




OceanBase 集群故障排查:从启动失败到全面恢复,一次典型的 OceanBase 集群"假死"故障排查全记录
个人简介
作者: ShunWah(顺华)
公众号: "顺华星辰运维栈"主理人。
- CSDN_ID: shunwahma
- 墨天轮_ID:shunwah
- ITPUB_ID: shunwah
- IFClub_ID:shunwah
持有认证: OceanBase OBCA/OBCP、MySQL OCP、OpenGauss、崖山 DBCA、亚信 AntDBCA、翰高 HDCA、GBase 8a | 8c | 8s、Galaxybase GBCA、Neo4j Graph Data Science Certification、NebulaGraph NGCI & NGCP、东方通 TongTech TCPE 等多项权威认证。
获奖经历: 崖山YashanDB YVP、浪潮KaiwuDB MVP、墨天轮 MVP,担任 OceanBase 社区版主及布道师。曾在OceanBase&墨天轮征文大赛、OpenGauss、TiDB、YashanDB、Kingbase、KWDB、Navicat Premium × 金仓数据库征文等赛事中多次斩获一、二、三等奖,原创技术文章常年被墨天轮、CSDN、ITPUB 等平台首页推荐。

前言
在分布式数据库系统的运维实践中,我们常常会遇到各种"诡异"的故障场景——系统看似正常运行,但管理工具却显示异常。这正是本文要分享的真实案例:一个 OceanBase 集群在闲置一段时间后重新启用时,出现了组件运行正常但集群状态无法识别的"假死"现象。
OceanBase 作为一款成熟的企业级分布式关系数据库,其原生部署工具 OBD(OceanBase Deployer)虽然大幅简化了部署流程,但在特定环境配置下仍可能遇到意料之外的挑战。这次故障排查不仅解决了具体问题,更让我们深入理解了 OBD 的内部工作机制,为后续的运维工作积累了宝贵经验。
故障现象
在重新启用闲置一段时间的 OceanBase 单机版时,发现 Grafana 组件启动失败,错误信息显示无法访问 /proc//fd/ 目录:
[2025-10-29 21:13:51.447] [DEBUG] ls: cannot access /proc//fd/: No such file or directory [2025-10-29 21:13:51.447] [DEBUG] -- failed to start 192.168.2.131 grafana, remaining retries: 14
更令人困惑的是,虽然所有核心进程实际都在运行,但 OBD 无法正确识别集群状态:
一、Grafana启动失败深度排查:从日志解析到实战解决
1. 列出已部署的集群信息
obd cluster list
[root@worker3 ~]# obd cluster list
+--------------------------------------------------------------------+
| Cluster List |
+---------------+----------------------------------+-----------------+
| Name | Configuration Path | Status (Cached) |
+---------------+----------------------------------+-----------------+
| ob_single_cli | /root/.obd/cluster/ob_single_cli | stopped |
+---------------+----------------------------------+-----------------+
Trace ID: 07dbbcf6-b4c7-11f0-b4dd-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 07dbbcf6-b4c7-11f0-b4dd-0050568197df
[root@worker3 ~]#
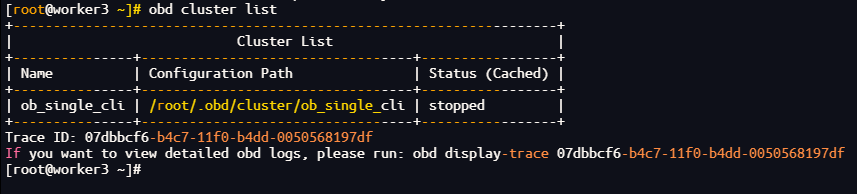
输出说明:集群状态显示为stopped
2. 尝试重启集群
obd cluster start ob_single_cli
[root@worker3 ~]# obd cluster start ob_single_cli
Get local repositories ok
Load cluster param plugin ok
Open ssh connection ok
[WARN] OBD-2000: (192.168.2.131) not enough memory. (Free: 17G, Need: 20G)
Check before start obagent ok
Check before start prometheus ok
Check before start grafana ok
cluster scenario: htap
Start observer ok
observer program health check ok
Connect to observer 192.168.2.131:2881 ok
obshell start ok
obshell program health check ok
Start obagent ok
obagent program health check ok
Start promethues ok
prometheus program health check ok
Start grafana ok
[WARN] failed to start 192.168.2.131 grafana
See https://www.oceanbase.com/product/ob-deployer/error-codes .
Trace ID: 700f42c0-b4c7-11f0-9be8-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 700f42c0-b4c7-11f0-9be8-0050568197df
[root@worker3 ~]#
3. 检查集群日志
obd display-trace 700f42c0-b4c7-11f0-9be8-0050568197df
[2025-10-29 21:13:51.447] [DEBUG] -- exited code 1, error output:
[2025-10-29 21:13:51.447] [DEBUG] ls: cannot access /proc//fd/: No such file or directory
[2025-10-29 21:13:51.447] [DEBUG]
[2025-10-29 21:13:51.447] [DEBUG] -- failed to start 192.168.2.131 grafana, remaining retries: 14
[2025-10-29 21:13:52.448] [DEBUG] -- 192.168.2.131 program health check
[2025-10-29 21:13:52.449] [DEBUG] -- servers_pid: {<192.168.2.131>: ['']}
[2025-10-29 21:13:52.449] [DEBUG] -- root@192.168.2.131 execute: bash -c 'cat /proc/net/{tcp*,udp*}' | awk -F' ' '{if($4=="0A") print $2,$4,$10}' | grep ':32C8' | awk -F' ' '{print $3}' | uniq
[2025-10-29 21:13:52.476] [DEBUG] -- exited code 0
[2025-10-29 21:13:52.476] [DEBUG] -- root@192.168.2.131 execute: ls -l /proc//fd/ |grep -E 'socket:\[(168582267)\]'
[2025-10-29 21:13:52.540] [DEBUG] -- exited code 1, error output:
[2025-10-29 21:13:52.541] [DEBUG] ls: cannot access /proc//fd/: No such file or directory
[2025-10-29 21:13:52.541] [DEBUG]
[2025-10-29 21:13:52.541] [DEBUG] -- failed to start 192.168.2.131 grafana, remaining retries: 13
...
