




大家好,我是JiekeXu,江湖人称“强哥”,青学会MOP技术社区主席,荣获Oracle ACE Pro称号,金仓最具价值倡导者KVA,崖山最具价值专家YVP,IvorySQL开源社区专家顾问委员会成员,墨天轮MVP,墨天轮年度“墨力之星”,拥有 Oracle OCP/OCM 认证,MySQL 5.7/8.0 OCP 认证以及金仓KCA、KCP、KCM、KCSM证书,PCA、PCTA、OBCA、OGCA等众多国产数据库认证证书,欢迎关注我的微信公众号“JiekeXu DBA之路”,然后点击右上方三个点“设为星标”置顶,更多干货文章才能第一时间推送,谢谢!
前 言
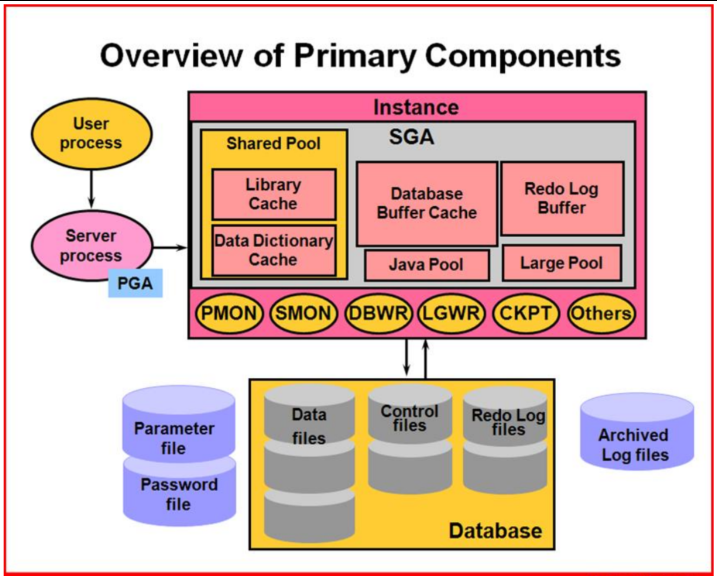
了解 Oracle 体系架构是学习 Oracle 数据库的基础,很多面试官也会问关于体系结构的相关知识点,下面是 Oracle 非常经典的架构图,十年前我开始学的时候就是下面这张图,概括了数据库的全貌,学会搞懂他也算是入门了,今天我们来看看预计下周二左右要发布的 Oracle AI Database 26ai 本地部署版本体系结构长啥样。
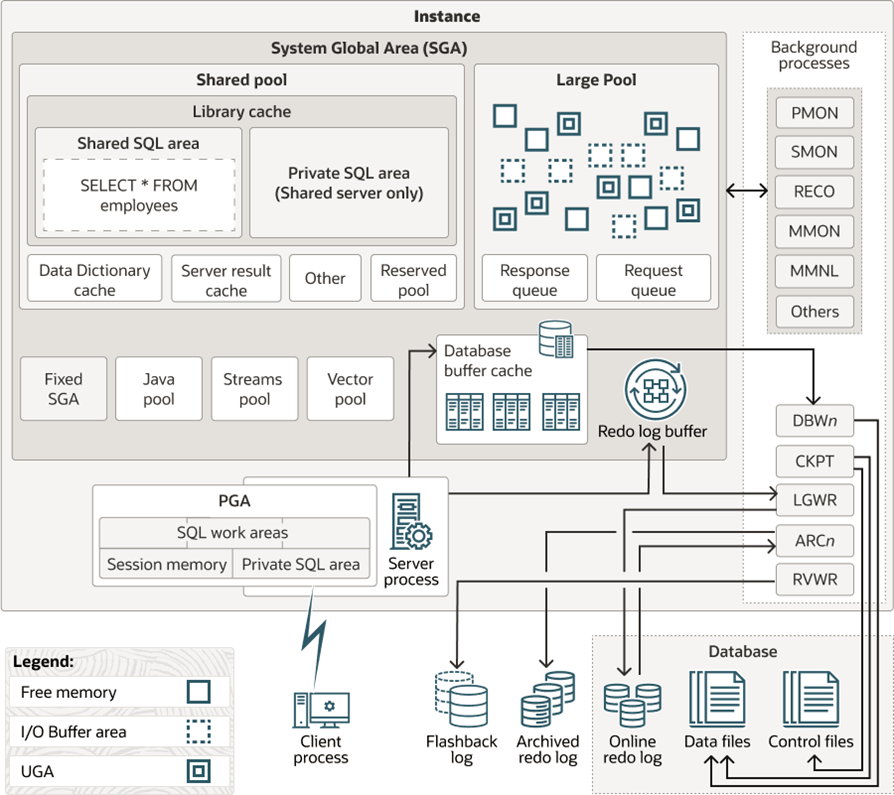
下面是官方网站 Oracle AI Database 26ai 最新的体系结构图,和之前看到的版本最大的不一样,就是多了【Vector pool】向量池,这是值得多研究研究的,其他的部分和之前看到的基本一样。
Database Server 数据库服务
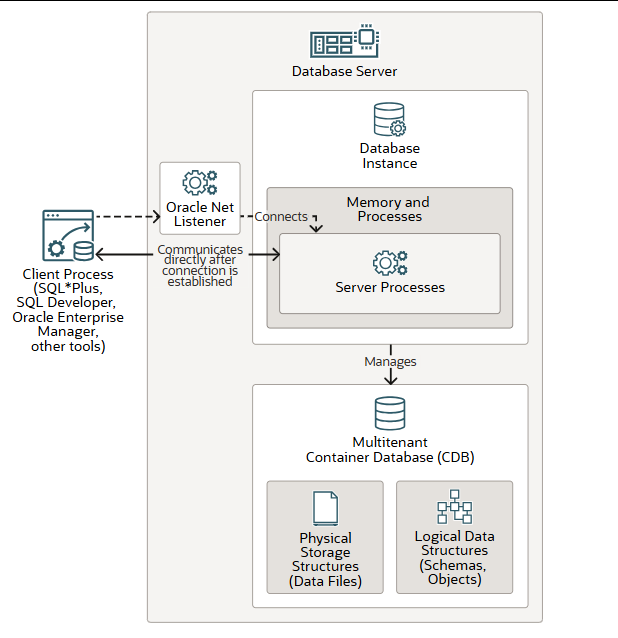
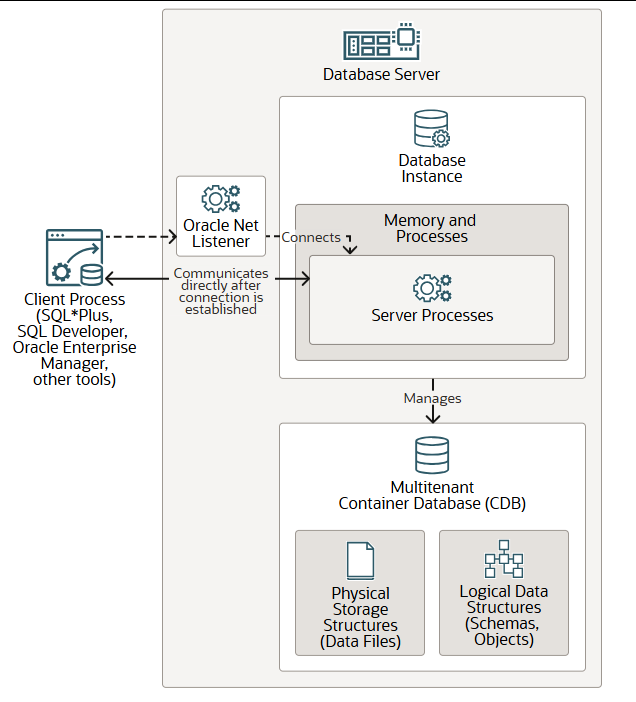
Oracle AI 数据库至少包含一个数据库实例和一个数据库。数据库实例由内存和进程组成,用于管理多租户容器数据库(CDB)。CDB 由物理存储结构(数据文件)和逻辑数据结构(模式和模式对象)组成。
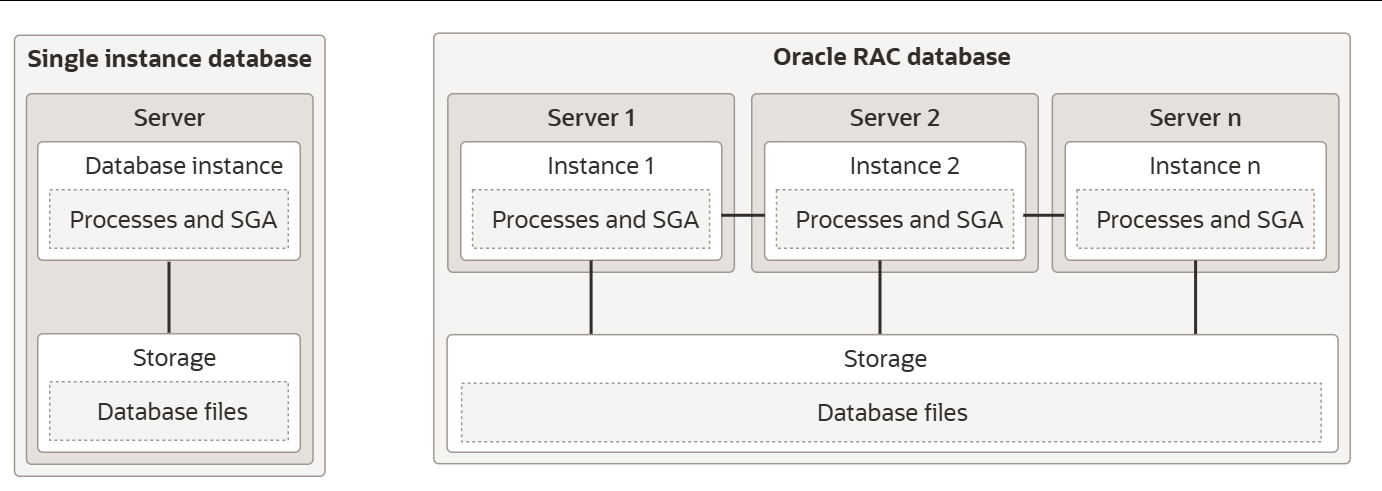
此图展示了单实例数据库架构,其中数据库与数据库实例之间是一对一的关系。同一台服务器机器上可以存在多个单实例数据库。这种配置适用于在同一台机器上运行不同版本的 Oracle AI 数据库。
Oracle Real Application Clusters(Oracle RAC)数据库架构由运行在不同服务器机器上的多个实例和一个共享数据库组成。有关 Oracle RAC 架构的更多信息,请参阅《Oracle Real Application Clusters 19c 技术架构》。
Oracle Net 监听器是数据库服务器进程,它接收来自客户端进程的传入连接,建立与数据库实例的连接,然后将客户端连接移交以直接与服务器进程通信,从而满足客户端请求。单实例数据库的监听器可以在数据库服务器本地运行,也可以在远程运行。
您可以使用多种工具来管理数据库,包括以下工具:
- Oracle Data Pump
- Oracle Enterprise Manager
- Oracle AI Database AutoUpgrade
- Database Configuration Assistant (DBCA)
- Oracle Recovery Manager (RMAN)
- Oracle Server Control Utility (SRVCTL)
- SQL Developer
- SQL*Loader
