




以下是分布式数据库高可用相关的常见问题和建议。
GoldenDB 如何实现高可用
GoldenDB 数据库系统中的每个主备式的节点之间的复制方式,采用快同步方式,称之为 gSync。基于 gSync,可以灵活地在高可靠和高可用两个场景之间进行平衡。效果以下图数据节点分片1说明:
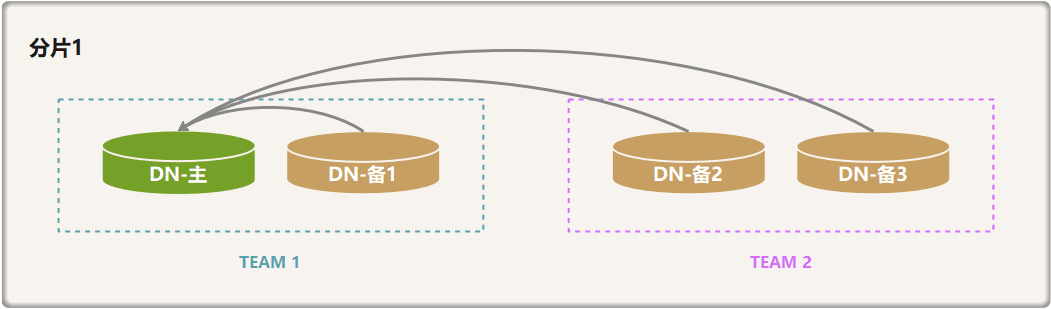
复制方式
要求: 相同 TEAM 中的 DN 节点需来自同一个机房。
TEAM:即安全组,GoldenDB 中使用 TEAM 为单位判断主备同步的状态。主机向备机同步事务,只要 TEAM 中有>= TEAM 响应数个备机同步了主机,则认为该TEAM是正常的。
基于 TEAM,我们使用分片的水位来描述分片的可用和可靠,分片水位即分片中正常 TEAM 的个数配置。
分片水位处于高水位,表示该分片处于可靠状态,主机发生故障时,数据不会丢失,RPO=0。
分片水位处于低于低水位,表示该分片处于不可用状态,无法提供写服务。
如上图中,1 个分片中有 2 个 TEAM,一般高水位设置为 2,主机不计数,低水位设置为 1,主机不计数。则:
正常 TEAM>=2 时,则分片处于高水位状态;
正常 TEAM<1 时,则分片处于低于低水位状态。
基于此,可以根据本地同城机房情况灵活调整水位配置,以达到相关要求,比如本地同城两个AZ,高低水位配置为高水位 2 主不计数,低水位 1 主不计数 ,能保证正常情况下同城机房存在强同步的副本,在本地机房故障时,同城机房不丢失数据。
GoldenDB 基于分组管理、高低水位及组合策略,实现满足业务灵活性的高可用策略设置:
分组管理: 将每个机房作为一个 TEAM 进行分组管理,达到该机房响应数(默认为 1 )时,判定为本机房已回响应。
高低水位: 水位就是已回响应的 TEAM 数。基于分组管理,可以设置一个城市所有机房的响应情况,可设置高水位阈值和低水位阈值。高水位用于设置正常运行要求,达到高水位后立刻提交。低水位用于设置机房机最低响应数要求,没有到高水位、但满足低水位要求,提交数据库事务但会产生告警。如果没有达到低水位要求,数据库事务不会提交。
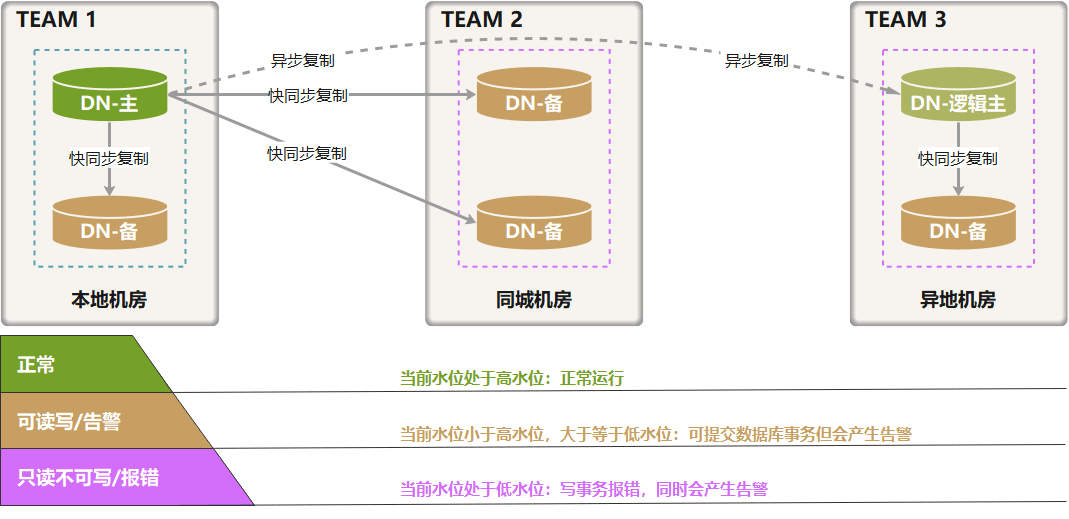
高低水位
通过不同的水位参数设置,系统可以设置成下列 3 种模式:
最大保护模式
最大保护模式要求所有分组必须都回复同步响应,能够最大程度保护数据的安全性,对应的水位是高 2 低 2 主不计数,即两个TEAM都必须回响应才能提交。
最高性能模式
最高性能模式不需要任何分组响应即可提交事务,能够自大限度满足应用的性能需求,对应的水位是高 1 低 1 主计数,即不需要任何一个TEAM回响应(主计数模式下主本身算水位 1)。
最高可用模式
最高可用模式的响应数介于最大保护模式和最大性能模式之间,既满足应用的性能需求也能满足应用的安全需求。
GoldenDB 在发生进程、机器、网络、机房、数据中心故障,在少数节点发生故障的情况下,可以实现自动切换并保证不丢数据 RPO=0,一旦发生故障可以快速恢复服务 RTO<8s 。
GoldenDB 如何规避脑裂的问题
GoldenDB 的管理节点的高可用是通过 ZK 的选举来进行控制管理的,一般场景下不会出现脑裂的情况。在极端场景下,例如主管理节点和其他管理节点发生了网络隔离,且其他管理节点满足活跃节点数量超过半数,那么管理节点会出现脑裂。但即使在这种场景下,对于租户本身而言,可以通过切换策略的配置和水位的调整来规避租户中双主的情况,从而避免租户产生脑裂的情况。
GoldenDB 的高低水位介绍和不同水位之间区别
