




📢📢📢📣📣📣
作者:IT邦德
中国DBA联盟(ACDU)成员,15年DBA工作经验
Oracle、PostgreSQL ACE
CSDN博客专家及B站知名UP主,全网粉丝15万+
擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复,
安装迁移,性能优化、故障应急处理
文章目录
PostgreSQL 18 的发布确实带来了不少令人兴奋的改进,主要集中在性能、开发灵活性和数据管理等方面,接下来就帮你们解读下。

1.异步 I/O
PostgreSQL 此前依赖操作系统的预读机制来加速数据检索。然而,操作系统无法感知数据库特有的访问模式,难以准确预测所需数据,导致在许多工作负载场景下性能欠佳。同步 IO(如read/write)会阻塞进程,导致 CPU 利用率低,无法充分利用硬件资源。
PostgreSQL 18 引入了新的异步 I/O (AIO) 子系统来解决这一局限。AIO 允许 PostgreSQL 并发地发出多个 I/O 请求,而不是等待每个请求顺序完成,从而增强了现有的预读能力并提高整体吞吐量。PostgreSQL 18 支持的 AIO 操作包括顺序扫描、位图堆扫描和清理(VACUUM),基准测试显示,在某些场景下性能提升高达 3 倍。
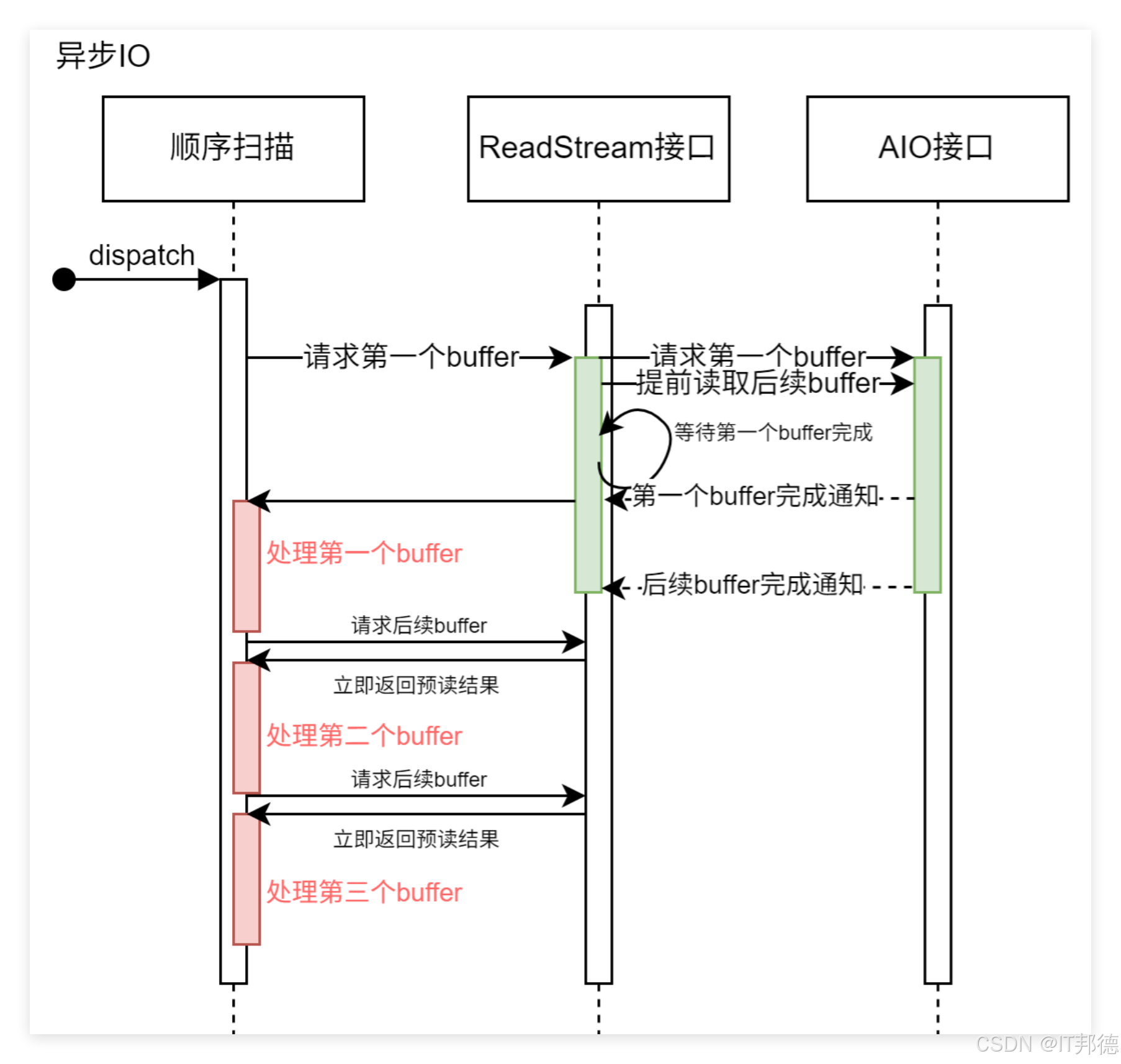
用户可选择三种不同的 io_method 启用异步 I/O,分别是:
1.worker 若干后台 I/O workers 接收处理后端进程的 I/O 请求。
2.io_uring Linux 系统中 io_uring 子系统通过操作系统内核线程处理 PG 的 I/O 请求。
3.sync 满足异步 I/O 框架接口要求的同步 I/O。
其中每个进程能够拥有的最大异步 I/O 句柄为 io_max_concurrency,