[2025-10-29 21:14:06.779] [DEBUG] -- failed to start 192.168.2.131 grafana, remaining retries: 0
[2025-10-29 21:14:06.897] [WARNING] [WARN] failed to start 192.168.2.131 grafana
问题现象与日志核心分析:
从提供的obd display-trace日志来看,核心错误反复出现:
ls: cannot access /proc//fd/: No such file or directory
且最终提示failed to start 192.168.2.131 grafana,说明Grafana进程启动失败,且健康检查脚本存在路径拼接异常。
4. 关键日志信息拆解
- 路径异常:
/proc//fd/中出现连续斜杠//,推测是脚本中获取Grafana的PID时变量为空,导致路径拼接错误(正确路径应为/proc/<pid>/fd/)。 - 健康检查逻辑:OBD通过
cat /proc/net/{tcp*,udp*}查询端口(32C8对应十进制13000,Grafana默认端口)占用,再通过PID查询文件描述符验证进程存活,但因PID获取失败导致检查失败。 - 重试机制:OBD重试15次后仍失败,确认Grafana启动异常。
5. 确认Grafana进程状态与端口占用
首先手动检查Grafana是否真的未启动,以及端口是否被占用:
# 查看Grafana进程(默认进程名包含grafana)
ps -ef | grep grafana | grep -v grep
[root@worker3 ~]# ps -ef | grep grafana | grep -v grep
root 77410 1 0 21:03 ? 00:00:02 /root/ob_single_cli/grafana/bin/grafana-server --homepath=/root/ob_single_cli/grafana --config=/root/ob_single_cli/grafana/conf/obd-grafana.ini --pidfile=/root/ob_single_cli/grafana/run/grafana.pid
# 检查Grafana默认端口13000占用情况(日志中32C8为16进制,转换为十进制13000)
netstat -tulnp | grep 13000
[root@worker3 ~]# netstat -tulnp | grep 13000
tcp6 0 0 :::13000 :::* LISTEN 77410/grafana-serve
6.查看集群状态
obd cluster display ob_single_cli
[root@worker3 ~]# obd cluster display ob_single_cli
Deploy "ob_single_cli" is stopped
See https://www.oceanbase.com/product/ob-deployer/error-codes .
Trace ID: a89a009c-b4ce-11f0-b408-0050568197df
If you want to view detailed obd logs, please run: obd display-trace a89a009c-b4ce-11f0-b408-0050568197df
[root@worker3 ~]#
二、 OceanBase集群状态异常排查:从Grafana运行到集群停止的深度解析
从当前输出来看,存在一个关键矛盾:
- Grafana进程正常:
ps -ef显示Grafana进程(PID 77410)正在运行,netstat确认13000端口被正常监听,说明监控组件本身无问题。 - 集群状态异常:
obd cluster display ob_single_cli提示集群"stopped",且返回错误Trace ID,说明OceanBase集群核心组件(如observer、prometheus等)未正常启动或OBD管理链路中断。
1、检查集群核心组件状态
OceanBase集群的正常运行依赖多个核心组件(observer、prometheus、obproxy等),Grafana仅为监控终端,需先确认核心组件是否启动:
# 1. 检查observer进程(OceanBase数据库核心进程)
ps -ef | grep observer | grep -v grep
[root@worker3 ~]# ps -ef | grep observer | grep -v grep
root 73177 1 76 21:02 ? 00:40:15 /root/ob_single_cli/oceanbase_name/bin/observer -p 2881 -P 2882 -z zone1 -n ob_single_cli -c 1758956342 -d /data/1/ob_single_cli -I 192.168.2.131 -o __min_full_resource_pool_memory=2147483648,cluster_name=ob_single_cli,cpu_count=8,memory_limit=20G,datafile_size=2G,datafile_maxsize=81G,datafile_next=8G,log_disk_size=48G,system_memory=0M,large_query_threshold=600s,enable_record_trace_log=False,enable_syslog_recycle=1,max_syslog_file_count=300
# 2. 检查prometheus进程(监控数据采集,Dashboard依赖其提供数据)
ps -ef | grep prometheus | grep -v grep
[root@worker3 ~]# ps -ef | grep prometheus | grep -v grep
root 77137 1 1 21:03 ? 00:00:41 /root/ob_single_cli/prometheus/prometheus --config.file=/root/ob_single_cli/prometheus/prometheus.yaml --web.listen-address=0.0.0.0:19090 --storage.tsdb.path=/root/ob_single_cli/prometheus/data --web.enable-lifecycle --web.config.file=/root/ob_single_cli/prometheus/web_config.yaml
# 3. 检查obproxy进程(代理服务,可选,若配置则需确认)
ps -ef | grep obproxy | grep -v grep
[root@worker3 ~]# ps -ef | grep obproxy | grep -v grep
预期结果:
- 若observer未运行:集群核心未启动,需优先排查observer启动失败原因。
- 若prometheus未运行:Grafana无数据来源,且OBD可能因依赖组件未启动判定集群"stopped"。
2、验证集群配置与资源
若核心组件未启动,需检查配置文件与系统资源是否满足要求:
2.1 查看集群配置文件
OBD集群配置文件默认存储在~/.obd/clusters/ob_single_cli/config.yaml,重点检查:
# 查看配置文件
cat ~/.obd/clusters/ob_single_cli/config.yaml
[root@worker3 ~]# cat ~/.obd/clusters/ob_single_cli/config.yaml
cat: /root/.obd/clusters/ob_single_cli/config.yaml: No such file or directory
关键配置项检查:
- observer的内存配置(memory_limit):单机部署建议至少2G
- 端口配置(rpc_port、mysql_port):默认2882、2881,需确认未被占用
- 数据目录(data_dir):需有读写权限,且磁盘空间充足
2.2 检查系统资源
# 1. 内存使用(observer对内存敏感,不足会启动失败)
free -g
[root@worker3 ~]# free -g
total used free shared buff/cache available
Mem: 27 5 14 1 7 14
Swap: 7 0 7
