




导读
AWR 报告是 DBA 最常用的性能诊断工具,但它展示的其实是一种“汇总后的视角”。很多时候,我们从报告中看到的是现象,而不是问题的根源。如果想更深入地理解数据库的运行状态,就需要回到 AWR 的底层,去分析它的“裸数据”——也就是最原始的统计表信息。这样我们才能获得更细粒度的性能数据,更精准地定位问题,甚至构建出自己的分析与监控体系。
本次我们邀请到云和恩墨性能优化专家、研发架构师 罗海雄,带大家深入了解 Oracle AWR 的底层结构,看看如何通过裸数据分析,让性能诊断更直观、更精准、更智能。
本文整理自直播分享,部分语句在不改变原意的基础上做了更改。
演讲资料:https://www.modb.pro/doc/147491
视频回放:https://www.modb.pro/video/10738

罗海雄
云和恩墨性能优化专家,研发架构师
ITPUB论坛数据库管理版版主,2012 ITPUB全国SQL大赛冠军得主;资深的架构师和性能优化专家,对 SQL 优化和理解尤其深入;
Oracle AWR 的作用与局限性
大家都知道,在做 Oracle 性能分析 的时候,我们最常用的工具之一就是 AWR(Automatic Workload Repository)报告,它能帮助我们清晰地看到一个时间区间内数据库的整体运行情况,是** Oracle 体系中一个非常核心的性能诊断工具**。

图1:常规使用–AWR/ASH报告
不过,相信大家在使用的时候也会发现——AWR 报告虽然内容非常丰富,但也存在一些局限性。
比如:
- 报告太长、章节太多,信息量非常大;
- Oracle 里与 AWR 相关的基表超过 100 张,数据结构复杂;
- 更重要的是,报告本身是一种“点对点”的结果,只能展示你选定的两个时间点之间的表现。
也就是说,我们每次只能看到一个时间段内的情况。如果想看趋势怎么办?那就得自己手动去生成多份报告,再人工比对。这一点,对我们分析性能问题来说,其实是挺不方便的。
另外,AWR 报告的各个章节之间也缺乏关联性:比如“等待事件”“SQL 统计”“I/O 情况”等章节,彼此都是独立的,很难直接做交叉分析。
还有一个问题——报告里的内容其实存在一定的冗余。对于有经验的 DBA 来说,可能只需要关注其中几个关键部分,但系统每次都会把所有章节都生成出来,既耗时,也占空间。
当然,AWR 报告也有它的优点。最大的好处是方便离线查看,比如我们可以把报告导出,发给同事或厂商的支持团队进行分析。但总体来看,AWR 报告提供的仍然是一种静态的、汇总式的分析方式。对于我们这些希望进行更灵活、更深入性能分析的场景来说,它可能就不够用了。
从 AWR 报告到裸数据分析
1、直接访问 AWR 的底层裸数据的优势
那有没有更灵活的方式呢?其实可以——我们可以直接访问 AWR 的底层裸数据表。
这样做的好处是:
- 我们能自己定义分析维度;
- 可以做趋势分析、跨章节对比;
- 还能自定义可视化图表,比报告自由度高得多。
AWR 的底层数据大概分为以下几类:

图2:AWR底层数据的类别
这些表加起来上百张,但核心思想其实不复杂,我们只要掌握它的数据类型特征,就能灵活分析。
2、AWR 裸数据的类型
我们可以把这些裸数据分为两类:👉 累计值(Cumulative Values) 和 变化值(Delta Values)。
举个例子:
-
累计值:比如逻辑读的总次数,是从数据库启动以来一直往上加的。
所以,如果我们要看一段时间的增量,就得做一个“当前值 - 上次值”的计算。 -
变化值:Oracle 有些表会直接记录两次采样之间的变化,比如每分钟逻辑读增量、平均值、最大值等。
-
还有一些是当前状态值,比如当前会话数,这类数据不会累计。
大多数时候,我们想要的其实是“累计值的变化量”,因为那反映的才是性能趋势。

