





2025年9月,开源PolarDB-X正式发布v2.4.2版本,重点完善周边生态能力,包含:新增客户端驱动(PolarDB-X Connector)、新开源polardbx-proxy组件,同时面向数据库运维和稳定性优化,提供在千亿大表场景下的实践验证,包含DDL在线变更、数据库扩缩容、数据TTL等的多项问题修复。详细请查阅ChangeLog[1]。

PolarDB分布式版简介
PolarDB分布式版(简称“PolarDB-X”)是阿里云自主研发的云原生集中式和分布式一体化数据库产品,整体采用了基于存储计算分离的Shared-Nothing系统架构,支持水平扩展、分布式事务、混合负载等能力,具备金融级高可用、高吞吐、大存储、低延时、易扩展、高度兼容MySQL系统及生态等特点。更多产品能力与特性介绍可参考产品文档[2]。
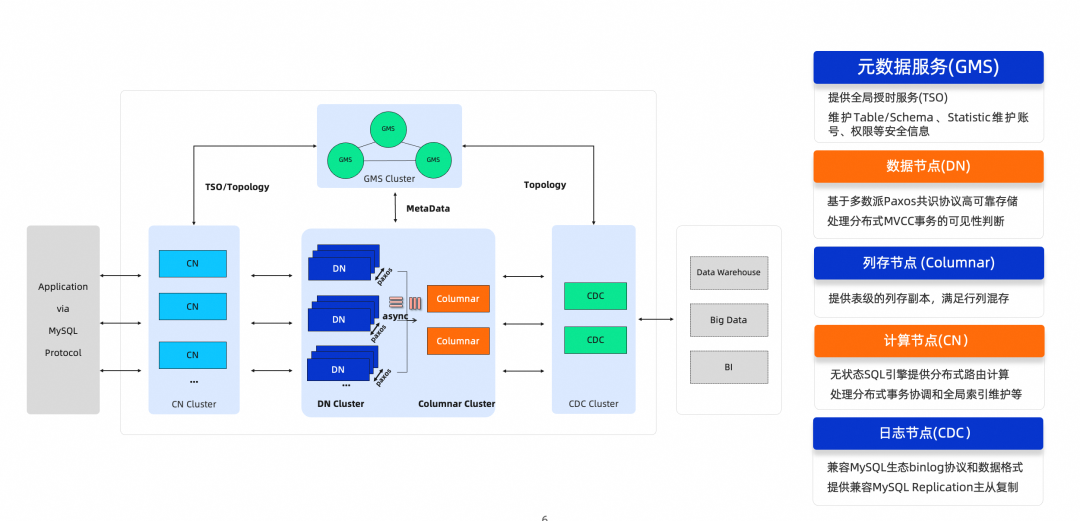 PolarDB分布式版产品架构
PolarDB分布式版产品架构
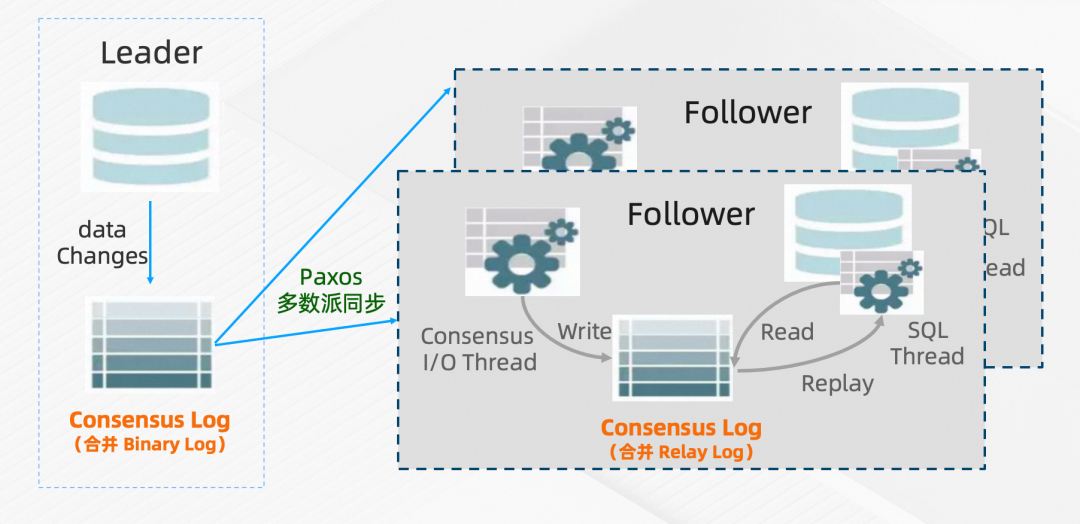
2021年10月,阿里云宣布对外开源云原生分布式数据库PolarDB-X,采用全内核开源的模式,开源内容包含计算引擎、存储引擎、日志引擎、列存引擎等,开源历程详见:云原生数据库PolarDB开源社区[3]。
开源PolarDB-X v2.4.2特性
新增开源polardbx-proxy组件
PolarDB-X Proxy是使用Java开发的高性能PolarDB-X标准版的代理,具备自动识别集群主节点、无感高可用切换、读写分离、实例级连接池等功能。可以部署于PolarDB-X标准版之前,提供更加简易便捷的使用体验。(开源地址[4])
读写分离 & 基于活跃请求数的负载均衡; 备库一致性读; 事务级连接池; 支持快速HA检测 & 幂等重试连接保持; 支持Prepared Statement性能提升 & 透传;
wget https://raw.githubusercontent.com/polardb/polardbx-proxy/refs/heads/main/polardbx-proxy/quick_start.sh
quick_start.sh -e backend_address=127.0.0.1:3306 -e backend_username=appuser -e backend_password=appuser -e memory=4294967296
backend_address: 数据库地址(格式:ip:port,leader或者follower的地址); backend_username: 数据库用户名; backend_password: 数据库密码(必须有密码,必须使用 mysql_native_password); memory: Proxy使用内存(单位B,请正确配置,否则可能会导致OOM,推荐 16GB,最少 4GB);
mysql -Ac -h127.1 -P3307 -uappuser -pappuser

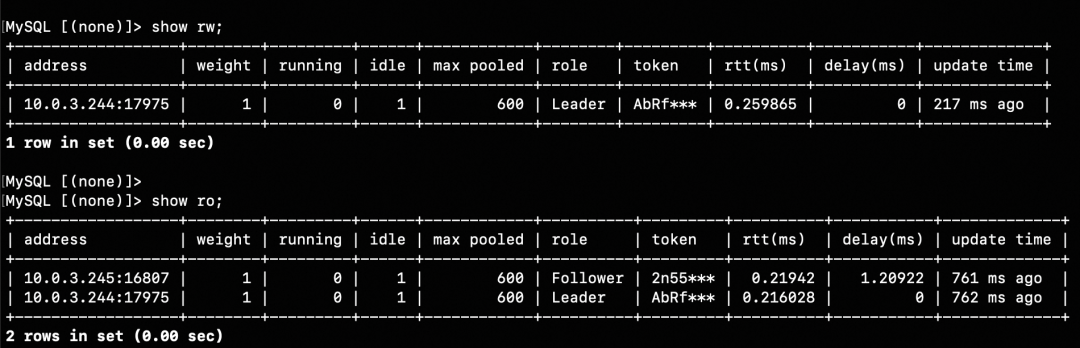
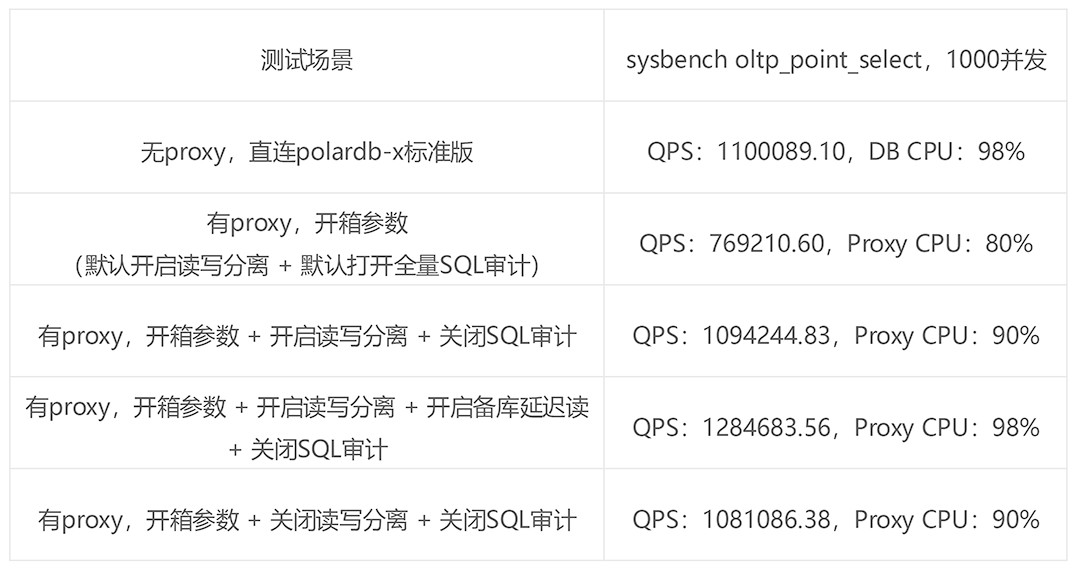
测试结论:
1. polardbx-proxy的整体的性能,可以转到单core 4万QPS;
