




本文为译文 , 原文发表于2016年7月20日,译文原文请查看文末 - 译者注
Apache Hive2.1发布于一个月以前, 这是一个回顾Hive2如何彻底改变Hadoop上的SQL 引擎的机会。
Hive 有很多新的改变,很难说具体的亮点, 但是以下有几个:
Hive LLAP的交互式查询,Hive2.0就介绍了LLAP,LLAP 在Hive 2.1得到了改善,传输速度比 Hive 1加快了25X, (以下详细介绍).
Robust SQL ACID 支持超过60以上的稳定性修复。
更智能的CBO使ETL加快了2X,更快的类转换以及动态分区优化。
程序的SQL显著简化了EDW(企业级数据仓库)解决方案的迁移。
文本文件的矢量化介绍了一个无需ETL就能快速分析的选项。
一个具有新的诊断程序和检测工具的主机包括新的HiveServer2 UI,新的LLAPUI 以及 改善完成的Tez UI.
总共超过了2100个新功能, 改善修复了Hive2.0 和 Hive 2.1之间存在的问题,惊人的创新率以及持续增长的势头。

我们将在后期文章中探索其他话题,现在我们将重点放在Hive 2中最值得期待的特性和巨大的性能提升 。
Hive LLAP比之前快25X的query性能
Hive 2中最大的故事也是最受期待的功能: LLAP 是live long andprocess的缩写,总结一下就是, LLAP 结合持续查询服务和优化内存缓冲让Hive可以立刻启动查询,避免了不必要的磁盘 I/O浪费, 换句话说, LLAP 是第二代大数据系统:LLAP 引领了内存计算(而不是磁盘计算),LLAP智能的缓存了内存并通过客户端共享数据,同时还保留了在同一个集群里面弹性扩展的能力。
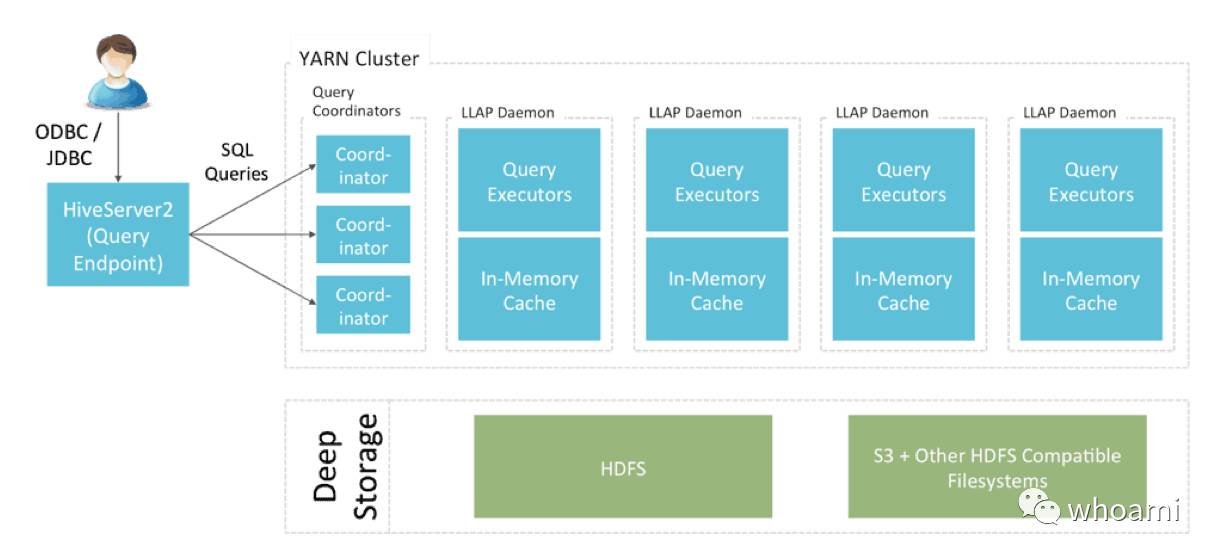
图表一:LLAP 架构
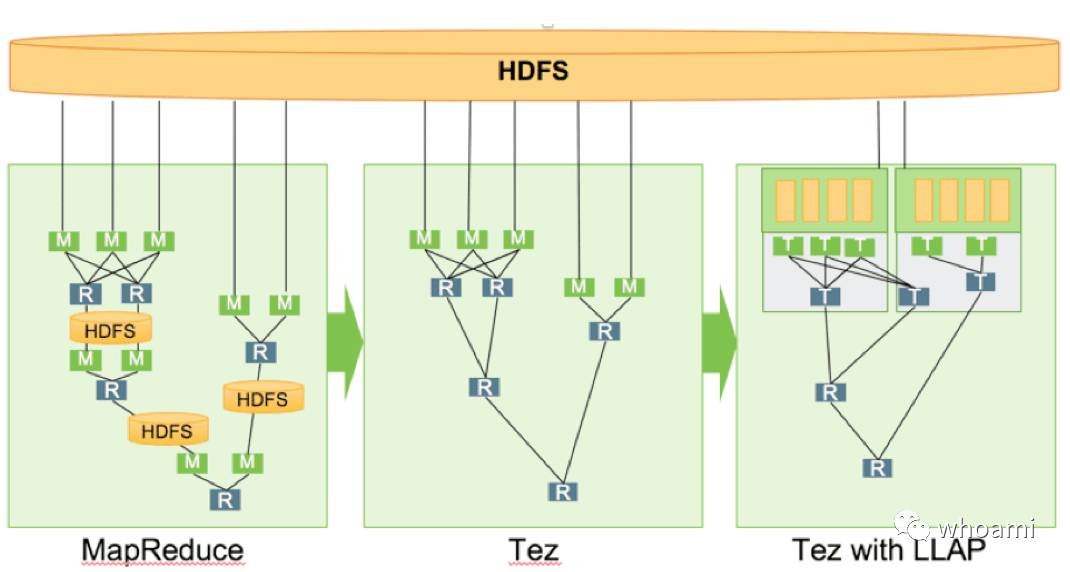
Tez LLAPprocess 对比Tez execution process 和MapReduce process
Comparing Hive with LLAP to Hive on Tez
