




1、io_uring介绍
io_uring 是 Linux 内核 5.1 版本引入的高性能异步 I/O 框架,旨在解决传统异步 I/O 接口(如 epoll、select、poll)的性能瓶颈问题。其核心设计通过双环形缓冲区(提交队列 SQ 和完成队列 CQ)实现用户态与内核态的高效通信,显著降低系统调用开销和上下文切换频率。
1.1为什么需要io_uring
传统的IO模型存在以下核心问题,导致难以满足高并发、低延迟场景的需求:
1) 同步IO的阻塞问题:同步 IO(如read/write)会阻塞进程,导致 CPU 利用率低,无法充分利用硬件资源。
2) libaio的局限性:作为早期异步 IO 接口,libaio仅支持直接 IO(O_DIRECT,绕过页缓存),不适合依赖页缓存的场景(如普通文件读写),且接口设计复杂,支持的 IO 操作类型有限(如不支持网络 IO);io请求元数据开销较大,每个 I/O 请求需拷贝 64+8 字节的提交元数据,完成事件还需额外拷贝 32 字节,总计 104 字节的元数据拷贝。对于小 I/O 操作(如 4KB 以下),此类开销占比显著,影响吞吐量。
3) epoll的低效交互:epoll是 IO 多路复用机制,本质是 “事件通知” 而非 “异步 IO”—— 它仅告知用户 “IO 可操作”,实际读写仍需用户主动调用同步接口(如recv/send),存在频繁的用户态与内核态切换开销,且高并发下事件处理逻辑复杂。
io_uring的优势:
1. 与libaio相比:更通用、更高效
1) 支持范围更广:libaio仅支持磁盘 IO,且强制要求O_DIRECT(绕过页缓存),无法利用内核页缓存提升性能;io_uring支持所有类型的 IO(磁盘、网络、管道等),且无需O_DIRECT,可正常使用页缓存,兼顾缓存收益和异步特性。
2) 接口设计更高效:libaio的io_submit和io_getevents是独立系统调用,高并发下系统调用开销大;io_uring通过共享队列(提交队列 SQ、完成队列 CQ)实现批量 IO 操作:用户态将多个 IO 请求写入 SQ,内核处理后将结果放入 CQ,全程可通过内存映射(mmap)直接操作队列,大幅减少系统调用次数(甚至可做到 “零系统调用” 批量处理)。
3) 功能更完善:libaio仅支持基础读写,不支持fsync、accept等操作;io_uring支持几乎所有 IO 相关操作(包括fsync、recvmsg、sendmsg、accept4等),覆盖更多场景。
2. 与epoll相比:真正的异步 IO,更低开销
1) 从 “事件通知” 到 “全程异步”:epoll的核心是 “通知用户何时可执行 IO”(如 “socket 可读”),但实际读写仍需用户主动调用同步函数(如recv),存在两次上下文切换(等待事件→处理 IO);io_uring是真正的异步 IO:用户发起 IO 请求后无需等待,内核全程处理 IO(包括数据拷贝),完成后直接将结果放入 CQ,全程仅需一次用户态 / 内核态交互(读取结果),大幅减少切换开销。
2) 更低的延迟和更高的吞吐量:epoll在高并发下需频繁调用epoll_wait等待事件,且事件处理逻辑需用户态维护状态(如连接上下文),复杂度高;io_uring的队列机制天然支持批量操作,且内核可预分配资源(如请求结构),减少动态内存分配开销,在高并发场景下吞吐量显著高于epoll。
3) 更灵活的调度:epoll的事件触发依赖内核调度,用户态无法干预 IO 处理顺序;io_uring支持 “优先级” 和 “链接请求”(如 IO 完成后自动触发下一个请求),可灵活控制 IO 执行顺序,优化业务逻辑。
1.2 io_uring的架构
io_uring需要Linux内核5.1以上,架构如下图所示。在共享内存中维护2个环形缓冲区,用于用户空间和内核空间的两个队列。SQ提交队列:用户空间的进程使用该队列向内核发送异步IO请求;CQ完成队列:内核使用该队列向用户空间返回异步IO操作的结果。
