




一、Greenplum 介绍
Greenplum数据库是一种大规模并行处理(MPP)数据库,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。MPP(也被称为shared nothing架构)指有两个或者更多个处理器协同执行一个操作的系统,每一个处理器都有其自己的内存、操作系统和磁盘。
Greenplum数据库是基于PostgreSQL开源技术的。它本质上是多个PostgreSQL面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS)。目前最新的Greenplum基于PostgreSQL 9.4开发,其SQL支持、特性、配置选项和最终用户功能在大部分情况下和PostgreSQL非常相似。
Greenplum数据库和PostgreSQL的主要区别在于:
1. 在基于Postgres查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划。
2. Greenplum数据库可以使用追加优化的存储。
3. Greenplum数据库可以选用列式存储,数据在逻辑上还是组织成一个表,但其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。列式存储只能和追加优化表一起使用。列式存储是可压缩的。
4. Greenplum数据库也包括为针对商业智能(BI)负载优化PostgreSQL而设计的特性。例如,Greenplum增加了并行数据装载(外部表)、资源管理、查询优化以及存储增强,这些在PostgreSQL中都是无法找到的。
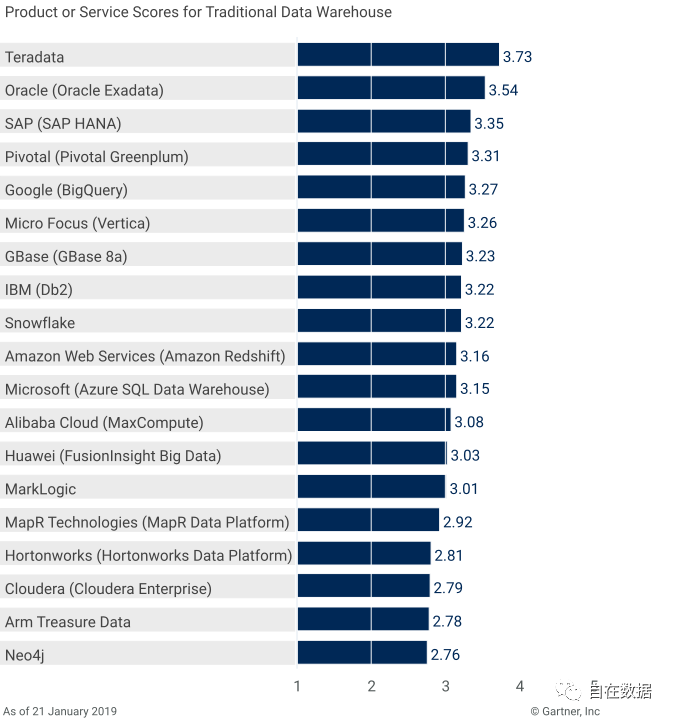
2019年,Garnter发布了2019数据分析管理产品和解决方案(Data Management Solution for Analytics,DMSA)行业报告。在报告中,Gartner从多个角度的12项关键指标中分析了19款重量级产品,Greenplum大数据平台排名跃居第四位,比2018年有了巨大的提升(2018年排名第9位),其他产品基本都经过长达40多年的发展,相比之下,Greenplum还处于青少年时期,发展更为快速。Greenplum是全球十大经典和实时数据分析产品中唯一的开源数据库。
Vendors’ Product Scores forTraditional Data Warehouse Use Case
二、数据库架构
Greenplum是典型的Master/Slave架构,在Greenplum集群中,存在一个或者两个Master节点和多个Segment节点,每个节点上可以运行多个数据库。
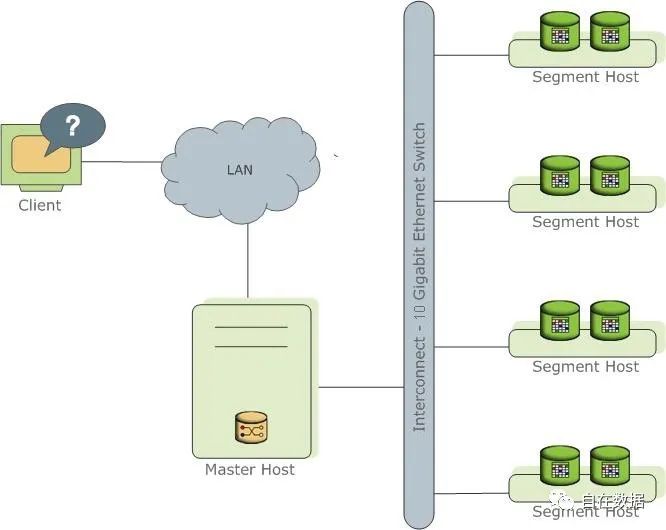
Master:存储用户元数据,负责对整个集群的调度、监控和管理控制
Segment:存储用户数据,执行master分配的任务
Interconnect:实现数据在各个节点间的传输
Greenplum 的核心架构特色:MPP shared nothing。MPP 是大规模并行处理,shared nothing是无共享。
三、Greenplum数据库高可用

1)磁盘
硬件级别RAID部署保证当个磁盘损坏。
2)数据校验码
使用checksums对从磁盘加载到内存数据进行检查,保证数据没有被损坏。
3)segment镜像
用户数据保存在segment,当启用了segment mirror,则每个segment实例都有一个主segment和镜像segment对,镜像segment采用WAL方式与主segment保存同步。