- SQL*Plus
Database Instance 数据库实例
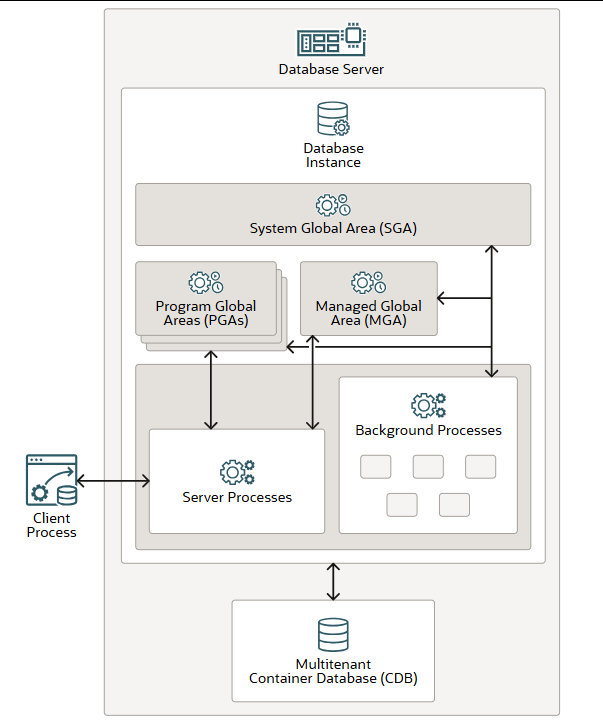
在Oracle AI数据库中,数据库实例是一组进程和内存结构的集合,用于管理数据库文件。主要的内存结构包括系统全局区(SGA)和程序全局区(PGAs)。managed global area 托管全局区(MGA)是一个内存框架,能够在一组受信任的Oracle进程中共享和协调内存。background processes 后台进程对数据库文件进行操作,并使用内存结构来完成其工作。数据库实例仅存在于内存中。
数据库实例还具有服务器进程,用于代表客户端程序处理与数据库的连接,并为客户程序执行工作。例如,这些服务器进程解析并运行SQL语句,检索结果并返回给客户端进程。这类服务器进程也称为前台进程。
借助多租户架构,一个数据库实例与一个单一的多租户容器数据库(CDB)相关联。所有插入到CDB中的可插拔数据库(PDBs)(无论是直接插入还是通过应用程序容器插入)共享一组后台进程和SGA。
SGA 系统全局区
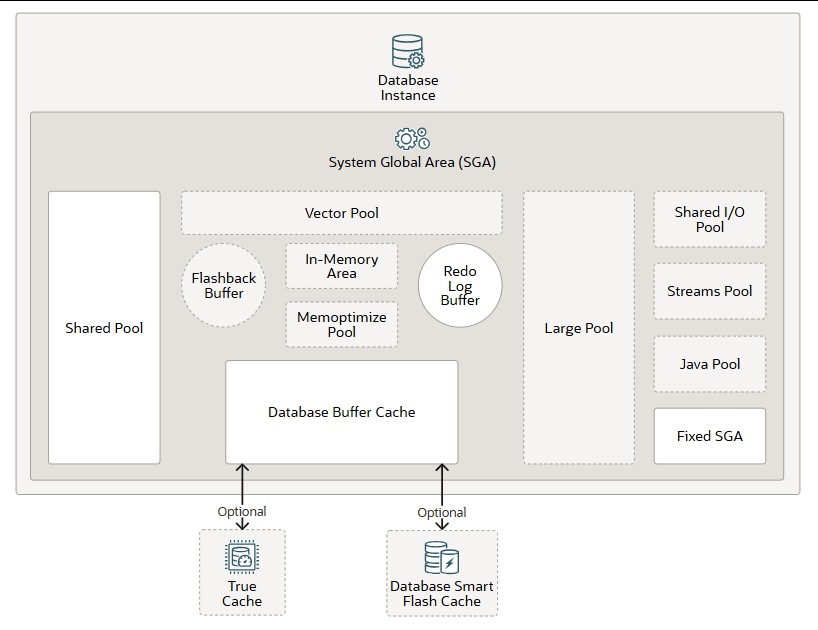
系统全局区 (SGA)是包含单个 Oracle AI 数据库实例的数据和控制信息的内存区域。所有服务器进程和后台进程共享 SGA。启动数据库实例时,会显示分配给 SGA 的内存量。SGA 包含以下数据结构:
- 共享池缓存各种可供多个用户共享的结构;例如,共享池存储已解析的 SQL、PL/SQL 代码、系统参数和数据字典信息。数据库中发生的几乎所有操作都与共享池有关。例如,如果用户运行 SQL 语句,则 Oracle AI 数据库会访问共享池。
- (可选)要允许创建和维护向量索引,您必须启用存储在 SGA 中的名为“向量池”的内存区域。向量池是 SGA 中分配的内存,用于存储分层可导航小世界 (HNSW) 向量索引及其所有关联的元数据。它还用于加速倒排文件平面 (IVF) 索引的创建,以及对具有 IVF 索引的基表执行数据操作语言 (DML) 操作。
- (可选)闪回缓冲区与闪回数据库配合使用,以便您可以将数据回溯到过去某个时间点来纠正任何问题。启用闪回数据库后,恢复写入器进程 (RVWR) 将启动。RVWR 会定期将修改过的数据块从缓冲区缓存复制到闪回缓冲区,并将闪回数据库数据从闪回缓冲区按顺序写入闪回数据库日志,这些日志会循环重用。
数据库缓冲区缓存是存储从数据文件中读取的数据块副本的内存区域。缓冲区是主内存中的一个地址,缓冲区管理器会将当前或最近使用的数据块临时缓存到该地址中。所有同时连接到数据库实例的用户共享对缓冲区缓存的访问权限。 - (可选) True Cache是 Oracle AI 数据库的内存缓存,它具有一致性和自动管理功能,支持 SQL 和键值(对象或 JSON)缓存。 您可以将常用表持久化到 True Cache 的数据库缓冲区缓存或主数据库(或两者都保留)。
(可选)数据库智能闪存缓存 是运行在 Solaris 或 Oracle Linux 上的数据库的数据库缓冲区缓存的内存扩展。它为数据库块提供二级缓存。对于读取密集型在线事务处理 (OLTP) 工作负载以及数据仓库 (DW) 环境中的即席查询和批量数据修改,它都能提高响应时间和整体吞吐量。数据库智能闪存缓存位于一个或多个闪存盘设备上,这些设备是使用闪存的固态存储设备。数据库智能闪存缓存通常比额外的内存更经济,并且比磁盘驱动器快一个数量级。
