一夜之间用户暴涨一千万,怎么无痛压缩成本?

大模型er请睁眼!
昨晚,由于新产品创新点满分,一夜之间,你们的用户量增长千万。
这时候,你会:
A 开个会复盘打法与痛点
B 融资、通稿、瑞士团建一条龙
C 打电话给辛顿,请教诺奖注意事项
醒醒!复习下年初考点!!!
答案显而易见,选D
由于突然的流量暴涨
系统瘫痪了
服务器资源不够了
大模型API成本直接上天,财务已经哭晕了
而你,我的朋友,你要连夜加班去搞定服务器,优化性能和资源分配!
要么成本超支,系统扩展性受限
作为十多年的老运维,最近发现一个宝藏
vLLM团队推出的Semantic Router项目
通过智能路由,Semantic Router会组合不同的模型,把简单需求扔给小模型,复杂任务上大模型,并在高频问题上,直接用向量数据库缓存直接取代模型推理,显著降低成本的同时加快响应速度。
那么,Semantic Router是怎么实现的,我们如何使用它?本文将带你手把手搞定。
01
行业背景
语义路由成为大模型落地必选项
一句话概括:Semantic Router = 语义路由 + MoM + 缓存层。
所谓语义路由,即根据输入的语义内容、复杂度与意图,匹配最合适模型。
MoM则指的是Mixture of Models,在一个系统内组合不同大小、复杂度、模态的模型。这个思路与大模型常用的MoE架构(Mixture of Experts,在单一大模型内部进行路由与专家模型组合)有异曲同工之处。但MoM整体的成本和延迟更低,并且能够避免我们的系统被单一模型绑定锁死。
在基于轻量级分类器的语义路由与MoM的基础上,vLLM Semantic Router还额外引入了一个向量数据库构建的缓存层,用于检查语义缓存是否有相似历史问题可复用。
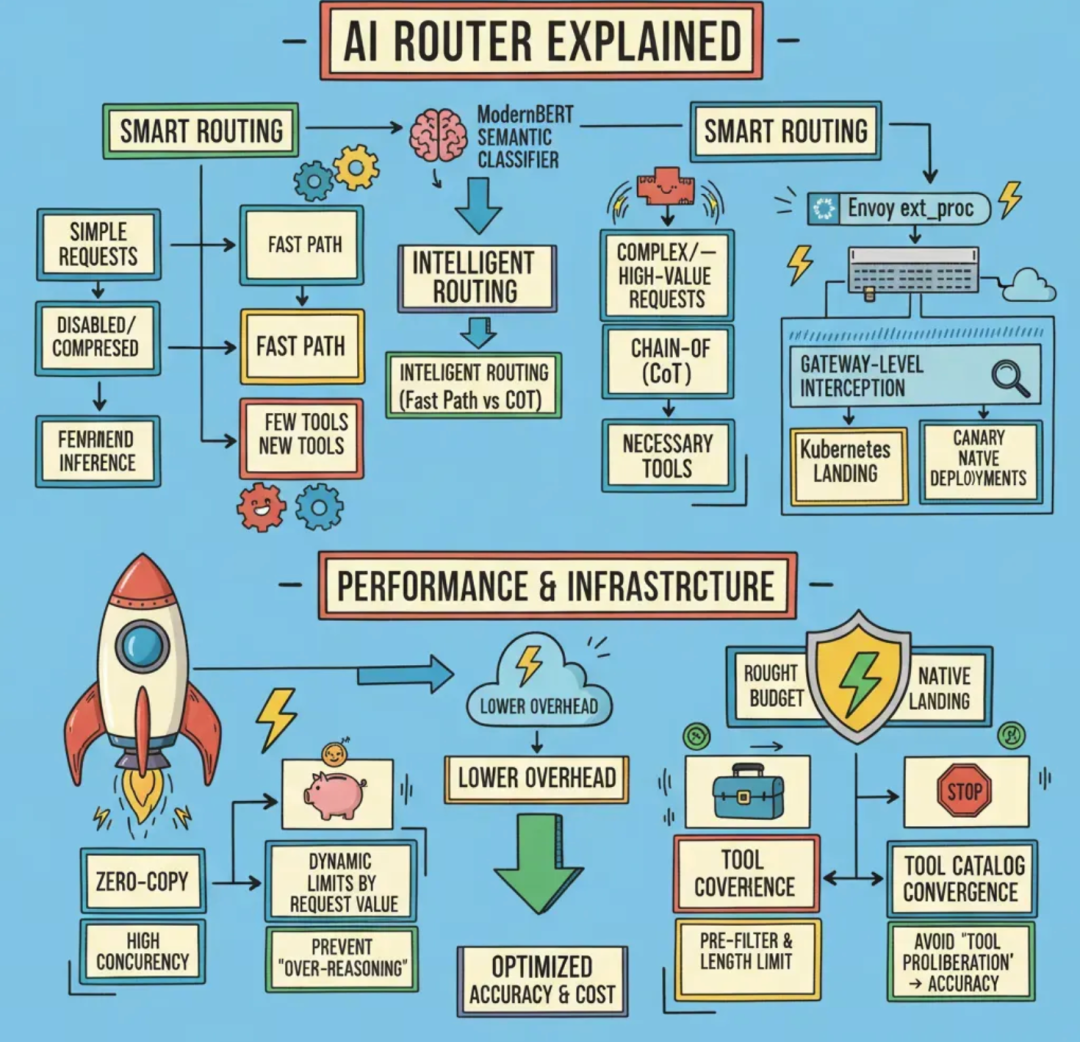
在这个三层架构中,比较值得一提的是基于Milvus打造的缓存层。
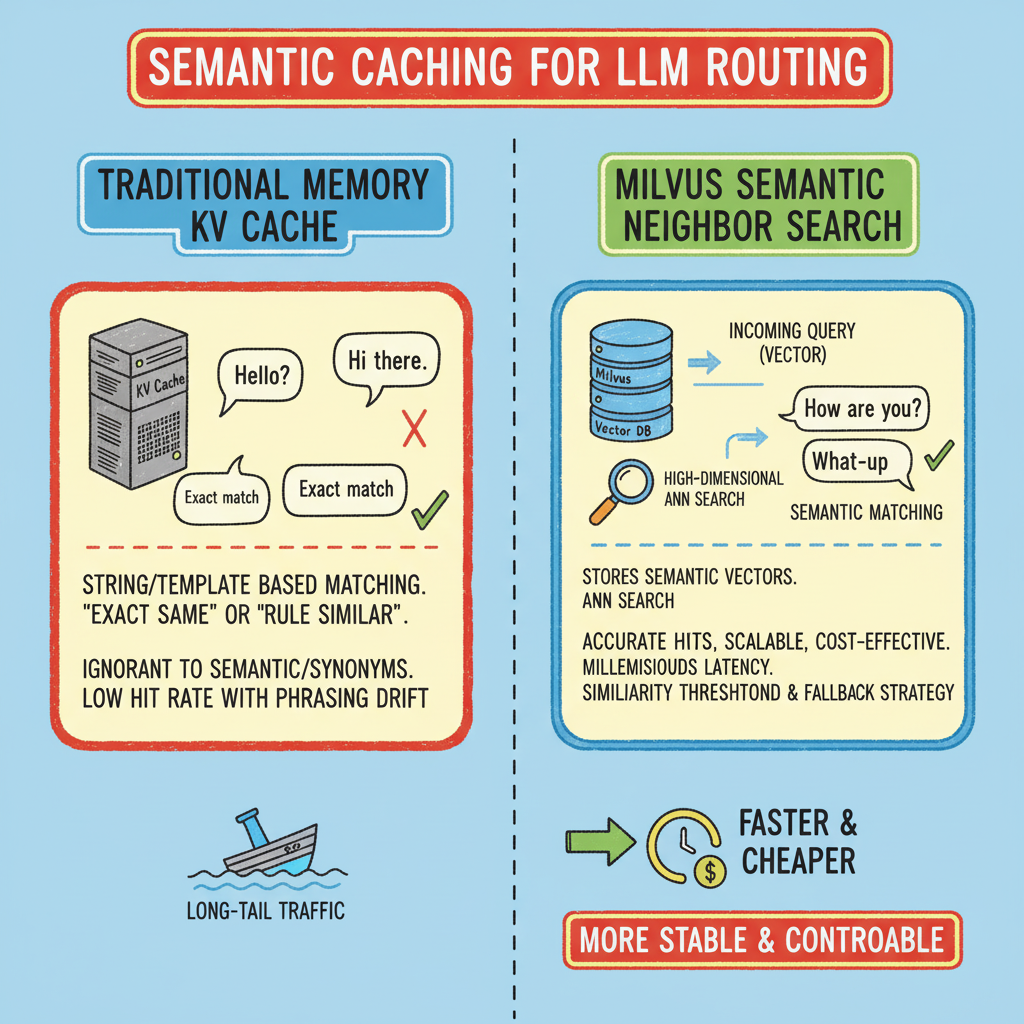
过去,行业内常用的传统内存键值缓存(例如基于字符串或模板的命中方式),仅能支持模板化程度高、话术变化小的场景,对语义改写、同义表述几乎无法识别,其命中率会随话术的变化(即 话术漂移)快速下滑。
因此,我们需要引入语义检索来打造我们的缓存层。语义检索的核心需求是高维向量近邻搜索(ANN),但当数据量从万级攀升至亿级时,若仍采用单机内存 + 暴力检索的模式(计算复杂度为 O (N・d)),不仅会因硬件成本高、架构无法横向扩展导致落地困难,更会因算力无法承载突发请求,轻易被长尾流量拖垮。
针对语义检索的核心需求与单机方案的痛点,在语义路由场景中,Milvus 给出了针对性解决方案:首先,Milvus是一个分布式架构的向量数据库,支持横向扩容;在此基础上搭配合适的相似度阈值与回退策略,还可以带来更高的稳定性与可控性。
02
Semantic Router + Milvus的典型场景
vLLM Semantic Router结合Milvus的核心场景概括有三:
客服问答:成本敏感、速度敏感、回答复用度高。常见问题交给小模型处理,复杂问题再使用大模型
代码辅助:回答复用度高。针对不同复杂度的编程问题选择合适的模型,提高开发效率
企业知识库:回答复用度高。利用Milvus缓存系统存储常见问题的答案,减少重复计算
另外,值得一提的是,Semantic Router + Milvus的整个流程基于Go和Rust高效实现,无侵入集成于网关层,持续通过指标监控优化路由策略。
以下是配置demo。
03
五分钟快速验证
demo目标:快速验证semantic-router 的语义缓存功能,通过 Milvus 向量数据库实现了高效的语义相似性匹配提升了相同或相似查询的响应速度
环境准备