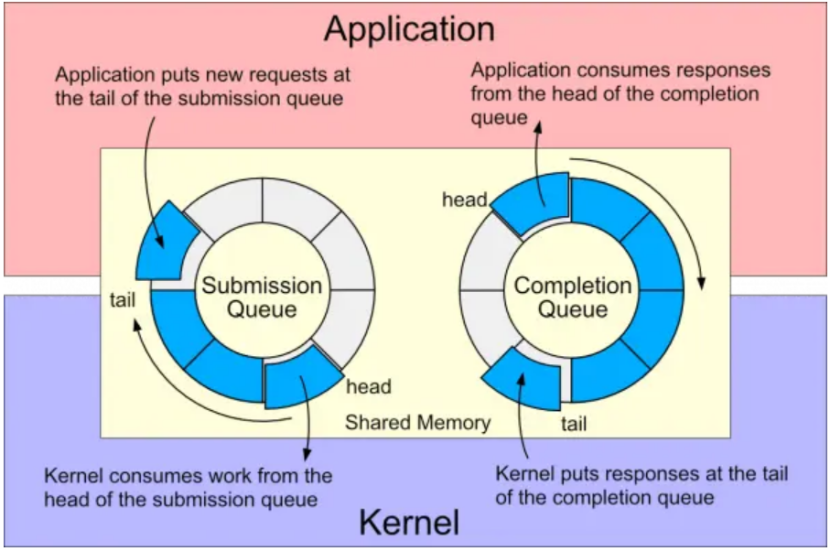
系统调用API包括:
1) io_uring_setup:设置异步IO执行的上下文
2) io_uring_register:注册文件或者用户缓存用于异步IO
3) io_uring_enter:启动或者完成异步IO
前两个API用于设置io_uring实例和可选地注册io_uring操作引用的buffer。队列submission和consumption时仅需调用io_uring_enter。调用io_uring_enter的代价可以分摊到多个IO操作上。对于非常繁忙的服务器,可以通过将内核中的submission队列开启busy-polling,从而避免完整调用io_uring_enter。代价时需要一个内核线程消耗CPU。
2、PgSQL18异步IO
2.1 异步IO带来的优势
1)同步read和write的时候,虽然会主动让出CPU,但当前进程/线程会阻塞,直到数据返回,线程阻塞可能导致并发能力受限。异步IO的时候,当前进程/线程不阻塞,可以继续执行其他任务,比如checkpoint刷脏页流程:write一个脏页时提交请求后就返回,然后继续下一个脏页的write请求处理,内核异步处理write,而NVMe SSD支持64K队列深度,可以同时处理数万个请求,异步IO可以将SSD的硬盘并发充分利用起来。对于select扫描场景来说,提交read异步请求后,虽然可以不阻塞立即返回,但是会在后面检查对应页是否加载到内存,若还没有,则仍旧需要等待。epoll_wait在等待时会主动让出CPU,而select/poll会持续占有CPU资源。当然这里如果仅扫描一个页后,需要立即等待,中间没有其他任何其他的工作可以做,那么这种场景发起异步读不仅不会带来收益,可能还会恶化,因为相对于同步IO来说还有发起异步IO的代价,比如PgSQL18的heap_insert获取待插入页的场景。
2)PgSQL18异步IO读在顺序扫描的场景下进行预读时,可以异步提交多个IO读请求,从而带来收益。
2.2 顺序扫描
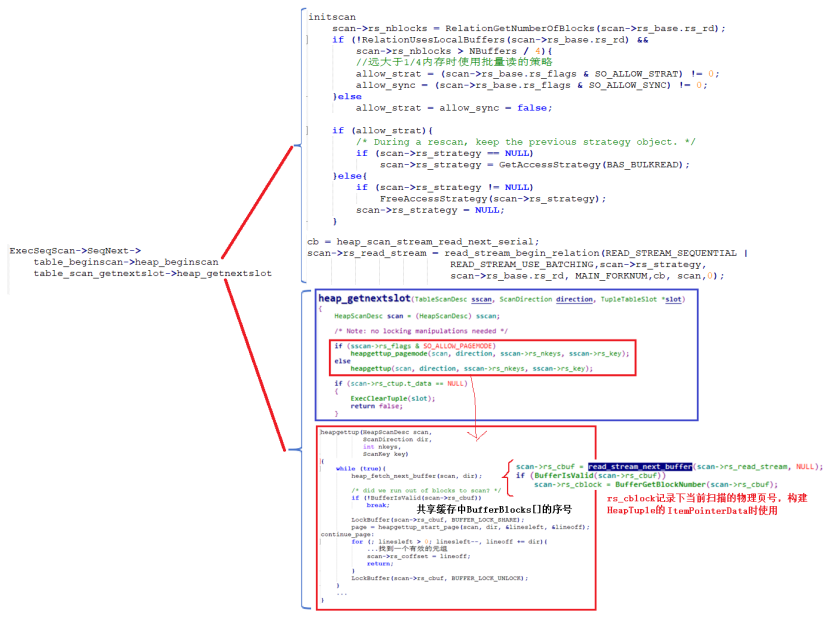
SeqScan算子执行的入口为ExecSeqScan,他会调用SeqNext到存储引擎进行顺序扫描。受现需要进行heap_begin,然后heap_getnextslot从数据页中顺序取元组向用户或者上层算子进行推送。
heap_begin调用initscan完成HeapScanDesc的初始化,这里注意是当物理表的页数大于共享内存的1/4时,就可以开启批量读的策略:BAS_BULKREAD。
然后对于SeqScan来说使用heap_scan_stream_read_next_serial来设置rs_read_stream的回调函数,也就是顺序获取要读的物理页页号,创建并初始化ReadStream结构由函数read_stream_begin_relation完成。
在heap_getnextslot函数中通过heapgettup_pagemode或者heapgettup来获取元组,这里以heapgettup为例,在一个while循环中通过heap_fetch_next_buffer获取一个内存页(将物理页加载到内存),然后在该内存页上依次向上返回元组。heap_fetch_next_buffer返回的是共享缓存BufferBlocks[]数组的序号。更深一层,由read_stream_next_buffer函数进行异步IO,并返回BufferBlocks[]数组的序号。
2.3 read_stream_next_buffer异步读
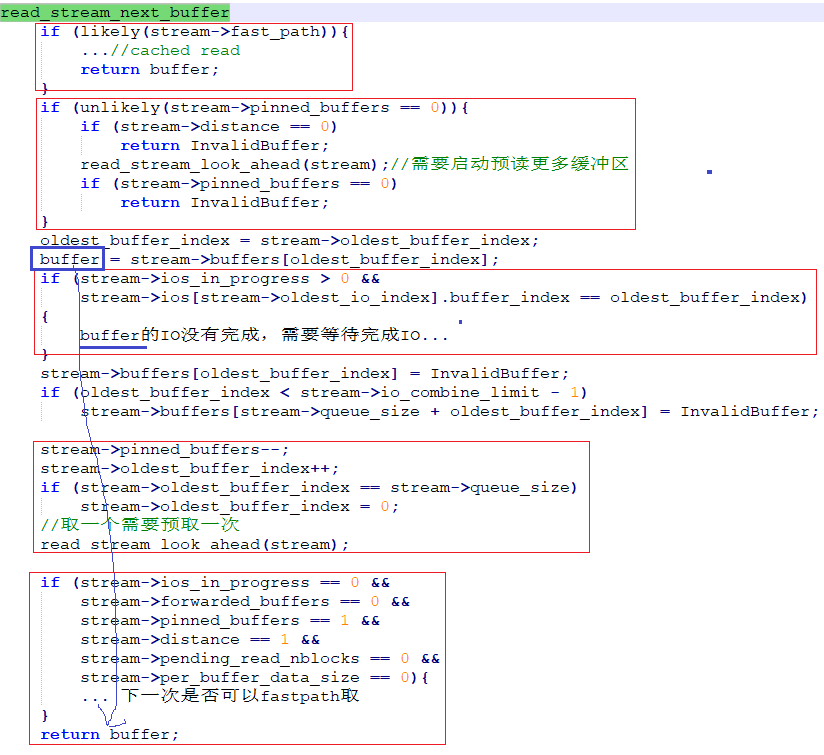