重做日志缓冲区是 SGA 中的一个循环缓冲区,用于保存数据库更改信息。这些信息存储在重做条目中。重做条目包含通过 DML、数据定义语言 (DDL) 或内部操作重建(或重做)数据库更改所需的信息。必要时,重做条目可用于数据库恢复。 - (可选)大型内存池用于分配比共享内存池更大的内存。大型内存池可以为共享服务器的用户全局区 (UGA) 和 Oracle XA 接口(用于事务与多个数据库交互的情况)、用于并行处理语句的消息缓冲区、用于恢复管理器 (RMAN) I/O 工作进程的缓冲区以及延迟插入提供大容量内存。
- (可选)内存区域允许将对象(表、分区和其他类型)以列式格式存储在内存中。这种格式使得扫描、连接和聚合操作的执行速度远超传统的磁盘格式,从而为联机事务处理 (OLTP) 和数据仓库 (DW) 环境提供快速的报表和数据操作语言 (DML) 性能。此功能对于处理少量列但返回大量行的分析应用程序尤为有用,而对于处理少量行但返回多列的 OLTP 则不然。
- (可选)memoptimize 池为基于键的查询提供高性能和可扩展性。memoptimize 池包含两部分:memoptimize 缓冲区和哈希索引。快速查找利用 memoptimize 池中的哈希索引结构,快速访问给定表(已启用MEMOPTIMIZE FOR READ)中永久固定在缓冲区缓存中的数据块,从而避免磁盘 I/O。memoptimize 池中的缓冲区与数据库缓冲区缓存完全分离。哈希索引在配置 Memoptimized Rowstore 时创建,Oracle AI 数据库会自动维护它。
(可选)共享 I/O 池 (SecureFiles)用于对 SecureFile 大型对象 (LOB) 执行大型 I/O 操作。LOB 是一组用于存储大量数据的数据类型。SecureFile 是一种 LOB 存储参数,支持数据去重、加密和压缩。 - (可选)流池与Oracle Data Pump 和 Oracle GoldenGate 进程配合使用。流池存储缓冲队列消息。除非您进行专门配置,否则流池的大小初始值为零。
- (可选)Java 池用于存储 Java 虚拟机 (JVM) 中所有会话特定的 Java 代码和数据。Java 池内存的使用方式取决于 Oracle AI 数据库的运行模式。
固定SGA是一个内部管理区域,其中包含有关数据库和数据库实例状态的一般信息以及进程之间通信的信息。
PGA 程序全局区
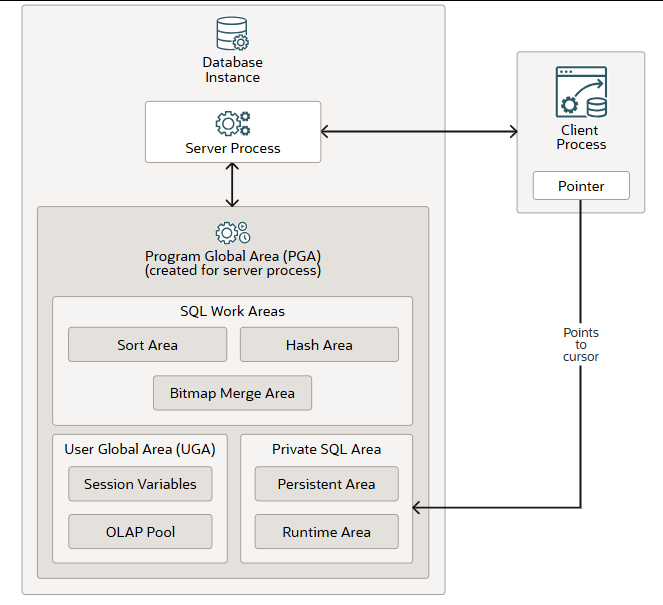
程序全局区 (PGA)是数据库实例内的一个非共享内存区域,其中包含仅供服务器或后台进程使用的数据和控制信息。Oracle AI 数据库会创建服务器进程,代表客户端程序处理与数据库的连接。(下图显示了一个服务器进程的 PGA。)
在专用服务器环境中,Oracle AI 数据库会为每个启动的服务器和后台进程创建一个 PGA。当关联的服务器或后台进程终止时,Oracle AI 数据库会释放该 PGA。在专用服务器会话中,PGA 由以下组件构成:
SQL 工作区 包括用于对数据进行排序的函数(如 ORDER BY 和 GROUP BY)的排序区、用于执行表哈希连接的哈希区,以及用于合并从多个位图索引扫描中检索到的数据的位图合并区。
用户全局区 (UGA)是用户会话数据存储区,用于存储会话变量,例如登录信息和数据库会话所需的其他信息,以及管理 OLAP 数据页(相当于数据块)的 OLAP 池。
