




Oracle数据库的正则表达式引擎支持多种元字符,用户可以利用正则表达式来对数据库中的字符串数据进行操作、提取和修改,功能十分强大。作为与Oracle生态兼容的数据库产品,Halo数据库在语法规范和功能上均实现了极致兼容。
1. 正则表达式基础
1.1 基础元字符
元字符是正则表达式中具有特殊含义的字符,它们赋予了正则表达式强大的模式匹配能力。Oracle 正则表达式支持多种元字符,Halo数据库完全兼容这些元字符,这些元字符可以分为以下几类。
1.1.1字符匹配元字符
.(点号):匹配任何字符(除了 NULL)
\d:匹配数字字符,等价于 [0-9]
\D:匹配非数字字符,等价于 [^0-9]
\w:匹配单词字符,包括字母、数字和下划线,等价于 [a-zA-Z0-9_]
\W:匹配非单词字符,等价于 [^a-zA-Z0-9_]
\s:匹配空白字符,包括空格、制表符、换行符等
\S:匹配非空白字符
1.1.2重复限定元字符
*:匹配前面的字符或子表达式零次或多次,等价于{0,}
+:匹配前面的字符或子表达式一次或多次,等价于{1,}
?:匹配前面的字符或子表达式零次或一次,等价于{0,1}
{m}:精确匹配前一个元素 m 次
{m,}:至少匹配前一个元素 m 次
{m,n}:匹配前一个元素 m 到 n 次(包括 m 和 n)
1.1.3锚点元字符
^:匹配字符串的开头,在多行模式下匹配任何行的开头
$:匹配字符串的结尾,在多行模式下匹配任何行的结尾
1.1.4分组和引用元字符
():用于分组和捕获匹配的内容。例如,(ab)+匹配 "ab"、"abab" 等
\num:后向引用,匹配第 num 个分组的内容(num 为 1-9 的数字)
1.1.5特殊功能元字符
|:分支操作符,用于指定选择性匹配项,表示或操作。例如,apple|banana匹配 "apple" 或 "banana"
[]:字符类,匹配列表中的任何字符。例如:[abc]:匹配 "a"、"b" 或 "c" 中的任意一个字符
[^]:否定字符类,匹配不在列表中的任何字符。例如:[^abc]:匹配除 "a"、"b"、"c" 外的任意字符。
元字符组合可创建复杂强大的模式,如正则表达式 "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$" 可用于验证电子邮件地址,确保格式正确。需要注意的是,元字符在正则表达式中有特殊含义,如果需要匹配元字符本身,必须使用反斜杠进行转义。例如,要匹配点号字符,需要使用 "\.";要匹配星号字符,需要使用 "\*"。
1.2 转义字符规则
在 Oracle 正则表达式中,转义字符规则用于规范特殊含义字符的处理方式,Halo数据库实现了对Oracle转义字符规则的完整兼容。反斜杠“\”作为正则表达式的转义字符,其具体含义取决于上下文,主要包括以下四种:表示字符本身、引用后续字符、引入运算符或不执行任何操作。
转义特殊字符是转义字符最常见的用途。在正则表达式中,有许多字符具有特殊含义,如.、*、+、?、^、$、|、{、}、[、]、(、) 等。如果需要匹配这些字符本身,必须使用反斜杠进行转义。例如,要匹配点号字符,需要使用 "\.";要匹配星号字符,需要使用 "\*"。
转义反斜杠本身是一个特殊情况。由于反斜杠本身是转义字符,如果需要匹配反斜杠字符,必须使用双倍转义,即 "\\"。这是因为第一个反斜杠用于转义第二个反斜杠,使其失去特殊含义,从而匹配反斜杠字符本身。
转义序列是反斜杠的另一个重要用途。通过反斜杠可以引入一些预定义的转义序列,这些序列代表特定的字符或字符类:
\d:数字字符(等价于 [0-9])
\D:非数字字符(等价于 [^0-9])
\w:单词字符(等价于 [a-zA-Z0-9_])
\W:非单词字符(等价于 [^a-zA-Z0-9_])
\s:空白字符
\S:非空白字符
