




什么是网关
随着互联网的快速发展,当前以步入移动互联、物联网时代。用户访问系统入口也变得多种方式,由原来单一的PC客户端,变化到PC客户端、各种浏览器、手机移动端及智能终端等。同时系统之间大部分都不是单独运行,经常会涉及与其他系统对接、共享数据的需求。所以系统需要升级框架满足日新月异需求变化,支持业务发展,并将框架升级为微服务架构。“API网关”核心组件是架构用于满足此些需求。
网关框架框架
1、基于nginx平台实现的网关有:KONG、API Umbrella
2、自研发的网关有:apigateway、Zuul
API网关设计
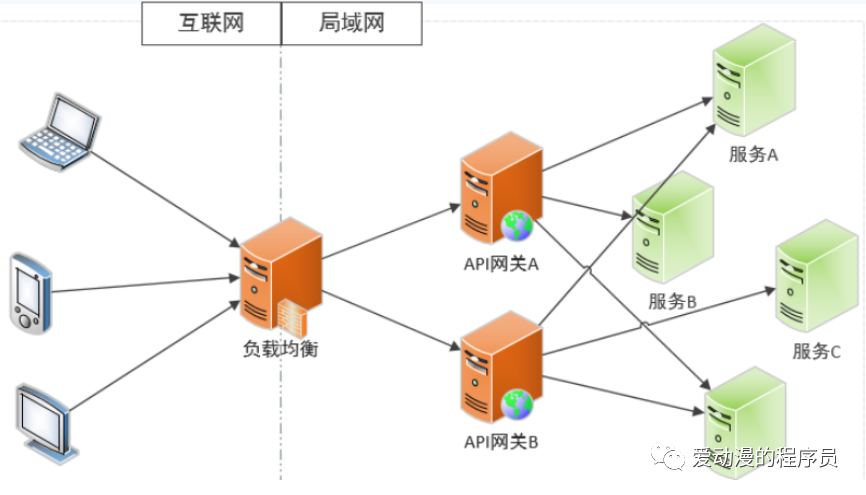
API网关是微服务架构(Microservices Architecture
)标准化服务的模式。API网关定位为应用系统服务接口的网关,区别于网络技术的网关,但是原理则是一样。API网关统一服务入口,可方便实现对平台众多服务接口进行管控,对访问服务的身份认证、防报文重放与防数据篡改、功能调用的业务鉴权、响应数据的脱敏、流量与并发控制,甚至基于API调用的计量或者计费等等。
微服务网关核心功能模拟实现
综上所述,微服务网关主要帮助我们屏蔽掉对服务的调用和请求处理的具体逻辑,所以我们通过模拟该功能的方式进行对微服务网关的理解.
首先,笔者所选定的注册中心为ZK,我们通过DiscoveryClient
的API
实现对服务提供方进行注册.
启动类代码:
1@SpringBootApplication
2@EnableDiscoveryClient
3@ServletComponentScan(basePackages = "com.gupao.micro.services.spring.cloud.gateway.servlet")
4@EnableScheduling
5public class SpringCloudServletGatewayApplication {
6
7 public static void main(String[] args) {
8 SpringApplication.run(SpringCloudServletGatewayApplication.class, args);
9 }
10
11 @Bean
12 public ZookeeperLoadBalancer zookeeperLoadBalancer(DiscoveryClient discoveryClient) {
13 return new ZookeeperLoadBalancer(discoveryClient);
14 }
15}
其中,EnableDiscoveryClient
注解默认注册中心为ZK,并且提供DiscoveryClient
APIgetInstances()
可以获取ZK中所有注册服务的列表.并在初始化ZookeeperLoadBalancer
Bean的时候,将所有的注册列表进行有效的维护.
