




部署 Ollama 大模型
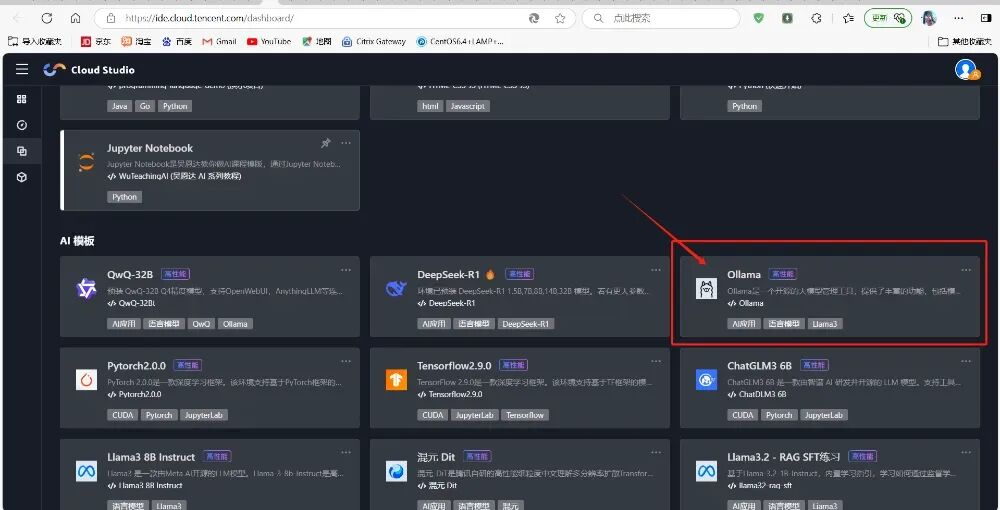
ollamarundeepseek-r1:32b
拉取模型耗时较长(约 30 分钟),需保持网络稳定。 若中断,可通过 ollama pull deepseek-r1:32b 继续拉取。
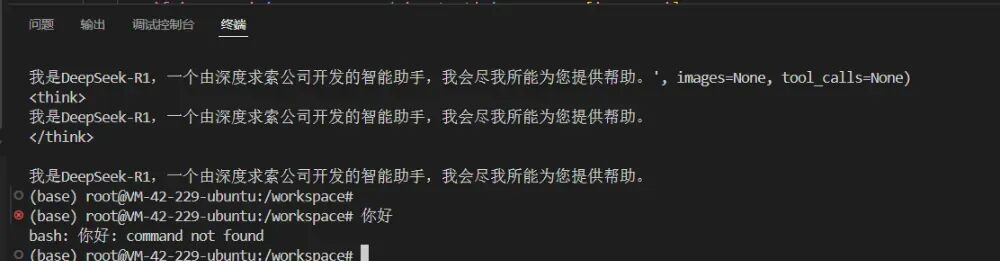
echo'export OLLAMA_HOST="0.0.0.0:12345"' >> ~/.bashrc
source ~/.bashrc
kill $(pgrep ollama) # 终止现有进程
/usr/local/bin/ollama serve & # 后台启动服务
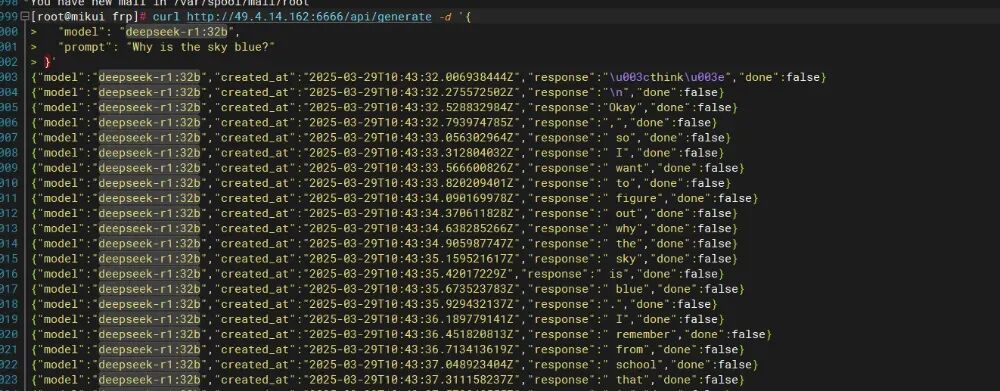
curl http://localhost:12345 # 应返回 Ollama 版本信息
需在云服务器安全组中放行 frp 使用的端口(默认 7000-7500)。 推荐使用 systemd 管理 frp 服务以避免中断。
部署 Dify
# V2docker compose up -d
# V1docker-compose up -d
若 80 端口被占用,编辑 .env 文件:
NGINX_HTTP_PORT=8080 # 修改为其他端口(如 8080)
重启服务:
docker compose down && docker compose up -d
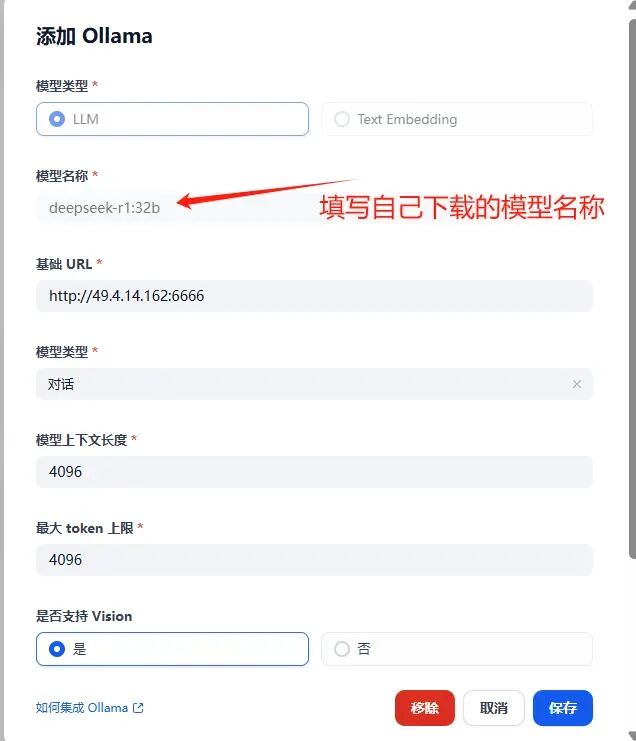
确保 Dify 与 Ollama 服务器网络互通。 若集成失败,检查 Ollama 日志:tail -f usr/local/bin/ollama/logs/server.log。
测试与验证
watch -n 1"docker stats"# 查看容器资源占用
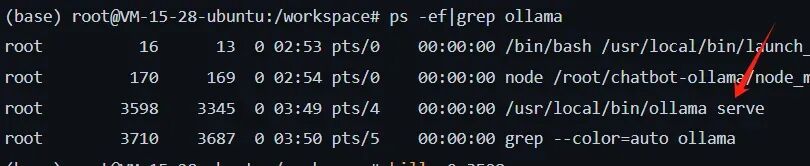
检查进程:ps -ef | grep ollama 查看日志:journalctl -u ollama.service
测试连通性:curl http://<Ollama_IP>:12345 检查防火墙规则:iptables -L -n
ollama list # 查看已安装模型
ollama rm <model> # 删除模型
本文作者:李泽基(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