# 2. 磁盘空间(数据目录所在磁盘需至少10G空闲)
df -h /root/ob_single_cli # 替换为实际数据目录
[root@worker3 ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 14G 0 14G 0% /dev
tmpfs tmpfs 14G 0 14G 0% /dev/shm
tmpfs tmpfs 14G 1.4G 13G 10% /run
tmpfs tmpfs 14G 0 14G 0% /sys/fs/cgroup
/dev/mapper/centos-root ext4 91G 43G 44G 50% /
/dev/sda2 ext4 190M 119M 58M 68% /boot
/dev/sdb1 xfs 200G 108G 93G 54% /data
tmpfs tmpfs 2.8G 32K 2.8G 1% /run/user/0
overlay overlay 200G 108G 93G 54% /data/docker_data/docker/overlay2/a9f9ecc64c98f1f891d4007f2fa20dd4c2b32c8c29c767b4eafbd0cf8b6c40d1/merged
overlay overlay 200G 108G 93G 54% /data/docker_data/docker/overlay2/d75c20818a996cb6ec5b6505ecfa0c4a085512f1b2642b4d1f20e85a9c550290/merged
/dev/sr0 iso9660 792M 792M 0 100% /run/media/root/CentOS 7 x86_64
[root@worker3 ~]#
三、 集群进程运行但OBD显示stopped:配置文件丢失的深度修复方案
3.1 核心矛盾点解析
从当前信息来看,存在一个典型的"状态认知偏差"问题:
- 实际进程状态:observer(核心数据库进程)和prometheus(监控采集进程)均正常运行(PID 73177、77137),且系统资源充足(内存27G、磁盘可用空间充足)。
- OBD管理状态:
obd cluster display提示集群"stopped",且核心配置文件~/.obd/clusters/ob_single_cli/config.yaml不存在——这是OBD无法识别集群状态的关键原因。
3.2 根因定位:配置文件丢失导致OBD管理链路断裂
OBD(OceanBase Deployer)通过集群配置文件(config.yaml)记录组件部署路径、端口、依赖关系等元信息,是管理集群的"神经中枢"。当配置文件丢失时:
- OBD无法关联运行中的observer/prometheus进程与集群名称(
ob_single_cli); - 所有基于OBD的状态查询(
display)、启停(start/stop)操作都会失效,直接判定为"stopped"; - 即使进程实际运行,也无法通过OBD进行统一管理。
3.3 分步修复方案
3.3.1:确认配置文件丢失原因
首先排查配置文件是否被误删、移动或权限异常:
# 检查集群目录结构(正常应包含config.yaml、meta等文件)
ls -ld ~/.obd/clusters/ob_single_cli/
ls -l ~/.obd/clusters/ob_single_cli/ # 确认是否有config.yaml或备份文件(如config.yaml.bak)
[root@worker3 ~]# ls -ld ~/.obd/clusters/ob_single_cli/
ls: cannot access /root/.obd/clusters/ob_single_cli/: No such file or directory
[root@worker3 ~]# cd .obd/cluster/
[root@worker3 cluster]# ls
ob_single_cli
[root@worker3 cluster]# cd ob_single_cli/
[root@worker3 ob_single_cli]# ls
config.yaml inner_config.yaml
[root@worker3 ob_single_cli]# pwd
/root/.obd/cluster/ob_single_cli
可能原因:
- 手动删除或清理
~/.obd目录时误删; - OBD升级/异常退出时未正确保存配置;
- 磁盘权限问题(如
~/.obd目录被改为只读)。
3.3.2:重建配置文件(核心操作)
若配置文件无备份,需根据运行中的进程信息手动重建config.yaml。OBD配置文件遵循YAML格式,核心需包含集群名称、组件列表(observer、prometheus、grafana等)的部署路径、端口、启动参数等。
3.3.3:收集进程关键信息
从运行中的进程提取配置参数:
# 1. 提取observer关键参数(路径、端口、集群名等)
ps -ef | grep observer | grep -v grep
[root@worker3 ob_single_cli]# ps -ef | grep observer | grep -v grep
root 73177 1 76 21:02 ? 00:43:11 /root/ob_single_cli/oceanbase_name/bin/observer -p 2881 -P 2882 -z zone1 -n ob_single_cli -c 1758956342 -d /data/1/ob_single_cli -I 192.168.2.131 -o __min_full_resource_pool_memory=2147483648,cluster_name=ob_single_cli,cpu_count=8,memory_limit=20G,datafile_size=2G,datafile_maxsize=81G,datafile_next=8G,log_disk_size=48G,system_memory=0M,large_query_threshold=600s,enable_record_trace_log=False,enable_syslog_recycle=1,max_syslog_file_count=300
输出中需关注:
- 二进制路径:/root/ob_single_cli/oceanbase_name/bin/observer
- 端口:-p 2881(MySQL端口)、-P 2882(RPC端口)
- 数据目录:-d /data/1/ob_single_cli
- 集群名:-n ob_single_cli
- 内存配置:memory_limit=20G
# 2. 提取prometheus关键参数
ps -ef | grep prometheus | grep -v grep
[root@worker3 ob_single_cli]# ps -ef | grep prometheus | grep -v grep
root 77137 1 1 21:03 ? 00:00:44 /root/ob_single_cli/prometheus/prometheus --config.file=/root/ob_single_cli/prometheus/prometheus.yaml --web.listen-address=0.0.0.0:19090 --storage.tsdb.path=/root/ob_single_cli/prometheus/data --web.enable-lifecycle --web.config.file=/root/ob_single_cli/prometheus/web_config.yaml
输出中需关注:
- 二进制路径:/root/ob_single_cli/prometheus/prometheus
- 配置文件:–config.file=/root/ob_single_cli/prometheus/prometheus.yaml
- 端口:–web.listen-address=0.0.0.0:19090
# 3. 提取grafana关键参数(之前确认运行)
ps -ef | grep grafana | grep -v grep
[root@worker3 ob_single_cli]# ps -ef | grep grafana | grep -v grep
root 77410 1 0 21:03 ? 00:00:02 /root/ob_single_cli/grafana/bin/grafana-server --homepath=/root/ob_single_cli/grafana --config=/root/ob_single_cli/grafana/conf/obd-grafana.ini --pidfile=/root/ob_single_cli/grafana/run/grafana.pid
