




本测试硬件环境是在比较老旧的Dell R710
机器上测试的,具体配置参考下面内容,我们在这里主要测试和探讨的是对Spark2、Hive2、Spark1、Hive1进行跑同样的TPCDS测试用例、比较它们的性能有多大差别,其中也会测一组最早期的Hive on MR
的性能。
硬件
CPU : 24
内存:128 G
磁盘:300g*5 块 / node
网络
千兆网络 0.98 Gbits/sec
系统
CentOS Linux release 7.2.1511 (Core)
软件
CRH v5.0
Hive 2.1 with LLAP
Hive 1.2.1 with Tez 7.0
Hadoop 2.7.3
Tez 0.7.0
Tez 0.8.3
Spark1 1.6.3
Saprk2 2.1.0
数据量
266.7 G ORCFile
916.7 G TextFile
24 Table
注:数据通过TPC-DS
提供的数据生成程序生成1TB的TextFile,再通过这1TB文件生成ORC文件格式同样的表。
资源分配
资源分配主要涉及Yarn和HDFS的资源分配,因为Hive1和Hive2、SparkSQL都是基于Yarn分配资源运行,本身并不占用资源、安装之后以客户端
的形式存在集群中,只有在需要的时候才会启动运行任务。
Yarn
Memory Total:452.50 GB
VCores Total:95
NodeManager:5 node
ResourceManager:1 node
HDFS
NameNode Java heap size: 11GB
DataNode maximum Java heap size: 6GB
NameNode: 1 node
DataNode: 5 node
集群连接方式
由于集群提供多种连接方式,不同的连接方式对集群性能会有所影响,所以统一使用一种方式连接集群也是所测试的框架都支持的方式beeline
。
SQL on Hadoop框架中,和这个生态融合度高的基本都有beeline
方式,他其实就是JDBC的命令行版本。
Hive JDBC
平台提供Hive1和Hive2的访问接口,分别如下方式,通过beeline
方式连接Hive集群。
Hive1 Examples
beeline --hiveconf hive.execution.engine=tez -u 'jdbc:hive2://bigdata-server-3:2181,bigdata-server-1:2181,bigdata-server-2:2181/tpcds_bin_partitioned_orcfile_1000;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2' -n hive
Hive2 Examples
beeline --hiveconf hive.execution.engine=tez -u 'jdbc:hive2://bigdata-server-3:2181,bigdata-server-1:2181,bigdata-server-2:2181/tpcds_bin_partitioned_orcfile_1000;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-hive2' -n hive
Spark JDBC
平台提供Spark 1.6.3和Spark 2.2的beeline
访问接口,可以通过如下方式直接访问spark集群。
由于默认启动的Jdbc Server没有提供动态资源分配的能力,如果通过beeline