私有SQL 区域保存已解析 SQL 语句的信息以及其他会话特定的处理信息。当服务器进程运行 SQL 或 PL/SQL 代码时,该进程使用私有 SQL 区域来存储绑定变量值、查询执行状态信息和查询执行工作区。同一会话或不同会话中的多个私有 SQL 区域可以指向 SGA 中的同一个执行计划。持久化区域包含绑定变量值。运行时区域包含查询执行状态信息。游标是指向私有 SQL 区域中特定区域的名称或句柄。您可以将游标视为客户端的指针和服务器端的状态。由于游标与私有 SQL 区域密切相关,因此这两个术语有时可以互换使用。
在共享服务器环境中,多个客户端用户共享服务器进程。用户组 (UGA) 会移至大型进程池,而私有组 (PGA) 则仅保留 SQL 工作区和私有 SQL 区域。
Background porceesses 后台进程
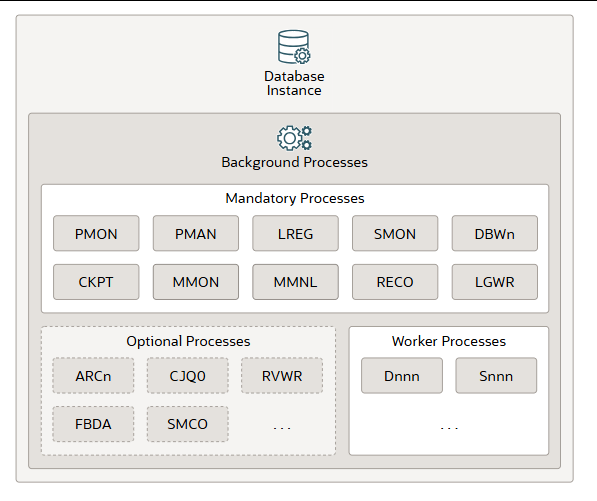
后台进程是数据库实例的一部分,负责执行维护任务,以确保数据库正常运行并最大限度地提高多用户性能。每个后台进程执行的任务各不相同,但彼此协同工作。Oracle AI 数据库会在您启动数据库实例时自动创建后台进程。具体存在的后台进程取决于您正在使用的数据库功能。启动数据库实例时,必需的后台进程会自动启动。您可以根据需要稍后启动可选的后台进程。
所有典型的数据库配置中都存在必需的后台进程。这些进程默认在以最小配置初始化参数文件启动的读写数据库实例中运行。只读数据库实例会禁用其中一些进程。必需的后台进程包括进程监视器 (PMON)、进程管理器 (PMAN)、监听器注册 (LREG)、系统监视器 (SMON)、数据库写入器 (DBWn)、检查点 (CKPT)、可管理性监视器 (MMON)、精简版可管理性监视器 (MMNL)、恢复器 (RECO) 和日志写入器 (LGWR)。
大多数可选后台进程都与特定任务或功能相关。一些常见的可选进程包括归档程序 (ARCn)、作业队列协调程序 (CJQ0)、恢复写入程序 (RVWR)、闪回数据归档程序 (FBDA) 和空间管理协调程序 (SMCO)。
工作进程是后台进程,它们代表其他进程执行工作。其中包括调度程序(Dnnn)和共享服务器(Snnn)进程。
Shared Pool 共享池
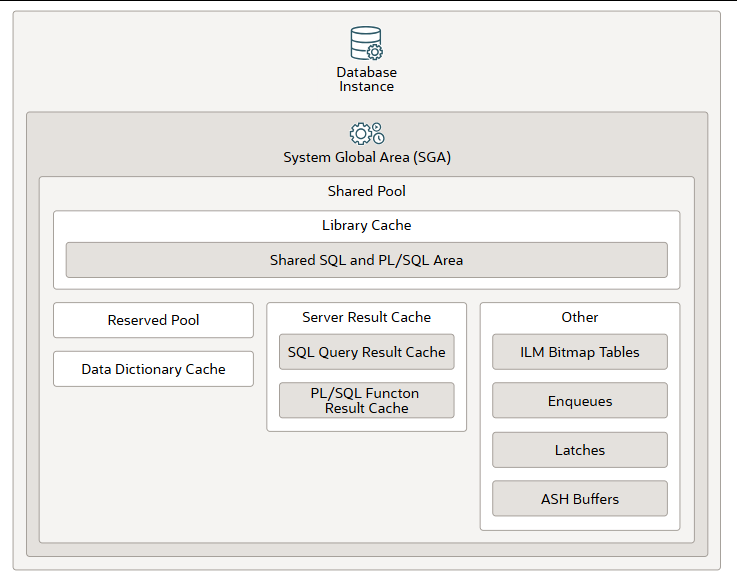
共享池是数据库实例中系统全局区 (SGA) 的一个组成部分。它负责缓存各种类型的程序数据。例如,共享池存储已解析的 SQL、PL/SQL 代码、系统参数和数据字典信息。数据库中发生的几乎所有操作都与共享池有关。例如,如果用户运行 SQL 语句,则 Oracle AI 数据库会访问共享池。
共享池由以下子组件构成:
库缓存是一个共享的内存池结构,用于存储可执行的 SQL 和 PL/SQL 代码。该缓存包含共享的 SQL 和 PL/SQL 区域以及控制结构,例如锁和库缓存句柄。当执行 SQL 语句时,数据库会尝试重用之前执行过的代码。如果库缓存中存在 SQL 语句的已解析表示形式且可以共享,则数据库会重用该代码。此操作称为软解析或库缓存命中。否则,数据库必须构建应用程序代码的新可执行版本,这称为硬解析或库缓存未命中。
预留池是共享池中的一个内存区域,Oracle AI 数据库可以使用该区域分配大块连续内存。数据库以块的形式从共享池中分配内存。分块分配允许将大对象(超过 5 KB)加载到缓存中,而无需使用单个连续区域。这样,数据库就降低了因内存碎片而导致连续内存耗尽的可能性。