为了测量改良后的LLAP我们从TPC-DS 基准上提取了15个queries进行运行,有点类似我们之前做过的测试。整个运行过程使用hive-testbench资源库和数据生成工具,有适应Hive SQL的查询,没有使用任何技巧修改标准查询,一些大数据供应商经常用这些技巧来展示他们的工具具有更好的性能。这篇文章只覆盖了15个查询, 但是更全面的性能测试正在进行中。
全面测试环境如下,但是更高级别的测试运行使用的是10个强大的虚拟机(VMs) 1TB 数据集,目的是展示通用的BI工具在数据扩张时的性能。同样的虚拟机(VMs) 和数据在Hive1和Hive2上测试,所有的报告显示在各个Hive版本中平均运行次数为3次。
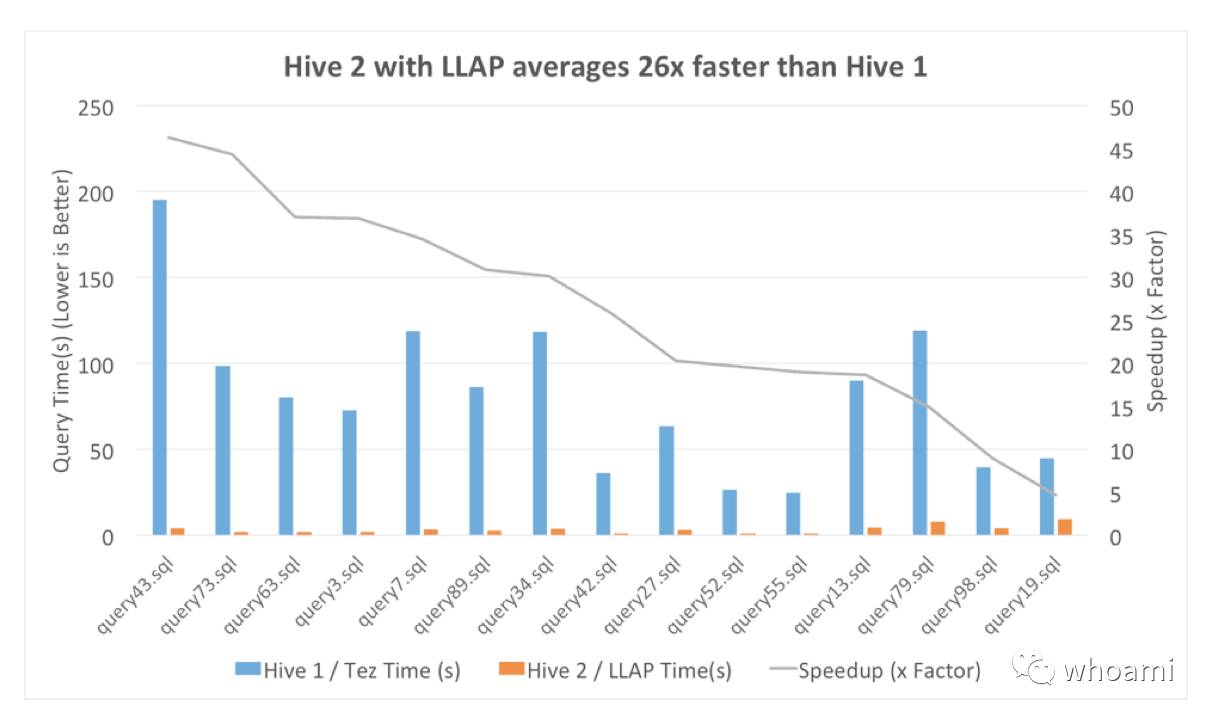
图表3:使用Tez的Hive1vs 使用LLAP的Hive2
如你所见,LLAP显著的性能收益, 对比 Hive 1的9.58秒,Hive LLAP 最少查询运行时间仅为1.3秒,
一起讨论一下这些性能收益的主要原因。
原因一:更智能的Map Joins。
在Hive上使用Tez是无共享架构:每个程序单元使用自己的内存和磁盘独立工作,LLAP是一个多线程序,内存可以在workers之间共享。map-side连接需要一个hash表分布1:1到每个map任务中, 如果24个容器在同一个节点上那么你就需要复制24份hash表然后分布出来。使用LLAP创建hash表在每个节点上,然后把所有的workers缓存到内存上, 这对于低延迟的SQL特别重要。
这种类型很好的例子是Query 55, 在TPC-DS中,Query 55涉及在任意query中查询最小数量的数据,查询一个事实表,只有一个月。若要在Hive中使用Tez运行这种query, 最小的date_dim 和项目表必须首先分布成所有的Tez任务。用LLAP在每个节点发生一次,是 LLAP的平均执行时间是1.3s的大部分原因。对比Hive Tez是24.72s。
原因2:更好的MapJoin矢量化连接。
很多的MapJoin已经优化到了Hive2, 例如,join上一个更小的维度表, 现在运行得和显式扩展列表一样快。
一个很不错的例子是Query43, 在储存维度join有37%的选择性。更佳的MapJoin优化,在事实表中重复利用序列,有助于将Query43所需时间从192.5s降到4.2s。
