





1).向量数据库技术路径
从向量数据库实现技术路径上看,大致分为两类。一种是垂直类原生向量数据库(如 Milvus、Pinecone),另一种是集成向量功能的通用数据库(如 PostgreSQL with pgvector、Elasticsearch)。前者的优势在于极致的检索性能和规模。它们从底层架构上就为海量向量的快速查找而设计,因此在对响应速度和数据处理规模有严苛要求的场景中是首选;但其主要挑战在于部署和运维的复杂性及处理复杂的多条件过滤、关联查询时,其灵活性可能不如成熟的通用数据库。而后者的核心优势是便捷性和统一架构。对于已经在使用通用数据库的公司来说,通过加载插件或升级版本,就能快速获得向量检索能力,无需引入新的数据库系统,这极大地降低了技术复杂度和运维成本;更重要的是,可以利用标准方式实现向量与结构化数据的联合查询。其不足之处在于应对超大规模、高并发的纯向量搜索需求时,性能天花板可能低于前者。
从长期发展来看,这两种技术路径的边界正在模糊。未来可能不会是非此即彼的选择。一方面原生向量数据库正在增强其SQL兼容性和复杂查询能力,另一方面传统数据库则在不断优化其向量搜索的性能和索引类型,这种融合趋势将使最终用户受益。此外,云托管与服务化也成为一种趋势,这将有效降低企业的使用门槛和运维负担。同时,产品聚焦AI原生与多模态,与AI工作流更深度地整合,成为RAG(检索增强生成)的核心组件,并为图像、音频、视频等多模态数据提供统一的语义检索能力成为另一趋势。从产业角度来看,个人更倾向于通用数据库的技术路径,这主要是源于来自需求侧的发展趋势。从根植于数据载体的数据库本身出发,不断探索AI使用场景,通过扩展向量能力更有助于低成本地实现这一过程。本文后面也将定位国产通用数据库的向量能力进行说明。
2).向量数据库评估体系
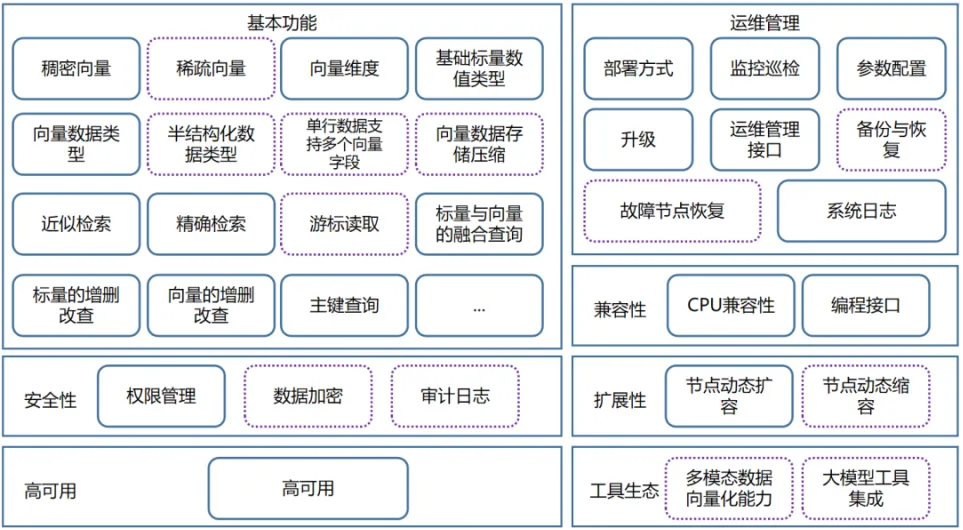
向量数据库尚没有类似国家或行业标准的评估体系,能查到的是来自信通院的评测标准,其包含基本功能、运维管理、安全性 、兼容性、扩展性、高可用以及工具生态七大能力域共47个测试项,其中分为27个必选项和20个可选项。目前包括百度云、腾讯云、拓数派、浪潮海诺等公司产品通过此评测,从中可以看出基本为原生向量数据库。
我们再看看DeepSeek是怎么看待的向量评测标准的,其给出下面提示

- 性能是评估向量数据库最直观的维度,但需要综合看待多个指标。查询延迟(Latency)指完成一次查询所需的时间,尤其要关注P99延迟,这比平均延迟更能反映系统的稳定性。QPS则衡量系统在高并发下的处理能力。需要注意的是,这两个指标与召回率(Recall)密切相关,通常需要在三者之间进行权衡。评估数据插入性能时,不能只看单个写入请求的速度,更要关注从数据写入到可被检索的整体时间(包括索引构建时间)。这对于实时性要求高的应用(如实时推荐)至关重要。