数据字典缓存存储数据库对象的信息(即字典数据)。该缓存也称为行缓存,因为它以行而不是缓冲区的形式存储数据。
服务器结果缓存是共享内存池中的一个内存池,其中包含 SQL 查询结果缓存和 PL/SQL 函数结果缓存,它们共享同一基础架构。SQL 查询结果缓存存储查询结果和查询片段。大多数应用程序都能从这种性能提升中受益。PL/SQL 函数结果缓存存储函数结果集。频繁调用且依赖于相对静态数据的函数非常适合进行结果缓存。
其他组件包括入队 、锁存器 、信息生命周期管理 (ILM) 位图表 、活动会话历史 (ASH) 缓冲区 和其他一些次要内存结构。入队是共享内存结构(锁),用于串行化对数据库资源的访问。它们可以与进程或会话关联。例如,控制文件事务、实例恢复、介质恢复、作业队列和行缓存。锁存器用作底层串行化控制机制,以保护 SGA 中的共享数据结构免受并发访问。例如,缓存缓冲区链和重做日志分配。
Large Pool 大池
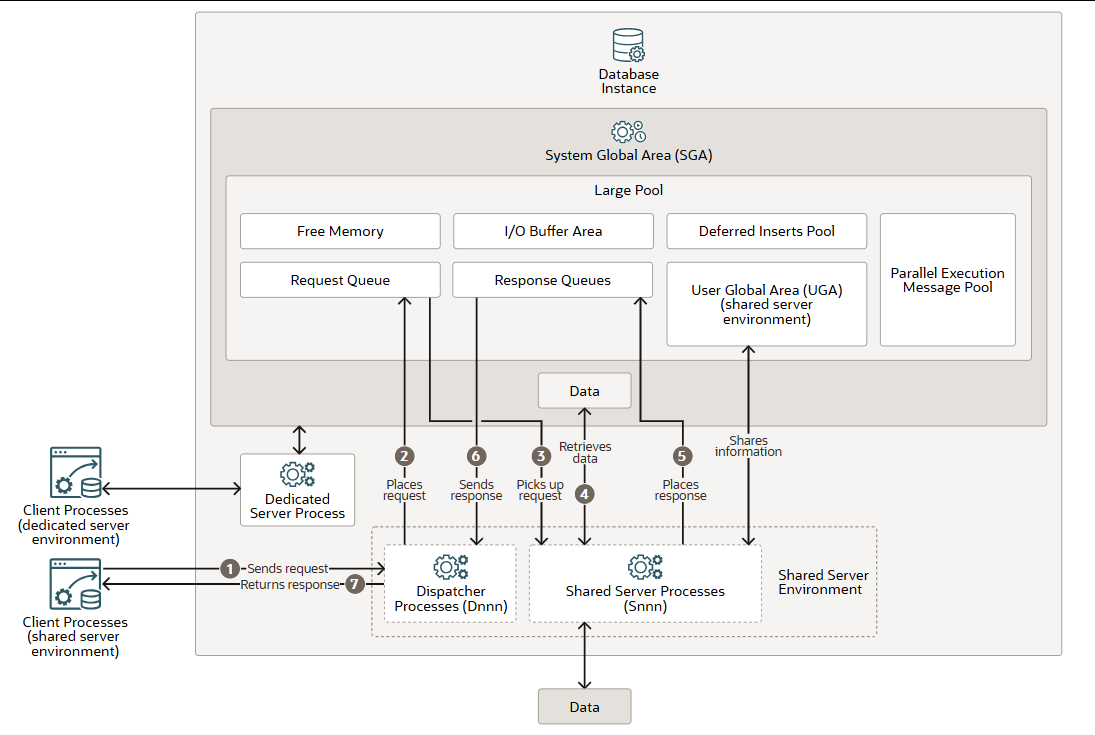
大内存池是数据库实例和系统全局区 (SGA) 中的一个可选内存区域。您可以配置大内存池,为以下区域提供大容量内存分配:
- 共享服务器环境和 Oracle XA 接口(用于事务与多个数据库交互)使用用户全局区 (UGA)(会话内存)。在专用服务器环境中,UGA 存储在程序全局区 (PGA)中。
- I/O 缓冲区区域包括I/O 服务器进程、并行查询操作的消息缓冲区、恢复管理器 (RMAN) I/O 工作进程的缓冲区以及高级队列内存表存储。
- 快速摄取功能使用延迟插入池,该功能允许对定义为
memoptimized的表进行高频单行数据插入MEMOPTIMIZE FOR WRITE。快速摄取插入的数据也称为延迟插入。这些数据最初会缓冲在大池中,然后在每个会话每个对象写入 1MB 后(或 60 秒后),由空间管理协调器进程 (SMCO) 和 Wxxx 工作后台进程异步写入磁盘。即使会话已提交,在 SMCO 后台进程清除缓存之前,会话也无法读取此池中缓冲的任何数据。该池在内存优化表插入第一行数据时初始化于大池中。当大池空间充足时,会分配 2GB 内存。如果大池空间不足,系统ORA-4031内部会发现并自动清除内存池。然后,系统会尝试使用请求大小的一半重新分配内存。如果大池空间仍然不足,系统会尝试使用 512M 和 256M 的内存重新分配,之后该功能将被禁用,直到实例重启。池初始化后,其大小将保持不变,无法增加或减少。 - 并行执行消息池(px msg pool)由并行查询执行进程用于相互发送消息。
- 可用内存
大内存池与共享内存池中的预留空间不同,后者与其他从共享内存池分配的内存一样,使用相同的最近最少使用 (LRU) 列表。大内存池没有 LRU 列表。内存一旦分配,只有在使用完毕后才能释放。
用户请求是指用户 SQL 语句中的一次 API 调用。
在专用服务器环境中,一个专用服务器进程处理来自单个客户端进程的请求。每个服务器进程都会占用系统资源,包括 CPU 周期和内存。
在共享服务器环境中,会发生以下操作:
- 客户端进程向数据库实例发送请求,**调度程序进程(Dnnn)**接收该请求。
- 调度程序将请求放入 Large Pool 大池的请求队列中。
- 下一个可用的**共享服务器进程(Snnn)**会处理该请求。共享服务器进程会检查公共请求队列中的新请求,并按照先进先出的原则处理新请求。一个共享服务器进程只能处理队列中的一个请求。