容器环境:docker+docker-compose
向量数据库:Milvus 服务
LLM+Embedding:项目本地下载
1.第一步:部署Milvus向量数据库
1.1.下载部署文件
wget https://github.com/Milvus-io/Milvus/releases/download/v2.5.12/Milvus-standalone-docker-compose.yml -O docker-compose.yml
1.2.启动Milvus服务
docker-compose up -d
docker-compose ps -a

2.第二步:Clone项目
git clone https://github.com/vllm-project/semantic-router.git3.下载本地模型
cd semantic-routermake download-models

4.配置修改
说明:修改semantic_cache类型为milvus
vim config.yamlsemantic_cache:enabled: truebackend_type: "milvus" # Options: "memory" or "milvus"backend_config_path: "config/cache/milvus.yaml"similarity_threshold: 0.8max_entries: 1000 # Only applies to memory backendttl_seconds: 3600eviction_policy: "fifo"
4.1修改milvus配置
说明:把刚才部署好的milvus服务填入
vim milvus.yaml
# Milvus connection settingsconnection:# Milvus server host (change for production deployment)host: "192.168.7.xxx" # For production: use your Milvus cluster endpoint# Milvus server portport: 19530 # Standard Milvus port# Database name (optional, defaults to "default")database: "default"# Connection timeout in secondstimeout: 30# Authentication (enable for production)auth:enabled: false # Set to true for productionusername: "" # Your Milvus usernamepassword: "" # Your Milvus password# TLS/SSL configuration (recommended for production)tls:enabled: false # Set to true for secure connectionscert_file: "" # Path to client certificatekey_file: "" # Path to client private keyca_file: "" # Path to CA certificate# Collection settingscollection:# Name of the collection to store cache entriesname: "semantic_cache"# Description of the collectiondescription: "Semantic cache for LLM