理由3:完全矢量化的流水线。
Hive 2介绍了在reduce中矢量化 Map Join和动态分区hash join,从本质上优化了MapJoin的reduce-side版本。这种优化使得reducer可以未排序输入,以流穿过hash表在reduce side上持续流动。这种优化将大的维度表分为很多小的不相交的维度表,还允许之前的维度表向上优化,扩展大小。
这儿很好的例子是Query 13,涉及到连接一些很大的维度表和很小的维度表,为了安全它需要像shufflejoin一样运行,这样就可以从其他维度过滤获得很高的选择率。 这种优化有助于将Query 13 所需要的时间从90.2s 降到4.8s。
原因4:更智能的CBO
持续深化整合 Apache Calcite 复杂的基于代价的优化正收获巨大的回报。几个例子,Hive的CBO现在可以用factor join 锁定表层predicates(避免交叉连接),还可以推断传递predicates横向join, 并且在即使表没有统计的情况下完成基本的传递(ETL jobs的一大胜利)。
测试环境
软件

其他Hive和Hadoop设置:
所有的这些软件都是用 Apache Ambari HDP等软件部署的, 现在还是技术预览版。除了从Ambari默认设置以外,一些新的优化是为了Hive2设置的, 这些优化将默认设置在新安装的GA上。
· hive.vectorized.execution.mapjoin.native.enabled=true;
· hive.vectorized.execution.mapjoin.native.fast.hashtable.enabled=true;
· hive.vectorized.execution.mapjoin.minmax.enabled=true;
· hive.vectorized.execution.reduce.enabled=true;
· hive.llap.client.consistent.splits=true;
· hive.optimize.dynamic.partition.hashjoin=true;
硬件:
10x d2.8xlarge EC2 nodes