- 共享服务器进程会向数据库发出所有必要的调用以完成请求。首先,共享服务器进程访问共享池中的库缓存来验证请求的数据项。例如,它会检查表是否存在、用户是否拥有正确的权限等等。接下来,共享服务器进程访问缓冲区缓存来检索数据。如果数据不存在,则共享服务器进程会访问磁盘。每个数据库调用都可以由不同的共享服务器进程处理。因此,解析查询、获取第一行、获取下一行以及关闭结果集的请求可能分别由不同的共享服务器进程处理。由于每个数据库调用都可能由不同的共享服务器进程处理,因此用户全局区 ( UGA)必须是共享内存区域,因为 UGA 包含有关每个客户端会话的信息。反过来说,UGA 包含有关每个客户端会话的信息,并且必须对所有共享服务器进程可用,因为任何共享服务器进程都可能处理任何会话的数据库调用。
- 请求完成后,共享服务器进程会将响应放入调用调度程序的响应队列(位于大队列中)。每个调度程序都有自己的响应队列。
- 响应队列将响应发送给调度器。
- 调度程序将完成的请求返回给相应的客户端进程。
Vector Pool 向量池
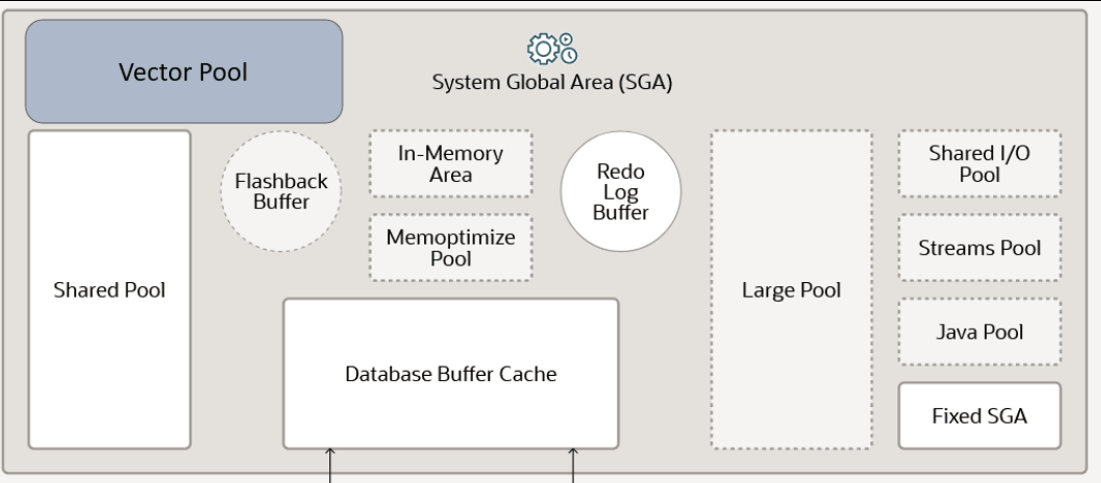
为了允许创建向量索引,您必须启用存储在SGA中的新内存区域——向量池。向量池是SGA中分配的内存,用于存储分层可导航小世界(HNSW)向量索引及其所有相关元数据。它还用于加快反向文件平面(IVF)索引的创建,以及对带有 IVF 索引的基本表执行 DML 操作。IVF 向量存储在向量池中,以提高 IVF 索引的创建和维护性能。如果向量池空间不足,质心向量将被缓存到大池中。如果大池空间也不足,则质心向量不会被缓存到内存中。此规则适用于未分区和已分区的本地及全局IVF索引。
要在本地环境中调整 Vector Pool 的大小,请使用以下方法:VECTOR_MEMORY_SIZE 初始化参数。您可以在以下几个层级动态修改此参数:
- 在中央开发银行层面VECTOR_MEMORY_SIZE指定向量池的当前大小。如果当前已有向量在使用,则减小参数值将失败。
- 在PDB层面VECTOR_MEMORY_SIZE 指定 PDB 允许的最大向量池使用量。即使当前向量使用量超过新的配额,也允许降低此参数值。
您可以通过以下方式更改参数文件中参数的值:
- 通过编辑初始化参数文件。在大多数情况下,新值会在下次启动数据库实例时生效。
- 通过发布ALTER SYSTEM SET … SCOPE=SPFILE声明来更新服务器参数文件。
- 通过发出一条ALTER SYSTEM RESET语句来清除初始化参数值并将其设置回默认值。
SQL> show con_name
CON_NAME
------------------------------
MYPDB1
SQL> show user
USER is "SYS"
SQL> show parameter vector_memory_size
NAME TYPE VALUE
------------------ ----------- -----
vector_memory_size big integer 500M
SQL> SELECT ISPDB_MODIFIABLE
2 FROM V$SYSTEM_PARAMETER
3* WHERE NAME='vector_memory_size';
ISPDB_MODIFIABLE
___________________
TRUE
SQL> ALTER SYSTEM SET vector_memory_size=1G SCOPE=BOTH;
System altered.
