





OpenPose人体姿态识别项目是美国卡耐基梅隆大学(CMU)基于卷积神经网络和监督学习并以caffe为框架开发的开源库。
可以实现人体动作、面部表情、手指运动等姿态估计。适用于单人和多人,具有极好的鲁棒性。是世界上首个基于深度学习的实时多人二维姿态估计应用,基于它的实例如雨后春笋般涌现。
人体姿态估计技术在体育健身、动作采集、3D试衣、舆情监测等领域具有广阔的应用前景,人们更加熟悉的应用就是抖音尬舞机。
OpenPose项目Github链接:https://github.com/CMU-Perceptual-Computing-Lab/openpose
要做为线上服务,性能估算是重要的环节,做一个简单的分析和测试。首先大致了解openpose的源码封装。
1. 默认开启多线程
// Implementation#include <openpose/wrapper/wrapperAuxiliary.hpp>namespace op{template<typename TDatum, typename TDatums, typename TDatumsSP, typename TWorker>WrapperT<TDatum, TDatums, TDatumsSP, TWorker>::WrapperT(const ThreadManagerMode threadManagerMode) :mThreadManagerMode{threadManagerMode},mThreadManager{threadManagerMode},mMultiThreadEnabled{true}{}...}
2. demo的初始化出于顺序处理、调试或者减少时延,会根据编译宏禁用,注释掉这段。
op::Wrapper opWrapper{op::ThreadManagerMode::Asynchronous};// Set to single-thread (for sequential processing and/or debugging and/or reducing latency)if (FLAGS_disable_multi_thread)opWrapper.disableMultiThreading();
3. 多线程队列,可能导致内存问题,猜测图片加载和相关处理的数据结构。从实测看,暂时看不出内存的变化,还需要加大测试量找到最佳值,在应用进程侧控制队列和线程数。
/*** It sets the maximum number of elements in the queue.* For maximum speed, set to a very large number, but the trade-off would be:* - Latency will hugely increase.