





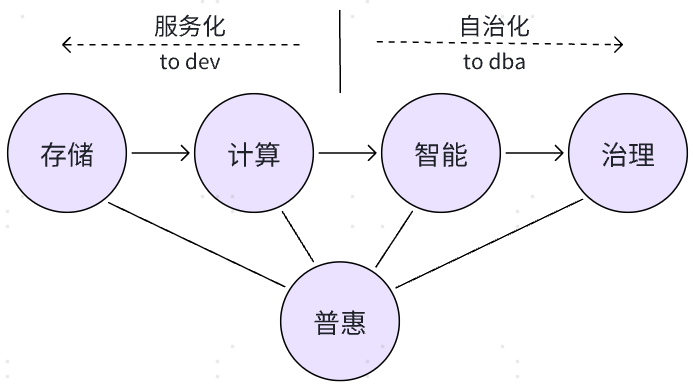
我们正置身于一个数据核聚变的时代。全球数据总量正以指数级攀升,据IDC等权威机构预测,到2025年,全球新创建的数据量将超过175ZB。这股奔涌的数据洪流,既是数字经济的新石油,也对承载和管理它们的核心基础设施——数据库,提出了前所未有的挑战与机遇。回首数据库发展历程,从最初的文件系统到关系型数据库一统天下,再到互联网时代NoSQL/NewSQL的百花齐放,其演进速度从未像近十年这般迅猛。细观当前数据库领域的技术脉络,我们可以清晰地梳理出五大核心发展趋势,我们将其概括为“存、算、智、理、惠”五个维度。这五个字不仅代表了数据库技术进化的五个关键方向,更勾勒出未来数据基础设施的整体蓝图。
存(存储):是数据库的根基,关乎数据如何被最有效、最可靠、最多元地承载。其演进方向是向着更合理的模型、更巨大的规模、更丰富的类型持续突破。
算(计算):是数据库的灵魂,关乎数据如何被高效、精准、灵活地处理。其趋势正从分化走向融合,从单一走向多元,甚至重新定义“计算”的边界。
智(智能):是数据库的升华,意味着数据库从被动的“数据保管员”向主动的“价值挖掘者”转变。AI与数据库的深度耦合,正催生新一代的数据智能平台。
理(治理):是数据库的骨架,确保数据资产的可控、可信、可用。治理能力正从“外挂式”工具向数据库内核“内嵌式”能力演进,实现由内而外的合规与高效。
惠(普惠):是数据库的愿景,旨在通过云原生、Serverless、开源等模式,将强大的数据能力转化为随需所用、按需付费的公共服务,极大降低技术创新门槛。
如果说人类文明的传承始于记录,那么数据库的雏形便可追溯至古老的“结绳记事”。其本质,便是寻找一个可靠、可解读的载体来存储信息。数据库诞生至今,其最根本的使命从未改变:如何更好地存储数据。数十年来,数据库在存储层面的创新主要围绕三个方面:更合理的存储模型、更大规模的数据存储以及存储数据类型的多元性。
1).存储模型演进:关系型的永恒与超越
2).存储规模突破:分布式架构开启“海量”之门
3).存储类型多元:“一专多能”多模数据库兴起
随着应用场景的复杂化,我们发现现实世界的数据类型是丰富多彩的,远非“结构化”一词可以概括。社交网络中的好友关系是复杂的图结构,物联网设备产生的则是带时间戳的时序数据,推荐系统依赖的是高维向量,内容缓存需要极低延迟的Key-Value存储,而产品目录可能是半结构化的JSON文档。尽管关系模型强大,但用它来存储和查询图关系或时序数据,就如同用螺丝刀去切菜,虽能勉强为之,却远非最优解,会带来极差的性能和复杂的查询。于是,多模数据库(Multi-Model Database) 应运而生,成为存储技术发展的前沿。它们在一个统一的数据库内核中,原生支持多种数据模型(如文档、图、KV、时序、向量等)。用户可以根据业务需求,为不同的数据选择最合适的存储和查询方式,同时享受统一运维、数据强一致性和跨模型事务的好处。
如果说“存”定义了数据的静态格局,那么“算”则赋予了数据动态的生命力,是数据库的灵魂所在。数据库的计算能力,直接决定了数据价值被挖掘的效率和深度。近年来,数据库在计算层面呈现出显著的“归流”与“聚变”特征:在计算接口上,SQL语言经历了否定之否定,展现出王者归来的大一统趋势;在计算架构上,则从OLTP与OLAP的专业化分化,走向HTAP的深度融合。
1).SQL“王者归来”:计算接口大一统与增强
2).TP、AP与HTAP:计算架构的“分久必合”
3).计算范式扩展:AI即计算,重新定义边界
当数据的价值被日益重视,我们已不满足于仅仅“存储”和“查询”数据,而是希望数据能主动“思考”、“预测”和“决策”。人工智能,特别是机器学习和深度学习技术的成熟,为这一愿景提供了可能。数据库与AI的关系,正从简单的“数据供给方”与“计算引擎”的松散组合,升级为深度的“能力融合”,这场“双向奔赴”正在从两个层面重塑数据库的形态和职能。
1).层面:AI能力内化,数据库即AI算力引擎
2).层面:职能范围外延,从数据库到数据智能平台
当数据被确立为企业的核心战略资产,数据治理的重要性就已超越了技术范畴,成为关乎企业合规、风险控制和运营效率的管理必修课。然而,在传统的数据架构中,数据治理往往被视为一项独立于数据库的、“外挂式”的管理活动。企业需要采购一整套独立的数据治理工具套件,覆盖数据建模、元数据管理、数据质量、数据血缘、数据安全等多个方面。这种方式虽然功能看似专业,但常常面临与数据库内核“两张皮”的困境:集成复杂、标准不一、治理动作滞后且往往在事后进行,最终导致治理效果大打折扣,甚至因流程繁琐而阻碍业务敏捷性。