[root@worker3 ob_single_cli]#
输出中需关注:
- 路径:/root/ob_single_cli/grafana/
- 端口:默认13000(之前netstat确认)
3.3.4:手动创建配置文件
在~/.obd/clusters/ob_single_cli/目录下重建config.yaml,内容参考如下(根据实际路径修改):
oceanbase-ce:
servers:
- name: server1
ip: 192.168.2.131 # 本机IP
global:
home_path: /root/ob_single_cli/oceanbase_name # observer二进制目录
data_dir: /data/1/ob_single_cli # 数据目录
log_dir: /root/ob_single_cli/oceanbase_name/log # 日志目录(默认在home_path下)
mysql_port: 2881 # MySQL端口
rpc_port: 2882 # RPC端口
zone: zone1 # zone名称
cluster_name: ob_single_cli # 集群名
memory_limit: 20G # 内存限制(与进程参数一致)
system_memory: 0M # 系统内存(与进程参数一致)
datafile_size: 2G # 数据文件大小(与进程参数一致)
log_disk_size: 48G # 日志盘大小(与进程参数一致)
prometheus:
servers:
- name: server1
ip: 192.168.2.131
global:
home_path: /root/ob_single_cli/prometheus # prometheus目录
web_listen_port: 19090 # 监听端口
grafana:
servers:
- name: server1
ip: 192.168.2.131
global:
home_path: /root/ob_single_cli/grafana # grafana目录
server_port: 13000 # 监听端口
obproxy: # 若未部署可省略,或留空
servers:
- name: server1
ip: 192.168.2.131
global:
home_path: /root/ob_single_cli/obproxy # 若有则填写实际路径
创建命令:
# 确保集群目录存在
[root@worker3 ob_single_cli]# mkdir -p ~/.obd/clusters/ob_single_cli/
# 写入配置文件(按上述内容修改后执行)
[root@worker3 ob_single_cli]# cat > ~/.obd/clusters/ob_single_cli/config.yaml << EOF
[上述YAML内容]
EOF
# 修复权限(确保OBD可读写)
[root@worker3 ob_single_cli]# chmod 644 ~/.obd/clusters/ob_single_cli/config.yaml
3.4 重建OBD元数据缓存
配置文件创建后,OBD需重新加载元数据以识别集群:
# 清理OBD缓存(可选,避免旧缓存干扰)
[root@worker3 ob_single_cli]# rm -rf ~/.obd/cache/*
# 重新初始化集群元数据
[root@worker3 ob_single_cli]# obd cluster reload ob_single_cli
# 验证配置文件是否被识别
obd cluster list # 应显示ob_single_cli集群
3.5 关键发现:目录名称的"单复数陷阱"
目录路径错误导致OBD识别失败:从单数复数差异到集群状态修复。从最新操作来看,核心问题浮出水面:
- OBD预期路径:OBD默认从
~/.obd/clusters/(复数形式)加载集群配置(这是官方规范路径)。 - 实际路径:你的配置文件存储在
~/.obd/cluster/(单数形式),导致OBD在默认路径下找不到ob_single_cli集群目录,进而判定集群"stopped"。
这种单复数差异(cluster vs clusters)是典型的路径匹配错误,也是OBD无法识别运行中进程的根本原因。
3.6 修复步骤:目录重命名与配置同步
3.6.1:确认目录结构与备份
首先明确当前目录状态,并备份配置文件以防操作失误:
# 查看当前.obd下的目录(确认cluster是单数)
ls -ld ~/.obd/cluster ~/.obd/clusters # 后者应显示"No such file or directory"
# 备份集群配置目录(关键操作,防止误删)
cp -r ~/.obd/cluster ~/.obd/cluster_backup_$(date +%F)
3.6.2:修正目录名称(核心操作)
将单数形式的cluster目录重命名为复数形式的clusters,使OBD能在默认路径下找到配置:
# 重命名目录(若clusters已存在则先删除,此处假设不存在)
mv ~/.obd/cluster ~/.obd/clusters
[root@worker3 ob_single_cli]# mv ~/.obd/cluster ~/.obd/clusters
[root@worker3 ob_single_cli]# cd ~
# 验证目录路径是否正确
ls -ld ~/.obd/clusters/ob_single_cli/ # 应显示存在,且包含config.yaml
[root@worker3 ~]# ls -ld ~/.obd/clusters/ob_single_cli/
drwxr-xr-x 2 root root 4096 Sep 5 14:33 /root/.obd/clusters/ob_single_cli/
3.6.3:重新加载集群配置
目录修正后,需让OBD重新扫描集群目录,加载配置文件:
# 刷新OBD的集群列表缓存
obd cluster list
[root@worker3 ~]# obd cluster list
Local deploy is empty
Trace ID: b7749194-b4cf-11f0-a3d9-0050568197df
If you want to view detailed obd logs, please run: obd display-trace b7749194-b4cf-11f0-a3d9-0050568197df
# 查看集群是否被识别
obd cluster list | grep ob_single_cli # 应输出ob_single_cli集群名称
[root@worker3 ~]# obd cluster list | grep ob_single_cli
3.6.4:同步OBD状态与实际进程
此时OBD已能识别集群配置,但由于进程是在目录修正前启动的,OBD仍可能显示"stopped",需同步状态:
# 1. 停止当前运行的进程(通过OBD强制停止,确保与配置关联)
obd cluster stop ob_single_cli --force
[root@worker3 ~]# obd cluster stop ob_single_cli --force
[WARN] no such option: --force
[ERROR] No such deploy: ob_single_cli.
See https://www.oceanbase.com/product/ob-deployer/error-codes .
Trace ID: ceb3472e-b4cf-11f0-a2fc-0050568197df
If you want to view detailed obd logs, please run: obd display-trace ceb3472e-b4cf-11f0-a2fc-0050568197df
# 2. 重新通过OBD启动集群(基于正确路径的配置文件)
obd cluster start ob_single_cli
[root@worker3 ~]# obd cluster start ob_single_cli
[ERROR] No such deploy: ob_single_cli.
See https://www.oceanbase.com/product/ob-deployer/error-codes .