用户可以将其置 -1,使数据库自行选择合适的值。
启动数据库后,用户可通过 pg_aios 视图实时地获取当前系统异步 I/O 执行状况
postgres=# select * from pg_aios;
2.查询性能
PostgreSQL 18 通过一系列能自动提升工作负载速度的功能,进一步提升了查询性能。此版本引入了对多列 B-tree 索引上的“跳跃扫描”查找,可缩短在查询中省略一个或多个前缀索引列等值(=)条件时的执行时间。它还可以优化 WHERE 子句中使用 OR 条件的查询,使其有效利用索引,大幅提升执行速度。此外,PostgreSQL 对表连接的执行计划和处理进行了多项改进,包括提升哈希连接性能、允许合并连接使用增量排序等。PostgreSQL 18 还支持GIN 索引的并行构建,与 B-tree 和BRIN 索引索引一样具备该能力。
该版本还进一步增强了 PostgreSQL 对硬件加速的支持,包括为 popcount 函数添加对 ARM NEON 和 SVE CPU 内置指令集的支持,该函数被bit_count和其他内部功能使用。
CREATE INDEX idx_t1_c1c2 ON t1(c1, c2);

PostgreSQL 18 执行计划选择使用索引扫描,可以看出跳跃式扫描执行效率提升幅度非常大
3.升级性能跃升
PostgreSQL 的一项关键特性是生成并存储统计信息,有助于 PostgreSQL 选择最优的查询计划。在 PostgreSQL 18 之前,这些统计信息无法在主版本升级过程中保留,导致高负载系统在ANALYZE完成前查询性能骤降。PostgreSQL 18 引入了在主版本升级时保留规划器统计信息的能力,这有助于升级后的集群更快地达到预期性能。
此外,主版本升级工具pg_upgrade在 PostgreSQL 18 中迎来多项增强,例如当数据库包含大量表和序列等对象时,升级速度显著提升。此版本还支持通过 --jobs 参数配置并行检查,并新增了 --swap 参数,通过直接交换升级目录的方式替代原有的复制、克隆或链接文件操作。