SQL> show parameter vector_memory_size
NAME TYPE VALUE
------------------- ----------- -------
vector_memory_size big integer 1G
SQL>
如果VECTOR_MEMORY_SIZE设置为1,且在CDB初始化时sga_target大于0,则HNSW索引创建会自动增大向量内存池以满足新索引的需求。PDB的VECTOR_MEMORY_SIZE最大值限制为PDB sga_target的70%。删除HNSW索引时,向量内存池会相应缩小。
在此配置下,向量内存池自动增长的情况下,PDB的VECTOR_MEMORY_SIZE值将默认为0,并且不能使用ALTER SYSTEM命令进行修改。由于自动增长导致的向量池大小变化不会保存到spfile中,因此当数据库重启时,向量池大小会被重置。
您可以查询V$VECTOR_MEMORY_POOL视图来监控向量池。
buffer canche 缓冲区缓存
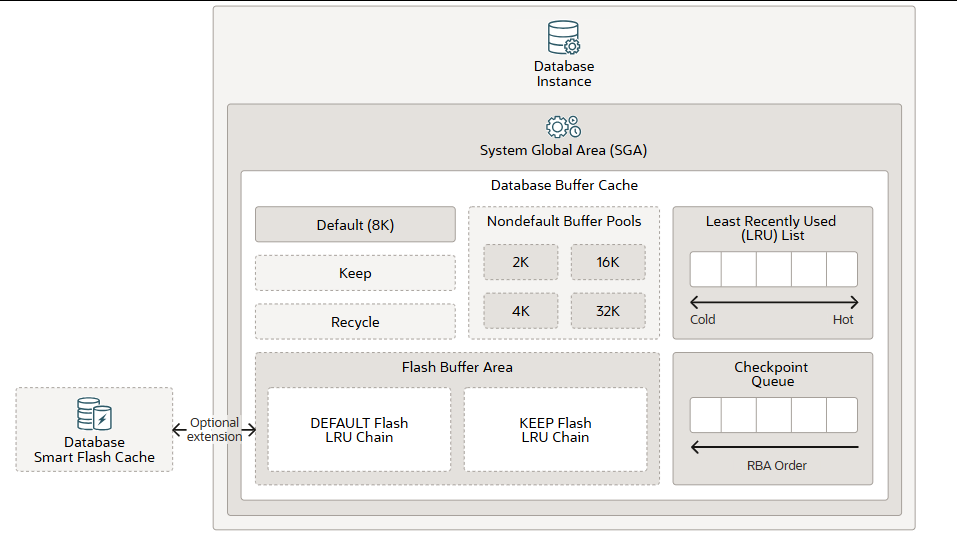
数据库缓冲区缓存(也称为缓冲区缓存)是数据库实例系统全局区 (SGA) 中的一个内存区域。它存储从数据文件中读取的数据块的副本。缓冲区是主内存中的一个地址,缓冲区管理器会将当前或最近使用的数据块临时缓存到该地址中。所有并发连接到数据库实例的用户共享对缓冲区缓存的访问权限。缓冲区缓存的目标是优化物理 I/O 并将频繁访问的数据块保留在缓冲区缓存中。
当 Oracle AI 数据库客户端进程首次需要特定数据时,它会在数据库缓冲区缓存中查找该数据。如果进程在缓存中找到该数据(缓存命中),则可以直接从内存中读取数据。如果进程在缓存中找不到该数据(缓存未命中),则会先将磁盘上数据文件中的数据块复制到缓存缓冲区中,然后再访问该数据。通过缓存命中访问数据比通过缓存未命中访问数据更快。
缓存中的缓冲区由一个复杂的算法管理,该算法结合了最近最少使用 (LRU) 列表和访问计数。LRU 有助于确保最近使用的数据块倾向于保留在内存中,从而最大限度地减少磁盘访问。
数据库缓冲区缓存由以下区域组成:
- 默认池是数据块通常缓存的位置。默认块大小为 8 KB。除非您手动配置其他池,否则默认池是唯一的缓冲池。其他池的可选配置不会影响默认池。
- (可选)保留池 用于存放预计会被频繁访问且因空间不足而从默认池中移除的数据块。保留池的目的是将指定的对象保留在内存中,以避免 I/O 操作。表会被分配到保留池中,它们不会自动从默认池移动到保留池。
- (可选)回收池用于存放不常用的数据块。回收池可以防止对象占用缓存中不必要的空间。
- (可选)非默认缓冲池适用于使用 2 KB、4 KB、16 KB 和 32 KB 非标准块大小的表空间。每种非默认块大小都有其自己的缓冲池。Oracle AI 数据库管理这些缓冲池中的块的方式与管理默认缓冲池中的块的方式相同。
- (可选)数据库智能闪存缓存(闪存缓存)允许您使用闪存设备来增加缓冲区缓存的有效容量,而无需增加主内存。闪存缓存通过将数据库缓存中频繁访问的数据存储在闪存中,而不是从磁盘读取数据,从而提高数据库性能。当数据库请求数据时,系统首先在数据库缓冲区缓存中查找数据。如果找不到数据,系统则在数据库智能闪存缓存缓冲区中查找。如果仍然找不到数据,系统才会查找磁盘存储。在 Oracle 实时应用集群 (RAC) 环境中,您必须在所有实例上配置闪存缓存,或者不配置任何实例。
- 最近最少使用 (LRU) 列表包含指向脏缓冲区和非脏缓冲区的指针。LRU 列表分为热端和冷端。冷缓冲区是指最近未使用的缓冲区。热缓冲区是指最近被频繁访问且已被使用的缓冲区。从概念上讲,LRU 列表只有一个,但为了保证数据并发性,数据库实际上会使用多个 LRU 列表。
- 检查点 队列是脏缓冲区的列表,按照重做块地址 (RBA) 顺序进行更改。
- (可选)如果启用数据库智能闪存缓存,闪存缓冲区将包含一个默认闪存 LRU 链和一个保留闪存 LRU 链。如果没有数据库智能闪存缓存,当进程尝试访问一个数据块且该数据块不存在于缓存中时,系统会首先从磁盘读取该数据块到内存(物理读取)。当内存缓存已满时,系统会根据 LRU 机制将缓冲区从内存中驱逐出去。启用数据库智能闪存缓存后,当一个干净的内存缓冲区老化时,数据库写入进程 (DBWn) 会在后台将内容写入闪存缓存,并且缓冲区头会作为元数据保留在内存中,具体位置取决于对象FLASH_CACHE属性的值,取决于默认闪存 LRU 列表或保留闪存 LRU 列表。保留闪存 LRU 列表会将缓冲区头维护在一个单独的列表中,以防止常规缓冲区头替换它们。这意味着,被指定为保留闪存 LRU 列表的对象,其闪存缓冲区头KEEP往往会在闪存缓存中保留更长时间。如果FLASH_CACHE对象属性设置为 true NONE,系统不会在闪存缓存或内存中保留相应的缓冲区。当再次访问已从内存中过期的缓冲区时,系统会检查闪存缓存。如果找到该缓冲区,系统会将其从闪存缓存中读出,这仅需从磁盘读取所需时间的一小部分。RAC 中闪存缓存缓冲区的一致性维护方式与 Oracle RAC 缓存融合相同。由于闪存缓存是扩展缓存,并且直接路径 I/O 完全绕过了缓冲区缓存,因此此功能不支持直接路径 I/O。请注意,系统不会将脏缓冲区放入闪存缓存,因为系统可能需要将缓冲区读入内存才能进行检查点操作,而写入闪存缓存的操作不计入检查点。