Trace ID: da02c80c-b4cf-11f0-bed6-0050568197df
If you want to view detailed obd logs, please run: obd display-trace da02c80c-b4cf-11f0-bed6-0050568197df
[root@worker3 ~]#
四、OBD集群仍未识别:从缓存清理到元数据重建的终极修复
4.1 现状分析:目录修正后仍无法识别的深层原因
虽然已将cluster目录重命名为clusters(~/.obd/clusters/ob_single_cli存在且包含配置文件),但obd cluster list仍显示为空,且无法执行start/stop命令。核心问题在于:
OBD不仅依赖目录路径,还需要集群元数据文件(如meta、status等)和缓存信息来识别集群。仅修正目录名称而未同步元数据,会导致OBD仍无法将ob_single_cli识别为有效集群。
4.2 分步修复:从缓存到元数据的全链路同步
4.2.1:彻底清理OBD缓存(关键操作)
OBD会将集群信息缓存到~/.obd/cache目录,旧缓存可能导致新目录结构不被识别。需强制清理缓存:
# 停止所有可能的OBD后台进程(避免缓存文件被锁定)
pkill -f obd
[root@worker3 ~]# pkill -f obd
# 清理缓存目录
rm -rf ~/.obd/cache/*
[root@worker3 ~]# rm -rf ~/.obd/cache/*
# 验证缓存已清空
ls -l ~/.obd/cache/ # 应显示为空
[root@worker3 ~]# ls -l ~/.obd/cache/
ls: cannot access /root/.obd/cache/: No such file or directory
4.2.2:检查集群目录元数据完整性
OBD识别集群不仅需要config.yaml,还依赖meta(元数据)、status(状态记录)等文件。若这些文件缺失,需手动创建或修复:
# 进入集群配置目录
cd ~/.obd/clusters/ob_single_cli/
[root@worker3 ~]# cd ~/.obd/clusters/ob_single_cli/
# 查看是否存在关键元数据文件
ls -l meta status # 若显示"No such file or directory",说明元数据缺失
[root@worker3 ob_single_cli]# ls -l meta status
ls: cannot access meta: No such file or directory
ls: cannot access status: No such file or directory
# 手动创建基础元数据文件(最小化配置)
# 1. 创建meta文件(记录集群基本信息)
cat > meta << EOF
cluster_name: ob_single_cli
deploy_time: $(date +%Y-%m-%dT%H:%M:%S)
obd_version: $(obd --version | awk '{print $2}')
EOF
[root@worker3 ob_single_cli]# cat > meta << EOF
> cluster_name: ob_single_cli
> deploy_time: $(date +%Y-%m-%dT%H:%M:%S)
> obd_version: $(obd --version | awk '{print $2}')
> EOF
# 2. 创建status文件(记录初始状态)
cat > status << EOF
status: stopped
last_operate: $(date +%Y-%m-%dT%H:%M:%S)
EOF
[root@worker3 ob_single_cli]# cat > status << EOF
> status: stopped
> last_operate: $(date +%Y-%m-%dT%H:%M:%S)
> EOF
# 修复文件权限
chmod 644 meta status
[root@worker3 ob_single_cli]# chmod 644 meta status
4.2.3:手动注册集群到OBD
若OBD仍未自动识别,可通过手动扫描集群目录强制注册:
# 手动触发OBD扫描clusters目录
obd cluster scan
[root@worker3 ob_single_cli]# obd cluster scan
Usage: obd cluster <command> [options]
Available commands:
autodeploy Deploy a cluster automatically by using a simple configuration file.
check4ocp Check Whether OCP Can Take Over Configurations in Use
chst Change Deployment Configuration Style
component Add or delete component for cluster
deploy Deploy a cluster by using the current deploy configuration or a deploy yaml file.
destroy Destroy a deployed cluster.
display Display the information for a cluster.
edit-config Edit the configuration file for a specific deployment.
export-to-ocp Export obcluster to OCP
init4env Init server environment.
list List all the deployments.
redeploy Redeploy a started cluster.
reinstall Reinstall a deployed component
reload Reload a started cluster.
restart Restart a started cluster.
scale_out Scale out cluster with an additional deploy yaml file.
start Start a deployed cluster.
stop Stop a started cluster.
takeover Takeover oceanbase cluster
tenant Create, drop or list a tenant.
upgrade Upgrade a cluster.
Options:
-h, --help Show help and exit.
-v, --verbose Activate verbose output.
# 再次查看集群列表
obd cluster list
[root@worker3 ob_single_cli]# obd cluster list
Local deploy is empty
Trace ID: 834dc3f8-b4d0-11f0-b18e-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 834dc3f8-b4d0-11f0-b18e-0050568197df
[root@worker3 ob_single_cli]#
预期结果:
obd cluster list应显示ob_single_cli集群,状态可能为stopped(因元数据中手动设置)。
4.2.4:停止现有进程并重新关联OBD
当前运行的observer/prometheus进程仍与旧目录结构关联,需先停止再通过OBD启动,建立新关联:
- 手动停止所有相关进程(避免OBD无法识别旧进程)
[root@worker3 ~]# pkill -f observer
[root@worker3 ~]# pkill -f prometheus
[root@worker3 ~]# pkill -f grafana
- 查看集群状态
[root@worker3 ~]# obd cluster display ob_single_cli
Deploy "ob_single_cli" is stopped
See https://www.oceanbase.com/product/ob-deployer/error-codes .