1.在PostgreSQL18 中,pg_upgrade工具被增强, 默认情况下会自动将旧集群中的 pg_statistic系统目录数据迁移到新集群 pg_upgrade -b /old/bin -B /new/bin -d /old/data -D /new/data 除非你明确使用 --no-statistics参数,否则统计信息保留功能会自动生效 2.为了确保查询优化器拥有最完整的信息,建议在升级完成后, 对缺少扩展统计信息的表执行针对性的 ANALYZE vacuumdb --all --analyze-in-stages --missing-stats-only 这条命令会只针对那些缺少扩展统计信息的表进行分析,而不是全库分析, 从而大大缩短了补充统计信息所需的时间
4.开发者体验
4.1 虚拟生成列
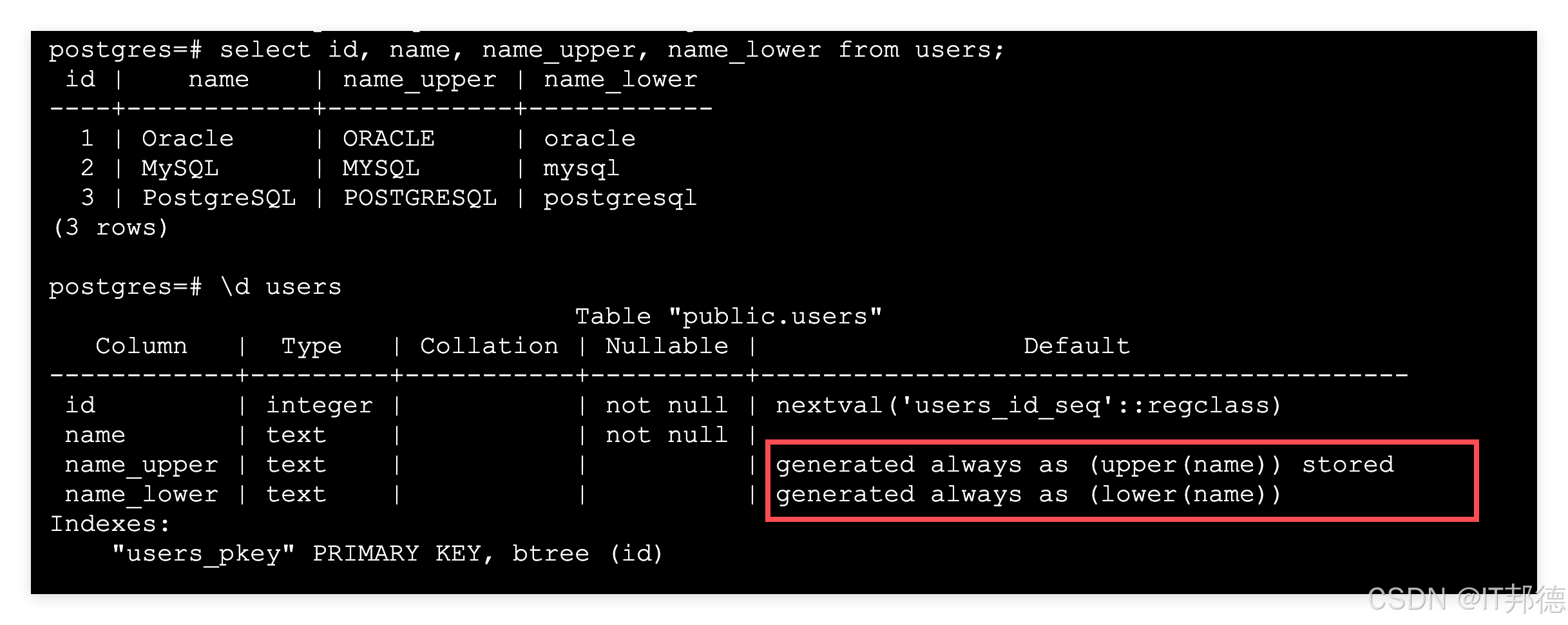
PostgreSQL 18 引入了虚拟生成列,其数值在查询时实时计算而非直接存储,现已成为生成列的默认选项。此外,存储型生成列现已支持逻辑复制。
生成列是那些可以免去编写大量样板代码、简化工作的功能之一,生成的列有两种形式存储列(stored)和虚拟列(virtual) 。
存储(stored)生成列在插入/更新时仅计算一次,并持久化到磁盘(占用存储空间)。之后,它们可以像“真实”列一样被索引。对于不想每次都重新计算的昂贵表达式,它们非常适用。
虚拟(virtual)生成列(PG 18 中的新功能!)不存储在磁盘上。它们在查询时动态计算。它们非常适合轻量级表达式或不希望表膨胀的情况。
4.2 UUID 功能增强
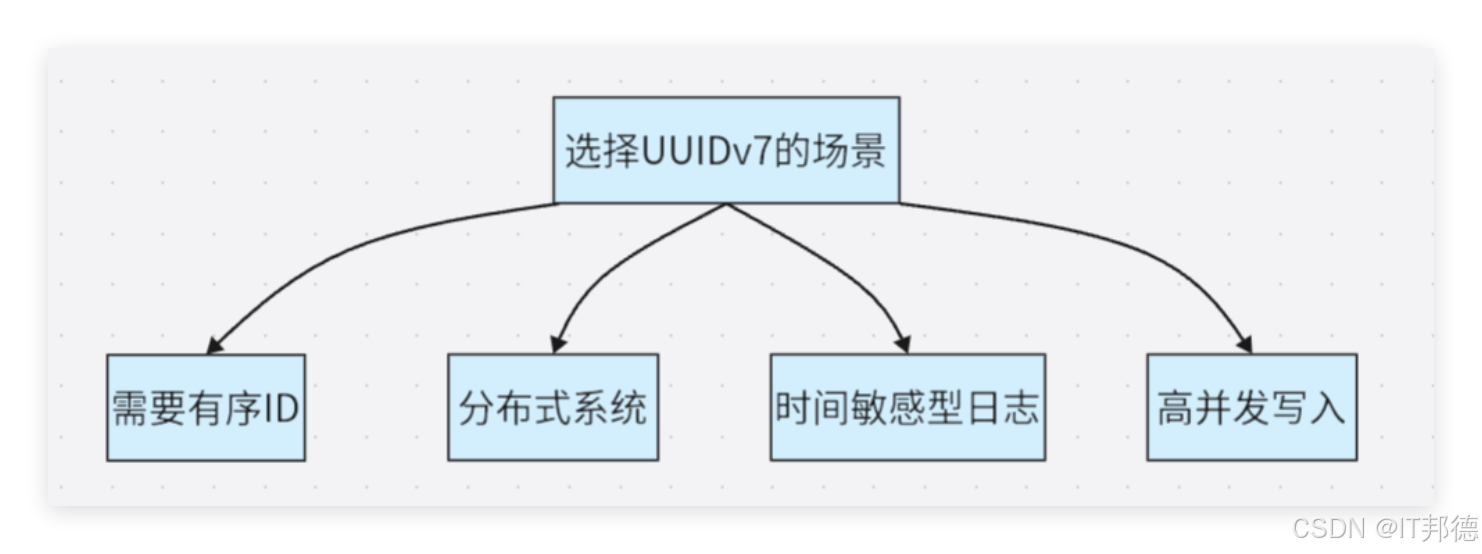