* - The program might go out of RAM memory (so the computer might freeze).* For minimum latency while keeping an optimal speed, set to -1, that will automatically* detect the ideal number based on how many elements are connected to that queue.* @param defaultMaxSizeQueues long long element with the maximum number of elements on the queue.*/void setDefaultMaxSizeQueues(const long long defaultMaxSizeQueues = -1);
4. 关于队列,运行时直接获取队列扔进去,等待线程队列有空闲后,进行处理。
template<typename TDatums, typename TWorker, typename TQueue>bool ThreadManager<TDatums, TWorker, TQueue>::waitAndEmplace(TDatums& tDatums){try{if (mThreadManagerMode != ThreadManagerMode::Asynchronous&& mThreadManagerMode != ThreadManagerMode::AsynchronousIn)error("Not available for this ThreadManagerMode.", __LINE__, __FUNCTION__, __FILE__);if (mTQueues.empty())error("ThreadManager already stopped or not started yet.", __LINE__, __FUNCTION__, __FILE__);return mTQueues[0]->waitAndEmplace(tDatums);}catch (const std::exception& e){error(e.what(), __LINE__, __FUNCTION__, __FILE__);return false;}}template<typename TDatums, typename TQueue>bool QueueBase<TDatums, TQueue>::waitAndEmplace(TDatums& tDatums){try{std::unique_lock<std::mutex> lock{mMutex};mConditionVariable.wait(lock, [this]{return mTQueue.size() < getMaxSize() || mPushIsStopped; });return emplace(tDatums);}catch (const std::exception& e){error(e.what(), __LINE__, __FUNCTION__, __FILE__);return false;}}
