




数据库管理372期 2025-10-04
数据库管理-第372期 磁盘和CPU之间为什么会有缓存和内存(20251004)
作者:胖头鱼的鱼缸(尹海文) Oracle ACE Pro: Database PostgreSQL ACE 10年数据库行业经验 拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证 墨天轮MVP,ITPUB认证专家 圈内拥有“总监”称号,非著名社恐(社交恐怖分子) 公众号:胖头鱼的鱼缸 CSDN:胖头鱼的鱼缸(尹海文) 墨天轮:胖头鱼的鱼缸 ITPUB:yhw1809 IFClub:胖头鱼的鱼缸 除授权转载并标明出处外,均为“非法”抄袭

要理解 CPU 物理核心如何操作数据,需先厘清其配套存储体系的设计规则与分工,原内容中的部分细节需修正补充,具体如下:
- L1缓存 CPU的每个物理核心会独享一套L1缓存(通常分为L1I指令缓存和L1D数据缓存),用于存放核心当前正在执行的指令、以及正在处理的临时数据。其容量确实较小,一般为几十KB级别(例如常见的32KB L1I+32KB L1D),L1的核心价值是 “极低延迟”(通常仅几个时钟周期),让核心无需等待即可获取关键数据。
- L2缓存 根据CPU的DIE(核心晶粒)或CCD(核心复合体)设计,多个物理核心会共享一块L2缓存(例如1个CCD 内的4个核心共享1块L2)。其容量通常为几百KB到十几MB级别,作用是承接L1缓存的 “溢出数据”,平衡延迟与容量。
- L3缓存 整个CPU会共享一块L3缓存,是CPU内部容量最大的高速缓存。其容量范围广泛,从几十MB到上百MB,核心作用是汇总所有物理核心的缓存数据,减少CPU对外部内存的直接访问,降低整体数据延迟。
- 内存控制器与内存 根据CPU 的DIE/CCD设计,其内部会集成多个内存控制器(而非 “由多个内存控制器连接”),这些控制器直接负责与内存(如 DDR4、DDR5)建立数据通道,实现CPU与内存之间的高速数据读写 —— 内存是 CPU 的 “主力临时数据仓库”,容量远大于缓存(通常为8GB-数TB不等),但延迟高于缓存(约几十到上百个时钟周期)。
- 磁盘存储(SSD/HDD) 磁盘(包括SSD固态硬盘、HDD机械硬盘)是持久化存储设备,实际逻辑是:非临时数据(如操作系统文件、应用程序、用户文档、数据文件等)会持久化存储在磁盘中。
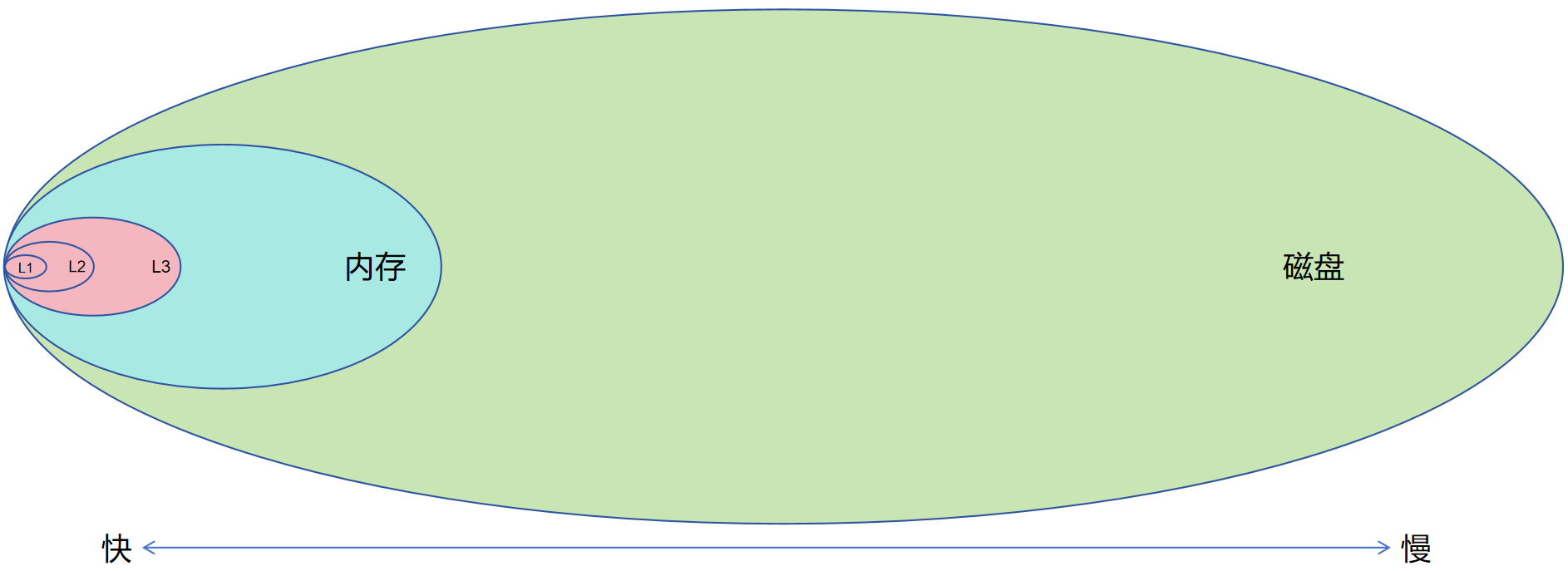
当CPU需要处理这些数据时,数据会先从磁盘加载到内存,再从内存逐步加载到L3、L2、L1缓存,最终由物理核心操作。临时数据(如计算过程中的中间结果)则主要在缓存和内存中流转,无需写入磁盘;而需要持久化保存的数据则均会写入磁盘中。在学习 Oracle 数据库的过程中,我们会先掌握一个核心存储逻辑:Oracle中几乎所有数据操作(如查询、更新、插入)都并非直接作用于磁盘,而是先加载到数据库内存结构(如SGA中的buffer cache)中完成处理,后续再通过数据库的写进程(如LGWR、DBWR数据写入进程)按特定策略持久化到磁盘(如数据文件)。这时候很容易产生一个疑问:既然数据最终要存到磁盘,为何不设计成让CPU直接对磁盘进行数据操作?其实核心原因在于CPU与磁盘的性能需求完全不匹配,而这种不匹配的关键,就体现在我们之前讨论过的延迟和带宽两个核心指标上——内存的存在,正是为了弥补这种不匹配,充当 CPU 与磁盘之间的 “性能桥梁”。