4)master镜像
用户也可以选择性地在一台不同于Master节点的主机上部署一个Master实例的备份或者镜像。如果主Master失效,日志复制进程会停止,并且后备Master会被激活以替代它的位置。
5)双集群
可通过“ETL”或者“备份/恢复”方式保持两个集群数据同步。
四、Greenplum的优势
很多用户从不同数据平台迁移到Greenplum,其中既有老牌数据仓库如Teradata、Netezza,也有传统关系型数据库(如Oracle、DB2、Sybase IQ等),还有一些Hadoop平台。它们之所以迁移到Greenplum,主要有以下几方面的原因:
1)成本低
Greenplum 相比Teradata、Oracle Exadata、IBM Netezza等一体机设备,不需要够买专有硬件设备,有明显的成本优势。100%纯软件产品,用户可以自由选择硬件搭配,可以跑在各种云化环境或私有数据中心中。
2)性能高
Greenplum 相比传统关系型数据库有明显的性能提升,其分析性能随着节点的增加呈类线型增长,一般在Oracle上跑数小时的分析型应用,在Greenplum上只用数分钟或者秒级别返回。
3)易用
Greenplum 相比Hadoop平台,SQL表达能力更为突出,应用改造成本要小很多。虽然近年来SQL On Hadoop的技术不断发展,但在SQL兼容性和性能(尤其是复杂业务场景下的复杂SQL)上相比传统的MPP关系型数据库,还有不小的差距。
4)原生的shared nothing MPP架构(扩展能力强)
当单台机器无法满足性能要求时,可以通过增加机器的方式方式进行水平扩展,理论上可以支持上千个节点以上的集群规模,在真实的生产环境,我们国内有多个用户其集群规模超过100节点,国外有超过200节点,压缩后的数据量达到PB级别。
5)支持多种场景
在支持传统BI分析型应用的基础上,同时支持机器学习、图计算、全文检索、地理位置分析等场景,无需为这些高级特性支持额外的授权费用。
6)产品生命力强
产品开源,完全基于PostgreSQL生态。
7)总成本低
不需要昂贵的专有设备和服务。
8)数据压缩
支持不同的数据压缩算法,降低了数据存储占用空间,提高了查询性能。
9)混合负载(HTAP)性能提升
从今年9月份发布的 Greenplum 6 开始,Greenplum 对 OLTP 业务处理能力大幅提升。数据更新效率:

10) 支持多态存储
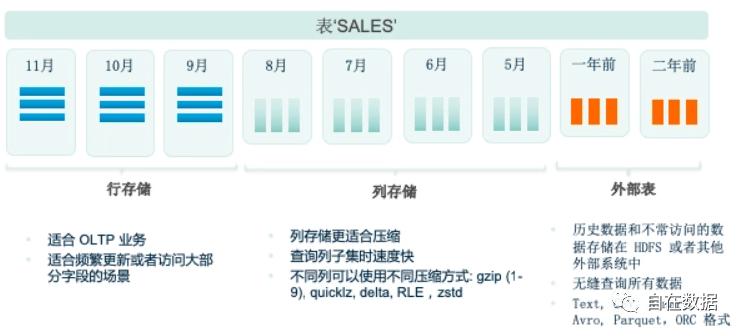
Greenplum可以对同一张表的不同分区采用不同的存储模式,常用的划分标准是根据时间划分分区。比如上图的例子中,最老的数据,也就是不常访问的数据可以使用外部表的模式,中间的数据可以使用列存储,频繁更新或者访问的数据可以用行存储。多态存储对用户透明。
11)数据规模大
产品支撑数据规模对比:
产品名称 | 集群规模 | 数据量 |
Oracle RAC | 32节点以内 | TB级 |
Greenplum | 1000节点以内 | PB级 |
Hadoop | 1000节点以上 | EB级 |
12)支持在线扩容
新的hash机制(Jump Consistant Hash),无需停库,不影响正在执行的查询,扩容时只需要移动部分数据,性能大幅提升。
13)Master自动FailOver
无需外部依赖,利用Segment监控Master,Master失效时自动切换Standby,监控进程失败时自动切换。
14)跨集群查询
支持跨集群数据查询。