1public class ZookeeperLoadBalancer extends BaseLoadBalancer {
2
3 private final DiscoveryClient discoveryClient;
4
5 private Map<String, BaseLoadBalancer> loadBalancerMap = new ConcurrentHashMap<>();
6
7 public ZookeeperLoadBalancer(DiscoveryClient discoveryClient) {
8 this.discoveryClient = discoveryClient;
9 //
10 updateServers();
11 }
12
13 @Override
14 public Server chooseServer(Object key) {
15 if (key instanceof String) {
16 String serviceName = String.valueOf(key);
17 BaseLoadBalancer baseLoadBalancer = loadBalancerMap.get(serviceName);
18 return baseLoadBalancer.chooseServer(serviceName);
19 }
20 return super.chooseServer(key);
21 }
22
23 /**
24 * 更新所有服务器
25 */
26 @Scheduled(fixedRate = 5000)
27 public void updateServers() {
28 discoveryClient.getServices().stream().forEach(serviceName -> {
29
30 BaseLoadBalancer loadBalancer = new BaseLoadBalancer();
31
32 loadBalancerMap.put(serviceName, loadBalancer);
33 List<ServiceInstance> serviceInstances = discoveryClient.getInstances(serviceName);
34 serviceInstances.forEach(serviceInstance -> {
35 Server server = new Server(serviceInstance.isSecure() ? "https://" : "http://",
36 serviceInstance.getHost(), serviceInstance.getPort());
37 loadBalancer.addServer(server);
38 });
39 });
40 }
41}
通过定时的方式,保证我们所维护的服务列表为ZK中维护的有效列表.这里可以优化为ZK的watch
机制来实现.discoveryClient
的getServices
可以获取到所有的注册服务的名称.通过名称和对应服务的协议,IP地址,服务端口号进行有效的关联.并通过实现BaseLoadBalancer
类的chooseServer
方法进行对负载均衡机制的实现.由于当前版本的netflix
存在一定的缺陷.如下代码:
1public class BaseLoadBalancer extends AbstractLoadBalancer implements
2 PrimeConnections.PrimeConnectionListener, IClientConfigAware {
3 private final static IRule DEFAULT_RULE = new RoundRobinRule();
4...
5 public Server chooseServer(Object key) {
6 if (counter == null) {
7 counter = createCounter();
8 }
9 counter.increment();
10 if (rule == null) {
11 return null;
12 } else {
13 try {
14 return rule.choose(key);
15 } catch (Exception e) {
16 logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
17 return null;
18 }
19 }
20 }
21...
22}
该类在初始化是默认选择轮询方式进行负载均衡的实现.
1public class RoundRobinRule extends AbstractLoadBalancerRule {
2 public Server choose(ILoadBalancer lb, Object key) {
3 if (lb == null) {
4 log.warn("no load balancer");
5 return null;
6 }
7
8 Server server = null;
9 int count = 0;
10 while (server == null && count++ < 10) {
11 List<Server> reachableServers = lb.getReachableServers();
12 List<Server> allServers = lb.getAllServers();
13 int upCount = reachableServers.size();
14 int serverCount = allServers.size();
15
16 if ((upCount == 0) || (serverCount == 0)) {
17 log.warn("No up servers available from load balancer: " + lb);
18 return null;
19 }
20
21 int nextServerIndex = incrementAndGetModulo(serverCount);
22 server = allServers.get(nextServerIndex);
23
24 if (server == null) {
25 /* Transient. */
26 Thread.yield();
27 continue;
28 }
29
30 if (server.isAlive() && (server.isReadyToServe())) {
31 return (server);
32 }
33
34 // Next.