2. 全量SQL审计,可以按需打开,部分影响性能;
JDBC/GO/C++客户端驱动
支持多语言驱动,包含JDBC、GO、C++; 直连PolarDB-X 2.0标准版,并提供在HA后自动连接新主节点的能力、以及提供无感切换能力; 直连PolarDB-X 2.0企业版,并实现多节点的负载均衡;
▶︎ 使用样例
以JDBC驱动为例,参考JDBC使用文档[5]。
<dependency>
<groupId>com.alibaba.polardbx</groupId>
<artifactId>polardbx-connector-java</artifactId>
<version>2.2.10</version>
</dependency>
jdbc:polardbx://11.167.60.147:6991/test
标准版三节点其中一个IP:port或者VIP:port,或者多个IP0:port0,IP1:port1(必须为同一集群中的节点,以英文逗号分隔),建连时会被路由到 leader 节点。 企业版其中一个IP:port或者VIP:port,或者多个IP0:port0,IP1:port1(必须为同一集群中的节点,以英文逗号分隔),建连时会负载均衡到集群中随机一个读写节点。
Class.forName("com.alibaba.polardbx.Driver");
try (final Connection conn = DriverManager.getConnection(
"jdbc:polardbx://127.0.0.1:3306/", "root", "*****");
final Statement stmt = conn.createStatement()) {
try (final ResultSet rs = stmt.executeQuery("select 1")) {
for (int i = 0; i < rs.getMetaData().getColumnCount(); ++i) {
System.out.print(rs.getMetaData().getColumnName(i + 1) + "\t");
}
System.out.println();
while (rs.next()) {
for (int i = 0; i < rs.getMetaData().getColumnCount(); ++i) {
System.out.print(rs.getObject(i + 1) + "\t");
}
System.out.println();
}
}
}
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="driverClassName" value="com.alibaba.polardbx.Driver" />
<!-- 基本属性 URL、user、password -->
<property name="url" value="jdbc:polardbx://ip:port/db?autoReconnect=true&rewriteBatchedStatements=true&socketTimeout=30000&connectTimeout=3000" />