Perl 风格的转义序列:Halo数据库还支持Oracle的 Perl 风格的转义序列:
\A:仅匹配字符串的开头
\Z:仅匹配字符串的结尾
\z:仅匹配字符串的结尾(与 \Z 类似)
1.3 POSIX 字符类支持
POSIX 字符类是 Oracle 正则表达式的一个重要特性,它提供了一组预定义的字符类,可以方便地进行字符匹配。POSIX 字符类以 [: 开头,以:] 结尾,中间包含一个或多个字符,代表特定的字符集合。Halo也支持 POSIX 字符类,具体包括:
1.3.1字母数字类
[:alnum:]:字母数字字符,等价于 [a-zA-Z0-9]
[:alpha:]:字母字符,等价于 [a-zA-Z]
1.3.2数字类
[:digit:]:数字字符,等价于 [0-9]、\d
1.3.3空白类
[:space:]:空白字符,包括空格、制表符、换行符、回车符、垂直制表符和换页符
1.3.4大小写字母类
[:lower:]:小写字母字符,等价于 [a-z]
[:upper:]:大写字母字符,等价于 [A-Z]
1.3.5可打印字符类
[:print:]:可打印字符(包括字母、数字、标点符号和空格)
1.3.6标点符号类
[:punct:]:标点字符
1.3.7控制字符类
[:cntrl:]:控制字符(不可打印)
1.3.8其他字符类
[:xdigit:]:十六进制数字字符,等价于 [0-9a-fA-F]
[:graph:]:图形字符(可打印且不是空格)
[:blank:]:空白字符(空格和制表符)
这些POSIX 字符类可以与其他元字符组合使用,以创建更复杂的模式。例如,正则表达式 "^[[:alpha:]][[:alnum:]_]*$" 可以用于验证变量名,确保其以字母数字(注:不包括下划线_)开头,后面跟字母、数字或下划线。
2. 正则核心函数介绍
2.1 REGEXP_LIKE 函数
2.1.1 函数语法与参数
REGEXP_LIKE 函数用于判断一个字符串是否匹配指定的正则表达式。返回布尔值(TRUE 或 FALSE),表示源字符串是否匹配正则表达式模式。
函数语法:
REGEXP_LIKE(source_string, pattern [, match_parameter])
参数说明:
source_string:字符表达式,用作搜索值。
pattern:正则表达式模式。
match_parameter(可选):文本字面量,用于更改函数的默认匹配行为。可以指定以下一个或多个值:
'i':指定不区分大小写的匹配。
'c':指定区分大小写的匹配(默认值)。
'n':允许匹配任何字符的运算符来匹配换行符。允许句点 (.) 匹配换行符。
'm':将源字符串视为多行处理。将 ^ 和 $ 分别解释为源字符串中任意行的开头和结尾,而不仅仅是整个源字符串的开头或结尾。如果省略此参数,将源字符串视为单行。
支持组合使用多个匹配选项。例如,'imn' 表示不区分大小写、多行模式并允许句点匹配换行符。需注意,若指定多个冲突选项,Oracle 将采用最后一个值。例如,'ic' 会被解释为 'c'(区分大小写)。
2.1.2 测试示例
以下是一些使用 REGEXP_LIKE 函数的应用示例:
示例 1:检查IP地址格式
SELECTCASE WHEN REGEXP_LIKE('192.168.1.1', '((2(5[0-5]|[0-4]\d))|(1\d{2})|([1-9]?\d))(\.((2(5[0-5]|[0-4]\d))|(1\d{2})|([1-9]?\d))){3}')THEN '有效IP' ELSE '无效IP' END AS ip_checkFROM dual;
正则表达式验证IPv4地址格式:四个1-3位数字用点分隔。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