GoldenDB 的高低水位是以 TEAM 作为基础的水位计数单位的。针对单个 TEAM 而言,如果 TEAM 内备机的响应数满足 TEAM 内配置的响应数要求,那么这个 TEAM 可以被计为一个水位。针对单个分片而言,满足高水位则分片工作正常,不会产生告警。如果水位处于高低水位之间,分片仍能正常工作,但是会有水位处于高低水位之间的告警产生。如果分片处于低水位,那么该分片只读甚至不可用。正常的系统运行都是要处于高水位及以上,如果出现了高低水位之间,则需要进行应急处置恢复高水位,防止备机进一步故障导致低于低水位从而分片不可用。
GoldenDB 的数据一致性原理
数据库最重要的一个特性就是事务,事务是数据库最小执行单元,具有原子性、隔离性、一致性和持久性的特点,即 ACID,在传统的单机数据库中已经完美的支持这个特性。业务开发时将交易代码封装到事务中,这样就不需要关注数据的状态,只要关注业务逻辑就好了,一旦交易失败,数据库自动保证数据恢复到交易之前的状态。
分布式数据库中,由于数据被水平切分,原来集中在单一节点变成分散在多个节点上,数据之间关系的完整性被割裂。原来一个节点内完成的交易,要到多个节点完成。针对分布式事务的原子性,我们从两方面入手,对于节点上未提交的事务,由数据本身的回滚机制保证。对于节点上已提交的事务,要从日志中找到对应的语句,自动生成一个反向的补偿语句,让系统自动执行这个补偿操作,使数据最终回到交易初始状态。为了完成分布式事务的原子性,我们引入了全局事务管理器即 GTM,为每个事务分配一个全局事务 GTID,事务操作会将 GTID 记录到日志中,一旦这个分布式事务失败,系统就会根据 GTID 在各分片数据节点日志中进行检索,识别出该事务执行的操作,生成反向补偿语句并执行,最终实现分布式事务的原子性。
GoldenDB 组件夯住场景的检测及解决方案
DN 组件由 DBAgent 来定时发起探活,并且会定期上报探活的结果到管理节点 ClusterManager 。如果 DN 组件发生了被夯住的场景,那么探活会失败,达到配置的阈值之后会根据是否 KILL 的配置(默认执行 KILL )来对 DN 进行处理,如果夯住 KILL 了之后,会由 ClusterManager 来判断是否要进行主备切换。CN 组件本身会由 OS 来去定期的探活,如果 CN 被夯住了,探活失败次数超过配置的阈值则会 KILL 掉夯住的 CN 节点。由于 CN 节点是无状态的,在被 KILL 重启后仍然能够对外提供服务。GTM 组件在开启夯住检查功能后会由 OS 来去定期的探活,如果 GTM 被夯住了,探活失败次数超过配置的阈值则会 KILL 掉夯住的 GTM 节点。如果夯住 KILL 了之后,会由 MetaDataServer 来判断是否要进行 GTM 主备切换。
GoldenDB 是否支持两地三中心方式部署
可以支持两地三中心的部署。需要在环境安装的时候进行规划好对应的 RZ ,AZ 以及对应的服务器规划信息,具体配置可参考一键安装章节。
GoldenDB 跨 AZ 及跨 RG 的切换介绍
GoldenDB 提供了多种切换的方式,目前能够支持同 RG 下不同 AZ 之间的演练切换、故障切换,支持跨 RG 的演练切换、故障切换,支持仅租户的跨 AZ 和跨 RG 的演练切换、故障切换。并且还支持孤岛演练。具体需要去进行演练切换还是应急处置故障切换需要根据现场的实际场景来去具体实施对应动作。
GoldenDB 管理节点出现故障对业务是否有影响
管理节点出现故障,一般不会对业务运行产生影响。但是执行 DDL 的过程中管理节点出现故障会导致 DDL 执行失败。
管理节点出现故障是否可以自动完成切换
管理节点如果在部署的时候配置了 ZK 多活的部署模式,那么管理节点出现故障后能够自动发生切换。如果是单机部署的管理节点,那么管理节点故障之后无法进行自动切换,需要应急恢复管理节点保证管理节点正常可用。
