





作者:Rebooter.S
原文:https://sqlflash.ai/blog/sql-llm-dataset-202507/ July 20, 2025
爱可生开源社区翻译,本文约 1700 字,预计阅读需要 5 分钟。

前言
当我们对 AI4SQL/AI4DB/DB4AI 类产品进行研究时,我们发现 SQL 领域应用能力的提升很大程度上依赖于高质量的数据集。
还需要在此基础上进行数据合成,生成针对特定问题的训练集和评估集。为了帮助更多开发者快速获取资源,我们将近年来公开的 Text2SQL/NL2SQL 数据集进行了整理清单,持续分享给大家!
第一期的高质量数据集推荐,我们一次性推荐了 23 款数据集。本期我们将带来 Brid 团队的 BIRD-CRITIC[1]。

充满挑战的 SQL 诊断评测基准
什么是 BIRD-CRITIC?
BIRD-CRITIC(又名 SWE-SQL)是首个 SQL 诊断评测基准,其发布旨在解答:大型语言模型(LLMs)能否修复真实世界数据库应用中的用户问题?
该基准包含 600 个开发任务和 200 个保留的分布外(OOD)测试任务。BIRD-CRITIC 1.0 基于跨越 4 种主流开源 SQL 方言(MySQL、PostgreSQL、SQL Server 和 Oracle)的真实用户问题构建。它超越了简单的 SELECT 查询,涵盖了更广泛的 SQL 操作,反映了实际应用场景。最后,基准还包含一个优化的、基于执行的评估环境,用于进行严格且高效的验证。
数据集分为四个版本:
bird-critic-1.0-flash-exp:轻量版,含 200 个 PostgreSQL 实例 bird-critic-1.0-open:完整版,覆盖四大方言共 600 个实例 bird-critic-1.0-postgresql:PostgreSQL 专属版,含 600 个实例 bird-critic-1.0-bigquery:包含 BigQuery 中 200 个任务的完整版本
大语言模型能否解决实际数据库应用程序中的用户问题?
