vb_ctl: server is running (PID: 6546)
/home/shawnyan/local/vexdb/bin/vexdb
连接到 VexDB
vsql 是 VexDB 提供的客户端连接工具,你可以使用 vsql 连接到 VexDB。
[shawnyan@rl9 ~]$ vsql -d postgres
vsql ((VexDB Developer Edition V3.0 Release) compiled at 2025-09-01 19:05:51 commit 28146 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
查看数据库版本。
postgres=# select vb_version();
vb_version
------------------------------------------------------------------------------------------------
(VexDB Developer Edition V3.0 Release) compiled at 2025-09-01 19:05:51 commit 28146 last mr +
product name:VexDB Developer Edition +
version:V3.0.0 +
commit:28146 +
openGauss version:6.0.0 +
host:x86_64-pc-linux-gnu +
support module:BASIC
(1 row)
向量检索
向量数据类型
VexDB 支持 floatvector 类型,用于存储浮点类型的向量数据。一个表可以包含 1 个或者多个 floatvector 字段。每个向量是一个固定长度的数组,可以存储机器学习模型的嵌入向量、图像特征、文本的词嵌入等。
创建一个含向量列的表。
CREATE TABLE t_vector (id bigserial PRIMARY KEY, embedding floatvector(3), embedding1 floatvector(3));
插入向量数据。
INSERT INTO t_vector (embedding, embedding1) VALUES ('[1,2,3]', '[4,5,6]');
查看表数据。
postgres=# table t_vector;
id | embedding | embedding1
----+-----------+------------
1 | [1,2,3] | [4,5,6]
(1 row)
向量检索索引
VexDB 支持在向量数据上创建 IVFFlat, IVFPQ, Graph_Index, DiskANN 索引,以及向标联合索引 HybridAnn 索引。
IVFFlat 索引,采用 IVF (Inverted File System,倒排系统)算法实现快速查询向量数据的目的,IVF 算法的主要原理在于将所有向量划分成多个簇,查询时只搜索最相邻的簇,减少计算量,从而加速近似最近邻查询。
IVFPQ(Product Quantization, 乘积量化)索引是对 IVFFlat 索引的变形, 在 IVFFlat 的基础上增加了乘积量化算法,牺牲了一定的查询精度来换取构建和查询性能的优化。
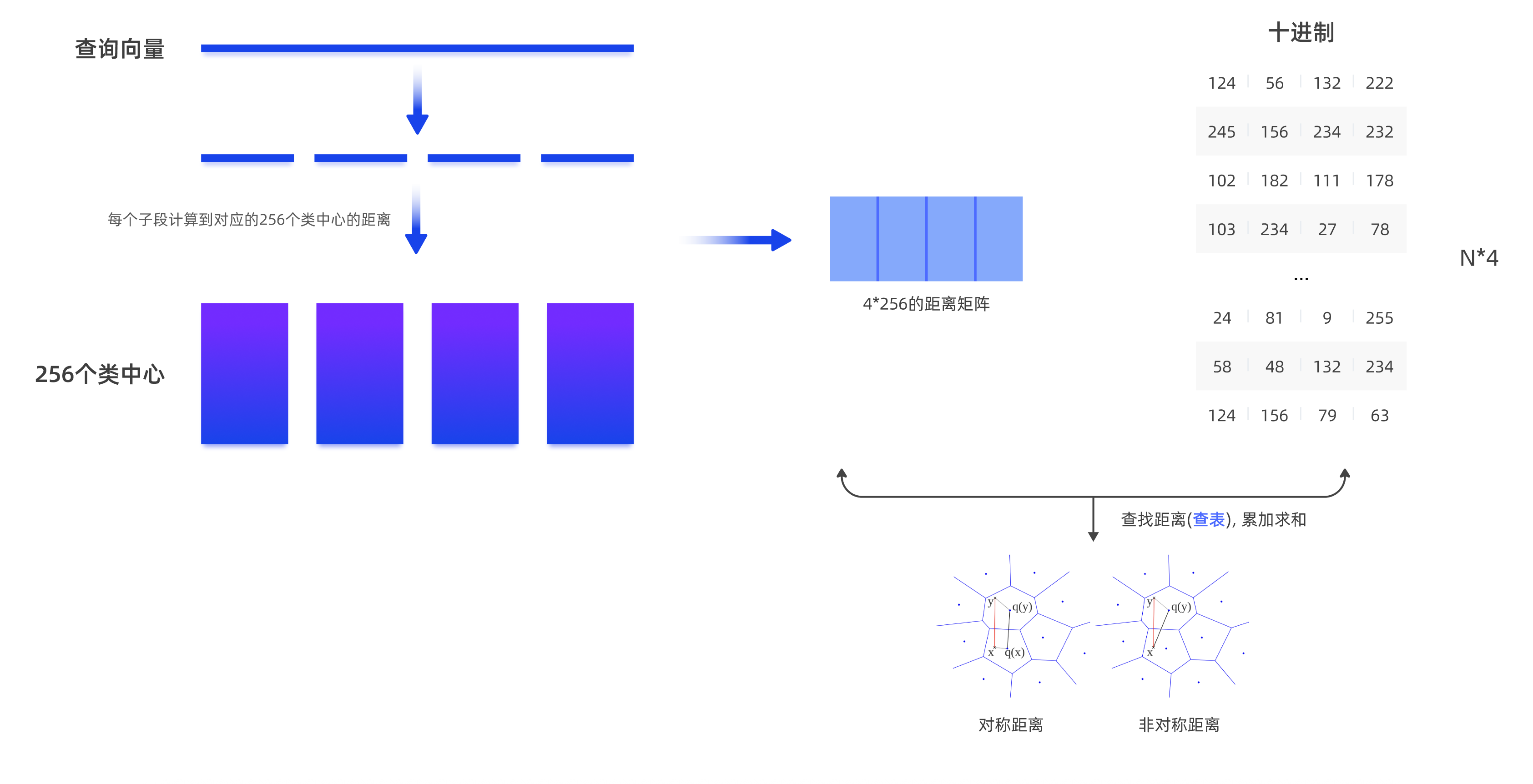
Graph_Index 是基于传统 HNSW 索引优化后得到的一种图索引,它解决了原生 HNSW 索引内存占用过高的问题。使用图索引的场景下,更推荐选择 Graph_Index。
DiskANN 索引是一种结合内存与磁盘存储的高效向量检索结构,通过图算法和量化技术优化大规模高维数据的近似最近邻搜索(ANNS,Approximate Nearest Neighbor Search),在查询速度、准确性与存储成本之间实现了兼顾。
对比表:
| 索引类型 | 核心思想 | 存储开销 | 查询速度 | 精度 | 适用场景 | 特点 |
|---|---|---|---|---|---|---|
| IVFFlat | 倒排文件 + 精确向量存储 | 高(存储原始向量) | 中等(依赖簇数量和探测数 nprobe) | 高 | 中小规模数据,需高精度 | 简单稳定,易实现,但内存占用大 |
| IVFPQ | 倒排文件 + 向量压缩 | 低(压缩存储) | 快(内存访问少) | 中(有压缩误差) | 大规模数据,内存有限 | 压缩率高,适合超大数据集,但精度会下降 |