PostgreSQL 18 还通过uuidv7()函数新增了 UUIDv7 生成功能,可生成按时间戳排序的随机 UUID,有助于优化缓存策略。uuidv4()也作为 gen_random_uuid() 的别名被引入PostgreSQL 18中。
UUIDv7 的时间戳顺序能显著减少页分裂和缓存失效,有效提升 B 树索引效率。
UUIDv7 自带时间排序,大部分场景下显著提升排序性能。
4.3 时态约束
PostgreSQL 18 新增了对时间范围约束的支持:通过 WITHOUT OVERLAPS 子句,可在主键(PRIMARY KEY)和唯一(UNIQUE)约束中定义不重叠的范围;通过 PERIOD 子句,可为外键(FOREIGN KEY)约束定义时间区间关系。
4.4 快速创建外部表
PostgreSQL 18 引入了CREATE FOREIGN TABLE … LIKE命令,可依据本地表的定义更便捷地创建外部表的模式结构。
以下语句将创建一个与 local_employees结构完全一致的外部表
-- 关键步骤:基于本地表结构创建外部表
CREATE FOREIGN TABLE foreign_employees (
LIKE local_employees INCLUDING ALL
-- INCLUDING ALL 复制所有列定义及约束(如NOT NULL)
)
SERVER remote_server
OPTIONS (
schema_name 'public',
table_name 'remote_employees_table'
-- 指定远程服务器上的实际表名
);
完成上述步骤后,你就可以像查询普通表一样查询 foreign_employees,
而 PostgreSQL 会在后台从远程数据库的 remote_employees_table表中获取数据
4.5 RETURNING 子句增强
