




(全文约3500字,预计阅读时间20分钟)
从HTAP这个概念提出至今也已经过了6年时间了。在这6年时间里,概念落地的过程中雨后春笋般出现了诸多的架构和产品组件。随着大数据技术的发展,HTAP逐渐变成了取代lambda架构的数据处理标准架构,本文主要探讨一下HTAP架构内涵,最后会给出两种具有代表性的平台架构
HTAP起源
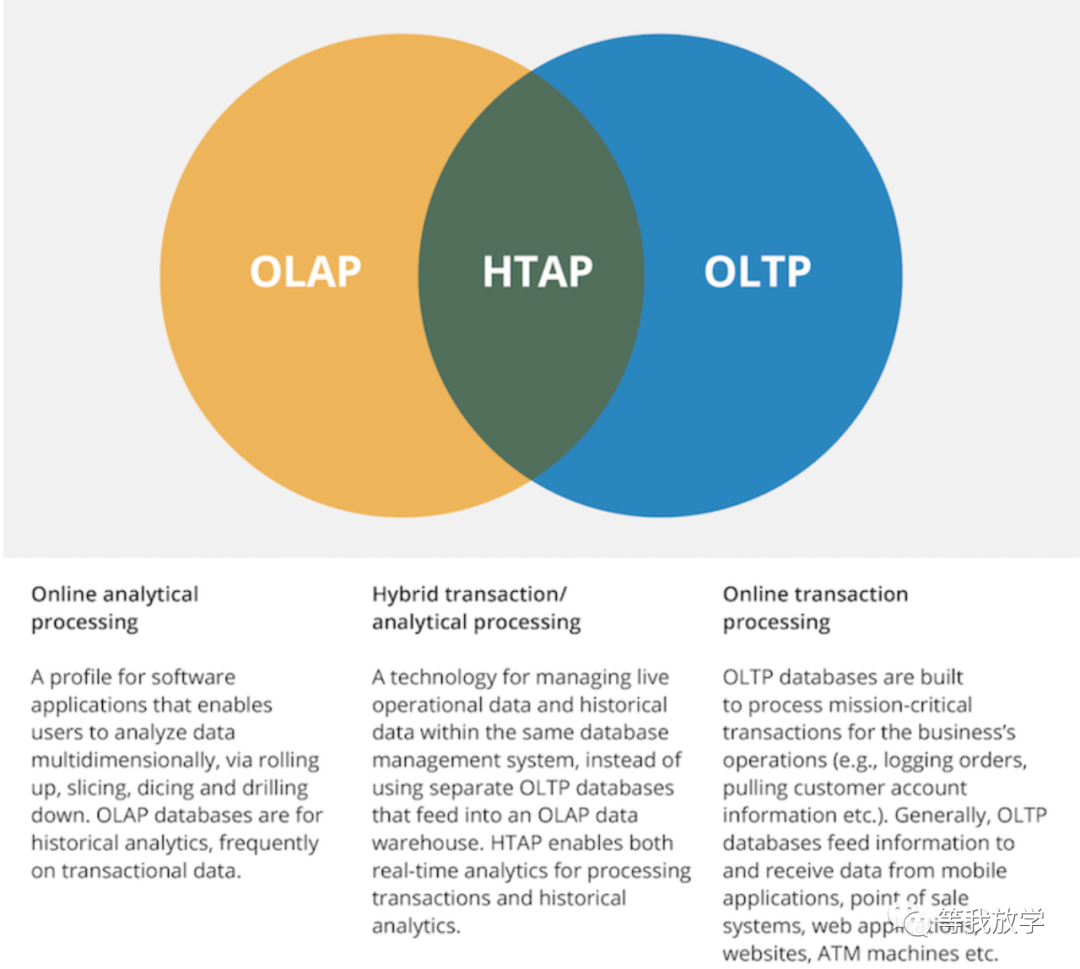
在数据处理领域,根据数据的使用特征,往往被划分成两种数据处理类型:OLTP(On-Line Transaction Processing)及OLAP(On-Line Analytical Processing)。
OLTP是事件驱动、面向应用的数据处理,常用于交易,比如银行的核心交易系统、电商的订单交易平台等。这类数据处理模式往往是数据的产生方。OLTP类系统每次处理的数据量较小,但对数据处理的响应时间要求较高;用户往往是客户或者操作员,用户基数大;映射到数据库中大多需要基于索引进行处理。
OLAP是管理驱动、面向信息分析的数据处理,常用于决策支持,比如数据仓库、报表系统等。这类数据处理模式本身不产生数据,而是以OLTP类的系统产生的操作数据作为数据源。OLAP类系统处理的数据量较大,经常进行一些复杂查询、多表关联、全表扫描等,响应时间往往根据查询数据量决定;用户一般是企业内部的业务人员或者管理员,用户数较少。
随着业务的发展,单纯的OLTP和OLAP架构越来越难满足大型企业对于数据处理的需要。举一个银行业务的场景,某个客户资产达到了私人银行客户级别,此时银行的服务需要针对该客户整体升级,比如理财销售的专属收益率、信用卡等级和额度匹配、信贷利率等。但受制于数据实效性和数 据规模,客户等级提升和专属服务升级往往是比客户资产达标更加滞后的。映射到数据处理领域,就是OLTP系统的数据吞吐量不足,OLAP系统的数据响应能力不够。基于这种情况,HTAP架构被提出。
HTAP(Hybird transaction/analytical processing,混合事务和分析处理)架构的提出源自Gartner2014年的一篇文章,文章认为HTAP使用内存计算技术作为其核心架构,可以提高业务的态势感知能力,并通过改进业务的敏捷性进行创新。简单来说,HTAP打破了OLAP和OLTP的隔阂,既可以运用于事务型场景,也可以运用于分析型场景,实时实现业务决策。
HTAP架构简介
HTAP作为混合式的数据处理框架,有显而易见的优势:减少了许多繁琐的ETL工作,并且让决策人员可以更快地进行数据分析。基于此,HTAP架构需要同时具备OLAP和OLTP的一些特征,比如:
底层数据的快速复制和高并发的实时更新
可以针对海量数据进行扩容,在存储和计算上都具有线性扩展能力
同时满足事务型和分析型的数据处理需求
为了满足以上特性,HTAP架构在数据存储、数据分布、数据计算上都有独特的设计,主要涉及了MPP存储、混合列式读写、增量快照更新等。
MPP存储
HTAP对海量数据的分析要求其数据存储必须建立在线性扩展的基础上。目前较流行的线性扩展的数据存储架构有两类:Sharding和MPP。sharding的核心思想是把一个数据库拆分到多个库中,从而缓解单一数据库的性能问题,一般做法是按表做垂直拆分或者按数据id做水平拆分,数据库之间相对独立,数据的merge、join等操作由中间件执行。MPP(Massively Parallel Processing)架构是一种较成熟的数据存储架构。区别于Sharding技术,笔者认为MPP的核心特点是每个数据节点之前均可以相互通信,协同计算,两种架构图如下所示:
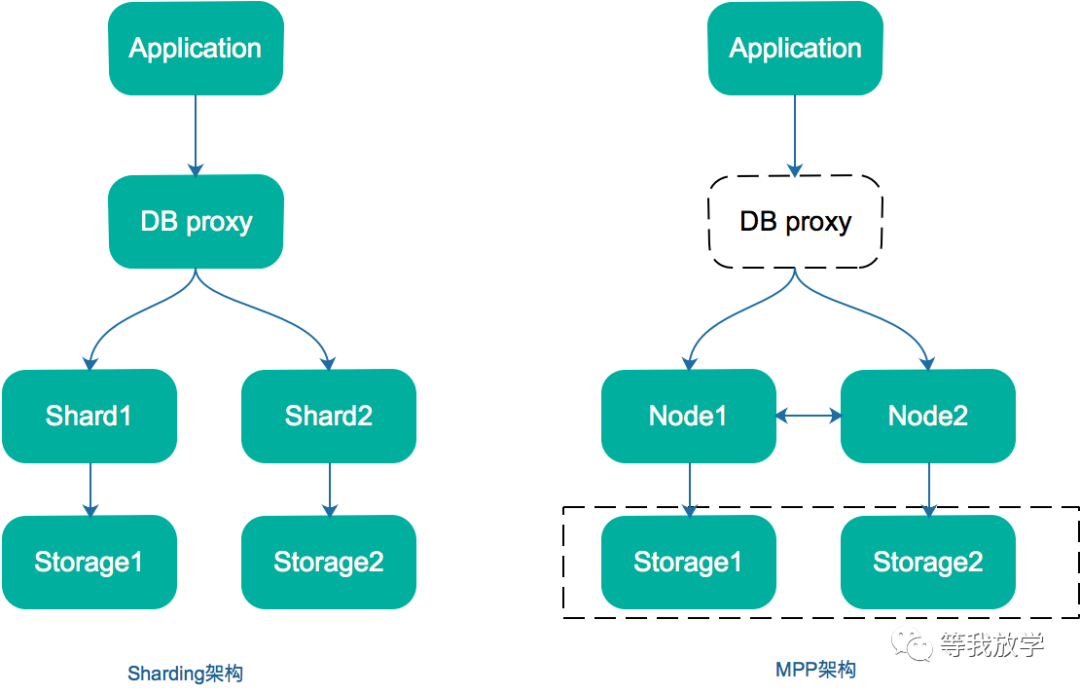
Sharding架构需要一个proxy角色,用于执行分布键拆分、数据路由、结果聚合等操作,每个节点独立存储和计算后把结果汇总给proxy返回应用端;MPP架构中,应用端可以使用proxy进行sql作业分发,也可以直接访问计算节点提交作业。计算节点资源独立,不依赖于master进行数据汇总,数据存储可以独立存储,也可以用分布式共享存储。
相比Sharding,MPP的设计优势有两点:
1、将Master节点解放出来,不再因为Merge操作成为集群瓶颈,从而实现了海量数据分析
2、不用考虑扩容和容灾处理的数据重分布,从而减少分布键带来的分布式事务问题
混合列式读写
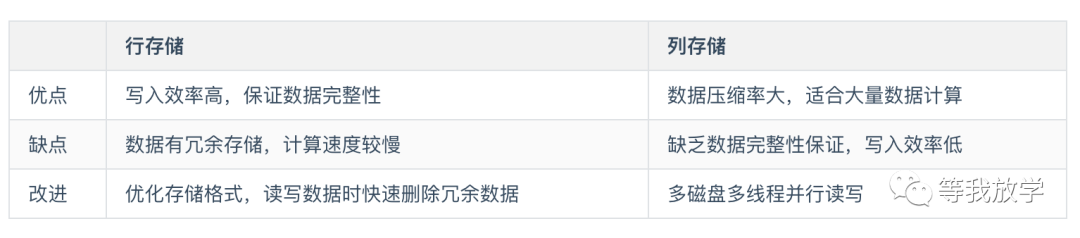
传统的数据库存储模式中,有两种存储方式:行式存储和列式存储。行式存储主要是OLTP的系统,列式存储主要是OLAP的系统。其对比特点如下表所示:
HTAP在大数据领域的演进
大数据技术发展的十几年来,数据处理架构一直在不断地演进,大致经历了纯OLAP、Lambda架构到HTAP架构三个阶段。目前主流架构为Lambda架构及类HTAP架构。
Lambda架构
Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架,大致分为三层:Batch Layer(批处理层)、Speed Layer(实时处理层)和Serving Layer(服务层);批处理层主要用于存储数据,数据清洗和构建模型,多处理离线数据;实时处理层处理增量数据,并不断merge数据到Batch Layer;数据服务层提供数据的查询结构,方便用户查询。Lambda架构的全景图如下:
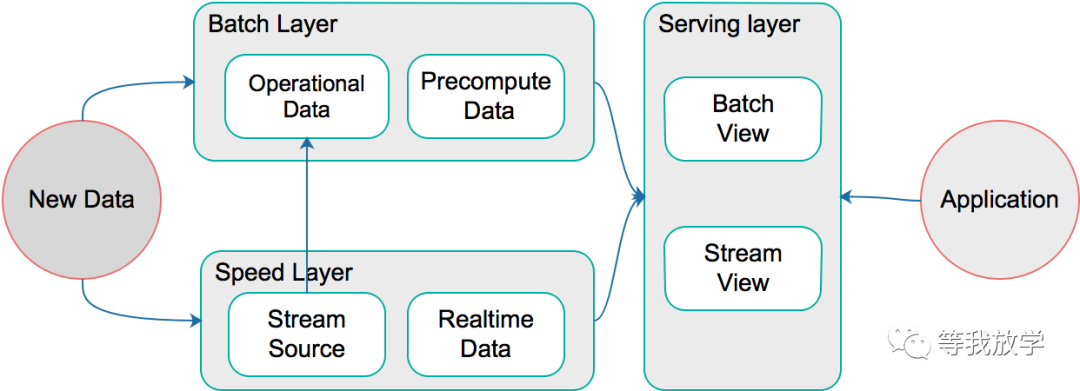
Lambda架构可以结合在线数据源与离线数据源,在一定程度上增加数据处理的实效性。由于其架构的特殊性,每一层需要的组件选择较多,在实践过程中会遇到数据不一致或者数据丢失的情况。实时数据处理往往应用于辅助性的业务场景中,主要靠离线层的批量处理来保证数据的有效性。为了让架构变得简单,采用Lambda架构的系统数据往往是不可变的,在遇到数据更新的场景时,采用覆盖原始数据并重跑作业的办法。
在大数据技术未完善发展的前几年,Lambda架构作为大数据应用的典型架构流行了很长时间,但是其架构非常复杂,在数据写入、存储、查询等方面都有较大的问题,主要集中在:
写入层,Lambda没有统一的数据写入抽象结构,采用批流双写的方式,带来了数据一致性的问题
存储层,流式数据要不断merge到批数据中,等批数据更新时候再进行覆盖,数据分散存储在不同组件里,造成数据的冗余
计算查询逻辑要同时适应批处理和流式计算框架,学习成本较大
针对第3点,spark的出现解决了批流的查询框架问题;针对前两点,业界有提出Kappa架构或者Kappa+架构。基本思想是对用Kafka进行数据存储,在批处理时利用kafka的数据不变型进行历史数据回放,总体上是对Lambda架构的补充,并未解决根本问题。
类HTAP
随着Parquet/ORC列式存储在大数据领域的广泛运用,HTAP架构在大数据领域也渐渐发展起来。结合HTAP思想,出现了如Kudu、Delta Lake为代表的存储方案。它们最大的特点是支持行级数据增删改查,兼顾了按key的查找和批量计算的效率。
在大数据领域中,HBase支持单行的增删改操作一度作为TP应用的典型代表。由于HBase底层基于LSM-Tree架构,数据读取路径长,合并多版本HFile会花费较长时间,所以它不适合作为批量分析。
大数据领域的HTAP组件在数据存储、读取等方面都有相似的优化相比较起来在以下几点:
存储机制:将热数据采用行式存储,存在内存或者delta文件中,在一段时间或者热数据量达到一定程度后merge到采用列式存储的冷数据中。
数据更新:先定位到需要更新的数据,通过预写log的方式进行数据更新,并在一段时间后进行合并或者提交。
数据读取:先扫描定位到数据范围,再读取冷数据的basedata,并计算热数据中的deltadata进行合并,最后union出计算结果。