管理节点存活数量不满足多数派场景下,对 GoldeDB 切换的影响及解决方案
如果主管理节点正常运行,但是备管理节点故障了一部分导致剩余存活的管理节点数量不满足多数派的要求,这种情况下主管理节点不会主动发起切换仍能够正常对外提供服务,对系统的影响程度保持最低。
如果主管理节点发生异常且剩余的管理节点数量不满足多数派的要求,那么管理节点将无法选出新主,如果想要去应急处置,有两种方法去做决策实施,一是恢复异常的管理节点,保证存活的管理节点满足多数派。二是对管理节点配置进行修改,缩减 ZK 集群的规模从而使现存的管理节点数量能够满足多数派的要求从而选主新主。
GoldenDB 组件高可用相关配置参数及切换时间计算公式说明
GoldenDB 的高可用预期切换的时间可以通过配置项来进行调整。主要涉及的参数如下:
DN 节点相关高可用配置: DBAgent.ini 文件路径: 所有 DN 家目录 ~/etc/dbagent.ini 详细参数:
| 配置项 | 值 | 说明 |
|---|---|---|
| heartbeat_interval | 5 | DBAgent 上报给 CM 心跳的时间周期 单位:秒 |
| monitor_interval | 5 | DBAgent 监控 DN 状态的时间周期 单位:秒 |
| monitor_dml_timeout | 5 | DBAgent 监控 DN 状态过程中执行探测 SQL、和 DN 建立连接的超时时间,夯住 DN 的情况下必定超时。 单位:秒 |
| monitor_kill_db_after_detect_fail | 1 | DBAgent 监控 DN 状态异常置为 DB_FAILED 后,是否进行KILL DN 的动作,防止 DN 夯住场景出现。默认为1表示开启 |
| connect_test_try_max_times | 6 | DBAgent 在监控 DN 时发现 DN 异常后的重试次数,重试次数超过配置值后仍异常,则将 DN 的状态置为 DB_FAILED,通过心跳上报给 CM 单位:次 |
DN 节点相关高可用配置: clustermanager.ini 文件路径: 所有管理节点家目录 ~/etc/clustermanager.ini 详细参数:
| 配置项 | 值 | 说明 |
|---|---|---|
| check_lost_heartbeat_interval | 10 | CM 检测 DBAgent 是否上报过心跳的时间周期 单位:秒 |
| max_allow_loss_heartbeats_times | 3 | CM 检测 DBAgent 连续丢失心跳的次数,超过该次数,CM 认为 DBAgent 异常,如果是主节点,则触发故障切换,故障切换中,如果有备机,且存在复制关系正常的备机,则不认为主 DN 异常,可能就是 DBAgent 故障了,放弃该次故障切换。 单位:次 |
| unlink_percent | 100 | 在故障切换过程中的网络抖动的判断,如果主所在城市的所有异常的副本数/主所在城市的所有 副本数*100% 超过这个配置,则认为是网络抖动,不进行故障切换。在机房级故障时,尤其要关注,可调整为 100 让机房级故障切换能够进行。 单位:% |
| switch_timeout | 180 | 切换过程中等备机升主的超时时间,超过该时间则升主失败,切换失败。 单位:秒 |
| query_binlog_pos_timeout | 60 | 切换过程中 CM 等待备机回放完成的时间。 单位:秒 |
DN 故障切换时间计算公式说明:
一个主 DN 夯住时触发故障切换的时间与 monitor_dml_timeout 配置有关,该配置项为监控流程中 DBAgent 连接 DN 的超时时间,如果夯住 DN,连接必定超时,每个监控周期可能会变化。在 monitor_dml_timeout < monitor_interval (建议差值最好大于等于 2)的场景时,详细计算公式如下:
min: 2 * monitor_interval + monitor_interval * (connect_test_try_max_times-1) + monitor_interval
max: monitor_interval + monitor_interval * 2 + monitor_interval * (connect_test_try_max_times -1) + monitor_interval + heartbeat_interval主动停止一个主 DN 节点触发故障切换的时间的计算公式如下:
min:check_lost_heartbeat_interval * (max_allow_loss_heartbeats_times-1)
max:check_lost_heartbeat_interval * (max_allow_loss_heartbeats_times+1)如果想缩短故障切换时间,则修改相关参数,但是请保持 check_lost_heartbeat_interval > heartbeat_interval
GTM 节点相关高可用配置: metadataserver.ini 文件路径: 所有管理节点家目录 ~/etc/metadataserver.ini 详细参数:
| 配置项 | 值 | 说明 |
|---|---|---|
| MasterGTMSwitchWaitTime | 50 | 主 GTM 异常切换发起等待时长 单位:0.1s |
| MasterGTMCheckWaitTime | 600 | 主 GTM异常时,异常 GTM 数量大于阈值(gtm_abnormal_rate)或者备 GTM 上报主正常的数量大于阈值(slave_report_matser_gtm_normal_rate ),MDS 用于检查主 GTM 定时器时长 单位:0.1s |
| gtm_abnormal_rate | 100 | GTM 异常率,0 表示关闭;如果主 GTM 与 MDS 链路异常,检查所有 GTM 与 MDS 异常率,如果超过该阀值,则认为 MDS 自身异常,停止切换主 GTM 单位:% |
| slave_report_matser_gtm_normal_rate | 50 | 备机上报主机状态正常率,0表示关闭;如备机上报与主机正常率,超过该阀值,则不启动切换 单位:% |
GTM 节点相关高可用配置: gtm.ini 文件路径: 所有 GTM 家目录 ~/etc/gtm.ini 详细参数:
| 配置项 | 值 | 说明 |
|---|---|---|
| SyncGTIDTimeOut | 20 | GTID 增量同步超时时长 单位:0.1s |
| SyncSeqTimeOut | 20 | 自增列、序列增量同步超时时长 单位:0.1s |
| gtm_handlethread_num | 6 | 工作线程数量, > = 6, 现在最大100, 根据实际的集群数量调整, 修改 GTM 集群中所有 GTM 的此配置项 单位:个 |
GTM 节点相关高可用配置: os.ini 文件路径: 所有 管理节点以及 GTM 家目录 ~/etc/os.ini 详细参数:
| 配置项 | 值 | 说明 |
|---|---|---|
| heartbeat_gap | 2 | 心跳检测间隔时间 单位:s |
| max_heartbeat_fail_num | 8 | 最大心跳检测失败次数 单位:次 |