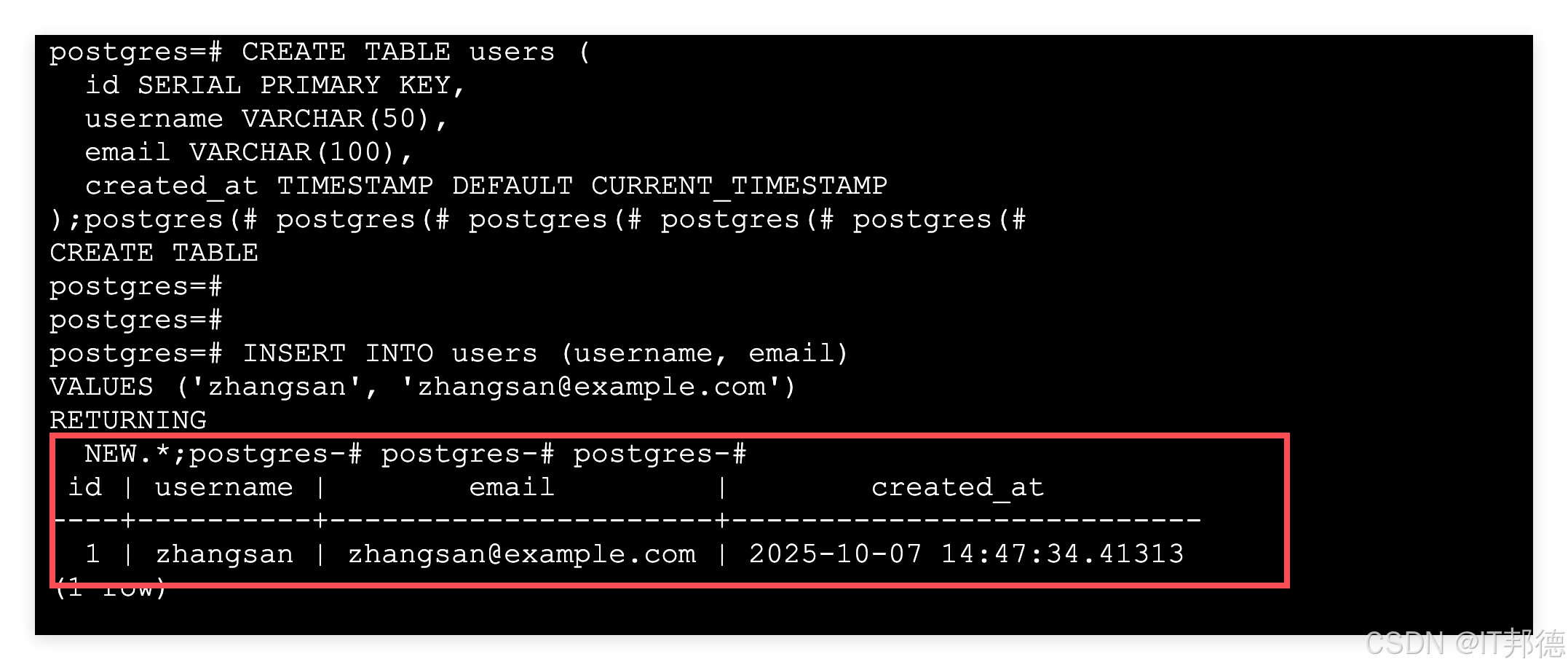
PostgreSQL 18 版本新增了在RETURNING 子句中同时访问修改前(OLD)与当前(NEW)数值的能力,适用于 INSERT、UPDATE、DELETE 和 MERGE 命令
5.文本处理增强
PostgreSQL 18 通过多项新特性使文本处理更简单、更快速。此版本新增了PG_UNICODE_FAST排序规则,该规则在提供完整的Unicode大小写转换语义的同时,显著提升了多种比较操作的性能,涵盖 upper 和 lower 字符串比较函数,以及用于大小写不敏感比较的新casefold函数。
下表展示了在相同数据量和硬件环境下,两种排序规则处理上述查询的简要性能对比

此外,PostgreSQL 18 现在支持对使用非确定性排序规则的文本进行 LIKE 比较,简化了复杂模式匹配的实现。本版本还调整了全文检索的实现机制,使其采用数据库集群的默认排序提供程序,而非始终依赖 libc,这一变化可能导致在运行pg_upgrade后,需要为所有全文检索及pg_trgm索引执行重建操作。
6.复制
PostgreSQL 18 支持在日志和pg_stat_subscription_stats视图中报告逻辑复制写入冲突。此外,CREATE SUBSCRIPTION现默认使用并行流式方式来应用事务,有助于提升复制性能。pg_createsubscriber工具新增了 --all 参数,可以通过一条命令为实例中的所有数据库创建逻辑副本。 PostgreSQL 18 持自动删除空闲复制槽,避免在发布服务器上积压过多WAL日志。
1.CREATE SUBSCRIPTION命令现在默认启用并行流式传输
-- 在PostgreSQL 18中创建订阅,默认即采用并行流式方式
CREATE SUBSCRIPTION my_subscription