<property name="username" value="root" />
<property name="password" value="123456" />
<!-- 配置初始化大小、最小、最大 -->
<property name="maxActive" value="20" />
<property name="initialSize" value="3" />
<property name="minIdle" value="3" />
<!-- maxWait 获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- timeBetweenEvictionRunsMillis 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- minEvictableIdleTimeMillis 一个连接在池中最小空闲的时间,单位是毫秒-->
<property name="minEvictableIdleTimeMillis" value="300000" />
<!-- 检测连接是否可用的 SQL -->
<property name="validationQuery" value="select 'z' from dual" />
<!-- 是否开启空闲连接检查 -->
<property name="testWhileIdle" value="true" />
<!-- 是否在获取连接前检查连接状态 -->
<property name="testOnBorrow" value="false" />
<!-- 是否在归还连接时检查连接状态 -->
<property name="testOnReturn" value="false" />
<!-- 是否在固定时间关闭连接。增加此参数可以均衡后端服务节点参数 -->
<property name="phyTimeoutMillis" value="600000" />
<!-- 是否在固定SQL使用次数之后关闭连接,增加此参数可以均衡后端服务节点参数-->
<property name="phyMaxUseCount" value="10000" />
</bean>
go get github.com/polardb/polardbx-connector-go
import (
_ "github.com/polardb/polardbx-connector-go"
)
db, err := sql.Open("polardbx", "user:password@tcp(ip:port)/dbname")
if err != nil {
panic(err)
}
db.SetConnMaxLifetime(time.Minute * 3)
db.SetMaxOpenConns(10)
db.SetMaxIdleConns(10)
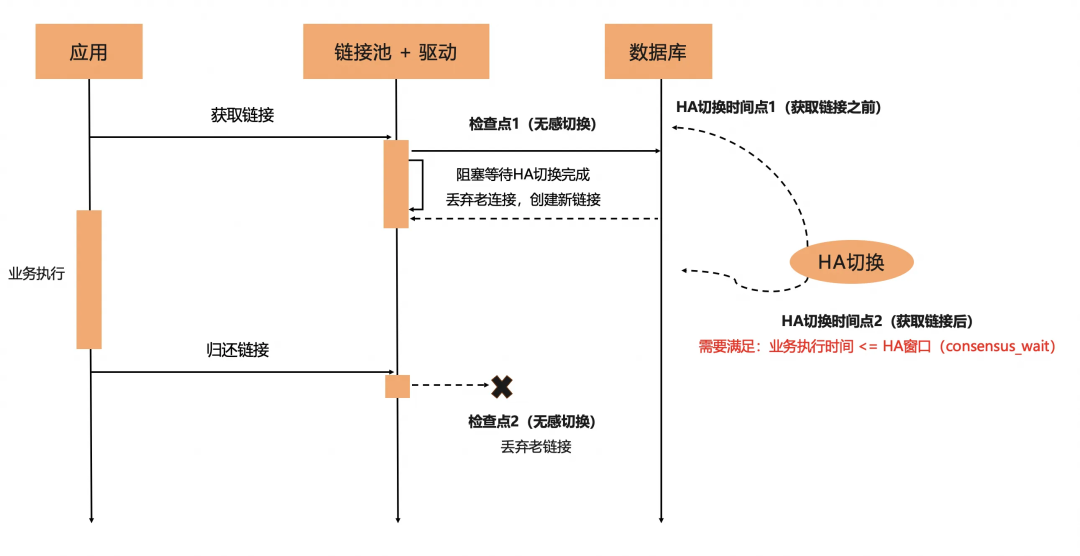
客户端驱动,阻塞分配连接返回,直到切换完成; 针对业务已经获取连接尽快完成请求,并标记其不可复用;