15)Kafka集成
支持断点续传,支持多种消息格式,通过Mini-batch执行。
16)支持复制表(Replicated Table)
复制表典型的以空间换时间。一个典型的例子就是维度表,比如人员信息、机构信息等。这类数据表的特点是,数据量不大、很多查询/分析都会与此关联,导致这类表在查询时经常被全量传到各个节点中去。当有这类查询时,现在则不用进行数据的motion,减少网络开销和CPU开销。
五、Greenplum与Oracle对比
Greenplum与Oracle RAC主要维度对比:
对比分类 | Oracle RAC/Exadata | Greenplum |
体系架构 | Shared storage | Shared Nothing |
优势场景 | OLTP | OLAP |
硬件搭配 | SAN存储+光纤网络 | 本地磁盘+以太网 |
扩展能力 | 理论上可以到100个节点,生产上一般在2~10个,虽然所有节点可以同时读写,一般通过应用层sharding扩展其写的能力,读取能力可以水平扩展 | 生产上多在32节点以上,超过100节点以上的有多个用户,理论上可以支撑3000个以上物理节点 |
典型扩展方式 | Scale up | Scale out |
库内编程能力 | 支持PL/SQL库内过程语言和自定义函数,如果要使用R语言等其他分析语言,需要购买额外的高级分析特性 | 支持PL/pgSQL等过程语言,集成Apache MADlib(机器学习、Apache Solr(全文检索、PostGIS(地理空间分析、Python、JAVA、Perl、MapReduce计算框架和其他分析Lib库,如Tensorflow,通过PXF、Spark connector、kafka connector可以方便与Hadoop生态集成 |
云上部署 | 支持AWS等但相比Oracle自家的云产品需要支付更高的授权费用 | 支持多云化部署,可以无差异部署在AWS、GCP、Azure、阿里云、腾讯云等公有云环境,也可以选择部署在企业私有云环境当中、有专门的Greenplum for Kubernetes版本 |
开源策略 | 纯商业产品,完全闭源 | 100%开源,集成原生PostgreSQL生态 |
软件开发效率 | 开发周期较长 | 小版本1个月发布一次,大版本一年,2019年发布基于PostgreSQL9.x版本的Geenplum产品 |
数据格式扩展 | 支持半结构化数据 | 支持Json、Hstore等半结构化数据 |
Oracle和Greenplum的字段类型映射表:
Oracle | Greenplum | Comment |
VARCHAR2(n) | VARCHAR(n) | 在Oracle中n代表的是字节数,在Greenplum中n代表的是字符数 |
CHAR(n) | CHAR(n) | 同上 |
NUMBER(n,m) | NUMERIC(n,m) | number可以转换成numeric,但如果真实业务中数值类型可以用:smallint、 int或bigint等替代,性能会有较大提升 |
NUMBER(4) | SMALLINT |
_ |
NUMBER(9) | INT |
_ |
NUMBER(18) | BIGINT |
_ |
NUMBER(n) | NUMERIC(n) | 如果n>19,可以转换成numerice类型 |
DATE | TIMESTAMP(0) | Oracle和Greenplum都有日期类似,但Oracle的日期类型会同时保存日期和时间,而Greenplum只保包存日期 |