CONNECTION 'host=192.168.1.100 port=5432 dbname=source_db user=repuser'
PUBLICATION my_publication;
2.一键为所有数据库创建逻辑副本
pg_createsubscriber工具新增了 --all参数,
可以通过一条命令为PostgreSQL实例中的所有数据库创建逻辑副本,极大简化了操作
pg_createsubscriber --all --source-host=192.168.1.100 --target-host=192.168.1.101 --user=repuser
3.自动删除空闲复制槽
PostgreSQL 18 支持自动检测并删除那些长时间处于非活动状态的复制槽,
从而有效防止WAL日志的无限制增长
可以在 postgresql.conf中设置 max_slot_wal_keep_size
参数来控制为复制槽保留的WAL日志的最大体积,
或者设置 slot_timeout参数来定义复制槽的最大空闲时间,超时后可能被自动清理
7.维护与可观测性
7.1 vacuum策略
PostgreSQL 18 改进了vacuum策略,通过在常规 vacuum 期间主动冻结更多页面来减少开销,并在需要激进清理的情况下提供了帮助。
7.2 EXPLAIN 增强
PostgreSQL 18 对 EXPLAIN 命令进行了重大升级,通过提供更丰富、更直观的执行计划信息,让数据库开发者和 DBA 能够更加轻松地进行查询性能分析与优化。
PostgreSQL 18 为EXPLAIN命令提供了更详细的执行信息,自此版本起,在执行 EXPLAIN ANALYZE 时会自动显示访问的缓冲区数量(数据存储的基本单位)。此外,EXPLAIN ANALYZE 现在会显示索引扫描期间发生的索引查找次数,而 EXPLAIN ANALYZE VERBOSE 则会包含 CPU、WAL 和平均读取统计信息。