示例 2:验证身份证号码有效性
SELECTCASE WHEN REGEXP_LIKE('11010119900101123X','^[1-9]\d{5}(19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}[\dXx]$')THEN '有效身份证' ELSE '无效身份证' END AS id_card_checkFROM dual;
正则表达式包含多个分组:^[1-9]\d{5}匹配前6位地址码(首位不为0),(19|20)\d{2}匹配1900-2099年份范围,(0[1-9]|1[0-2])匹配有效月份01-12,(0[1-9]|[12]\d|3[01])匹配有效日期01-31,\d{3}[\dXx]$匹配顺序码和校验码(允许数字或X)。执行结果验证18位身份证号码格式正确性。执行结果显示,Halo与Oracle在身份证号码验证场景下返回结果完全一致。

2.2 REGEXP_INSTR 函数
2.2.1 函数语法与参数
REGEXP_INSTR 函数用于返回字符串中匹配正则表达式的子串的起始或结束位置。
函数语法:
REGEXP_INSTR(source_string, pattern [, position [, occurrence [, return_option [, match_option]]]])
参数说明:
source_string:字符表达式,用作搜索值。
pattern:正则表达式模式。
position(可选):正整数,表示开始搜索的位置。默认值为 1,表示从 source_string 的第一个字符开始搜索。
occurrence(可选):正整数,表示返回的是第几次出现。默认值为1,表示搜索 pattern 的第一个匹配项。
return_option(可选):数字值,指示返回匹配项的开始位置还是结束位置:
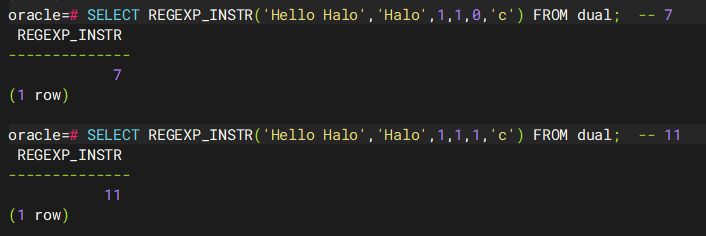
0(默认值):返回匹配模式的起始位置。例如,如果源字符串是 "Hello Halo",正则表达式是 "Halo",则返回 7,因为 "Halo" 从第 7 个字符开始。
1:返回匹配模式的结束位置之后的位置。例如,对于同样的例子,"Halo" 的结束位置是第 10 个字符(假设空格也算一个字符),则返回 11。
match_option(可选):与 REGEXP_LIKE 函数相同的匹配选项:'i'(不区分大小写)、'c'(区分大小写)、'n'(允许。匹配换行符)、'm'(多行模式)。
SELECT REGEXP_INSTR('Hello Halo','Halo',1,1,0,'c') FROM dual; -- 7SELECT REGEXP_INSTR('Hello Halo','Halo',1,1,1,'c') FROM dual; -- 11
2.2.2 测试示例
以下是一些使用 REGEXP_INSTR 函数的应用示例:
示例 1:查找特定模式的多次出现
SELECT REGEXP_INSTR('Halo 羲和数据库 DataBase 羲和数据库', '[a-zA-Z]+', 1, 2) AS second_num FROM DUAL;
这个查询字符串中第二个英文字母序列的位置。第一个英文字母序列是"'Halo",第二个是"DataBase"。查询返回12,因为"DataBase"从第12个字符开始。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

示例 2:查找模式结束后的位置
SELECT REGEXP_INSTR('abc123def', '\d+', 1, 1, 1) AS end_pos FROM DUAL;
查询返回数字序列结束后的位置(return_option=1)。数字序列 "123" 结束于第 6 个字符,所以返回 7。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

2.3 REGEXP_SUBSTR 函数
2.3.1 函数语法与参数
REGEXP_SUBSTR 函数用于从字符串中提取匹配正则表达式的子串。
函数语法:
REGEXP_SUBSTR(source_string, pattern [, position [, occurrence [, match_option [, subexpr]]]])
参数说明:
source_string:字符表达式,用作搜索值。
pattern:正则表达式。
position(可选):正整数,表示开始搜索的位置。默认值为1,表示从 source_string 的第一个字符开始搜索。
occurrence(可选):正整数,表示返回的是第几次出现。默认值为1,表示搜索 pattern 的第一个匹配项。
match_option(可选):与 REGEXP_LIKE 函数相同的匹配选项:'i'(不区分大小写)、'c'(区分大小写)、'n'(允许。匹配换行符)、'm'(多行模式)。
subexpr(可选):正整数,取值0到9,表示要返回的子表达式。允许指定返回第几个子表达式的内容。默认值为 0,表示返回整个匹配的子字符串。
2.3.2 测试示例
以下是一些使用 REGEXP_SUBSTR 函数的应用示例:
示例 1:提取URL域名
SELECT REGEXP_SUBSTR('http://www.halodbtech.com/','^(https?://)?([^/]+)',1,1,'c',2) AS domin FROM dual;
正则表达式包含两个分组,第一个分组:(https?://)匹配http或https协议,第二个分组:([^/]+)匹配域名。subexpr=2,只返回了第二分组域名部分,忽略协议部分。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

示例 2:提取电子邮件地址信息
SELECT REGEXP_SUBSTR('Halo羲和数据库邮箱:yijingkeji@halodbtech.com','([a-zA-Z0-9\._%-]+)@([a-zA-Z0-9\.-]+\.[a-zA-Z]{2,})',1,1,'c',1) AS username,REGEXP_SUBSTR('Halo羲和数据库邮箱:yijingkeji@halodbtech.com','([a-zA-Z0-9\._%-]+)@([a-zA-Z0-9\.-]+\.[a-zA-Z]{2,})',1,1,'c',2) AS domin,REGEXP_SUBSTR('Halo羲和数据库邮箱:yijingkeji@halodbtech.com','([a-zA-Z0-9\._%-]+)@([a-zA-Z0-9\.-]+\.[a-zA-Z]{2,})',1,1,'c',0) AS email FROM dual;
正则表达式包含两个捕获组,第一个捕获组 ([a-zA-Z0-9\._%-]+)用于匹配邮箱用户名部分(@之前),第二个捕获组 ([a-zA-Z0-9\.-]+\.[a-zA-Z]{2,})用于匹配域名部分(@之后)。subexpr=1时,返回了第1捕获组邮箱用户名部分。subexpr=2时,返回了第2捕获组邮箱域名部分。subexpr=0时,返回整个匹配的子字符串,即电子邮件地址全称。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

