






PostgreSQL 18 重磅来袭
系统级性能提升
进一步提升开发者体验
-- 生成时间戳排序的UUIDSELECT uuidv7();-- 结果示例:01980de8-ad3d-715c-b739-faf2bb1a7aad-- 提取时间戳信息SELECT uuid_extract_timestamp(uuidv7());-- 结果示例:2025-06-21 10:20:28.549+01
高可用环境和主版本升级时的逻辑复制增强功能
更多安全性和操作管理选项

什么是 PolarDB for PostgreSQL 版
为什么选择使用阿里云 PolarDB-PG 18
服务端支持 GBK/GB18030 字符集,可以更好地服务于各类对字符集有要求的系统。 TDE,透明数据加密功能,可以提供更好的数据安全保障。 GPC,全局计划缓存,将查询计划缓存放置在全局内存中,可以减少计划占用的内存。 监控系统,可以监控全链路的 DB 监控,包括存储、CPU、内存等硬件资源,DB 年龄、复制延迟、缓冲层等 DB 资源监控,SQL 等待事件、高频 SQL、慢 SQL 等 SQL 级监控。 此外还有大量在低版本 PolarDB-PG 的企业级功能正在向 18 版本进行移植,包括 Serverless、冷热分层存储、分布式等。
Ganos:阿里云自主研发的一套 时空数据库引擎,它专注于高效存储、管理和分析带有时间和空间维度的大规模数据,广泛应用于智慧城市、交通调度、物联网(IoT)、地理围栏、移动轨迹分析、环境监测等领域。 pgvector:把“向量检索”以原生数据类型 + 索引 + 函数的方式无缝嵌入到 PolarDB 中。让传统关系型数据库也能高效执行 K 近邻(KNN)搜索、近似最近邻(ANN)搜索、向量聚类 过滤 相似度 join 等 AI 场景常见操作,而不需要再把数据搬到专门的向量数据库。 包含 hypopg,ip4r,mysql_fdw,pase,pgaudit,pg_bigm,pg_cron,pg_hint_plan,pgjwt,pg_net,pg_similarity,pgsodium,pg_stat_kcache,pgtap,pldebugger,postgres-decoderbufs,prefix,roaringbitmap,sequential_uuids,varbitx,vault,wal2json,zhparser,oss_fdw,tds_fdw,smlar,log_fdw,pg_jieba,oracle_fdw,postgresql-hll 等 30 +个常用插件。 此外还有大量多模(图,数据湖,列存、全文)、时序(timescaledb、ganos_tsdb)、向量、AI ( polar_ai)等插件即将发布。
