




前言
自从开始使用 RMAN Duplicate 搭建 DG 之后,发现非常好用,基本都是这样去操作,也没有遇到过什么问题。
这次有一个 20T 左右的库需要搭建 DG,放在后台去跑 Dup,结果早上看了下,报错了:
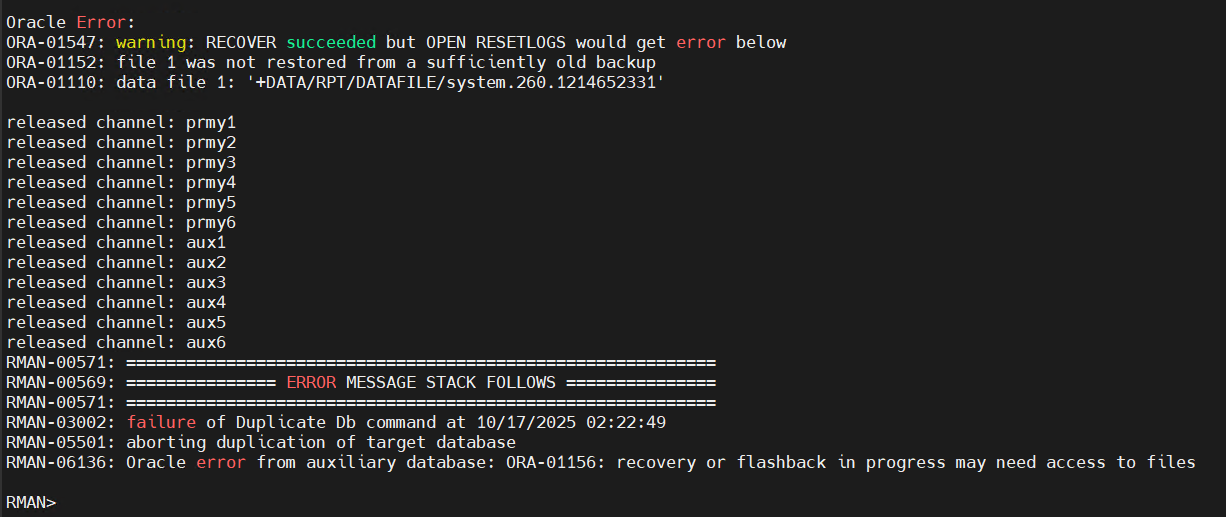
正常应该是 dup 完成后可以直接开库了。
问题分析
尝试手动启动数据库报错 ORA-19838:
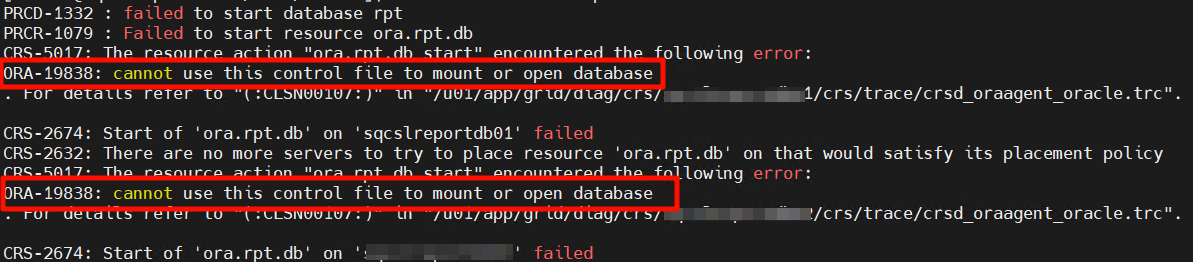
直接 startup mount 也是报错:
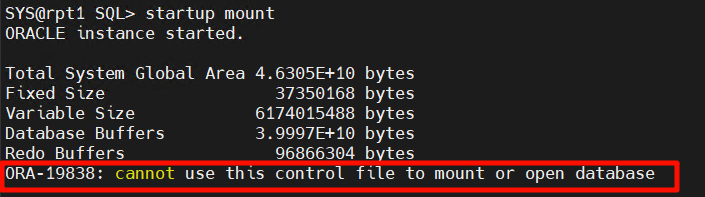
alert 日志:
2025-10-17T08:52:27.367981+08:00 ORA-19838 signalled during: ALTER DATABASE MOUNT...
搜索 MOS 发现一篇文档比较符合:Mounting Standby Database After RMAN Duplicate Failure Returns Error ORA-19838 (Doc ID 2452298.1)
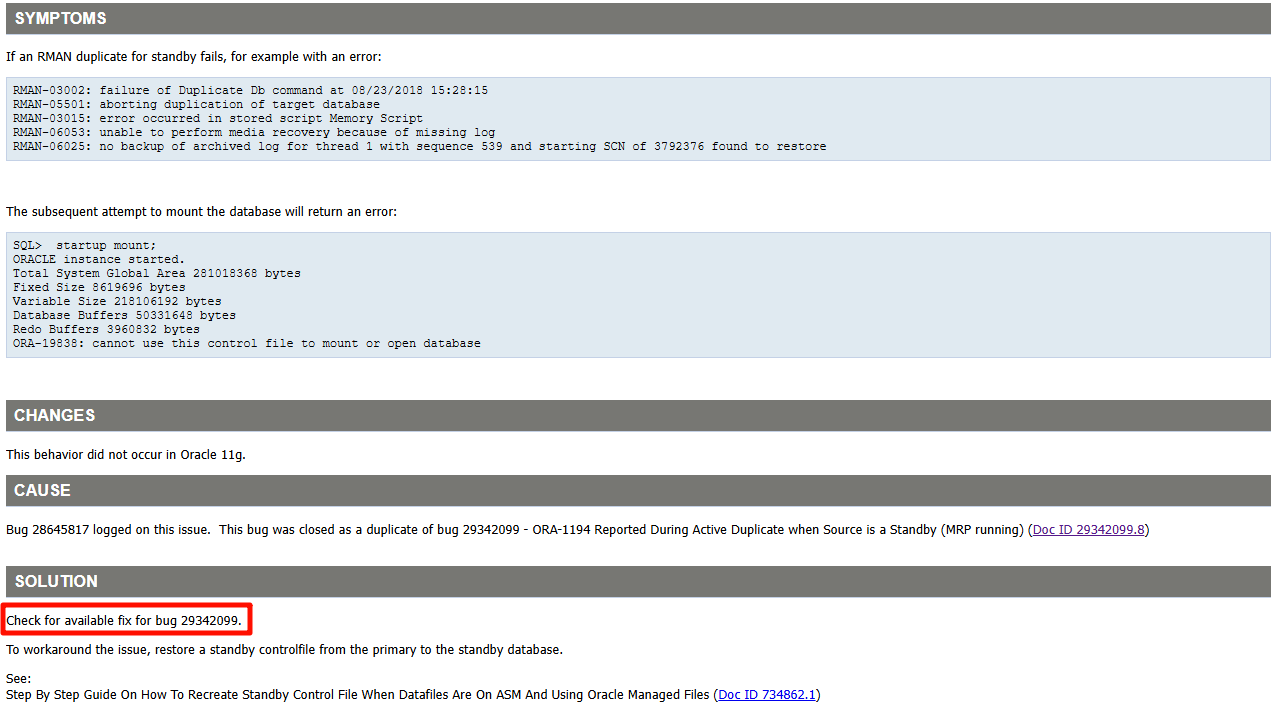
但是数据库版本是 19.24,应该已经包括了这个 BUG 修复:

根据 MOS 提示:
To workaround the issue, restore a standby controlfile from the primary to the standby database.
参考以下几篇文档:
- Step By Step Guide On How To Recreate Standby Control File When Datafiles Are On ASM And Using Oracle Managed Files (Doc ID 734862.1)
- Manual Completion of a Failed RMAN Backup Based Duplicate (Doc ID 360962.1)
- Manual completion of RMAN DUPLICATE(ACTIVE DUPLICATE) from STANDBY as TARGET (Doc ID 3009037.1)
- Manual Completion of a Failed RMAN Duplicate FROM ACTIVE DATABASE (Doc ID 1602916.1)
解决方案
重建备库控制文件:
SQL> alter session set tracefile_identifier='control_create';
SQL> alter database backup controlfile to trace resetlogs;
在 diag 跟踪目录中,找到上方命令创建的跟踪文件,名称中包含 ‘control_create’,编辑跟踪文件,删除所有除 create controlfile 命令之外的信息,将更改保存到 SQL 文件:
cat<<-EOF>/home/oracle/create_aux_controlfile.sql
EOF
关闭备库,启动数据库实例到 nomount 状态,执行重建控制文件 SQL:
shu immediate startup nomount @/home/oracle/create_aux_controlfile.sql
使用以下命令检查数据文件:
alter session set nls_date_format = 'DD-MON-RRRR HH24:MI:SS';
select status,checkpoint_change#,checkpoint_time, count(*),fuzzy from v$datafile_header
group by status,checkpoint_change#,checkpoint_time, fuzzy;
打开并恢复辅助数据库:
RMAN> {
set until scn 36836414202;
recover
standby
clone database
delete archivelog
;
}
至此,备库可以正常打开。
写在最后
后来我又想了一下,有可能是因为 Veeam 在备份的时候,把归档日志删除了,导致 Dup 过程中无法获取到所需的归档日志,所以才恢复失败的。
看了下 Veeam 的配置策略:

并且是昨天晚上 11 点多执行成功的:

也就是说当 duplicate 需要归档日志进行恢复的时候,归档日志已经从 ASM 磁盘组中被删除,我怀疑有可能是这个原因导致的 Duplicate 失败,还需要进行实验验证。