图3:AWR裸数据的类别
分析函数篇:用 LAG 与 LEAD 探索时间序列变化
在分析 AWR 的裸数据时,我们首先要解决的问题是:如何观察数据库性能指标随时间的变化趋势。这些数据本质上是一组时间序列快照,若能比较相邻快照之间的变化,就能直观看出系统的波动情况。在这里,分析函数 LAG() 和 LEAD() 就非常有用。它们可以帮助我们取到“上一条”或“下一条”快照的值,再与当前值相减,计算出增长或下降幅度。
例如,我们希望了解 CPU 时间的变化趋势,就可以用 LAG(DB_TIME) 取上一快照的值,再减去当前值,即可得到每个时间段的性能变化。

图5:多个指标并列
此外,还可以结合 SUM()、AVG() 等聚合函数,计算移动平均值或滑动区间的统计,从而更全面地观察性能波动。相比标准的 AWR 报告,这种基于裸数据的方式更动态化,可以实现实时趋势分析,而不局限于两个固定时间点之间的静态比较。
行列转换篇:用 PIVOT 实现多指标对比
在完成时间趋势分析之后,我们往往希望进一步进行多指标的横向对比。比如同时观察 CPU 使用率、I/O 吞吐量、Redo 大小、逻辑读次数等关键指标。但由于这些数据在底层表中往往是“按行存放”的,若用传统 SQL 分析,就需要写很多 SUM(CASE WHEN …) 语句,不仅繁琐,还不易维护。
这时,PIVOT 函数就能大大简化我们的工作。通过 PIVOT,我们可以将行数据转为列展示,只需在 IN() 子句中定义需要的指标,例如:
CPU_TIME, DB_TIME, Redo Size, Logical Reads …
一次性即可生成所有指标列,查询结构清晰、扩展性也很强。此外,我们还可以自定义指标的别名,让结果更易读。在查询结果中加入时间戳字段后,便能轻松查看各项指标在不同时间点的变化情况。通过这种方式,我们可以快速构建出一张“多维性能监控表”,让不同指标的趋势对比一目了然。