2025 年 7 月 9 日,Bird 发布了该数据集的人类表现分数,相交大语言模型均有较大幅度的领先!
三个 排行榜[2] 上显示的分数反映了人类评估者(数据库专家),他们被允许使用标准工具(数据库教科书、官方文档或 IDE),但不允许使用人工智能助手。
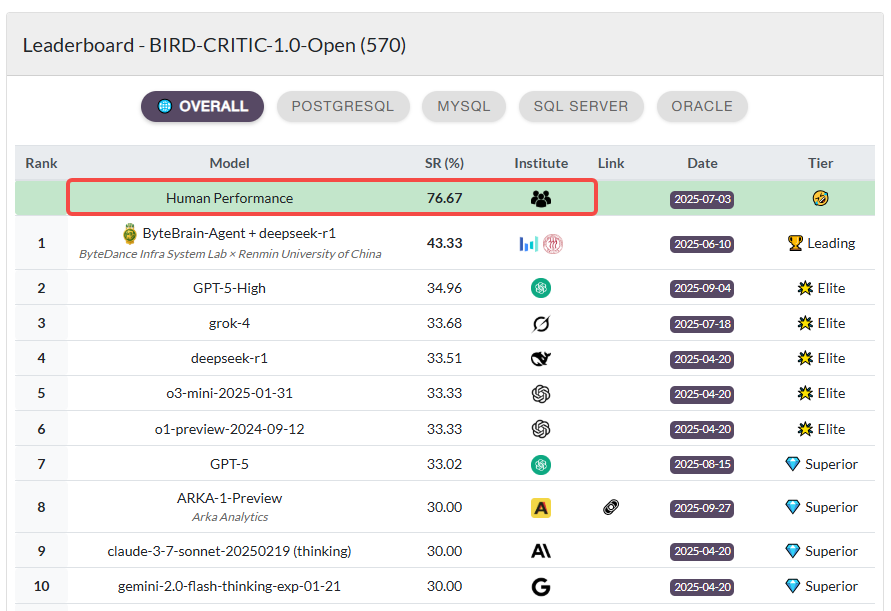
Leaderboard - BIRD-CRITIC-1.0-Open (570)
当另一组具有相同专业知识的团队被允许使用人工智能工具(ChatGPT、Claude 或 Gemini)时,bird-critic-1.0-open 的性能提高到 83.33,bird-critic-1.0-postgresql 的性能提高到 87.90,bird-critic-1.0-flash-exp 的性能提高到 90.00,展示了人机协作在 SQL 问题解决方面的巨大潜力。
该数据集有哪些特点呢?
BIRD-CRITIC 作为 SQL 调试新基准,其核心数据包含三大要素:问题 SQL 语句、自然语言问题描述和数据库模式,重点评估大模型根据用户描述修复错误 SQL 的能力。
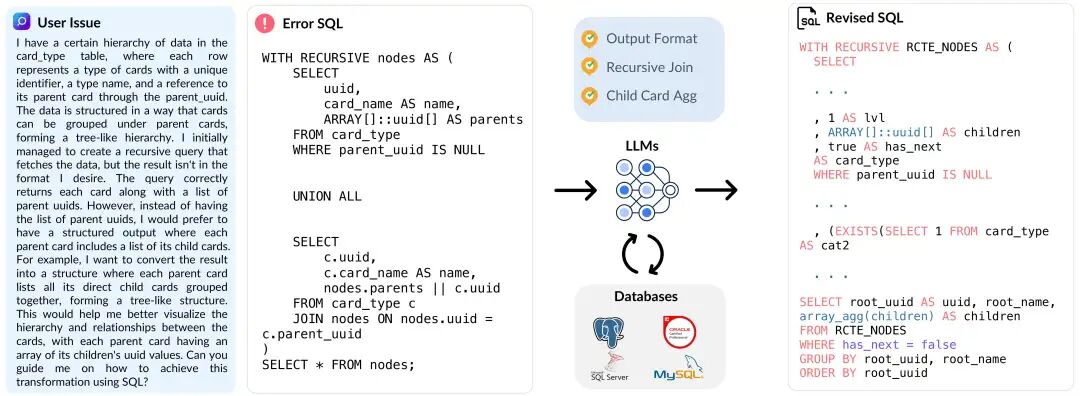
① 具备真实场景的高复杂度设计
其任务均源自 StackOverflow[3] 真实用户问题,并经过严格筛选,标准包括:
包含可执行但存在错误/低效的 SQL 代码 体现学术研究或实际调试中的关键数据库概念 具备适当复杂度(查询长度 > 100 token 或含非平凡函数) 提供充分上下文以避免歧义
数据集示例 A
在财务数据库中,我希望对数据表的所有可空列应用一个前向填充函数。该函数应能动态处理,只需给定表名、一个 ID 列和一个行号列即可对每个可空列进行前向填充。例如,对于 trans
表,我希望以 account_id
分组并按 date
排序,对所有可空列执行前向填充。此函数应能适用于任何包含可空列的表并进行相应处理。然而,我最初尝试编写的函数出现了语法错误。我需要一个修正后的函数版本,能够适用于任何包含可空列的表。