以AMD Zen3平台为例,对比缓存、内存(DDR4)的带宽与延迟:
| 缓存级别 | 读取带宽 | 写入带宽 | 拷贝 | 延迟 |
|---|---|---|---|---|
| L1 | 3300GB/s | 1700GB/s | 3400GB/s | 0.9ns |
| L2 | 1700GB/s | 1500GB/s | 1600GB/s | 2.7ns |
| L3 | 1100GB/s | 1050GB/s | 1000GB/s | 14.5ns |
| DDR4 | 55GB/s | 54GB/s | 52GB/s | 72.1ns |
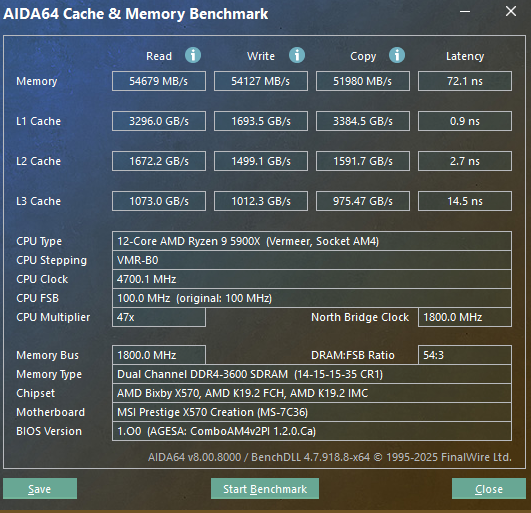
这里可以看到,CPU缓存在带宽和延迟方面对比内存有压倒性优势,类似的场景也出现在内存(DDR5)、NVMe SSD和HDD的延迟和带宽的对比:
| 存储类型 | 带宽范围 (连续读写) |
带宽范围 (4K随机读写) |
延迟范围 (平均访问) |
核心特点 |
|---|---|---|---|---|
| 内存 (DDR5) |
读: 40~55GB/s 写: 35~50GB/s |
读: 30~45GB/s 写: 25~40GB/s |
20-100ns | 速度快,延迟低,断电数据丢失 |
| NVMe SSD (PCIe 4.0) |
读: 3~8GB/s 写: 2~7GB/s |
读: 400~1200MB/s 写: 300~1000MB/s |
20~200ns | 无机械部件,速度较快,延迟较低 |
| HDD | 读: 100~220MB/s 写: 90~200MB/s |
读: 0.5~2MB/s 写: 0.3~1.5MB/s |
5~10ms | 依赖机械臂+盘片旋转,延迟极高 |
我们可以用 “翻书查资料” 的日常场景,直观类比计算机中CPU获取数据的逻辑 —— 从 “最快响应” 到 “最慢操作”,对应缓存、内存、磁盘的层级分工,其核心目的是避免 “等待” 浪费核心能力(大脑/CPU):
- 记忆→对应 “缓存” 最理想的状态是直接凭记忆回忆起资料内容,无需额外操作,这是最快的方式。类比到计算机中,就是 CPU 的 L1/L2/L3 缓存 —— 容量虽小,但延迟极低,能让 CPU 直接获取最常访问的关键数据,避免 “向外求助” 的等待。
- 提前整理的材料→对应 “内存” 若记忆无法覆盖,此时若有一份提前整理好的 “核心资料汇总”(比如按需求筛选后的重点页复印件),无需翻找原书,直接查看汇总即可。这就像内存的作用——作为 “中间缓冲层”,加载磁盘中高频访问的数据,速度远快于直接读磁盘,让CPU能快速拿到所需数据,无需长时间等待。
- 原始书籍→对应 “磁盘” 若需要深究细节,只能去翻找完整的原始书籍,一页页查找目标内容 —— 这是最慢的方式。类比计算机中的磁盘(HDD/NVMe SSD),它是数据的 “持久化仓库”,容量大但访问延迟高;若CPU直接读磁盘,就像人逐页翻书一样,会产生大量等待时间,导致CPU(或大脑)处于空闲状态,浪费计算能力。
在多数常规数据使用场景(排除数据量极小、可直接全量缓存到内存的特殊情况) 中,计算机遵循 “局部性原理”—— 仅有少量数据会被 CPU 频繁访问。此时,缓存与内存的组合能发挥关键作用:
- 通过 “缓存(快但小)+内存(中速且容量适中)” 的层级设计,大幅降低CPU对 “慢设备(磁盘)” 的依赖,平滑提升整体IO(数据输入输出)能力;
- 让CPU尽可能 “不等数据”,持续高效地执行计算任务,避免因等待磁盘数据而浪费宝贵的算力资源。
尽管内存是提升 CPU 效率的关键,但它的扩展存在明确的硬件限制,无法无限制增大:
- 单CPU的硬件上限 一颗CPU的内存支持能力,由其DIE/CCD设计、内存控制器规格直接决定——例如最大支持的内存通道数、单CPU可管理的最大内存容量,超过上限则无法识别或稳定运行。
- 多CPU场景的NUMA问题 若系统采用多CPU(如双路、四路服务器)搭配多内存,需额外考虑 “NUMA(非统一内存访问)” 架构的影响——每个CPU会优先访问 “本地直连的内存”,访问其他CPU的 “远程内存” 时延迟会显著增加,需通过硬件优化或软件调度(如操作系统、数据库的NUMA适配)减少性能损耗。
随着技术的不断发展,为了进一步提升CPU获取数据的速度和带宽,出现了下面一些技术/方案:
- L3缓存堆叠 该技术的典型应用是AMD消费级CPU的X3D系列(如游戏神U 9800X3D),核心思路是通过3D堆叠工艺大幅扩容L3缓存,将原本几十MB级别的L3缓存提升至百MB级,甚至向GB级迈进。更大的L3缓存能让CPU更大概率在高速缓存中命中所需数据,显著减少对延迟更高的内存的访问频次,从而提升算力密集型任务(如游戏、渲染)的效率。据公开信息,AMD下一代服务器级CPU的L3缓存容量预计将达到1.5GB,进一步强化服务器场景下的多核心数据共享能力。
- RDMA 该技术主要面向多节点计算场景,核心目标是提升跨节点(如多服务器组成的集群)的内存访问效率。其关键优势在于:无需通过本地CPU中转,即可让本地服务器直接读取/写入远程服务器的内存,彻底绕开传统网络传输中CPU参与的瓶颈,实现低延迟、高带宽的跨节点数据交互。目前RDMA技术的成熟落地案例集中在高端企业级一体机,例如 Oracle Exadata、SuperCluster 等产品,通过硬件与软件的深度优化,将 RDMA 与数据库、计算任务深度融合,满足金融、电信等行业对分布式数据处理的严苛需求。
- PMEM 又称非易失性内存,是一种介于标准DRAM(易失性内存)与NVMe SSD(持久化存储)之间的 “中间层存储”。其核心特性是兼具内存级的访问速度与磁盘级的持久化能力(断电后数据不丢失),容量通常比DRAM更大(如单条 128GB、256GB),可作为 “超大容量缓存层” 或 “低速内存扩展层” 使用——既缓解了 DRAM 容量不足的问题,又比 NVMe SSD的访问延迟更低,从而提升数据缓存与复用效率。
- CXL 作为一种新型高速互连协议,CXL的核心价值是打破传统总线的带宽与延迟瓶颈,实现CPU、内存、加速器(如GPU、FPGA)之间的高效扩展与数据联通。它能让外部设备(如扩展内存模块、加速卡)以接近CPU直连内存的效率与CPU交互,大幅提升系统的扩展性。不过,该技术当前面临的核心挑战在于:如何在CPU直连DRAM(低延迟、高带宽) 与CXL扩展内存(延迟略高、带宽可能存在差异)之间实现平滑对接——例如需解决两者的数据一致性、延迟协调、带宽分配等问题,避免因性能差异导致整体系统效率受限。
本期又瞎扯了一些硬件技术,老规矩,不知道写了些啥。