数据建模与架构治理内嵌:数据库可以在最源头的DDL层面就强化治理规则。例如,支持强制性的注释规范,自动生成业务元数据;在创建表或修改表结构时,可强制要求添加数据分类分级标签,为后续基于策略的安全控制打下坚实基础。 元数据、主数据与数据血缘自动化:数据库内核最了解数据的来龙去脉。它可以自动采集最基础、最准确的技术元数据(表结构、字段类型、约束、权限等)。通过解析SQL日志、执行计划和事务日志,可以自动生成精确到列级别的数据血缘图谱,清晰展示数据从何源表而来、经过哪些加工步骤(存储过程、视图、ETL任务)、流向何处。这种由数据库自身产生的血缘关系,远比外部工具通过扫描SQL脚本或日志进行推断要准确和高效得多,为影响分析、合规审计提供了可靠依据。 数据质量管控实时化:有效的治理不等于事后检查和补救。数据库可以在数据写入(INSERT/UPDATE)时,就通过内置的约束、触发器或可扩展的校验框架,对数据进行实时质量检查。例如,强制要求邮箱字段符合特定正则表达式,或通过调用外部服务验证身份证号、银行账号的合法性,实现“坏数据不进库”,从源头保障数据质量。 数据安全与合规内置化:安全是治理的底线,相关能力正以前所未有的深度融入数据库内核。除了传统的基于角色的权限控制(RBAC),还包括如:动态数据脱敏,在查询时根据用户角色和权限实时对敏感数据进行脱敏,无需在应用层进行复杂处理,保障数据可用不可见;细粒度访问控制,支持到行级和列级的安全策略,实现“千人千面”;数据加密:提供透明的静态数据加密以及在网络传输中的加密,并探索同态加密等先进技术,实现“数据可用不可见”的计算;完整审计,记录所有用户(包括管理员)对数据的访问、修改、删除行为,形成不可篡改的审计日志,满足GDPR、等保、数据安全法等合规要求。
数据价值的最终实现,必须落在广泛的“应用”上。如何让各行各业、不同规模的企业和个人开发者,都能以可承担的成本、便捷的方式享受到数据服务,从而激发全社会的数字创新能力?这就是“普惠”趋势要解决的核心问题。它贯穿于数据生命周期的所有环节(存、算、智、理),其本质是通过技术和商业模式的协同创新,不断降低数据技术的使用门槛和总拥有成本(TCO),实现数据能力的“民主化”。
1).云原生:资源供给模式的颠覆性革命
2).存、算、智、理层面的普惠性创新
存的普惠:多模数据库通过“一库多用”,降低了采购、学习和维护多种专用数据库的成本。 算的普惠:HTAP架构避免了维护OLTP和OLAP两套系统以及高昂的ETL成本,本身就是一种架构上的普惠。SQL语言的重新一统,极大降低了开发者的学习成本和不同系统间的集成成本。 智的普惠:数据库内置AI能力,让中小企业无需组建庞大的AI算法团队和搭建复杂的AI平台,就能快速入门和部署数据智能应用,大大降低了AI的使用门槛。 理的普惠:治理能力内嵌,让广大中小企业能用得起、用得好原来只有财力雄厚的大企业才玩得转的复杂数据治理工具,以较低成本建立起可信的数据资产体系。
除了“存算智理惠”这五大主干趋势外,未来数据库的图景还有一些不可或缺的“枝叶”,它们虽不直接对应核心技术能力,却深刻影响着技术的采纳效率和用户体验,其中以“服务化”和“自治化”最为突出。前者一方面提供更多开箱即用的高级功能,而非一个需要大量编码的“半成品”,如原生支持强大的全文搜索引擎、灵活的JSON/XML文档处理、地理空间信息处理、甚至轻量级的流处理能力;另一方面提供数据服务接口,将复杂的数据库管理能力封装为简单的API或服务接口,让开发者能像调用本地函数一样使用数据能力,无需深入底层细节。后者则通过AI和机器学习技术实现数据库自我驱动、自我修复、自我优化、自我安全,最大限度地减少甚至消除人工干预,迈向“零运维”的数据库“自动驾驶”时代,这类似于汽车从手动挡到自动挡,再到自动驾驶的演进。自治数据库将DBA从繁重、重复、高风险的日常运维劳动中解放出来,使其能转型专注于更高价值的数据库架构设计、容量规划、业务赋能和数据资产管理等工作。
“存、算、智、理、惠”五大趋势,并非孤立存在,而是相互交织、协同演进,共同勾勒出下一代数据库的完整面貌:它是一个能够存储海量、多模数据,融合计算、智能使能,内置强大治理能力,并能以普惠方式交付的一体化数据智能平台。
这场深刻的变革意味着,数据库的角色正从一个被动的、后台的“数据记录系统”,演变为一个主动的、战略性的“业务创新平台”。对于企业和开发者而言,深刻理解这些趋势,意味着能更好地规划自身的技术架构选型、团队技能培养和数据战略方向,在这场波澜壮阔的数据浪潮中抢占先机,构筑长期的数字化竞争力。
