




0x0 背景
团队6月份在规划华北机房的事情,运维同事在华北部署了一套resync-broker 和 resync-agent, broker挂在了华东的server下面, 恰好华北机房内跑broker的机器只有8G内存,在运行一段时间后,容器直接OOM了。
resync是一套文件自研的文件同步系统,主要解决用户在我们的定制平台使用定制工具定制完成语言模型资源和语义资源定制后,将这些模型资源快速同步到不同集群内每台部署有语音识别/语义解析的服务端所在的物理机器上,设计上参考了git对于文件的管理,对实际文件计算hash后分组保存,通过软连接指向这个实际文件,这个设计在拥有大量重复文件的情况下,可以很好的节约磁盘,架构图如下
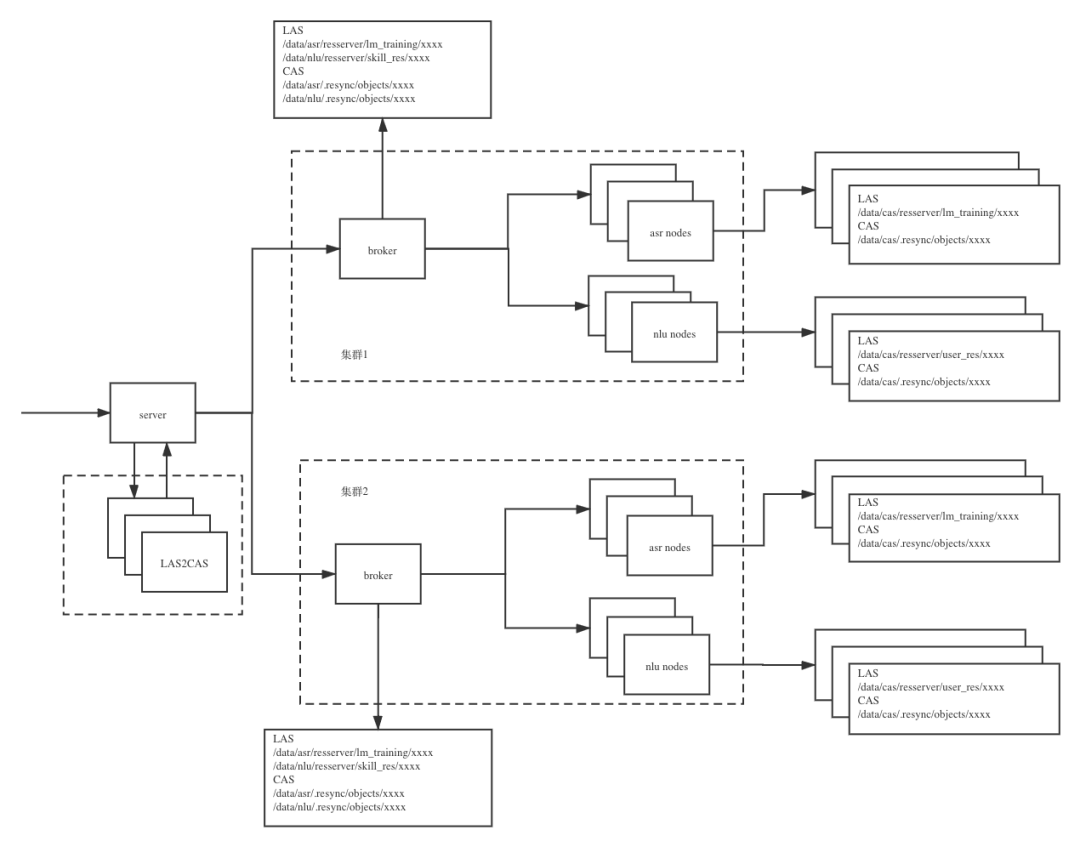
0x1 现象
我们查看了华北环境的broker内存占用监控可以看到OOM前内存就在持续上涨,OOM后由于机制原因,K8S还会把服务拉起来,但是拉起来后内存仍然是一个持续上涨的过程。
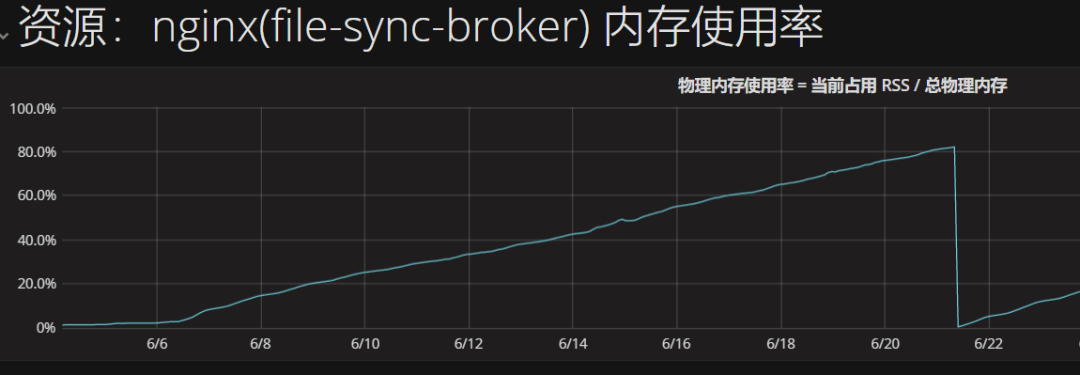
这现象提醒我们也关注了一下华东集群里两个broker内存情况,内存其实也是在上涨的,只是机器的配置高,没有出现重启而已。
0x2 问题分析
这里要说一下resync-broker做的工作,resync这套服务是基于Openresty开发的,broker 通过长轮询拉取任务,一旦有用户发布定制的资源,broker可以获取到一个任务信息的描述,然后根据描述信息将华东环境产生的识别/语义资源定制文件同步到各个运行了file-sync-agent的节点上。
broker服务内部使用了队列,在具体的实现时,服务启动时会创建两类定时任务
第一类是producer timer,其实只有一个,它就是通过长轮询负责从华东server拉取文件同步的任务,然后将任务信息塞入队列中。