OS配置:
在大多数情况下,OS默认使用1例外。
/proc/sys/net/core/somaxconn = 4000
如下屏幕抓图提示了如何利用Ambari的配置支持LLAP。请注意, Ambari的LLAP配置正在持续演变中,所以这篇文章及当前安装可能会和图片稍有不同。
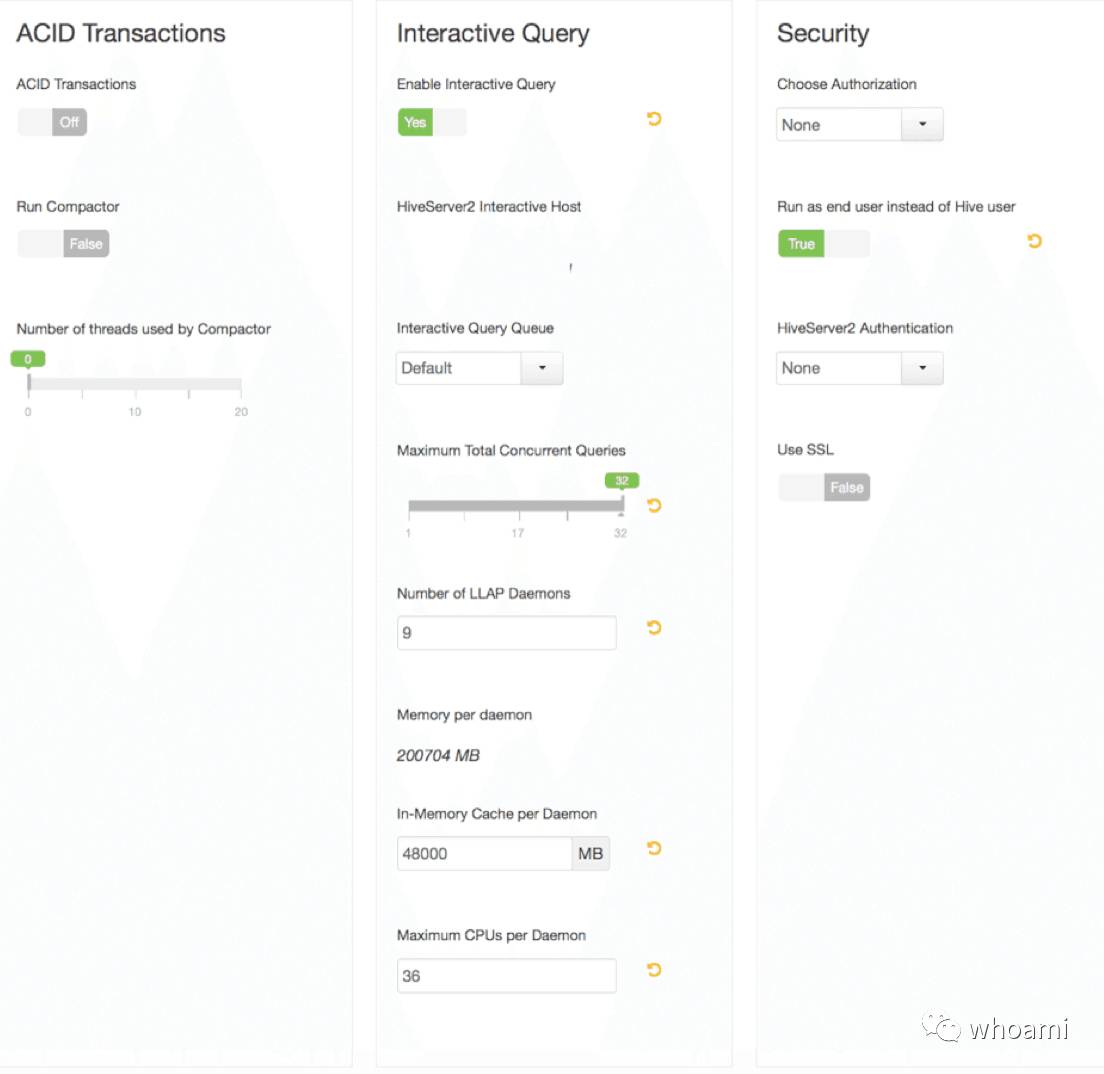 图表4:在Apache Ambari中安装流线LLAP
图表4:在Apache Ambari中安装流线LLAP
数据:
TPC-DS通过date_sk扩展1000列分区数据,存储为ORC格式,同样的数据和表用于Hive1 和 Hive 2.
查询:
测试是通过 Hive 测试台驱动生成数据以及query,同样的query文本文件用于Hive 1 和Hive 2。参考https://github.com/t3rmin4t0r/hive-testbench/tree/hive14。
15 queries在测试基准中是一个示例,一个更全面的测试基准,具有LLAP功能的Hive将会在几周内公布。
今天尝试Hive 2.1和LLAP!
和以往一样, Apache Hive是100%开源,你还可以选择用于Hadoop分布,Apache Hive还适用于性能改善和文章中讨论的一些其他功能。
如果你想期待尝试Hive 2.1,以下有几个选项:
1,直接从Apache下载公开版本, 并在Hadoop集群上运行。
2,在HDP 2.5 技术的预览Sandbox上试用LLAP, 如果你想调整一下Sandbox释放更多内存, 你可以选择最小的投入把LLAP作为测试驱动器来完成。
3,使用 HDP-AWS 技术预览的LLAP模板。选择LLAP集群类型,然后还需要一个AWS账户。
图表5:LLAP in HDP-AWS
欢迎关注微信公众号,阅读更多有关云计算、大数据文章。

原创文章,转载请注明: 转载自Itweet的博客
本博客的文章集合:
http://www.itweet.cn/blog/archive/
译文原文:https://hortonworks.com/blog/announcing-apache-hive-2-1-25x-faster-queries-much/