- 可扩展性策从水平和垂直两个维度来看待,水平扩展(通过增加节点扩展集群)通常比垂直扩展(升级单节点硬件)具有更高的灵活性和上限,更适合数据量持续增长的场景。需要评估数据库在数据量从百万级增长到十亿级时,能否保持性能的平滑过渡。
- 功能特性方面,主要看是否支持多种索引算法(如HNSW, IVF),以适配不同的精度和性能需求,是否支持混合查询至关重要。
- 运维与开发方面,前者更关注于企业级功能,如多租户、权限控制、数据加密、监控告警和灾难恢复等能力;后者则希望有良好的开发体验能显著降低项目周期,评估其是否提供简洁的API、丰富的多语言SDK(如Python、Go、Java)、以及与主流AI框架(如LangChain、LlamaIndex)的开箱即成集成。
成本与生态角度,是否提供多种部署方式(全托管、自运维等),是否支持支持在传统数据库通过插件或升级来获得向量能力。后者的优势在于可以利用现有数据库体系和SQL技能,实现结构化数据与向量数据的统一查询。
如前文所讲,本文聚焦于通用数据库支持向量能力,而非专用向量库;因此参照上文的评估体系,这里没有将重点放在开发、运维能力层面,这些对于通用数据库来说已经大多具备。另一方面也没有将性能和扩展性作为要点,上述这些能力是需要真实评测才具有说服力。这里仅就向量自身的功能特性作为要点进行说明。此外,在收集信息的过程中发现,有些国产数据库产品外部宣传已经支持了向量,但大多还在原型阶段或文档还没有放出,没有更多详细信息因此未列入其中。从这方面也不难看出,国内数据库厂商就向量能力来看,还多处于探索阶段。特别说明下,之前也有文章介绍的VexDB,后续其全部能力将内嵌入海量数据库G100 V3.0版本中,因此也作为通用数据库产品列入说明。
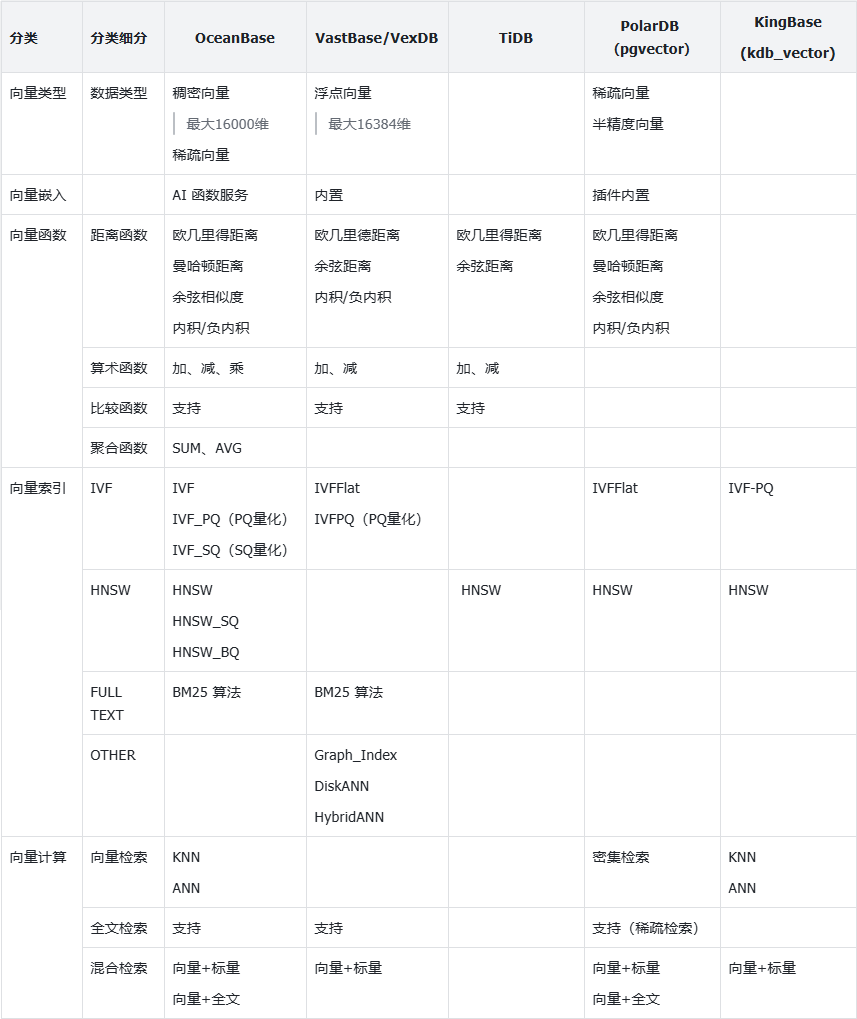
向量嵌入(Vector Embeddings)是一种数据向量化的手段,指的是使用机器学习技术将各类非结构化数据(文本、图像和音频等)转化为固定长度的数字向量的过程,被广泛应用于多模态非结构化数据检索任务中。 相似性搜索,K 最近邻(K-Nearest Neighbor, KNN)算法和近似最近邻(Approximate Nearest Neighbor, ANN)算法是向量检索中常用的两种技术。KNN 优先考虑准确性,细致地识别“K”个最近邻居。ANN 注重速度和效率,查找近似查询点的最近邻居,无法保证得到一组精确的最佳匹配;但 ANN 能够在高准确性和更快性能之间取得平衡。 余弦相似度(cosine similarity)是衡量两个向量的角度差异,它反映了两个向量在方向上的相似度,与向量的长度(大小)无关。内积又称为点积或数量积,表示两个向量之间的一种乘积。在几何意义上,内积表示两个向量的方向关系和大小关系。