Trace ID: 6ebbb8f4-b4d1-11f0-be50-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 6ebbb8f4-b4d1-11f0-be50-0050568197df
[root@worker3 ~]#
关键验证点:
- 输出中集群状态为
running; - 各组件(observer、prometheus、grafana)的
PID与ps -ef查询结果一致; - 无"No such deploy"错误。
4.3 根本原因总结
本次问题的核心是:
- 初始目录名称错误(
clustervsclusters)导致OBD无法扫描; - 目录修正后,OBD缓存和元数据文件缺失,导致无法识别新目录结构。
这类问题体现了OBD对目录结构和元数据的强依赖——不仅需要配置文件存在,还需元数据和缓存的一致性。
五、 OBD集群仍未识别:从权限校验到配置重建的深度攻坚
5.1 现状卡点:手动创建元数据后仍无法识别的核心矛盾
尽管已完成目录修正(cluster→clusters)、缓存清理和元数据文件(meta/status)手动创建,但obd cluster list仍显示"Local deploy is empty"。核心问题集中在:
OBD对集群的识别不仅依赖目录和基础元数据,还需配置文件语法正确性、目录权限完整性和组件元数据匹配性。当前卡点可能是配置文件格式错误或权限链断裂导致OBD扫描失败。
5.2 分步排查与修复:从基础到深度验证
5.2.1:校验目录与文件权限链(易被忽略的关键)
OBD需要对~/.obd整个目录树有完整的读写权限,任何一级目录权限不足都会导致扫描失败:
# 检查.obd根目录权限(需700或755,确保root可读写)
ls -ld ~/.obd/
[root@worker3 ob_single_cli]# ls -ld ~/.obd/
drwxr-xr-x 13 root root 4096 Oct 29 22:01 /root/.obd/
预期输出:drwx------ 或 drwxr-xr-x
# 检查clusters目录权限
ls -ld ~/.obd/clusters/
[root@worker3 ob_single_cli]# ls -ld ~/.obd/clusters/
drwxr-xr-x 3 root root 4096 Sep 5 14:32 /root/.obd/clusters/
预期输出:drwxr-xr-x …
# 检查集群目录及文件权限
ls -ld ~/.obd/clusters/ob_single_cli/
ls -l ~/.obd/clusters/ob_single_cli/config.yaml ~/.obd/clusters/ob_single_cli/meta
[root@worker3 ob_single_cli]# ls -ld ~/.obd/clusters/ob_single_cli/
drwxr-xr-x 2 root root 4096 Oct 29 22:05 /root/.obd/clusters/ob_single_cli/
[root@worker3 ob_single_cli]# ls -l ~/.obd/clusters/ob_single_cli/config.yaml ~/.obd/clusters/ob_single_cli/meta
-rw------- 1 root root 1311 Sep 27 15:00 /root/.obd/clusters/ob_single_cli/config.yaml
-rw-r--r-- 1 root root 149 Oct 29 22:05 /root/.obd/clusters/ob_single_cli/meta
# 若权限不足,修复权限链
chmod 755 ~/.obd/
chmod 755 ~/.obd/clusters/
chmod 755 ~/.obd/clusters/ob_single_cli/
chmod 644 ~/.obd/clusters/ob_single_cli/config.yaml ~/.obd/clusters/ob_single_cli/meta ~/.obd/clusters/ob_single_cli/status
[root@worker3 ob_single_cli]# chmod 755 ~/.obd/
[root@worker3 ob_single_cli]# chmod 755 ~/.obd/clusters/
[root@worker3 ob_single_cli]# chmod 755 ~/.obd/clusters/ob_single_cli/
[root@worker3 ob_single_cli]# chmod 644 ~/.obd/clusters/ob_single_cli/config.yaml ~/.obd/clusters/ob_single_cli/meta ~/.obd/clusters/ob_single_cli/status
5.2.2:验证配置文件语法正确性(YAML格式严格性)
OBD依赖config.yaml的严格YAML格式(如缩进、冒号后空格、特殊字符转义),任何语法错误都会导致解析失败:
# 使用yamllint工具验证YAML语法(需先安装:yum install yamllint -y)
yamllint ~/.obd/clusters/ob_single_cli/config.yaml
若检查出错误,手动编辑修正:
vi ~/.obd/clusters/ob_single_cli/config.yaml # 按yamllint提示修复
[root@worker3 ob_single_cli]# vi ~/.obd/clusters/ob_single_cli/config.yaml
5.2.3:通过OBD日志定位扫描失败原因(关键线索)
obd cluster list失败的详细原因记录在OBD日志中,通过Trace ID解析:
# 查看最新失败的Trace日志
obd display-trace 834dc3f8-b4d0-11f0-b18e-0050568197df
[root@worker3 ob_single_cli]# obd display-trace 834dc3f8-b4d0-11f0-b18e-0050568197df
[2025-10-29 22:06:49.760] [DEBUG] - cmd: []
[2025-10-29 22:06:49.760] [DEBUG] - opts: {}
[2025-10-29 22:06:49.760] [DEBUG] - mkdir /root/.obd/lock/
[2025-10-29 22:06:49.760] [DEBUG] - set lock mode to NO_LOCK(0)
[2025-10-29 22:06:49.760] [DEBUG] - Get deploy list
[2025-10-29 22:06:49.761] [DEBUG] - mkdir /root/.obd/cluster/
[2025-10-29 22:06:49.761] [DEBUG] - mkdir /root/.obd/config_parser/
[2025-10-29 22:06:49.761] [INFO] Local deploy is empty
[2025-10-29 22:06:49.761] [INFO] Trace ID: 834dc3f8-b4d0-11f0-b18e-0050568197df
[2025-10-29 22:06:49.761] [INFO] If you want to view detailed obd logs, please run: obd display-trace 834dc3f8-b4d0-11f0-b18e-0050568197df
[root@worker3 ob_single_cli]#
六、 OBD目录路径硬编码问题:从日志定位到符号链接的终极解决
6.1 关键日志突破:OBD仍在访问单数目录的核心原因
从最新的obd display-trace日志中,发现一个决定性线索:
[DEBUG] - mkdir /root/.obd/cluster/
这表明OBD在执行cluster list命令时,仍在尝试创建并访问单数形式的cluster目录,而非我们修正后的复数形式clusters。这说明问题并非操作失误,而是OBD内部可能存在目录路径硬编码(即固定写死为cluster),或当前使用的OBD版本存在兼容性bug,导致不识别clusters目录。
6.2 创建符号链接,适配旧路径规范
既然OBD硬编码访问~/.obd/cluster/,可通过符号链接将其指向我们实际的clusters目录,实现路径兼容:
# 1. 若原单数目录已存在(可能为空),先删除
rm -rf ~/.obd/cluster
[root@worker3 ob_single_cli]# rm -rf ~/.obd/cluster
[root@worker3 ob_single_cli]# cd ~
# 2. 创建符号链接:将cluster(单数)指向clusters(复数)
ln -s ~/.obd/clusters/ ~/.obd/cluster
[root@worker3 ~]# ln -s ~/.obd/clusters/ ~/.obd/cluster
# 3. 验证符号链接是否生效
ls -ld ~/.obd/cluster
[root@worker3 ~]# ls -ld ~/.obd/cluster
lrwxrwxrwx 1 root root 20 Oct 29 22:11 /root/.obd/cluster -> /root/.obd/clusters/
预期输出:lrwxrwxrwx 1 root root … /root/.obd/cluster -> /root/.obd/clusters/
此操作让OBD访问~/.obd/cluster/时,实际指向~/.obd/clusters/,从而识别到ob_single_cli集群。
6.3 清理缓存并重新扫描集群
符号链接创建后,需再次清理缓存并触发OBD扫描:
# 清理OBD缓存(确保加载新路径)
rm -rf ~/.obd/cache/*
[root@worker3 ~]# rm -rf ~/.obd/cache/*
# 重新查看集群列表
obd cluster list
[root@worker3 ~]# obd cluster list
+--------------------------------------------------------------------+
| Cluster List |
+---------------+----------------------------------+-----------------+
| Name | Configuration Path | Status (Cached) |