GTM 故障切换时间计算公式说明:
一个主 GTM 夯住触发故障切换的时间与 MasterGTMSwitchWaitTime 值有关,该配置项为 MDS 判断主 GTM 是否异常的等待时间,等待 MasterGTMSwitchWaitTime 时间后,如果发现主 GTM 还处于异常状态,则发起切换。
同时也与 OS 组件心跳参数 heartbeat_gap 与 max_heartbeat_fail_num 有关。
详细时间计算公式如下:
MasterGTMSwitchWaitTime + heartbeat_gap*max_heartbeat_fail_num + 新主GTM等待备机向主机建链定时器(2s)
Min: 5 + 2*8 + 2 = 23s
Max: 23s + 冗余超时(5s) = 28若超出最大值为切换逻辑异常。
主动停止一个主 GTM 触发故障切换的时间与 MasterGTMSwitchWaitTime 值有关,该配置项为 MDS 判断主 GTM 是否异常的等待时间,等待 MasterGTMSwitchWaitTime 时间后,如果发现主 GTM 还处于异常状态,发起切换。详细时间计算公式如下:
MasterGTMSwitchWaitTime + 新主GTM等待备机向主机建链定时器(2s)
min:5 + 2 = 7s
max:7s + 冗余超时(5s) = 12s若超出最大值为切换逻辑异常。
备 DN 异常对读写分离的影响
如果配置了读写分离,当承接了读的备机出现异常后会导致查询语句失败。在 CN 探活到 DN 异常之后,会将异常的 DN 从读写分离的票箱中剔除出去,剔除之后后续的走备 DN 的读请求会往状态正常的 DN 上发送执行。
如何观测 GoldenDB 组件的高可用异常
GoldenDB 的 Insight 管理平台上能够展示所有组件的状态信息。当系统中组件发生异常时,运维人员可以 Insight 界面–租户管理–实例–数据节点下查看到组件状态是异常。对于管理节点以及大数据组件的状态信息,能够通过资源管理–集群管理来进行查看。另外组件发生异常时,Insight 图形界面上告警管理中也会有相关告警信息的上报,如果配置了告警推送的相关功能,或者对接了客户的运维平台,能够通过短信的方式来提醒客户告警信息。
管理节点的高可用切换优先级的配置方法
一键安装完后即固定。优先级 number 越小,优先级越高。
优先级配置可查看 OmmAgent 配置文件 haconfig.xml 的 <priorityNumber>1</priorityNumber> 配置。配置文件路径:Manager 用户家目录下 ommagent/etc/haconfig.xml 如果需要调整优先级,需要修改所有的管理节点 Manager 用户和 Insight 用户的 OmmAgent 配置文件 haconfig.xml ,调整优先级,之后重启上述组件下的 OmmAgent 进程。
GoldenDB 中主备 DN 不一致的影响及解决方案
无法正常接入主 DN。如果想要正常作为备机接入到主 DN 中,可以考虑用备份恢复的方式,备份主 DN 的数据之后恢复到要接入的备 DN 上,之后该备 DN 可以正常作为备机接入到主 DN 中。
GoldenDB 检测到丢包、闪断、延迟等网络异常后处理方案
对于 GoldenDB 的高可用设计而言,只要网络的相关异常没有触发到 DN、GTM 等组件的探活的阈值,那么就不会触发高可用的切换。需要针对实际的网络状态去实际的分析影响的程度,比如说网络中断 1s 和网络中断 1min,影响的程度大小直接决定了实际的高可用表现是维持正常还是主备切换。所以需要具体问题具体进行分析。但上述的网络条件下数据的一致性,GoldenDB 是能够保证的。