读完代码做一个测试
// 预先建立好100张图片,并发提交处理func main() {C.initPose()path := "/yogadata/image/"suffix := ".jpeg"var wg sync.WaitGroup// 初始化大概会消耗2s的时间,排除掉这部分的影响time.Sleep(time.Duration(20) * time.Second)t1 := time.Now()for i := 1; i <= 100; i++ {num := strconv.Itoa(i)img := path + num + suffixwg.Add(1)go func(img string, n int) {defer wg.Done()imgc := C.CString(img)ret := C.getVoiceId(imgc, 0)fmt.Print("num:", n, "ret:", ret, "\n")}(img, i)}wg.Wait()t2 := time.Now()fmt.Println(t2.Sub(t1))}
初始化后内存占用如下图,如果没有加载模型,库占用比较小。

加载模型后,占用变大,但仍没有达到demo交付的大小。模型解析后大约占用1.2G。

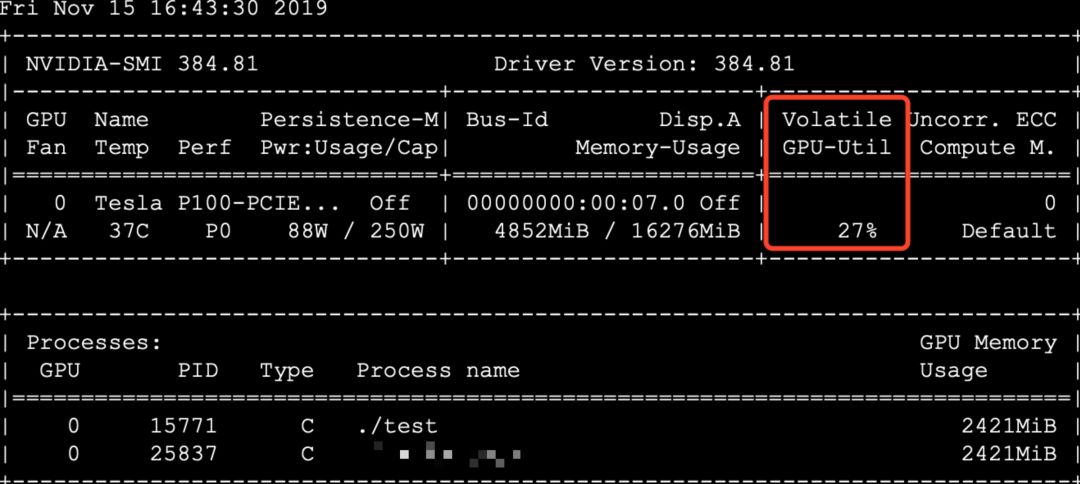
运行期间,内存占用同demo,运行期的内容占用约870M,多线程满负荷占用GPU 70% ~ 72%,跑不满。
分析日志
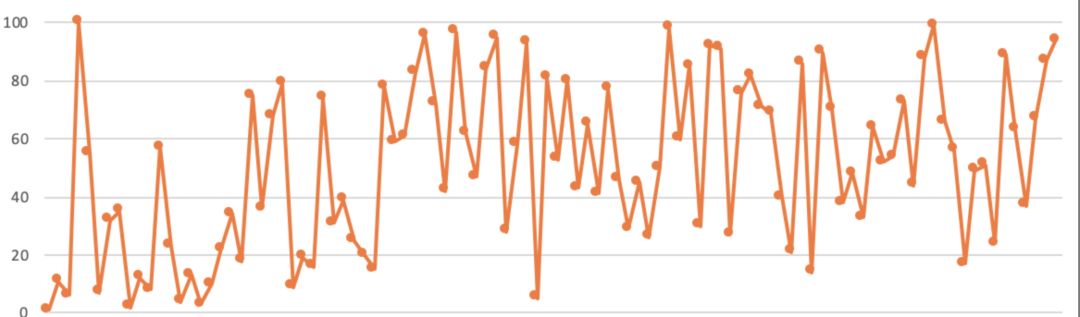
1. 下图纵轴为图片id,横轴为输出时间。可见多线程是并行随机处理的,较晚的图片也可能较早完成处理,较早的图片可能延迟比较高。
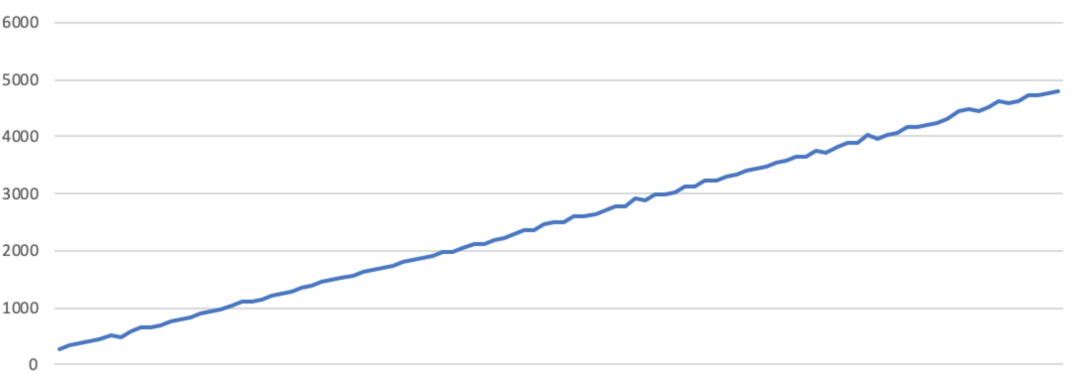
2. 下图为时延曲线,可以看到是线性增长的。最低200ms左右,100张的最后一张时延高达近5s。
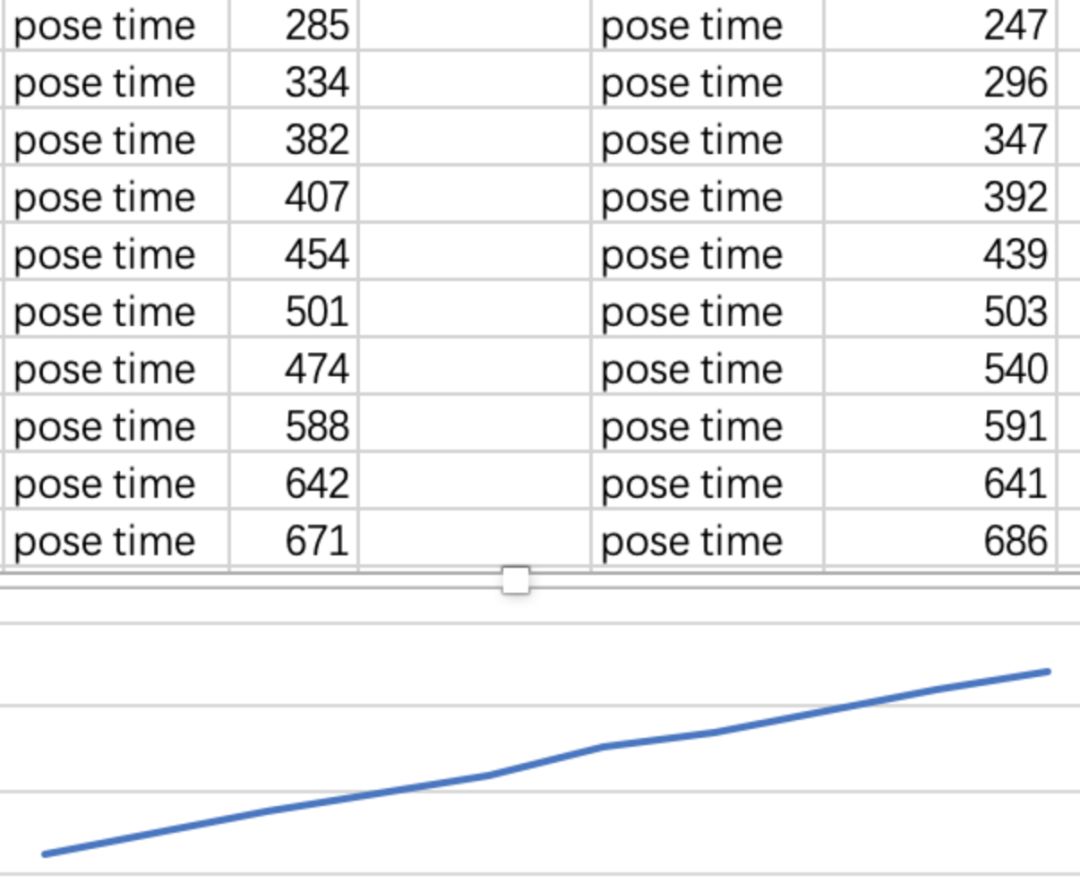
3. 将测试集缩小为10张,和100张的测试集没有变化,延迟是稳定的线性增长,处理结果的时延也相当。但CPU约为30%上下,没有跑满。
综上,多线程的时延在大并发的情况下不尽人意,多进程处理会受到GPU内存的限制,需要在这两者间做均衡。
拖地先生,从事互联网技术工作,在这里每周两篇文章,一起聊聊日常的技术点滴和管理心得。

如果对你有帮助,让大家也看看呗~