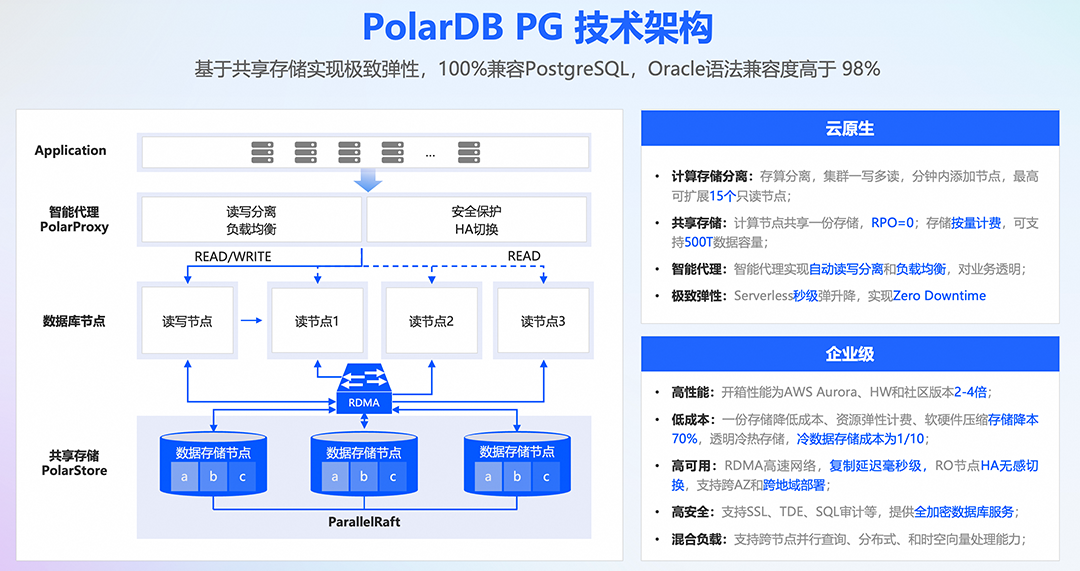
计算节点和存储分离:多个计算节点共享存储,新增只读节点时只需支付计算节点费用,大大降低扩容成本。 Serverless存储:存储空间无需手动配置,根据数据量自动伸缩,您只需为实际使用的数据库容量付费。
深度优化数据库内核,使用 PGO、BOLT、LTO、代码段大页等系统级优化手段,提升代码的执行效率。 支持表大小缓存,大幅减少原生 PG 内文件的 open/lseek 操作。 支持批量文件读取、批量文件扩展、批量刷脏,优化 IO 性能,并进行了深入的参数调优,提供了极致性能。 采用物理复制、RDMA高速网络和分布式共享存储,大幅提高性能。 集群包含一个主节点和最多15个只读节点,满足高并发场景对性能的要求,尤其适用于读多写少的场景。 基于共享存储的一写多读集群,数据只需要一次修改,所有节点立即生效。 大幅提升OLTP性能,支持超过50万次/秒的读请求以及超过15万次/秒的写请求。
共享分布式存储的设计,彻底解决了主从(Master-Slave)异步复制所带来的备库数据非强一致的缺陷,使得整个数据库集群在应对任何单点故障时,可以保证数据零丢失。 多可用区架构,在多个可用区内都有数据备份,为数据库提供容灾和备份。 集群地址利用LSN(Log Sequence Number)确保读取数据时的全局一致性,避免因为主备延迟引起的不一致。 利用基于Redo的物理复制代替基于Binlog的逻辑复制,提升主备复制的效率和稳定性。即使对大表进行加索引、加字段等DDL操作,也不会造成数据库的延迟。 采用白名单、VPC网络、数据多副本存储等全方位的手段,对数据库访问、存储、管理等各个环节提供安全保障。
配置升降级,5分钟生效。
增减节点,5分钟生效。
使用开通说明
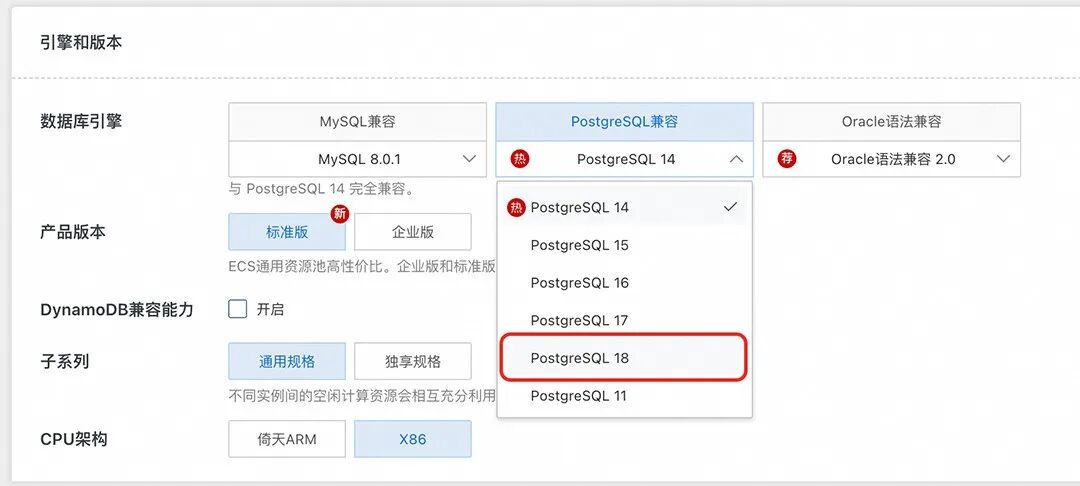
开通步骤
紧急程度选择 产品使用咨询; 问题描述填写 PolarDB-PG 18 申请加白试用,并附上阿里云的主账号 ID(鼠标悬浮在控制台右上角的头像上会自动展示出来); 产品分类选择 云原生数据库 PolarDB; 其他选项按需进行填写。


点击 阅读原文 了解云原生数据库PolarDB

文章转载自阿里云瑶池数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
