




某版本上线客户端广播推送采用新的第三方推送,三天后新任务配置,在广播触发的时间节点,应用出现dubbo线程池满的告警。
定位是新厂商回执导致的问题后,暂停新上线的广播任务,让运维同学dump线上环境,重启应用后恢复,后续通过性能环境的复现和对dump文件的分析发现如下问题:
问题时间节点回执队列大量积压,内存占用过高:新的推送厂家在广播触发的时间节点会产生大量的回执请求,短时间大批量回执请求充斥内存回执队列(线程池处理的无界队列,防止任何一个回执请求被丢弃),占用大量内存系统宕机
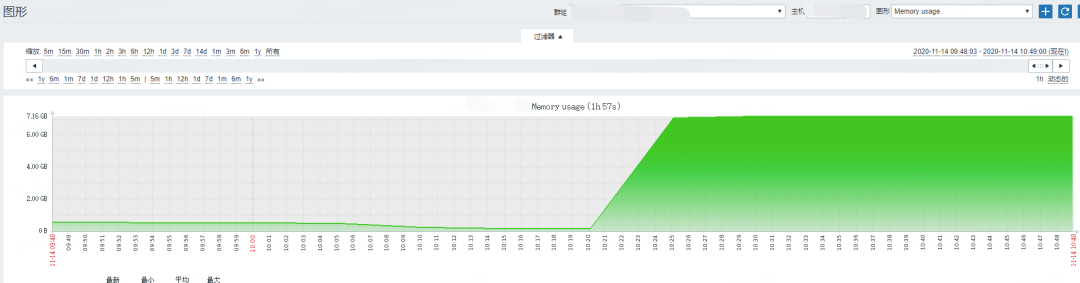
客户端首页改造后,会触发消息列表查询接口(queryMyNews)用于落表推送的消息,广播触发的时间节点触发大批量queryMyNews的接口,然后dubbo线程池打满,dubbo服务处于不可用的状态
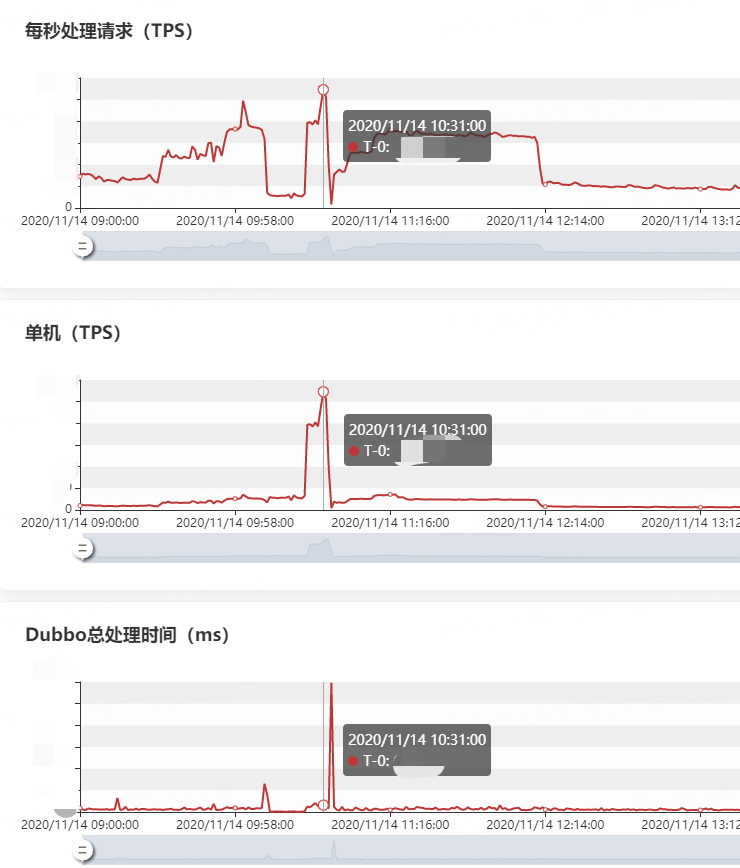
第一个问题很容易解决,关停厂商的广播回执推送能力后,内存就正常了。
第二个问题性能环境有复现,和DBA确认数据库和redis在问题时间节点未有慢查询的问题,dump文件分析后也都无法准确的判断根本原因。
查看Dubbo_JStack.log日志后发现一些端倪,压测1-3分钟后,全部dubbo线程waiting。
waiting on java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject@2a458df0
如下图 500个dubbo线程都堵死在从redis中获取连接这一步
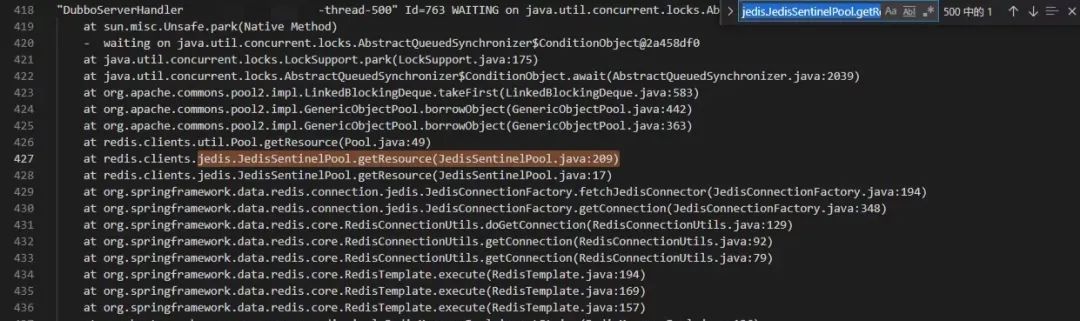
线上当时redis连接池最大连接数为60,可能无法满足异常期间的应用需求量。但是为什么没有看到相关报错信息呢?