| Graph Index | 基于图的近邻搜索(构建小世界图,贪心+多层跳跃搜索) | 高(需存储邻居关系) | 很快(log 级搜索复杂度) | 高 | 高频查询、低延迟场景 | 查询速度极快,但索引构建成本高 |
| DiskANN | 基于磁盘的 ANN,图索引 + SSD 存储 + 内存缓存 | 低(数据主要在磁盘) | 中(比内存慢,但可扩展到 TB 级) | 高 | 超大规模数据(>1B 向量),成本敏感场景 | 结合内存+磁盘,降低内存占用,查询延迟可控 |
向量标量联合索引 HybridAnn 允许在向量索引基础上额外增加对标量条件的过滤功能。在构建索引时将需要支持的标量放入索引构建目标中。HybridAnn 采用了改良后的 graph_index 作为向量检索索引,令 HybridANN 也继承了 graph_index 的更高召回率、更低内存占用和更短索引构建耗时的优势。
实操演示
接下来演示如何创建向量索引。按余弦距离构建 IVFFlat 索引。
CREATE INDEX idx1
ON t_vector
USING ivfflat(embedding floatvector_cosine_ops)
WITH(ivf_nlist= 100, enable_toast=true, parallel_workers=1);
查看表结构。
postgres=# \d t_vector
Table "public.t_vector"
Column | Type | Modifiers
------------+----------------+-------------------------------------------------------
id | bigint | not null default nextval('t_vector_id_seq'::regclass)
embedding | floatvector(3) |
embedding1 | floatvector(3) |
Indexes:
"t_vector_pkey" PRIMARY KEY, btree (id) TABLESPACE pg_default
"idx1" ivfflat (embedding floatvector_cosine_ops) WITH (ivf_nlist=100, enable_toast=true, parallel_workers=1) TABLESPACE pg_default
postgres=#
VexDB 开发
VexDB 已面向开发者提供了 Java 和 Python 接口,用户可以使用 vexdb-jdbc、vexdb-psycopg2、pyvector-vexdb 数据库驱动程序,实现对 VexDB 数据库的连接与访问。
这里不做展开,感兴趣的同学可查看官方文档。
https://vexdb.com/docs/api-reference/
总结
VexDB V3.0.0 把向量检索与关系型数据库相融合,支持多种高性能向量索引,能够同时满足结构化查询与语义检索的需求。在大模型、图像检索、推荐系统、搜索引擎等应用场景中,企业往往既需要对传统数据做精确查询,又需要对高维向量进行快速近似搜索。VexDB 将二者合一,既降低了系统复杂度和运维成本,又提升了检索效率与扩展性。对于希望在 AI 时代抓住机遇的用户而言,VexDB 提供了一条低门槛、高性能、可持续演进的数据库路径,是支撑智能应用的理想选择。
Have a nice day ~ ☕
🌻 往期精彩 ▼
- 全球 Oracle ACE 社区突破 500 位成员
- 「合集」MySQL 8.x 系列文章汇总
- 星辰资讯 | Ti 星球新鲜事(2025.09)
- TiDB:TEM on 腾讯云 尝鲜体验
- 来尔滨聊聊PostgreSQL和IvorySQL
- IvorySQL 4.6 发布:新增兼容 MongoDB 解决方案
- 一文带你了解 KING BASE 金仓数据库
- 金仓数据库 Oracle 兼容模式体验
- 崖山数据库 YAC 共享集群入门
- 新建群聊:崖山和ta的朋友们~
- 一文带你了解 KWDB 数据库
- 国产老兵“虚谷数据库”初探
- 对话晨章数据CTO张桓:中国企业出海需要更优质的合作伙伴
- VexDB:源于清华的向量数据库
- 如果国产中间件也参与国测,会有哪些厂商和产品入围
- 腾讯云数据库家族扩容:TDSQL 与 AI 共生进化
– / END / –
👉 欢迎关注我的视频号

👉 这里有得聊
如果对国产基础软件(操作系统、数据库、中间件)感兴趣,可以加群一起聊聊。
关注微信公众号:少安事务所,后台回复[群],即可看到入口。
如果这篇文章为你带来了灵感或启发,请帮忙『三连』吧,感谢!ღ( ´・ᴗ・` )~