EXPLAIN ANALYZE 现在默认包含 BUFFER 统计信息,无需手动添加 BUFFERS 选项: 1.共享命中(Shared Hits):显示从缓存中读取的数据块数量,反映内存使用效率。 2.共享读取(Shared Reads):标识必须从磁盘读取的数据块,帮助识别 I/O 瓶颈。 3.共享脏块(Shared Dirtied):针对数据修改操作,显示被更改的块数量。
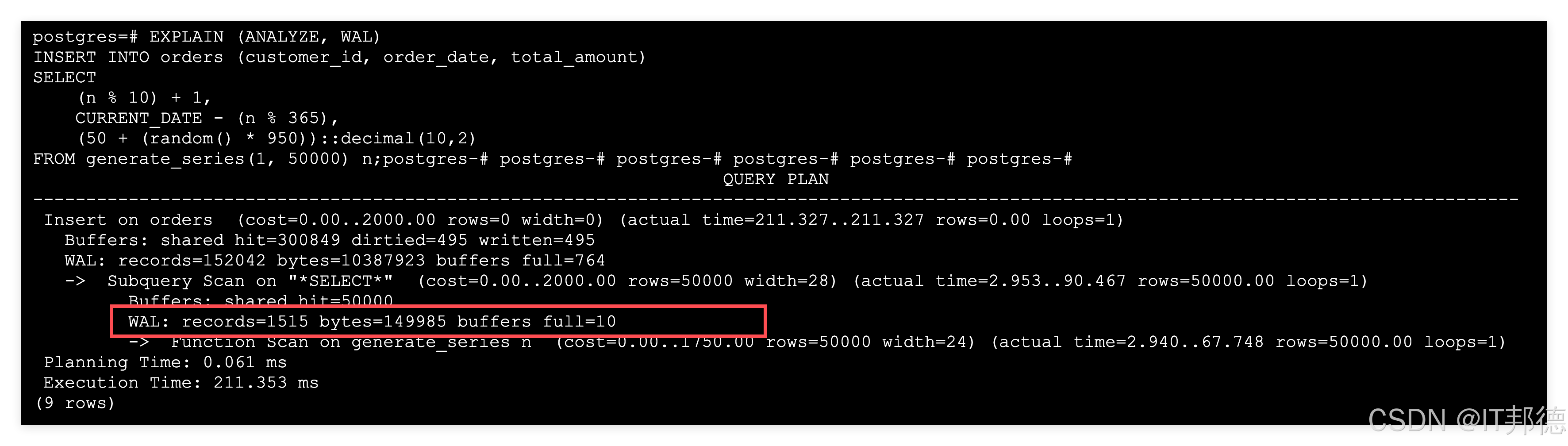
PostgreSQL 18 还在pg_stat_all_tables视图增加了有关 VACUUM 及相关操作耗时统计,以及按连接统计的 I/O 和 WAL 使用情况数据。
8.OAuth 2.0 认证
提升身份管理的灵活性与安全性,降低操作复杂性。同时,MD5密码认证被弃用,建议迁移至更安全的SCRAM认证.
而这次 PostgreSQL18 在身份认证方面继续加强,引入对 OAuth 2 的支持。这是一种开放标准的授权协议,用于授权一个应用程序或服务访问用户在另一个应用程序中的资源,而无需提供用户名和密码。
配置于 pg_hba.conf,配合 oauth_validator_libraries 加载令牌验证库,提升身份认证的灵活性与安全性。
local all test oauth issuer="http://127.0.0.1:9000" scope="openid postgre"
总结
PostgreSQL是世界上最先进的开源数据库,拥有一个数以千计的用户、贡献者、公司和组织组成的全球社区。PostgreSQL起源于加利福尼亚大学伯克利分校,已经有超过40年的历史,并且以无与伦比的速度持续发展。PostgreSQL成熟的特性不仅与顶尖商业数据库系统相媲美,而且在高级数据库功能、可扩展性、安全性和稳定性方面超越了它们。