方式连接,不能完全把集群资源利用起来,导致查询性能还能有很大的优化空间。
所以针对sparkSQL集群的测试,使用的是spark-sql加了动态资源分配之后执行测试。
beeline -u 'jdbc:hive2://bigdata-server-1:10016/tpcds_bin_partitioned_orcfile_1000' -n spark
SparkSQL动态资源分配、预申请资源11个Executors、spark会在这个基础上在运行tpcds不同SQL的时候动态的去轮询申请资源,进行数据计算,具体参考如下:
/usr/crh/current/spark2-client/bin/spark-sql --master yarn-client --conf spark.driver.memory=10G --conf spark.driver.cores=1 --conf spark.executor.memory=8G --conf spark.driver.cores=1 --conf spark.executor.cores=2 --conf spark.shuffle.service.enabled=true --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.minExecutors=10 --conf spark.dynamicAllocation.maxExecutors=114 --database tpcds_bin_partitioned_orcfile_1000 -f sample-queries-tpcds/query98.sql
Comparing Hive with LLAP to Hive on Tez
我自己通过Python
封装了一下查询命令,可以通过直接通过变换命令行参数自动化测试整个tpcds过程,最后记录执行日志和时间到相应Log中。
python Hadoopdb-tpcds-test.py Hive2 tpcds_bin_partitioned_orcfile_1000
执行的TPCDS相关Log日志,我已经上传到百度云:
链接: https://pan.baidu.com/s/1nvE55fN 密码: 999r
里面有几个压缩文件,解压后对应有执行SQL的时间情况、执行SQL过程记录情况。
HAWQ
有关HAWQ的测试,是有段时间接触了一些做HAWQ的人,所以我就深度研究了一下这个东西,相对来说性能还是不错的,不过就是有很多莫名其妙的错误,社区也很不活跃,简单我自己修复了几个小问题。不过改造难度挺大的,跟Hadoop生态融合得也比较差,可以当做一个MPP DB来看比较直观,使用方式完全于GPDB一致。不过需要考虑很多HDFS参数改动和Linux系统本身的内核参数调整,不然很容易崩,相对来说稳定性没那么高。
我打算单独写一篇HAWQ相关的测试,这里就不多介绍了,下面是我遇到的几个莫名其妙的问题,Pivotal官方文档做的真心不错,使用之后,简单些几点感受,比较肤浅的看法,具体如下:
Hawq Load Data Error
这里使用到了PXF插件直接读取Hive 、Hbase、HDFS数据,发现通过他们提供的可视化工具部署安装,依然无法正常直接进入使用阶段,各种报错。
通过HAWQ CLI登录之后, 能查询到元数据信息,无法查询到具体的数据是什么鬼。底层看了下PXF实现,跑在一个Tomcat里面的JAVA程序算是咋回事,这个性能不用想,也很低下。只能Load数据到HAWQ。
