




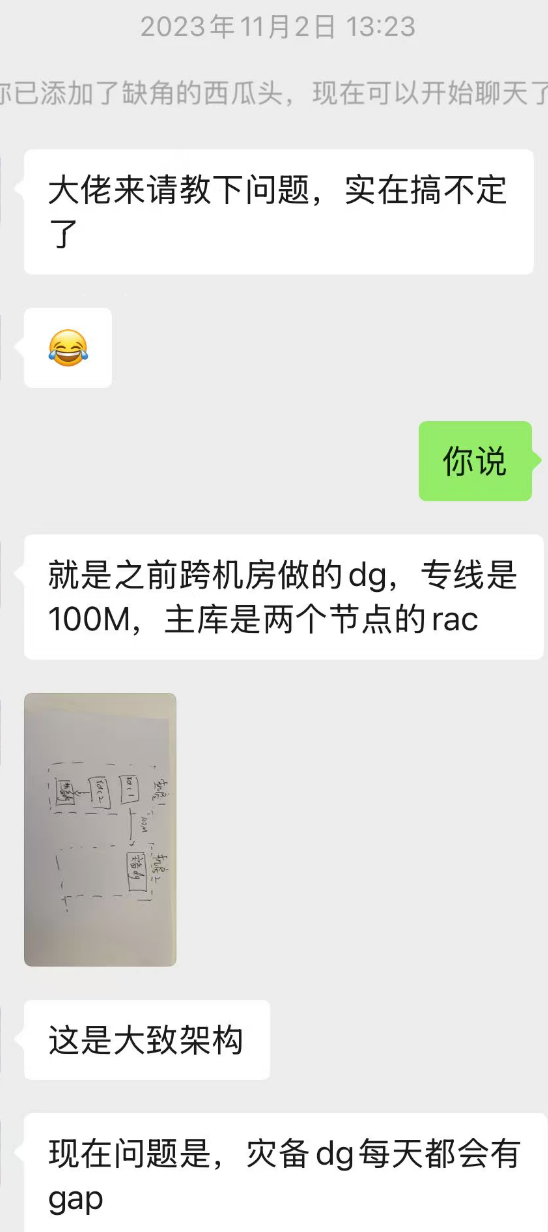
数据库情况:交易系统,主要压力在每天15:30-18:00的结算期间
问题现象:结算期间因为带宽限制(100m,每天峰值都在140M左右)出现2-4个gap,触发fal请求后,有时候能自己恢复,有时候需要等很久(1-2小时)才能恢复。
前期处理:awr报告能看到明显的log file switch (checkpoint incomplete)的等待事件,将redo从1G扩大到了2G,并优化了一些sql改善log file sync,gap频率下降到1-2次每天,整体数据库在结算期间没什么大的压力


所以首先可以定调,瓶颈不在数据库,在于跨机房的带宽,那带宽无法增加,gap无法避免,我们解决问题的思路就来到了如何解决fal无法及时自动恢复gap的问题上。
我们观察备库V$MANAGED_STANDBY视图


可以看到mrp复制进程在等待120073号日志,接收进程是接收中的状态;而看到主库的V$ARCHIVE_PROCESSES视图发现,arc0号进程处于busy状态一直在传输120073号日志,而日志最新已经传到120082号日志了,很明显备库已经检测到gap,发起fal请求了
于是写了个脚本持续观察主库arch进程的情况


数据库默认是4个arc进程(log_archive_max_processes=4),可以看到3号在传输120037号归档,值得注意的是在active的进程中,1号进程是no fal no srl的,就是不响应fal和server请求,2号进程是检测心跳的,也就是说真正能响应fal的只有0号和3号进程
此时猜想,因为进程占满,备库发出fal请求,需要等待。
当主库进程释放120037,状态变为idle,同一进程开始传输其它日志时,备库认定接收120037号日志失败,发起fal请求,这个过程需要一点时间


此时我将log_archive_max_processes=4修改为8
ALTER SYSTEM SET log_archive_max_processes = 8 SID='*';
通过备库日志应用可以发现fal请求正常发起,gap恢复

观察流量图

此时的流量因为多个归档的恢复,持续打满(这里时间的匹配说明不是因为带宽打满,导致gap去恢复,而是因为fal请求,多个归档发起传输持续打满了带宽,正常打满带宽是一个尖尖)
验证一周,加大参数log_archive_max_processes后,gap都能及时自己fal恢复;
说明:根因是带宽,gap无法避免,我们做的优化只是从侧面提升了数据库用fal请求处理gap的能力。
两年前就和这位网友做过多次讨论,基本上我们能达成一致的意见,就是根本原因就是带宽问题;因为这里是一个特殊的场景跨机房ADG,而且带宽有限,再加上是数据库的版本是11g,如果是12c+可以考虑far sync ADG,或者使用中间件OGG/DSG来实现。 但是基于现状来看调整log_archive_max_processes 确实可以加速fal的恢复,下面介绍参数的基本信息。
log_archive_max_processes参数的核心作用
- 主要功能:指定可以创建的最大 ARCn 进程数量(从 ARC0 到 ARC9,或扩展到 ARCa 到 ARCt)。这些进程不仅处理本地归档,还支持远程归档(如 Data Guard 中的 FAL 请求),并可用于心跳检测(例如,某些进程标记为 "no FAL no SRL",不响应 Fetch Archive Log 请求)。
- 在 RAC 和 Data Guard 中的应用:在 RAC 环境中(如文章的 2 节点主库),多个实例共享 redo 日志,ARC 进程需协调跨节点归档。在 Data Guard 备库(如单节点 DG)中,当检测到 gap 时,会发起 FAL 请求,主库的 ARC 进程响应传输缺失的归档日志。如果可用 ARC 进程不足(如文章观察到的仅 0 号和 3 号进程可用),FAL 请求会排队等待,导致恢复延迟(文章中 1-2 小时)。增加该参数(如从 4 改为 8)可提升并发处理能力,确保 FAL 及时响应,尤其在带宽受限(100M 峰值 140M)的高压结算期。
- 动态调整:参数支持 ALTER SYSTEM 动态修改(需数据库挂起但未打开),范围为 1-30,默认值为 4。
在文章案例中,修改后观察到流量峰值呈 "尖尖" 状(多个归档并发传输打满带宽),验证一周无延迟恢复,证明了其在优化 gap 恢复方面的侧面作用。
| 8i (8.1.6) | ||||
| 9i/10g (10.1) | ||||
| 11g (11.2) | ||||
| 12c/19c | ||||
| 21c | ||||
| 26ai |