客户端驱动,新增两个无感切换的检查点(获取链接、归还链接),通过实时感知PolarDB-X标准版三节点集群状态,实现HA切换后链接的动态重建能力,仅增加了获取新连接时间,但不会导致已有连接上请求报错,实现计划切换时应用无感。 业务获取了数据库Connection链接,推荐使用标准try-with-resources实现的数据库操作,只要try块中的业务执行时间小于对应PolarDB-X设置的HA窗口(consensus_wait_millisecond_before_change_leader时间阈值,默认为1秒),就不会因为计划切换报错。而对于持有连接时长超出时间阈值的长事务,因为横跨切换流程,切换后会因为不能写入而报错。
目前PolarDB-X的无感切换能力,推荐链接池:Druid[6]>= 1.2.24版本。
适配开源MySQL的主备集群复制
自建MySQL迁移PolarDB-X,PolarDB-X提供了非常好的兼容性,目前用户最大的诉求是支持数据迁移、以及回流的标准方案。PolarDB-X在商业化版本,提供了专业的数据迁移和同步工具,比如阿里自研的DTS工具,官网完整说明见《解决方案:自建MySQL迁移至PolarDB-X》[7]。
▶︎ MySQL增量同步到PolarDB-X
1. 在主库MySQL上。
#1. 主库上创建主从复制使用的账户
create user rep identified with mysql_native_password by '123456';
grant replication slave on *.* to rep;
#2. 显示Master主机上已注册的复制主机列表
mysql> show slave hosts;
Empty set, 1 warning (0.00 sec)
#3.过滤掉不需要同步的系统库表,比如原有的心跳表等,
# 将下面参数配置到从库的cnf文件中重启生效
replicate_ignore_db=aaa:mysql
replicate_ignore_db=aaa:sys
replicate_ignore_db=aaa:__recycle_bin__
replicate_ignore_db=aaa:information_schema
replicate_ignore_db=aaa:performance_schema
#4. 在从库上停掉之前创建aaa链路
stop slave for channel 'aaa';
reset slave all for channel 'aaa';
#5. 配置主从复制链路aaa, master_host、master_port为主库的host和port,
#master_user为刚才创建的复制账户
change master to master_host = '127.0.0.1', master_port = 13050, \
master_user = 'rep', master_password = '123456', \
master_auto_position=1 \
for channel 'aaa';
#6. 查看该链路 Slave_IO_Running、Slave_SQL_Running都是No
show slave status for channel 'aaa'\G
#7. 在从库leader节点上启动aaa主从复制链路
start slave for channel 'aaa';
#8. 查看该链路 Slave_IO_Running、Slave_SQL_Running都是Yes
