




这个案例其实是在我写完第一本书后遇到的,所以也一直没写
- 日常开发中,分页查询是高频操作 —— 列表页一页页往下翻、批量导出数据分批拉取,我们早已习惯用 LIMIT(MySQL)或类似语法(Oracle)实现。但很多人不知道:LIMIT 200,100 不是直接查 100 行,而是先查 300 行再丢弃前 200 行!
- 如果开发用循环分页批量取数(比如每次取 100 行,循环 10 次),以为总共只查 1000 行,实际可能查了几万行,数据量越大性能越崩。今天 MySQL 8.0 做实测(其实Oracle和PostgreSQL也一样,因为这是数据库基本原理),带你看清这个隐藏误区。
我有一个1万行的表(真实环境可能是会大一些比如1000万,我们这里用1:1000的比例缩放一下)
-
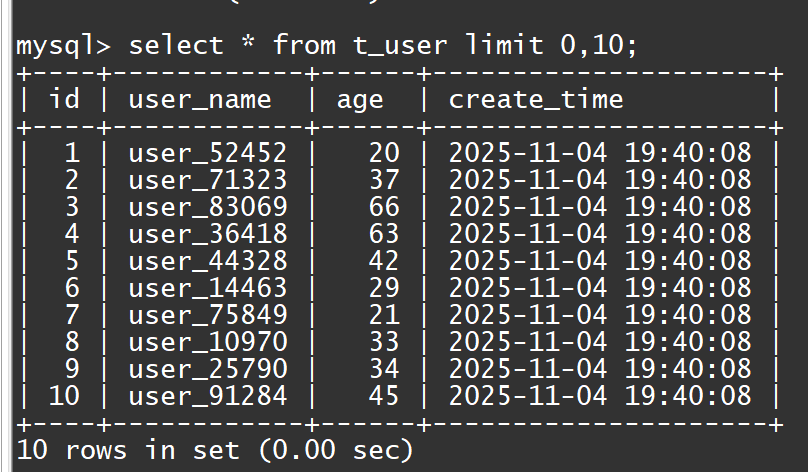
-

-
可以看到这个SQL查了10行返回10行。
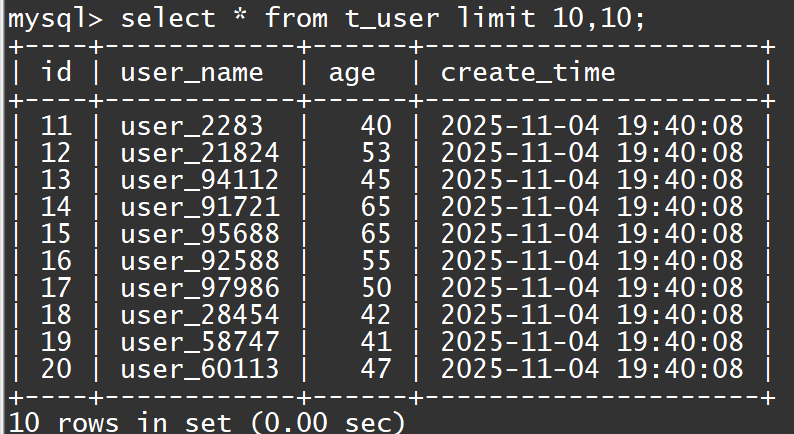

-
可以看到这个SQL查了20行返回10行。
-
所以以此类推
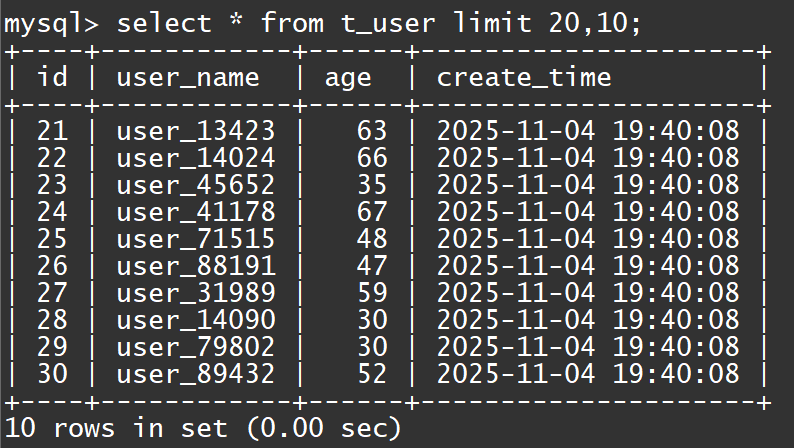

- 可以看到这个SQL查了30行返回10行。
主观上以为是10行10行的分段取数,实际上是叠加。
- 这个的计算公式应该是:S = k × (size + k×size) ÷ 2 = size × k × (k + 1) ÷ 2
- 总扫描行数 S = 项数 × (首项 + 末项) ÷ 2
- 如果每页10行按照这种错误的方式导出数据则是:循环 10 次(k=10,size=100)
- S = 100 × 10 × (10 + 1) ÷ 2 = 100 × 10 × 11 ÷ 2 = 5500 行
- 结论以为读取了100行下载了100行,实际是读取了5500行下载了100行。是55倍的关系。
- 而一开始我说了,本案例的比例尺是1:1000。这里的5500行实际上可能是5500000。
- 当然这里还是只循环10次,如果是循环100次呢?
所以分页本身没有错,但是如果说用这种方法去下载大可不必了
- 语法直觉误导:LIMIT offset, size 看起来像「直接跳过 offset 行,取 size 行」,但数据库无法直接「跳过」,只能先扫描到 offset+size 行,再丢弃前 offset 行;
- 下载那就select 结果集一次性吧。如果一次性实在很大。那么就指定好一些条件,比如时间等,分批下载。
最后修改时间:2025-11-05 09:53:01
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