第二类是consumer timer, 每个worker有一个,它主要负责消费任务队列的任务元信息,然后去server上把文件下载到机房内。
两类timer都是循环,在循环内会频繁地向server发送http请求,初步怀疑是http请求创建的资源无法回收,导致内存持续上涨。通过搜索,从openresty的issues里春哥的回复也得到了印证。
在openresty中,timer是模拟的http请求,我们知道openresty中资源会在请求结束后由gc回收,在循环中处理业务逻辑申请的资源同样的要等到timer退出后才能回收,但是当timer中我们写成了死循环后这部分的资源gc是一直无法回收的。
由于agent也同样使用了这套机制,果然查看了监控,服务的内存占用也是在缓慢上涨,基本可以确定是这个问题了, 同样的agent所在的机器也是配置比较高,并且timer的任务相较于broker会轻一些,因此这个问题不明显。
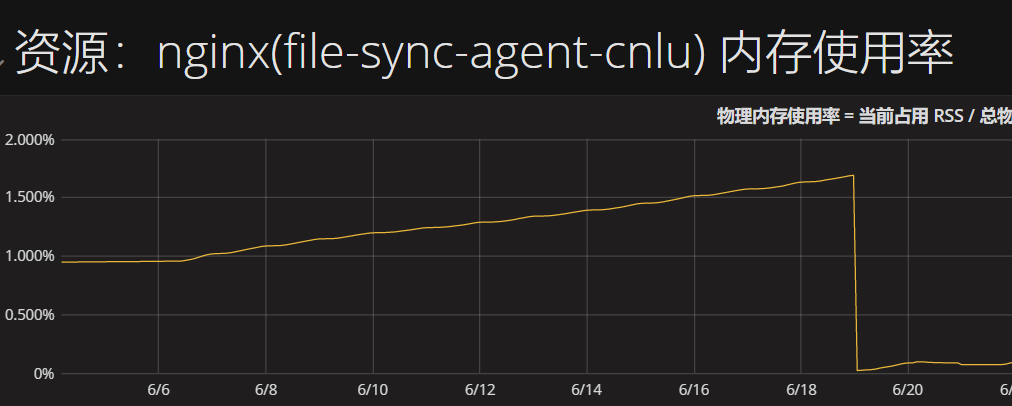
0x3 修改验证
我们修改了timer运行的逻辑,从之前的死循环不退出的timer修改为运行24小时后,退出这个timer并创建新的timer, 大致的伪代码逻辑如下
1 | local function loop() |
修改后的版本上线后,如下图,通过监控可以观察到每隔24个小时左右,内存都会有一次下降,这里对应的就是timer的重新创建,到这里物理内存持续上涨问题应该已经解了。
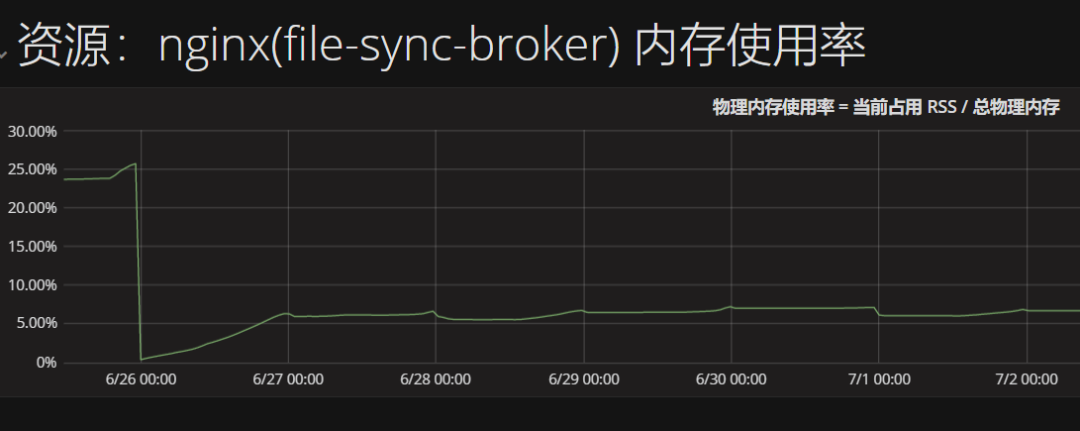
这次问题排查的经验就是在openresty里面使用timer一定要记得及时释放,如果要重复执行代码逻辑, 需要创建新的timer。其实openresty在1.11.2版本里已经引入了ngx.timer.every来创建循环执行的定时器,可以直接用它更简洁地实现需求。