图6:利用PIVOT 函数进行行列转换
用 RATIO_TO_REPORT 做统一尺度分析
当我们将这些分析结果导出至 Excel 或 BI 工具时,就能绘制出类似 AWR 报告中的趋势图或 Load Profile 图表。不过,这时常常会遇到一个问题:不同指标的数量级差异太大。
例如,Redo Size 可能是数亿,而 Write I/O 仅有几千。如果直接画在同一张图上,小指标往往会被“压扁”,几乎看不出趋势变化。
为了解决这个问题,我们可以利用分析函数 RATIO_TO_REPORT()。它的作用是将每个值转换为当前结果集中的占比,也就是把绝对值变成百分比。这样,不同数量级的指标就能在同一尺度上进行对比。
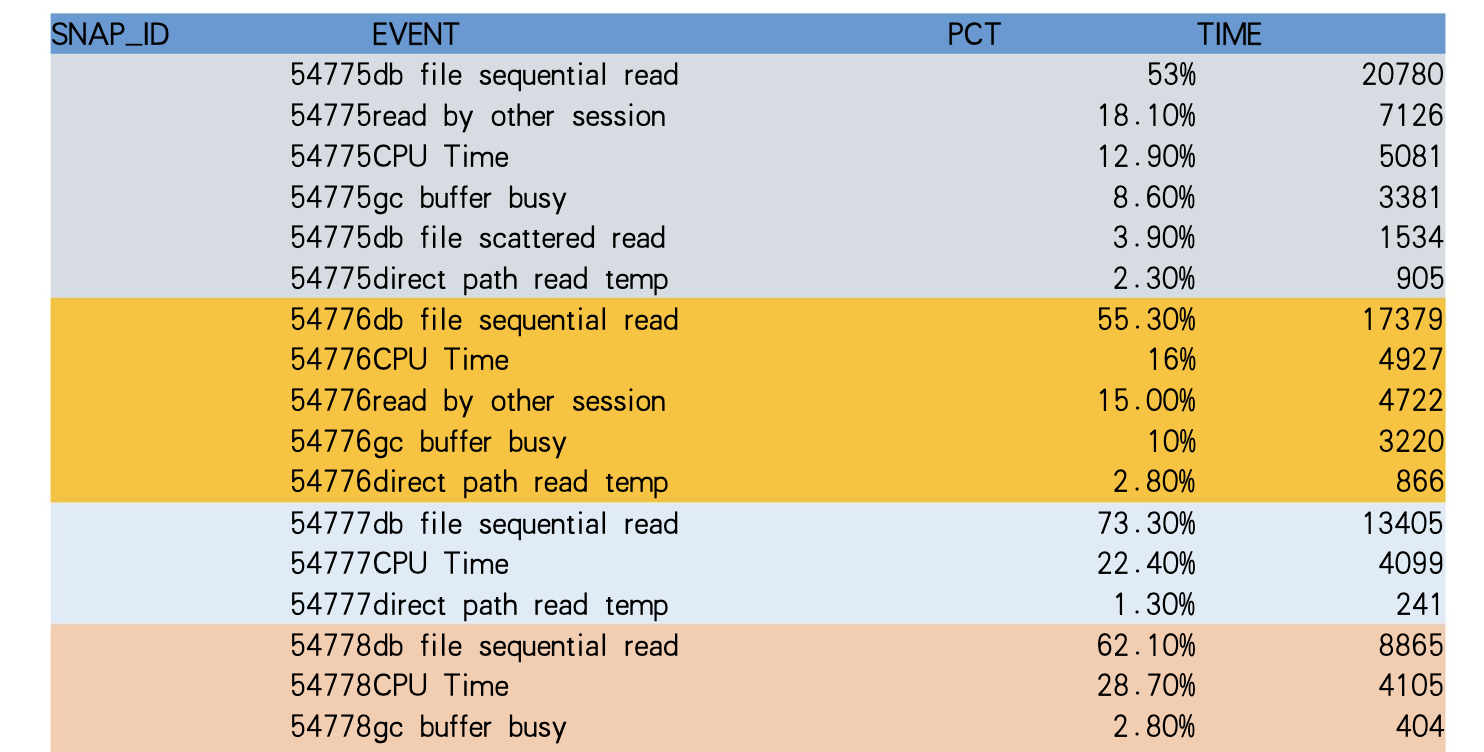
图7:回归本来含义的RATIO_TO_REPORT()
通常我们会将结果乘以 100 或 1000,并结合 ROUND() 函数做取整处理,使数据更加直观。
最终得到的趋势图既清晰又有可比性——无论是巨大的 Redo Size,还是较小的 I/O 操作,都能在同一张图上准确反映其变化趋势。
通过这种比例化分析方法,我们可以将 AWR 的原始统计信息转化为更具洞察力的趋势视图,让性能分析从“静态汇报”走向“动态理解”。
通过直接访问 AWR 的裸数据,我们可以突破传统报告的限制,带来更灵活、更深入的性能分析。这种方法能帮助我们:
- 实现时间序列的趋势分析,追踪性能变化;
- 进行多指标的对比与可视化,便于从不同角度分析系统状况;
- 进行跨章节的性能关联,打破报告章节之间的隔阂,深入发现根本原因;
- 更精准地定位问题,快速找到瓶颈,提供针对性的解决方案。
相比于单纯依赖 AWR 报告,这种基于裸数据的分析方式更加贴近我们 DBA 的思维方式,也能帮助我们更高效地解决性能问题。
以上就是我今天分享的所有内容,希望能让大家在性能诊断上有更多新的思路和工具。