+---------------+----------------------------------+-----------------+
| ob_single_cli | /root/.obd/cluster/ob_single_cli | stopped |
+---------------+----------------------------------+-----------------+
Trace ID: 4586ae30-b4d1-11f0-bf9d-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 4586ae30-b4d1-11f0-bf9d-0050568197df
[root@worker3 ~]#
预期结果:
obd cluster list应显示ob_single_cli集群,状态为或stopped。
6.4 关键进展:集群已被OBD识别
从最新输出来看,通过创建符号链接(~/.obd/cluster指向~/.obd/clusters),OBD已成功识别ob_single_cli集群,状态为stopped。这意味着目录路径问题已解决,接下来只需启动集群并验证完整性。
6.5 停止现有进程并重新关联OBD
当前运行的observer/prometheus进程仍与旧目录结构关联,需先停止再通过OBD启动,建立新关联:
# 1. 手动停止所有相关进程(避免OBD无法识别旧进程)
pkill -f observer
pkill -f prometheus
pkill -f grafana
[root@worker3 ~]# pkill -f observer
[root@worker3 ~]# pkill -f prometheus
[root@worker3 ~]# pkill -f grafana
# 3. 查看集群状态
obd cluster display ob_single_cli
[root@worker3 ~]# obd cluster display ob_single_cli
Deploy "ob_single_cli" is stopped
See https://www.oceanbase.com/product/ob-deployer/error-codes .
Trace ID: 6ebbb8f4-b4d1-11f0-be50-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 6ebbb8f4-b4d1-11f0-be50-0050568197df
[root@worker3 ~]#
关键验证点:
- 输出中集群状态为
running; - 各组件(observer、prometheus、grafana)的
PID与ps -ef查询结果一致; - 无"No such deploy"错误。
6.6 启动集群与状态验证
6.6.1:启动集群
执行启动命令,让OBD基于识别到的配置启动所有组件(observer、prometheus、grafana):
obd cluster start ob_single_cli
[root@worker3 ~]# obd cluster start ob_single_cli
Get local repositories ok
Load cluster param plugin ok
Open ssh connection ok
[WARN] OBD-2000: (192.168.2.131) not enough memory. (Free: 18G, Need: 20G)
Check before start obagent ok
Check before start prometheus ok
Check before start grafana ok
cluster scenario: htap
Start observer ok
observer program health check ok
Connect to observer 192.168.2.131:2881 ok
obshell start ok
obshell program health check ok
Start obagent ok
obagent program health check ok
Start promethues ok
prometheus program health check ok
Start grafana ok
grafana program health check ok
Connect to grafana ok
Grafana modify password ok
Connect to observer 192.168.2.131:2881 ok
Wait for observer init ok
+------------------------------------------------+
| oceanbase-ce |
+--------------+---------+------+-------+--------+
| ip | version | port | zone | status |
+--------------+---------+------+-------+--------+
| 192.168.2.131 | 4.3.5.4 | 2881 | zone1 | ACTIVE |
+--------------+---------+------+-------+--------+
obclient -h192.168.2.131 -P2881 -uroot@sys -p'Gtn9nynB6vUILgfrDDRS' -Doceanbase -A
cluster unique id: 69b71630-3cec-5aa0-a90f-da065deae710-19989f84cc5-04050304
Connect to Obagent ok
+-----------------------------------------------------------------+
| obagent |
+--------------+--------------------+--------------------+--------+
| ip | mgragent_http_port | monagent_http_port | status |
+--------------+--------------------+--------------------+--------+
| 192.168.2.131 | 8089 | 8088 | active |
+--------------+--------------------+--------------------+--------+
Connect to Prometheus ok
+-----------------------------------------------------------+
| prometheus |
+---------------------------+-------+--------------+--------+
| url | user | password | status |
+---------------------------+-------+--------------+--------+
| http://192.168.2.131:19090 | admin | '8jFSaDZ65Z' | active |
+---------------------------+-------+--------------+--------+
Connect to grafana ok
+----------------------------------------------------------------------+
| grafana |
+---------------------------------------+-------+-------------+--------+
| url | user | password | status |
+---------------------------------------+-------+-------------+--------+
| http://192.168.2.131:13000/d/oceanbase | admin | 'oceanbase' | active |
+---------------------------------------+-------+-------------+--------+
obshell program health check ok
display ob-dashboard ok
+-------------------------------------------------------------------+
| ob-dashboard |
+--------------------------+------+------------------------+--------+
| url | user | password | status |
+--------------------------+------+------------------------+--------+
| http://192.168.2.131:2886 | root | 'Gtn9nynB6vUILgfrDDRS' | active |
+--------------------------+------+------------------------+--------+
ob_single_cli running
Trace ID: 81f7a298-b4d1-11f0-9345-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 81f7a298-b4d1-11f0-9345-0050568197df
启动过程关注点:
- 命令输出中是否有"start observer success"、"start prometheus success"等成功提示;
- 若出现错误(如端口冲突、配置无效),根据提示修复(例如kill占用端口的进程)。
6.6.2:验证集群状态
启动后,通过display命令确认各组件状态:
obd cluster display ob_single_cli
[root@worker3 ~]# obd cluster display ob_single_cli
Get local repositories and plugins ok
Open ssh connection ok
Connect to observer 192.168.2.131:2881 ok
Wait for observer init ok