35 server = null;
36 }
37
38 if (count >= 10) {
39 log.warn("No available alive servers after 10 tries from load balancer: "
40 + lb);
41 }
42 return server;
43 }
44}
但是该方法并没有有效的对传递过来的服务列表进行对服务名称的过滤.所以读者在使用该类进行负载均衡实现的时候,还需注意在传递服务列表之前,需要手动过滤分组之后实施.到目前位置,我们已经实现了对服务提供方的发现和负载均衡逻辑的实现.接下来,完成对服务请求的拦截和转发的过程实现:
1@WebServlet(name = "ribbonGateway", urlPatterns = "/ribbon/gateway/*")
2public class RibbonGatewayServlet extends HttpServlet {
3
4 @Autowired
5 private ZookeeperLoadBalancer zookeeperLoadBalancer;
6
7 @Override
8 public void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
9 // ${service-name}/${service-uri}
10 String pathInfo = request.getPathInfo();
11 String[] parts = StringUtils.split(pathInfo.substring(1), "/");
12 // 获取服务名称
13 String serviceName = parts[0];
14 // 获取服务 URI
15 String serviceURI = "/" + parts[1];
16 // 随机选择一台服务实例
17 Server server = chooseServer(serviceName);
18 // 构建目标服务 URL -> scheme://ip:port/serviceURI
19 String targetURL = buildTargetURL(server, serviceURI, request);
20
21 // 创建转发客户端
22 RestTemplate restTemplate = new RestTemplate();
23
24 // 构造 Request 实体
25 RequestEntity<byte[]> requestEntity = null;
26 try {
27 requestEntity = createRequestEntity(request, targetURL);
28 ResponseEntity<byte[]> responseEntity = restTemplate.exchange(requestEntity, byte[].class);
29 writeHeaders(responseEntity, response);
30 writeBody(responseEntity, response);
31 } catch (URISyntaxException e) {
32 e.printStackTrace();
33 }
34 }
35}
笔者这里采用Servlet的方式进行了实现.主要逻辑为:
通过HttpServletRequest
获取到当前请求的URI
,示例:http://127.0.0.1:8080/ribbon/gateway/spring-cloud-server-application/getway/say?message=hello
,如当前请求,则会解析为:spring-cloud-server-application/getway/say
,之后通过StringUtils.split
对字符串进行截取,结果:{spring-cloud-server-application,getway/say}
,之后通过对应的服务名称,获取对应负载均衡之后的服务提供者.
1@WebServlet(name = "ribbonGateway", urlPatterns = "/ribbon/gateway/*")
2public class RibbonGatewayServlet extends HttpServlet {
3
4 @Autowired
5 private ZookeeperLoadBalancer zookeeperLoadBalancer;
6
7 private Server chooseServer(String serviceName) {
8 Server server = zookeeperLoadBalancer.chooseServer(serviceName);
9 return server;
10 }
11}
通过获取到的服务提供方和当前有效信息,对请求进行对应的拼接处理.
1 private String buildTargetURL(Server server, String serviceURI, HttpServletRequest request) {
2 StringBuilder urlBuilder = new StringBuilder();
3 urlBuilder.append(server.getScheme())
4 .append(server.getHost()).append(":").append(server.getPort())
5 .append(serviceURI);
6 String queryString = request.getQueryString();
7 if (StringUtils.hasText(queryString)) {
8 urlBuilder.append("?").append(queryString);
9 }
10 return urlBuilder.toString();
11 }
之后通过RestTemplate
对服务进行调用.调用之前,将请求所需要的数据进行有效的封装.
1 private RequestEntity<byte[]> createRequestEntity(HttpServletRequest request, String url) throws URISyntaxException, IOException {
2 // 获取当前请求方法
3 String method = request.getMethod();
4 // 装换 HttpMethod
5 HttpMethod httpMethod = HttpMethod.resolve(method);
6 byte[] body = createRequestBody(request);
7 MultiValueMap<String, String> headers = createRequestHeaders(request);
8 RequestEntity<byte[]> requestEntity = new RequestEntity<byte[]>(body, headers, httpMethod, new URI(url));
9 return requestEntity;
10 }
在调取之后,在将数据进行返回即可:
1 /**
2 * 输出 Body 部分
3 *
4 * @param responseEntity
5 * @param response
6 * @throws IOException
7 */
8 private void writeBody(ResponseEntity<byte[]> responseEntity, HttpServletResponse response) throws IOException {
9 if (responseEntity.hasBody()) {
10 byte[] body = responseEntity.getBody();
11 // 输出二进值
12 ServletOutputStream outputStream = response.getOutputStream();
13 // 输出 ServletOutputStream
14 outputStream.write(body);
15 outputStream.flush();
16 }
17 }
18
19 private void writeHeaders(ResponseEntity<byte[]> responseEntity, HttpServletResponse response) {
20 // 获取相应头
21 HttpHeaders httpHeaders = responseEntity.getHeaders();
22 // 输出转发 Response 头
23 for (Map.Entry<String, List<String>> entry : httpHeaders.entrySet()) {
24 String headerName = entry.getKey();
25 List<String> headerValues = entry.getValue();
26 for (String headerValue : headerValues) {
27 response.addHeader(headerName, headerValue);
28 }
29 }
30 }