异步读的时候主要依赖于ReadStream结构,该结构中主要通过InProgressIO ios[]和Buffer buffers[]两个循环队列来管理异步IO,其中buffers[]用来管理异步IO可以处理哪些数据页(一批),主要是连续页IO的数据页申请阶段;ios[]用来管理异步IO执行,主要是将buffers[]中的连续IO数据页作为一个IO申请,放到ios[]中进行处理,处于IO执行阶段。
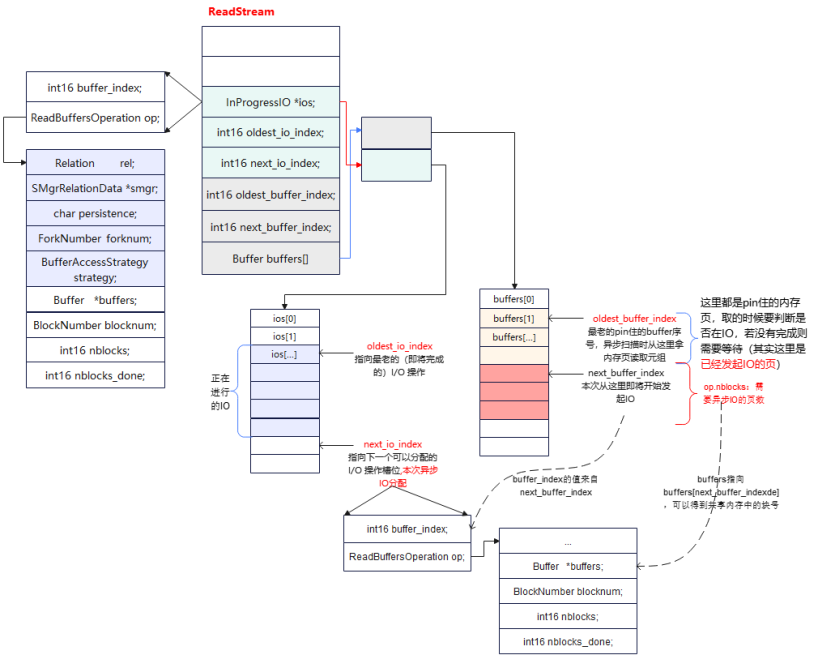
read_stream_next_buffer首先需要看下fast_path,这个分支最后讲。然后stream->pinned_buffers为0时,也就是还没有发起的读IO页,此时需要read_stream_look_ahead进行预读更多数据页(这里时发起异步IO),如果pinned_buffers为0也就是没有数据页可以读,则返回,该函数后面介绍。
从stream->oldest_buffer_index处开始取内存数据页(前面已经发起了一个异步批量IO,已经讲数据页pin住了),ios[oldest_io_index].buffer_index == oldest_buffer_index时表示该页所处的批次IO还未完成,则等待IO完成。这里为什么使用这个条件,而不是检查oldest_io_index到next_io_index之间所有批次IO呢?
1) ReadStream发起的批次IO是一个进程内存独享,不存在并发;
2) 发起一次异步IO - 取一个内存页 - 再发起一次异步IO,以这个顺序执行。取的顺序也是按照oldest_buffer_index向后进行依次推进。ios[].buffer_index也是本次批量IO的开始的序号即next_buffer_index。
3) 如果ios[].buffer_index == oldest_buffer_index,说明该批次IO还没有完成,则需要等待(下图第二中场景)。不相等的场景有三种:(1)如果取得oldest_buffer_index处于oldest_io_index前面,则已经完成IO,不用等待(下图第一种场景);(2)如果是该批次oldest_buffer_index后面的页,走到这里时条件不相等,但是第一个页的等待已经完成该批次所有页的IO了,所以可以不等(下图第三中场景),完成IO后会将olest_io_index向后进行推进;(3)如果ios[oldes_io_index]是取完页后后面发起的IO,说明前面的ios[前面]的IO都已经完成了,所以也可以不等。
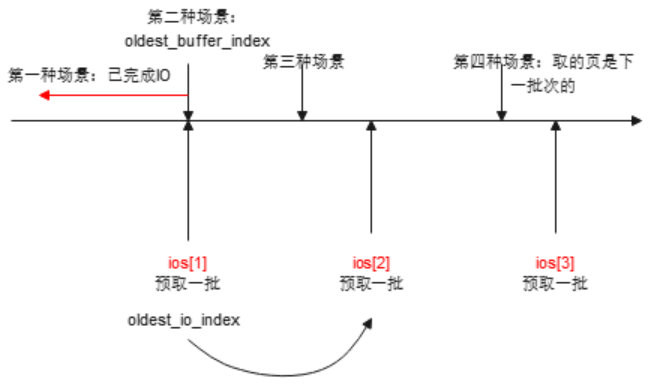
取完页后,pined_buffers--,oldest_buffer_index++向前推进,下次取的时候仍旧从oldest_buffer_index处取。取一次后,需要预取一次。
2.4 read_stream_look_ahead预取批量异步IO
第一次预取或者每消费一个buffer都需要发起新的预取。合并相邻页面的IO请求,在资源限制的范围内尽可能填满IO队列。
1) 目前积攒的 I/O 请求大小已经达到 I/O 合并的最大粒度,那么立刻发起 I/O 请求
2) 目前积攒的 I/O 请求大小尚未达到 I/O 合并的最大粒度,那么通过 read_stream_get_block 确认下一个页面与当前读请求是否相邻
3) pending_read_blocknum本批次第一个块的页号,如果相邻,则可以合并,积攒起来,继续检查下一页。这里不用记录所有页号,只需要记录首页,以及连续页数,就可以得到所有连续页的页号
4) 遇到不相邻的,立即发起IO。不相邻的页作为后续积攒 I/O 请求的第一个页面
5) 如果已经没有更多页面需要访问了,那么立刻发出已积攒的读请求
static void
read_stream_look_ahead(ReadStream *stream)
{
if (stream->batch_mode)