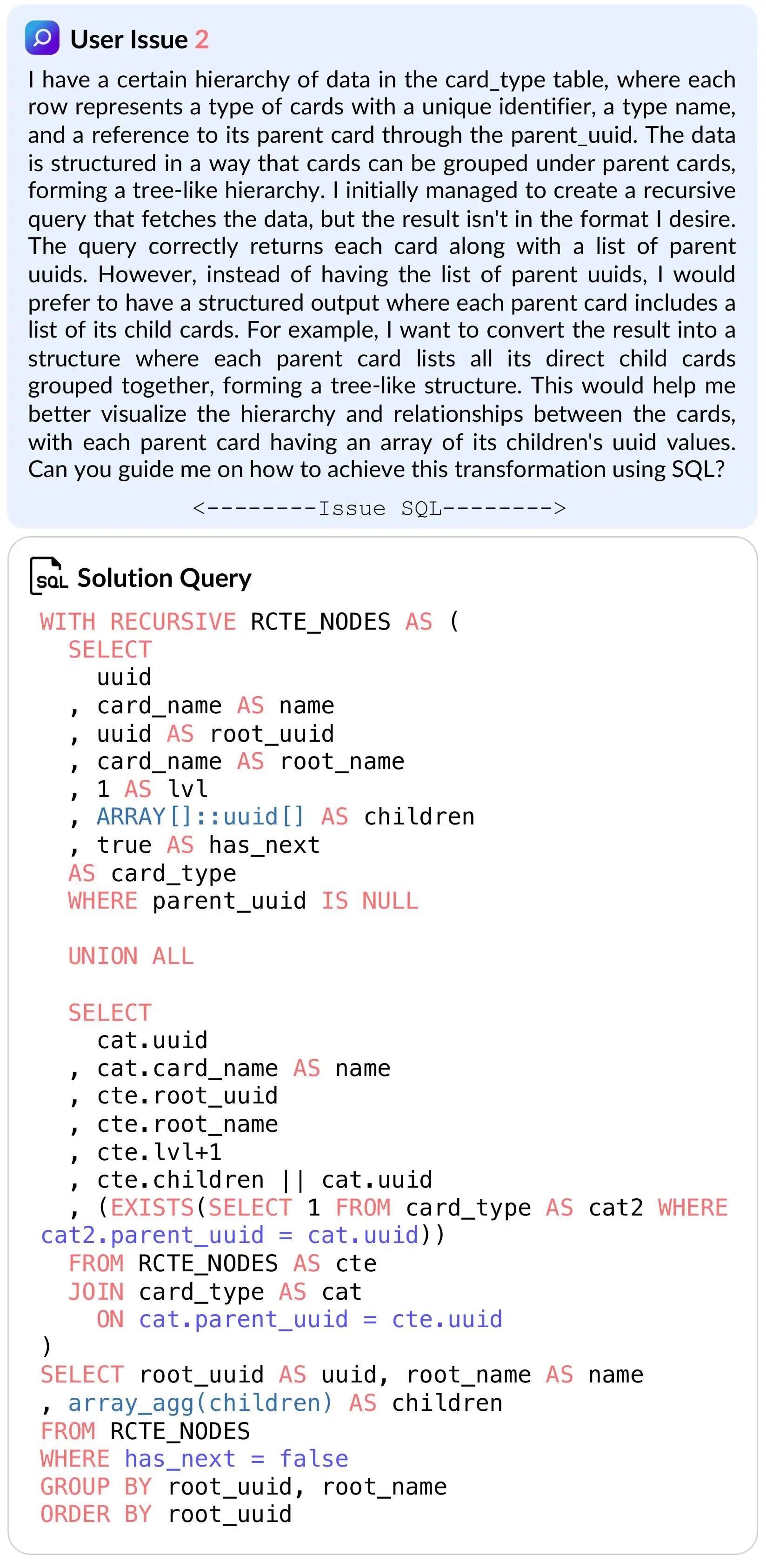
数据集示例 B
我在 card_type
表中存在层级化数据,每行代表一种卡片类型,包含唯一标识符、类型名称以及通过 parent_uuid
字段指向其父卡片的引用。数据结构的设计使得卡片可以分组在父卡片下,形成树状层级结构。我最初创建了一个递归查询来获取数据,但结果格式不符合我的期望。该查询能正确返回每张卡片及其父级 UUID 列表,然而,相比于显示父级 UUID 列表,我更希望获得结构化的输出,即每个父卡片包含其子卡片列表。例如,我希望将结果转换为一种结构,其中每个父卡片都列出其所有直接子卡片并分组在一起,形成树状结构。这将有助于我更清晰地可视化卡片间的层级关系和关联,使每个父卡片都包含一个其子卡片 UUID 值的数组。您能否指导我如何使用 SQL 实现这种转换?
② 多方言兼容性实践
基于 BIRD-SQL 开发集的数据库结构,团队通过 Navicat 将原始 SQLite 模式迁移至 PostgreSQL、MySQL、SQL Server 和 Oracle 这四种广泛使用的生产级方言。迁移后通过人工验证确保:
架构结构正确反映方言差异 数据一致性通过跨数据库检查 原始数据完整性得到保留
③ 数据质量保障体系
采用双重标注机制。
基础标注组:10 名通过严格测试的 SQL 专业人员 专家仲裁组:3 名资深数据库科学家。
并实施三阶段交叉验证:
通过扩展测试用例强化 SQL 验证 引入错误进行红队测试评估脚本 争议问题由专家团队最终裁决
总结
基于 BIRD-CRITIC 论文中所做的实验发现:
SOTA 模型表现:当前最优模型(如 O3-Mini)在 PostgreSQL 任务上的成功率仅 38.87%,凸显任务挑战性; 方法论对比:基于推理的 LLMs 优势显著 —— PostgreSQL 任务平均成功率比通用模型高 6.13%,多方言任务高 8.03%;基于 BIRD-FIXER 微调架构可以将小模型的能力提升超越顶级大模型; 问题类型差异:对比不同的问题类型例如在数据管理相关、DDL、DML、DQL 等问题,查询类问题对所有 LLMs 来说依然都是最大的挑战。
该基准的推出,为 SQL 诊断领域的模型能力评估树立了新的现实标准。
后续更新
我们将继续介绍高质量数据集,敬请期待。
BIRD-CRITIC Paper: https://arxiv.org/html/2506.18951v2
[2]排行榜: https://bird-critic.github.io/
[3]StackOverflow: https://stackoverflow.co/
本文关键字:#数据集 #Text2SQL #LLMs #PostgreSQL


✨ Github:https://github.com/actiontech/sqle
📚 文档:https://actiontech.github.io/sqle-docs/
💻 官网:https://opensource.actionsky.com/sqle/
👥 微信群:请添加小助手加入 ActionOpenSource
🔗 商业支持:https://www.actionsky.com/sqle