request-response pairs"# Vector field configurationvector_field:# Name of the vector fieldname: "embedding"# Dimension of the embeddings (auto-detected from model at runtime)dimension: 384 # This value is ignored - dimension is auto-detected from the embedding model# Metric type for similarity calculationmetric_type: "IP" # Inner Product (cosine similarity for normalized vectors)# Index configuration for the vector fieldindex:# Index type (HNSW is recommended for most use cases)type: "HNSW"# Index parametersparams:M: 16 # Number of bi-directional links for each nodeefConstruction: 64 # Search scope during index construction
5.启动项目
说明:建议修改部分Dockerfile依赖为国内源
docker compose --profile testing up --build
6.测试请求
说明:共两次请求(无缓存和缓存命中)
第一次请求
echo "=== 第一次请求(无缓存状态) ===" && \time curl -X POST http://localhost:8801/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer test-token" \-d '{"model": "auto","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "What are the main renewable energy sources?"}],"temperature": 0.7}' | jq .
第一次请求结果
real 0m16.546suser 0m0.116ssys 0m0.033s
第二次请求
echo "=== 第二次请求(缓存状态) ===" && \time curl -X POST http://localhost:8801/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer test-token" \-d '{"model": "auto","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "What are the main renewable energy sources?"}],"temperature": 0.7}' | jq .
第二次请求结果
real 0m2.393suser 0m0.116ssys 0m0.021s
这个测试演示了 semantic-router 的语义缓存功能,通过 Milvus 向量数据库实现了高效的语义相似性匹配,显著提升了相同或相似查询的响应速度。
在AI成本优化成为刚需的今天,vLLM Semantic Router + Milvus的组合为我们提供了一个兼顾成本与性能的解决方案。
关于这个项目与组合,大家还有哪些更多的意见与建议欢迎在评论区讨论交流。
作者介绍

Zilliz黄金写手:尹珉