drop external table pxf_sales_info; CREATE EXTERNAL TABLE pxf_sales_info( location TEXT, month TEXT, number_of_orders INTEGER, total_sales FLOAT8 ) LOCATION ('pxf://bigdata-server-1:51200/sales_info?Profile=Hive') FORMAT 'custom' (FORMATTER='pxfwritable_import'); SELECT * FROM pxf_sales_info;
TPCDS load数据报错,看样子依赖很多c库,一个个装吧。
gpfdist: error while loading shared libraries: libapr-1.so.0: cannot open shared object file: No such file or directory
解决:yum install -y apr
gpfdist: error while loading shared libraries: libevent-1.4.so.2: cannot open shared object file: No such file or directory
解决:yum install -y libevent
待全方位测试之后,我在发一篇完整的吧,HAWQ论文我是读完了,个人没感到有什么创新点,感兴趣的可以看看。
https://github.com/changleicn/publications
Impala 整合CRH报错
在测试跑全系CRH产品组件的时候,本想把Impala也放进来一起测试一下,没想到,依赖特定的Hive版本,有些兼容性问题,待解决。
NoSuchMethodError: org.apache.hadoop.hive.metastore.MetaStoreUtils.updatePartitionStatsFast(Lorg/apache/hadoop/hive/metastore/api/Partition;Lorg/apache/hadoop/hive/metastore/Warehouse;)Z
TPCDS 性能
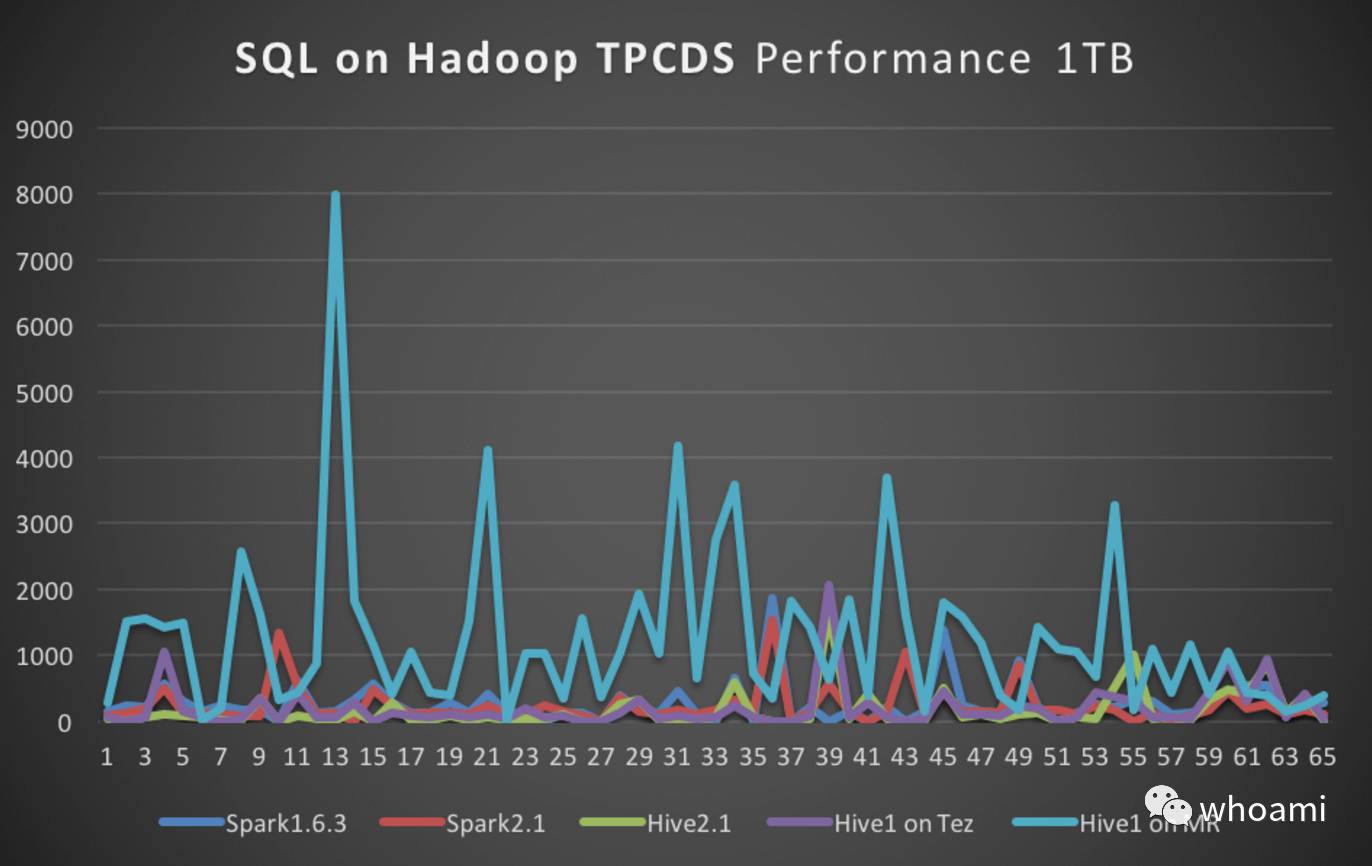
上图,可以看出,Hive2在性能上有了很大的提升,至于原因,关注微信的可能又看到过有关Hive with LLAP优化的文章,剖析了很多篇,由于个人时间问题,导致博客和微信有些文章没时间同步。
相对来说Hive,SparkSQL在跑TPCDS的时候,在稳定性上都有了长足的进步,不在会出现各种莫名其妙崩溃的问题,甚至查询几个小时都没结果的情况,但是易用性和细粒度资源控制上还有很长的路要走,要达到企业级产品级别,各种做大数据发现版的公司得花费大的精力去完善产品,达到企业级可用的程度。
SQL on Hadoop产品五花八门,目前还没有一个相对完整和全面一点的软件产品,满足客户大部分需求,导致选择困难,POC的时间太长,都是成本。
SQL on Hadoop的框架,目前Hive、Spark、Impala都是可选对象,其他框架社区不活跃,用户少很难继续走下去。一直在吃老本的Hive2也憋了个大招,Impala也在不断优化,都在性能这条路上越走越远,我们敬请期待吧。
欢迎关注微信公众号,第一时间,阅读更多有关云计算、大数据文章。
原创文章,转载请注明: 转载自Itweet的博客本博客的文章集合:
http://www.itweet.cn/blog/archive/