pgaio_enter_batchmode();
while (stream->ios_in_progress < stream->max_ios &&
stream->pinned_buffers + stream->pending_read_nblocks < stream->distance)
{
BlockNumber blocknum;
int16 buffer_index;
void *per_buffer_data;
//目前积攒的 I/O 请求大小已经达到 I/O 合并的最大粒度,那么立刻发起 I/O 请求
if (stream->pending_read_nblocks == stream->io_combine_limit){
read_stream_start_pending_read(stream);
continue;
}
//目前积攒的 I/O 请求大小尚未达到 I/O 合并的最大粒度,
//那么通过 read_stream_get_block 确认下一个页面与当前读请求是否相邻
buffer_index = stream->next_buffer_index + stream->pending_read_nblocks;
if (buffer_index >= stream->queue_size)
buffer_index -= stream->queue_size;
per_buffer_data = get_per_buffer_data(stream, buffer_index);
blocknum = read_stream_get_block(stream, per_buffer_data);
if (blocknum == InvalidBlockNumber){
/* End of stream. */
stream->distance = 0;
break;
}
//pending_read_blocknum本批次第一个块的页号
if (stream->pending_read_nblocks > 0 &&
stream->pending_read_blocknum + stream->pending_read_nblocks == blocknum)
{//相邻,可以合并
stream->pending_read_nblocks++;
continue;//继续查看下一个页面
}
//遇到不相邻的,立即发起IO
while (stream->pending_read_nblocks > 0)
{
if (!read_stream_start_pending_read(stream) ||
stream->ios_in_progress == stream->max_ios)
{
/* We've hit the buffer or I/O limit. Rewind and stop here. */
read_stream_unget_block(stream, blocknum);
if (stream->batch_mode)
pgaio_exit_batchmode();
return;
}
}
//不相邻的页作为后续积攒 I/O 请求的第一个页面
stream->pending_read_blocknum = blocknum;
stream->pending_read_nblocks = 1;
}
//如果已经没有更多页面需要访问了,那么立刻发出已积攒的读请求
if (stream->pending_read_nblocks > 0 &&
(stream->pending_read_nblocks == stream->io_combine_limit ||
(stream->pending_read_nblocks >= stream->distance &&
stream->pinned_buffers == 0) ||
stream->distance == 0) &&