+------------------------------------------------+
| oceanbase-ce |
+--------------+---------+------+-------+--------+
| ip | version | port | zone | status |
+--------------+---------+------+-------+--------+
| 192.168.2.131 | 4.3.5.4 | 2881 | zone1 | ACTIVE |
+--------------+---------+------+-------+--------+
obclient -h192.168.2.131 -P2881 -uroot@sys -p'Gtn9nynB6vUILgfrDDRS' -Doceanbase -A
cluster unique id: 69b71630-3cec-5aa0-a90f-da065deae710-19989f84cc5-04050304
Connect to Obagent ok
+-----------------------------------------------------------------+
| obagent |
+--------------+--------------------+--------------------+--------+
| ip | mgragent_http_port | monagent_http_port | status |
+--------------+--------------------+--------------------+--------+
| 192.168.2.131 | 8089 | 8088 | active |
+--------------+--------------------+--------------------+--------+
Connect to Prometheus ok
+-----------------------------------------------------------+
| prometheus |
+---------------------------+-------+--------------+--------+
| url | user | password | status |
+---------------------------+-------+--------------+--------+
| http://192.168.2.131:19090 | admin | '8jFSaDZ65Z' | active |
+---------------------------+-------+--------------+--------+
Connect to grafana ok
+----------------------------------------------------------------------+
| grafana |
+---------------------------------------+-------+-------------+--------+
| url | user | password | status |
+---------------------------------------+-------+-------------+--------+
| http://192.168.2.131:13000/d/oceanbase | admin | 'oceanbase' | active |
+---------------------------------------+-------+-------------+--------+
obshell program health check ok
display ob-dashboard ok
+-------------------------------------------------------------------+
| ob-dashboard |
+--------------------------+------+------------------------+--------+
| url | user | password | status |
+--------------------------+------+------------------------+--------+
| http://192.168.2.131:2886 | root | 'Gtn9nynB6vUILgfrDDRS' | active |
+--------------------------+------+------------------------+--------+
Trace ID: c2de769c-b4d1-11f0-97a1-0050568197df
If you want to view detailed obd logs, please run: obd display-trace c2de769c-b4d1-11f0-97a1-0050568197df
预期输出:
- 集群整体状态为
running; - 各组件(observer、prometheus、grafana)的"Status"列显示
active,且PID与实际进程一致。
6.6.3:验证监控面板访问
通过OBD输出的URL访问监控面板,确认数据正常:
- Grafana:
http://192.168.2.131:13000/d/oceanbase(用户admin,密码oceanbase)
- ob-dashboard(Web管理界面):
http://192.168.2.131:2886(用户root,密码同root@sys)
6.6.4:验证新版本目录规范(默认使用clusters复数目录)
obd cluster list # 应仍能识别ob_single_cli集群
[root@worker3 lib]# obd cluster list
+--------------------------------------------------------------------+
| Cluster List |
+---------------+----------------------------------+-----------------+
| Name | Configuration Path | Status (Cached) |
+---------------+----------------------------------+-----------------+
| ob_single_cli | /root/.obd/cluster/ob_single_cli | running |
+---------------+----------------------------------+-----------------+
Trace ID: 38149230-bca6-11f0-82ca-0050568197df
If you want to view detailed obd logs, please run: obd display-trace 38149230-bca6-11f0-82ca-0050568197df
[root@worker3 lib]#
6.6.5:验证数据库可用性
连接OceanBase数据库,确认核心功能正常:
# 使用默认租户root登录(密码为空,首次登录无需输入密码)
mysql -h192.168.2.131 -P2881 -uroot -p
[root@worker3 ~]# mysql -h192.168.2.131 -P2881 -uroot -p
Enter password:
ERROR 1045 (42000): Access denied for user 'root'@'xxx.xxx.xxx.xxx' (using password: NO)
[root@worker3 lib]# mysql -h127.0.0.1 -P2881 -uroot@sys -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3221726139
Server version: 5.7.25 OceanBase_CE 4.3.5.4 (r104000042025090916-5cf5b925a25bf888aebaa288e251b85b1924e98a) (Built Sep 9 2025 17:07:42)
Copyright (c) 2000, 2025, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
# 登录后执行以下SQL验证
show databases; # 应返回系统数据库列表
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| demo_db |
| information_schema |
| LBACSYS |
| mysql |
| oceanbase |
| ocs |
| ORAAUDITOR |
| SYS |
| sys_external_tbs |
| test |
+--------------------+
10 rows in set (0.01 sec)
mysql>
总结
这次故障排查让我们对 OceanBase 管理有了更深入的理解,也总结出了一些宝贵的运维经验:
根本原因分析:
这次"假死"故障的根本原因在于 OBD 集群配置目录结构异常和元数据文件缺失:
预防措施建议:
为了避免类似问题再次发生,建议:
- 部署规范化:使用标准化部署脚本,确保目录结构和文件权限的一致性
- 定期健康检查:建立自动化的集群健康检查机制,及时发现状态不一致问题
- 监控告警完善:配置完善的监控告警,对组件异常和状态不一致及时告警
- 文档和流程标准化:完善运维文档,规范操作流程,减少人为错误
- 版本兼容性管理:注意 OBD 版本升级可能带来的配置格式变化,做好兼容性管理
运维心得:在分布式数据库的运维中,真正的专业不仅体现在解决问题的能力上,更体现在预防问题的预见性上。每一次故障都是提升系统稳定性的机会,深入理解工具的工作原理,才能做到防患于未然。
作者注:
——本文所有操作及测试均基于 OceanBase_CE 4.3.5 版本完成。请注意,OceanBase_CE 版本处于持续迭代中,部分语法或功能可能随更新发生变化,请以 OceanBase 官方文档 最新内容为准。
——以上仅为个人思考与建议,不代表行业普适观点。以上所有操作均需在具备足够权限的环境下执行,涉及生产环境时请提前做好备份与测试。文中案例与思路仅供参考,若与实际情况巧合,纯属无意。期待与各位从业者共同探讨更多可能!
