




在传统MPP数仓中,时间点恢复(Point-in-Time Recovery,PITR) 一直是保障数据安全的基础机制。通过归档 WAL 日志并结合全量备份,可以在数据库出现逻辑错误或异常宕机时,将系统恢复到指定的历史时刻。但这种机制更多依赖于 DBA 对日志与备份的手工管理,恢复流程复杂,且恢复完成后的集群往往只能以冷备形式存在,缺乏对业务连续性与资源利用率的支撑。
在这一背景下,酷克数据基于 Apache Cloudberry 2.0,为 HashData Lightning 2.0 打造了全新的灾备恢复工具 CBDR。CBDR 在继承 Greenplum WAL 归档与 PITR(时间点恢复) 思路的基础上,进行了系统性的扩展与优化:通过自动化的恢复点管理、跨机房的增量复制,以及支持查询的热备模式,CBDR 为分布式数据库提供了真正意义上的持续保护与业务连续性保障。
与传统 PITR 相比,CBDR 的价值不仅体现在“能恢复”,更强调“可持续”:灾备集群不再只是被动的“备用保险箱”,而是可以在日常运行中承担只读查询、数据一致性验证等实际任务,让灾备资源真正被充分利用。本文将围绕 CBDR 的核心能力、关键机制以及典型应用场景展开详细介绍。
什么是CBDR?
CBDR 连续归档恢复是一种基于 WAL 日志归档的灾难恢复方案。它通过结合物理全量备份与 WAL 归档文件,实现对 Apache Cloudberry 数据库集群的连续数据保护与时间点恢复(Point-in-Time Recovery, PITR)。
与传统的增量备份方式相比,CBDR 能够以更轻量的方式、更高的频率创建恢复点,从而在恢复时间目标(RTO)和恢复点目标(RPO)方面提供更优表现。
借助 CBDR,可以实现 MPP 数据库的异地容灾。在容灾机房中部署一个服务器数量更少、但实例规模一致的集群,即可通过 CBDR 实现跨机房的数据增量复制与恢复。同时,灾备集群还可对外提供只读服务,不仅能够合理利用系统资源,还能实时验证数据与主集群的一致性。当生产集群发生故障时,应用可快速切换至灾备集群运行。待生产集群恢复后,再将数据回复制至生产环境,并重新构建灾备保护机制,从而保障业务的连续性与稳定性。
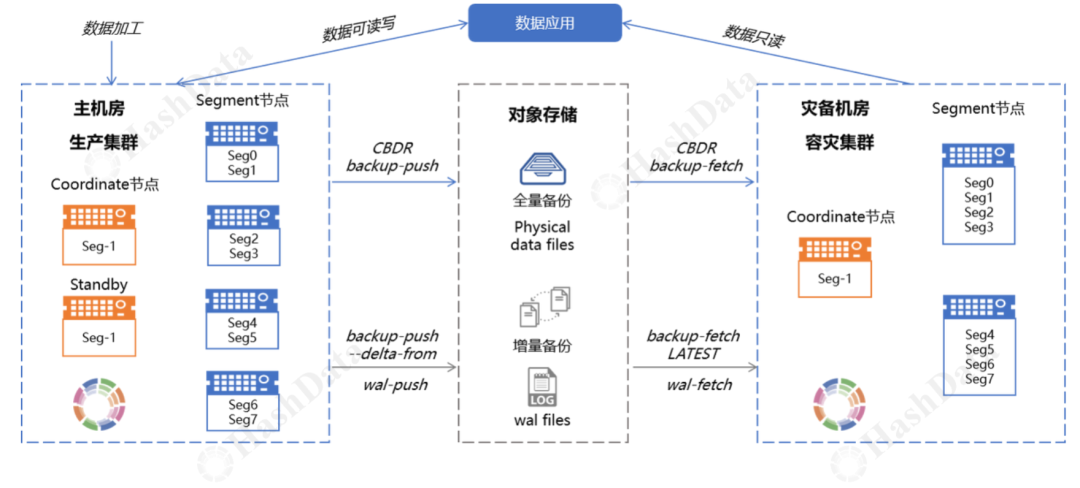
CBDR 的核心能力
恢复点机制
WAL 归档机制:主集群正常运行时产生 WAL 文件,CBDR 持续将 WAL 文件归档到远程存储S3 恢复点 (Restore Point):记录集群在特定时间点的一致性状态
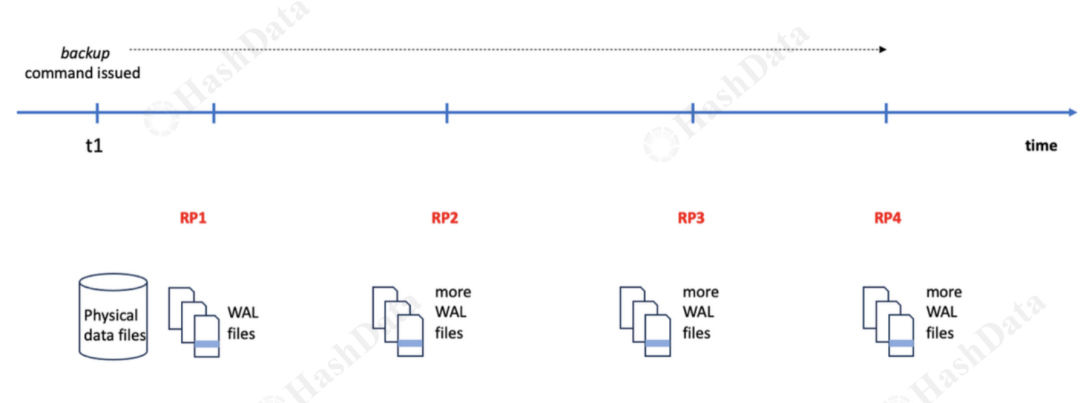
如上图在 t1 时间点进行全量备份后,每当创建一个恢复点,wal log 就会进行切换,由 cbdr 备份工具归档到 s3 存储中,恢复集群只需要顺序回放这些 wal log 即可恢复到和备份集群一致的状态。
连续恢复机制
恢复点检测 恢复集群的 Startup 进程在 WAL 日志回放过程中,会逐条检查日志记录:当检测到恢复点时,会将该恢复点名称与gp_pause_on_restore_point_replay GUC值进行比对;若两者匹配,则触发 WAL 回放暂停机制。 暂停与恢复流程 当 WAL 回放到达目标恢复点并暂停后,可按以下步骤继续回放:
修改gp_pause_on_restore_point_replay参数,指定下一个目标恢复点名称; 执行配置重新加载操作select pg_wal_replay_resume();使新的恢复点配置生效; 调用pg_wal_replay_resume()函数,重启 WAL 日志回放; 系统会在新的目标恢复点再次自动暂停,直至重复上述步骤。
Hot Standby(热备)机制
Hot Standby 的核心是使备集群在恢复至指定恢复点后,仍能对外提供只读查询服务。其核心原理是:主集群通过 WAL 日志将分布式快照同步至备集群,当备集群接收读请求时,即以该分布式快照作为数据可见性的判断基准。要实现这一机制,需解决以下两个核心问题:
确保所有的节点都恢复到指定的恢复点后才提供读查询:为避免因部分节点未完成日志回放导致的查询数据不一致,CBDR 对恢复进度同步做了严格控制,当执行 replay-resume(日志回放恢复)命令时,自动轮询备集群的所有节点,实时检查各节点的 WAL 日志回放进度是否已达到目标恢复点(restore-point)。只有当所有节点均确认完成该恢复点的日志回放、集群整体处于数据一致状态后,备集群才会正式对外开放只读查询服务
确保备份集群和主集群分布式快照一致:相较于 PostgreSQL 单节点,CBDB 分布式集群的 Hot Standby 需额外处理分布式事务一致性问题。系统在内部通过分布式事务的两阶段提交机制及对应的 WAL 日志跟踪来保证主备间事务状态的一致性,并在恢复时动态构建分布式快照,确保查询结果与主集群视图保持同步。
CBDR 典型应用场景
金融交易系统:在证券、支付清算等场景中,事务一致性与极低的 RPO/RTO 是核心要求。CBDR 通过分布式两阶段提交日志的精确回放,确保主备集群的分布式快照保持一致。在灾难发生时,可以在秒级时间内将应用流量切换至灾备集群,避免因事务丢失或回滚带来的资金对账差异。 电商高峰业务:电商大促或秒杀期间,主集群需要承载高并发写入压力,而灾备集群不仅提供 WAL 增量复制与实时恢复,还能开启 Hot Standby 模式分担只读查询(如订单状态查询、商品检索、报表统计)。这种模式既降低了主集群的压力,又保证在主集群宕机时能够快速接管写入请求,保障业务连续性。 IoT 实时数据采集:在 IoT 或日志采集场景下,数据写入量大、更新频繁。传统冷备机制无法满足连续恢复需求。CBDR 提供的连续归档能力,可以在异地集群上实现毫秒级的 WAL 流式回放,使灾备集群在灾难切换时几乎无数据丢失,并能在平时承载时序分析、告警检测等只读查询。 合规与审计:在受监管行业(如银行、能源、电信)中,系统需要长期保留可追溯的历史恢复点。CBDR 的恢复点管理机制,不仅能够精确记录任意时间点的集群一致性状态,还能通过只读灾备集群对历史快照进行回放验证,满足数据可追溯、合规审计与灾备演练的要求。
写在最后
综上所述,CBDR 并非对 Greenplum 等 MPP 数据库传统 PITR 机制的简单复刻,而是一次系统性的革新。它继承了 WAL 归档的核心思想,但通过自动化的恢复点管理、可靠的连续恢复机制以及革命性的热备(Hot Standby)模式,将灾备体系从过去被动的“冷保险箱”,转变为一个兼具数据保护与业务价值的“生产力平台”。
对于企业而言,CBDR 的价值是双重的:一方面,它以更低的 RPO 和 RTO 实现了更可靠的数据安全保障;另一方面,它盘活了灾备资源,允许在备用集群上运行只读查询、报表分析和数据验证任务,显著提升了资源利用率,有效降低了整体 TCO。