2.4 REGEXP_REPLACE 函数
2.4.1 函数语法与参数
REGEXP_REPLACE 函数用于搜索并替换匹配正则表达式的字符串部分。
函数语法:
REGEXP_REPLACE(source_string, pattern [, replace_string [, position [, occurrence [, match_option]]]])
参数说明:
source_string:字符表达式,用作搜索值。
pattern:正则表达式模式。
replace_string(可选):用于替换匹配模式的字符串。使用\n(n为数字 1 - 9)来引用正则表达式中的分组,这些引用指向正则表达式中相应分组匹配的内容。如果 replace_string 为空或省略,则匹配的内容将被删除。
position(可选):正整数,表示开始搜索的位置。默认值为 1,表示从 source_string 的第一个字符开始搜索。
occurrence(可选):正整数,表示返回的是第几次出现。默认值为 0,表示替换所有匹配项。
match_option(可选):与 REGEXP_LIKE 函数相同的匹配选项:'i'(不区分大小写)、'c'(区分大小写)、'n'(允许。匹配换行符)、'm'(多行模式)。
2.4.2 测试示例
以下是一些使用 REGEXP_REPLACE 函数的应用示例:
示例 1:格式化日期字符串
SELECT REGEXP_REPLACE('2025-10-20, 2025/10/21, 20251022', '([0-9]{4})\W*([0-9]{2})\W*([0-9]{2})', '\3/\2/\1',1,0) AS formatted_date FROM dual;
正则表达式定义了三个分组:年、月、日,并利用反向引用\1\2\3将日期重新排列为指定格式。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

示例 2:提取 URL 域名
SELECT REGEXP_REPLACE('http://www.halodbtech.com/news', '^[^/]+//([^/:]+).*$', '\1', 1, 1, 'c') AS clean_domain FROM dual;
正则表达式:[^/]+// 匹配协议部分,([^/:]+)捕获域名(排除端口和路径),替换为第一分组。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

示例 3:删除 HTML 标签
SELECT REGEXP_REPLACE('<span class="red" id="text1">Halo</span>: <span style="color:blue">羲和数据库</span>', '<[^>]*>', '') AS cleaned_text FROM dual;
这个查询删除字符串中的所有 HTML 标签。正则表达式 '<[^>]+>' 匹配尖括号内的任何内容,替换为空字符串,从而删除标签。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

2.5 REGEXP_COUNT 函数
2.5.1 函数语法与参数
REGEXP_COUNT 函数用于统计字符串中匹配正则表达式的次数。
函数语法:
REGEXP_COUNT(source_string, pattern [, position [, match_option]])
参数说明:
source_string:字符表达式,用作搜索值。
pattern:正则表达式模式。
position(可选):正整数,表示开始搜索的位置。默认值为 1,表示从 source_string 的第一个字符开始搜索。
match_option(可选):与 REGEXP_LIKE 函数相同的匹配选项:'i'(不区分大小写)、'c'(区分大小写)、'n'(允许。匹配换行符)、'm'(多行模式)。
2.5.2 测试示例
以下是一些使用 REGEXP_COUNT 函数的应用示例:
示例 1:统计元音字母的数量
SELECT REGEXP_COUNT('Hello Halo', '[aeiouAEIOU]') AS vowel_count FROM DUAL;
这个查询统计字符串中元音字母的数量。正则表达式匹配任何大小写的元音字母。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

示例 2:统计特定单词出现的次数
SELECTREGEXP_COUNT('ABCabcABC', 'abc') AS case_sensitive_count,REGEXP_COUNT('ABCabcABC', 'abc', 1, 'i') AS case_insensitive_countFROM dual;
第一个:区分大小写,只匹配小写'abc'一次。第二个:不区分大小写,匹配所有'abc'(包括大小写变体)3次。执行结果如下图所示,Halo与Oracle的行为结果保持一致。

3. 总结
Halo数据库在兼容Oracle正则表达式方面表现优异,实现了功能上的极致兼容。随着技术不断进步、生态持续完善,Halo将在企业数字化转型中发挥更为重要的作用,为国内的信创事业作出更大贡献。