遇事不先百度,毕竟这么大的人口基数在这里,总有人和我遇到同样的问题,(https://blog.csdn.net/u013887008/article/details/83825358)
咨询后发现如下问题JedisPool.java
中有一段代码
if (p == null) {if (borrowMaxWaitMillis < 0) {p = idleObjects.takeFirst();} else {p = idleObjects.pollFirst(borrowMaxWaitMillis,TimeUnit.MILLISECONDS);}}
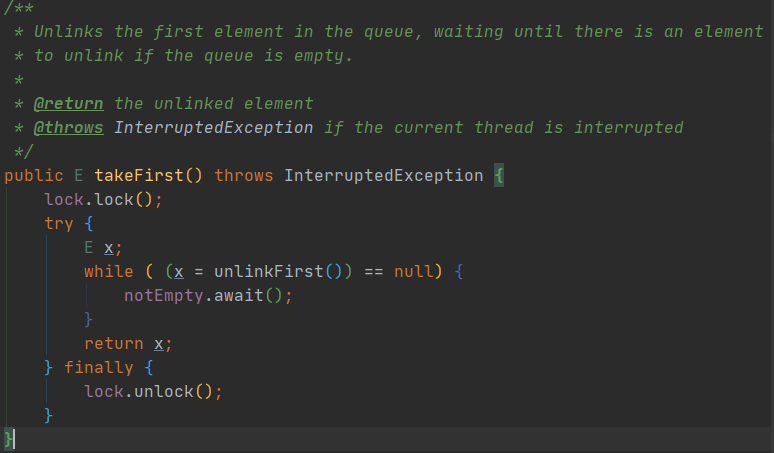
当“borrowMaxWaitMillis ”小于零时,如果从pool中获获取连接超时后会一直阻塞。
查看redis的相关配置
<!-- Jedis 连接池配置--><bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"><property name="minIdle" value="5"/><property name="maxIdle" value="50" /><property name="maxTotal" value="60"/><property name="testOnBorrow" value="false" /><property name="testOnReturn" value="false"/><property name="testWhileIdle" value="true"/></bean>
确实未配置maxWaitMillis
(默认是-1,表示如果从jedispool中获取jedis超时后会一直阻塞;而将maxWaitMillis
设置成一个正数,表示在规定时间超时后会抛出异常)。
配置该值后,再次进行压测。
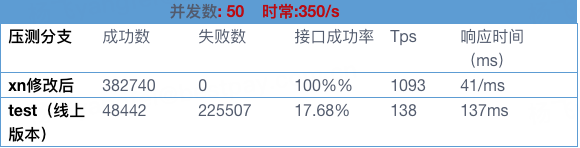
ps:maxWaitMillis
和maxTotal
并没有一个规定的或者公式可推导的建议值,具体值需要和业务场景强相关,具体合适的值需要结合应用场景大量压测来取舍一个成功率和tps都相对较高的值。
经过该次问题,总结出几点经验教训
应用需要合理拆分,防止一个业务场景而导致整个系统能力不可用
中间件,数据库的相关配置需要紧跟公司规定,需要配置的值都需要去配置尽量不适用默认值
业务分析时,要确认清楚接口所有的触发场景,确保场景不冗余,减少对底层应用的重复调用
高危大流量接口需要有限流操作,在保障业务正常的情况下,需要有相关的防护机制
拖地先生,从事互联网技术工作,在这里每周两篇文章,聊聊日常的实践和心得。往期推荐:
如果对你有帮助,让大家也看看呗~