stream->ios_in_progress < stream->max_ios)
read_stream_start_pending_read(stream);
if (stream->batch_mode)
pgaio_exit_batchmode();
}2.5 read_stream_start_pending_read发起预取批量异步IO
发起IO请求,将本次 I/O 需要 pin 住的 Buffer 记录到 Buffer 队列中,buffers[next_io_index]开始记录pin住的Buffer,nblocks为本次IO发起的页数,将本次IO放到ios[next_io_index]中。
read_stream_start_pending_read(ReadStream *stream)
{
...
nblocks = stream->pending_read_nblocks;
...
buffer_index = stream->next_buffer_index;
io_index = stream->next_io_index;
while (stream->initialized_buffers < buffer_index + nblocks)
stream->buffers[stream->initialized_buffers++] = InvalidBuffer;
requested_nblocks = nblocks;
/*
* 发起IO请求,将本次 I/O 需要 pin 住的 Buffer 记录到 Buffer 队列中
* buffers[next_io_index]开始记录pin住的Buffer
* nblocks为本次IO发起的页数
* 将本次IO放到ios[next_io_index]中
*/
need_wait = StartReadBuffers(&stream->ios[io_index].op,
&stream->buffers[buffer_index],
stream->pending_read_blocknum,
&nblocks,
flags);
stream->pinned_buffers += nblocks;
/* Remember whether we need to wait before returning this buffer. */
if (!need_wait){
//不需要异步IO,Buffer 命中 Buffer Pool,则控制好预读窗口
if (stream->distance > 1)
stream->distance--;
}
else{//将 I/O 请求记录到 I/O 队列中
stream->ios[io_index].buffer_index = buffer_index;
if (++stream->next_io_index == stream->max_ios)
stream->next_io_index = 0;
stream->ios_in_progress++;
stream->seq_blocknum = stream->pending_read_blocknum + nblocks;
}
...
//推进next_buffer_index
buffer_index += nblocks;
if (buffer_index >= stream->queue_size)
buffer_index -= stream->queue_size;
stream->next_buffer_index = buffer_index;
//推动下次IO的起使页号,发起了IO后,将本次流的未发起的IO页数恢复
stream->pending_read_blocknum += nblocks;
stream->pending_read_nblocks -= nblocks;
return true;
}