show slave status for channel 'aaa'\G
#9. 登陆主库显示Master主机上已注册的复制主机列表
mysql> show slave hosts;
+-----------+------+-------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+-------+-----------+--------------------------------------+
| 10 | | 13060 | 2 | 26663b57-91e6-11f0-8700-b8599f3009a8 |
+-----------+------+-------+-----------+--------------------------------------+
1row in set(0.00 sec)
#1. 查看最新binlog
mysql> show consensus logs;
+---------------+-----------+-----------------+
| Log_name | File_size | Start_log_index |
+---------------+-----------+-----------------+
| binlog.000001 | 15777 | 1 |
| binlog.000002 | 7611 | 44 |
+---------------+-----------+-----------------+
2rows in set(0.00 sec)
#2. 查看最新binlog的最后一行的End_log_pos
mysql> show binlog events in 'binlog.000002';
+---------------+------+--------------------------+-----------+-------------+--------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+---------------+------+--------------------------+-----------+-------------+--------------------------------------------------------------+
| binlog.000002 | 4 | Format_desc | 10 | 190 | Server ver: 8.0.32-X-Cluster-8.4.20-20241014, Binlog ver: 4 |
| binlog.000002 | 190 | Previous_consensus_index | 10 | 221 | ##PREV_CONSENSUS_INDEX: 44' |
| binlog.000002 | 221 | Previous_gtids | 10 | 332 | 37a1bb4b-91f9-11f0-b12d-b8599f3009a8:1-30,
902b4fe0-92a4-11f0-92ea-b8599f3009a8:1-11 |
.......