TIMESTAMP WITH LOCAL TIME ZONE | TIMESTAMPTZ | 注意:PostgreSQL中TIMESTAMPTZ不等同于Oralce中的TIMESTAMP WITH TIME ZONE |
CLOB | TEXT | PostgreSQL中TEXT类型不能超过1GB |
BLOB | BYTEA(1 GB limit) | 在Oracle中BLOB用于存放非结构化的二进制数据类型,BLOB最大可存储128TB,而PostgreSQL中BYTEA类型最大可以存储1GB,如果有更大的存储要求,可以使用Large object类型 |
六、Greenplum最佳实践
1、 数据模型
· Greenplum数据库使用非规范化的模式设计会工作得最好,非规范化的模式适合于MPP分析型处理,例如 带有大型事实表和较小维度表的星形模式或者雪花模式。
· 表之间用于连接(join)的列采用相同的数据类型。
2、 堆存储 vs. 追加优化存储
· 经常进行反复的批量或单一UPDATE,DELETE和INSERT 操作的表或分区使用堆存储。
· 对于在初始装载后很少更新并且只会在大型批处理操作中进行后续插入的表和分区,使用追加优化存储。
3、 行存 vs. 列存
· 如果负载中有要求更新并且频繁执行插入的迭代事务,则对这种负载使用行存。
· 在对宽表选择时使用行存。
· 为一般目的或混合负载使用行存。
· 选择面很窄(很少的列)和在少量列上计算数据聚集时使用列存。
· 如果表中有单个列定期被更新而不修改行中的其他列,则对这种表使用列存。
4、 压缩
· 在大型追加优化和分区表上使用压缩以改进系统范围的I/O。
· 在数据最终的存储位置表设置列压缩。
· 平衡压缩解压缩时间和CPU执行周期,选择性能最高的压缩级别。
5、 数据分布
· 为所有的表显式定义一个列分布或者随机分布。不要使用默认值。
· 使用能将数据在所有segment上均匀分布的单个列作为分布键。
· 不要采用查询的WHERE条件中使用的列作为分布键。
· 不要采用日期或时间戳作为分布键。
· 不要将同一列同时用于数据分布和分区。
· 在经常做连接(join)操作的大表上采用相同的分布键,这样可以通过本地连接(join)来显著提高性能。
· 在初始装载数据以及增量装载数据之后验证数据没有明显倾斜。
6、 分区
· 只对大型表分区。不要分区小表。
· 只有能基于查询条件实现分区消除(分区裁剪)时才使用分区。
· 选择范围分区而舍弃列表分区。
· 基于查询谓词对表分区。
· 不要在同一列上对表进行分布和分区。
· 不要使用默认分区。
· 不要使用多级分区,创建较少的分区让每个分区中有更多数据。
· 不要用列存储创建太多分区,因为每个Segment上的物理文件总数:physical files = segments x columns x partitions
7、 索引
· 通常在Greenplum数据库中无需使用索引。
· 对高基数的表在列式表的单列上创建索引用于钻透目的要求查询具有较高的选择度。
· 不要索引被频繁更新的列。
· 总是在装载数据到表之前删除索引。在装载后,重新为该表创建索引。
8、 资源队列
· 使用资源队列来管理集群上的负载。
· 将所有的角色都与一个用户定义的资源队列关联。
9、 Vacuum
· 在大量UPDATE和DELETE操作后运行 VACUUM。
· 不要运行VACUUM FULL。而是运行一个CREATETABLE...AS 操作,然后重命名并且删掉原始表。
· 绝不要杀掉系统目录表上的VACUUM操作。
文章中部分内容引自:
Greenplum官方文档