由于不同的组件架构有区别,所以大数据领域中还没有一个可以满足所有需求场景的HTAP组件,比如kudu无法支持跨tablet的事务处理,TServer的partition数有上限;delta lake在spark3.0发布后有一定完善,但是多用户并发更新会有较大的性能问题。
总结
HTAP架构提出的时间不算很长,但其同时满足AP和TP场景的愿景非常吸引人。大数据技术虽然只有十几年的发展,但已经经历了从离线批到Lambda架构到批流一体到HTAP(还有人称为HSAP)的路线,发展可谓是否迅速。随着Spark3.0的发布, Delta Lake由于原生使用HDFS,其乐观并发锁机制和update操作也引起了很多从业人员的兴趣。而Impala混合kudu和HDFS的运用,也在有效地推动HTAP思想在大数据领域的落地,相信将来HTAP会替代Lambda、Kappa架构,成为大数据领域数据处理的主流框架。
参考文献
[1] 混合事务分析处理“HTAP”的技术要点分析 https://www.infoq.cn/article/rkCx3gsvFZGS9hBSU8LI
[2]Gartner关于HTAP的介绍 https://www.gartner.com/en/documents/2657815/hybrid-transaction-analytical-processing-will-foster-opp
[3]数据库必知词汇 https://developer.aliyun.com/article/745866
[4]数据库行存储及列存储详解https://www.cnblogs.com/rockg/p/11286180.html
[5]From Data Lakes to HTAP: 3 Alternatives to OLAP Data Warehouses https://www.softwareadvice.com/resources/olap-data-warehouse-alternatives/
[6]从数砖开源 Delta Lake 说起 https://developer.aliyun.com/article/699919
[7]用于实时大数据处理的Lambda架构https://blog.csdn.net/brucesea/article/details/45937875
[8]大数据架构如何做到流批一体https://www.infoq.cn/article/Uo4pFswlMzBVhq*Y2tB9
[9]Kudu、Hudi和Delta Lake的比较 https://www.cnblogs.com/kehanc/p/12153409.html