| binlog.000002 | 7580 | Xid | 3 | 7611 | COMMIT /* xid=237 */ |
+---------------+------+--------------------------+-----------+-------------+--------------------------------------------------------------+
78rows in set(0.00 sec)
#3.过滤掉不需要同步的系统库表,比如原有的心跳表等,
# 将下面参数配置到从库的cnf文件中重启生效
replicate_ignore_db=mysql
replicate_ignore_db=sys
replicate_ignore_db=__recycle_bin__
replicate_ignore_db=information_schema
replicate_ignore_db=performance_schema
#4. 在从库上停掉之前创建bbb链路
stop slave for channel 'bbb';
reset slave all for channel 'bbb';
#5. 配置主从复制链路bbb, master_host、master_port为主库的host和port,
#master_log_file、master_log_pos来自上面在主库上获取的值
change master to master_host = '127.0.0.1', master_port = 13050, \
master_user = 'rep', master_password = '123456', \
master_log_file='binlog.000002' \
master_log_pos=7611 \
for channel 'bbb';
#6. 查看该链路 Slave_IO_Running、Slave_SQL_Running都是No
show slave status for channel 'bbb'\G
#7. 在从库leader节点上启动bbb主从复制链路
start slave for channel 'bbb';
#8. 查看该链路 Slave_IO_Running、Slave_SQL_Running都是Yes
show slave status for channel 'bbb'\G
#9. 登陆主库显示Master主机上已注册的复制主机列表
mysql> show slave hosts;
+-----------+------+-------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+-------+-----------+--------------------------------------+
| 1 | | 13010 | 2 | 902b4fe0-92a4-11f0-92ea-b8599f3009a8 |
+-----------+------+-------+-----------+--------------------------------------+
1row in set(0.00 sec)
[mysqld]
expire_logs_days = 7
适配 MCP 开源生态
SQL 查询执行:AI代理可通过query接口直接运行SQL查询。 数据库状态监控:实时获取PolarDB-X集群状态(如QPS、慢 SQL 数、节点负载),辅助动态调优。 命令管理:提供PolarDB-X支持的运维和语法规范,供大模型使用。
Schema 信息查询:提供JSON格式的表结构信息,包括列名、数据类型及索引定义。示例:polardbx://<database_name>/<table_name> 支持AI Agent快速解析复杂表结构,生成上下文感知的查询建议。
智能数据库运维:AI Agent通过MCP Server获取数据库状态和Schema信息,自动诊断性能瓶颈(如数据分布不均、死锁)并生成修复建议。 Data Agent/Chat BI:通过SQL接口,连接PolarDB-X的只读实例,提供数据分析和报表服务 Vibe Coding/低代码开发:AI工具通过MCP Server的Schema查询接口,自动解析数据库结构、生成符合实际版本的代码片段;提供SQL执行接口,使AI工具自动校验SQL正确性。
# Install globally
npm install -g polardbx-mcp
# Or install in current project only
npm install polardbx-mcp
{
"mcpServers": {
"polardbx-mcp": {
"command": "npx",
"args": [
"polardbx-mcp"
],
"env": {
"POLARDB_X_HOST": "your_database_host",
"POLARDB_X_PORT": "your_database_port",
"POLARDB_X_USER": "your_database_user",
"POLARDB_X_PASSWORD": "your_database_password",
"POLARDB_X_DATABASE": "your_database_name"
},
}
}
}
总结
PolarDB坚持自主研发创新,100%兼容原生社区生态和主流数据库管理工具,支持同城灾备、异地灾备等多种容灾架构,兼容国产主流操作系统和芯片,获得信安中心权威认可,更多详情可以访问安全可靠的国产自研分布式数据库PolarDB[8]。
点击阅读原文了解云原生数据库PolarDB