IM 内存区域
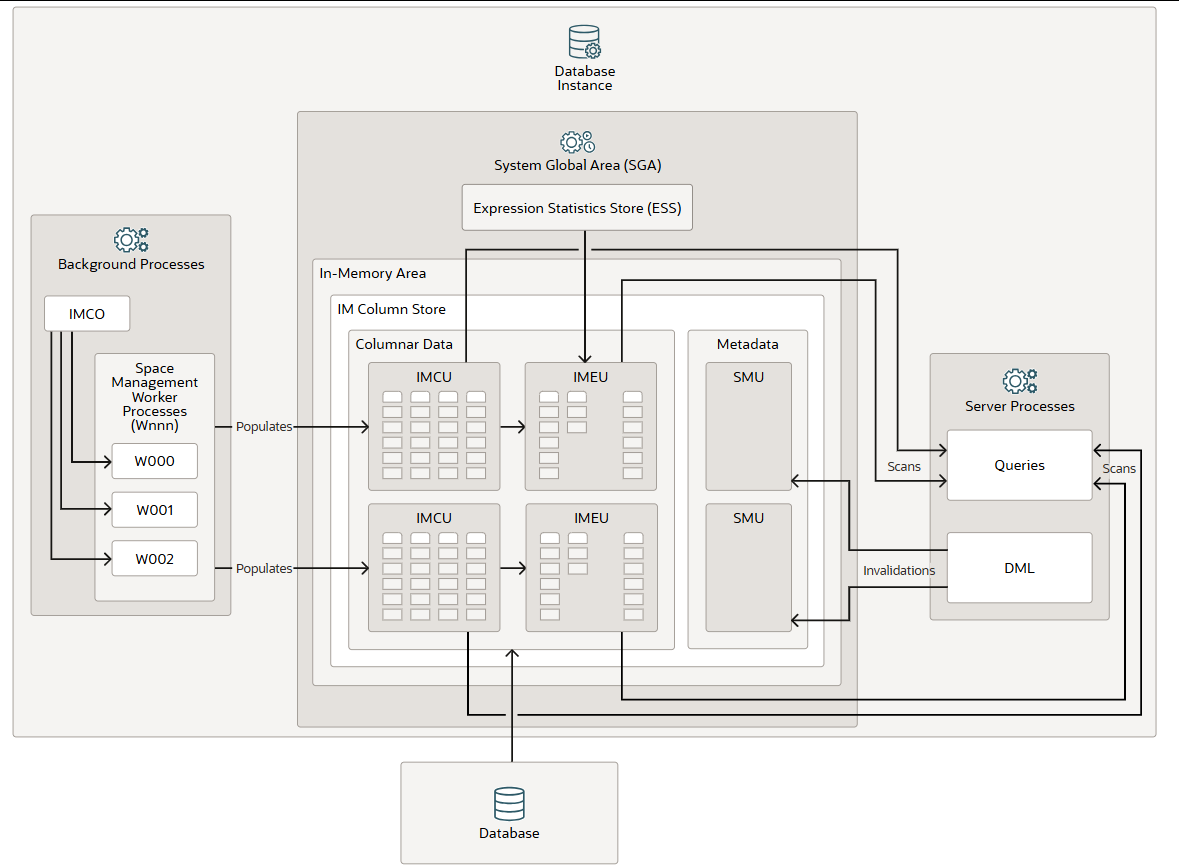
内存区域 (In-Memory Area)是数据库实例中的一个可选系统全局区 (SGA) 组件。它包含内存列式存储 (IM 列式存储),该存储使用针对快速扫描优化的列式格式将表和分区存储在内存中。IM 列式存储允许以传统的行格式(在缓冲区缓存中)和列式格式同时填充 SGA 中的数据。数据库会将联机事务处理 (OLTP) 查询(例如主键查找)透明地发送到缓冲区缓存,并将分析和报表查询发送到 IM 列式存储。在获取数据时,Oracle AI 数据库还可以在同一查询中从两个内存区域读取数据。这种双格式架构不会使内存需求翻倍。缓冲区缓存经过优化,其运行大小远小于数据库的大小。
您应该只在 IM 列存储中填充对性能影响最大的数据。要将对象添加到 IM 列存储,INMEMORY请在创建或修改对象时启用该对象的属性。您可以为表空间(适用于表空间中的所有新表和视图)、表、分区、子分区、物化视图或对象中的列子集指定此属性。
IM 列式存储使用优化的存储单元(而非传统的 Oracle 数据块)来管理数据和元数据。**内存压缩单元 (IMCU)**是一种压缩的只读存储单元,其中包含一个或多个列的数据。**快照元数据单元 (SMU)**包含与 IMCU 关联的元数据和事务信息。每个 IMCU 都映射到一个单独的 SMU。
**表达式统计信息存储库 (ESS)**是一个用于存储表达式求值统计信息的存储库。ESS 驻留在存储全局区 (SGA) 中,同时也持久化到磁盘上。启用内存表达式列存储后,数据库会利用 ESS 来实现其内存表达式 (IM expressions) 功能。**内存表达式单元 (IMEU)**是一个用于存储物化 IM 表达式和用户定义虚拟列的存储容器。请注意,ESS 与 IM 列存储相互独立。ESS 是数据库的永久组件,无法禁用。
从概念上讲,IMEU 是其父 IMCU 的逻辑扩展。正如 IMCU 可以包含多个列一样,IMEU 也可以包含多个虚拟列。每个 IMEU 都映射到唯一一个 IMCU,并且映射到同一组行。IMEU 包含与其关联的 IMCU 中所含数据的表达式结果。当 IMCU 被填充时,关联的 IMEU 也会被填充。
典型的IM表达式包含一个或多个列,可能还包含常量,并且与表中的行存在一一映射关系。例如,对于EMPLOYEES表的IMCU,可能包含每周工资(weekly_salary)列的第1至1000行。对于存储在该IMCU中的这些行,IMEU 会计算自动检测到的IM表达式“weekly_salary52”,以及用户定义的虚拟列“quarterly_salary”(定义为“weekly_salary12”)。IMCU中的第三行将映射到IMEU中的第三行。
内存区域分为两个池:
- 一个 1MB 的列式数据池,用于存储实际填充到内存(IMCU 和 IMEU)中的列格式数据。
- 一个 64K 的元数据池,用于存储有关填充到 IM 列存储(SMU)中的对象的元数据。
两个内存池的相对大小由内部启发式算法决定。In-Memory 区域的大部分内存分配给1MB内存池。In-Memory区域的大小由初始化参数 INMEMORY_SIZE(默认值为0)控制,且最小大小必须为100MB。从Oracle Database 12.2开始,可以通过 ALTER SYSTEM 命令将 INMEMORY_SIZE 参数至少增加 128MB,从而动态增加 In-Memory 区域的大小。请注意,无法动态减小 In-Memory 区域的大小。
Oracle AI 数据库内存版具有基本级别功能,允许您使用高达 16GB 的列式存储,而不会触发任何许可证跟踪。
首次访问内存表数据或数据库启动时,会在内存列存储中为内存表分配 IMCU。通过将磁盘格式转换为新的内存列存储格式,即可创建表的内存副本。每次实例重启时都会执行此转换,因为内存列存储副本仅驻留在内存中。转换完成后,表的内存版本会逐渐可用于查询。如果表已部分转换,查询可以使用部分内存版本,其余部分则从磁盘读取,而无需等待整个表转换完成。
当表中并非所有列都已填充到内存列存储中时,内存混合扫描可以同时访问内存列存储中的部分数据和行存储中的部分数据。与纯行存储查询相比,这可以将性能提升几个数量级。
自动内存功能无需用户干预即可启用、填充、逐出和重新压缩段。当 INMEMORY_AUTOMATIC_LEVEL 设置为 HIGH 时,数据库会根据段的使用模式自动启用并填充段。这种自动化有助于最大化一次可填充到IM列存储中的对象数量。
服务器进程响应查询和数据操作语言 (DML) 指令,扫描列式数据并更新空间管理单元 (SMU) 元数据。后台进程将磁盘上的行数据填充到内存 (IM) 列式存储中。内存协调器进程 (IMCO)启动列式数据的后台填充和重新填充。空间管理协调器进程 (SMCO)和空间管理工作进程 (Wnnn)代表 IMCO 执行实际的数据填充和重新填充操作。DML 块更改先写入缓冲区缓存,然后再写入磁盘。后台进程随后根据元数据失效和查询请求,将磁盘上的行数据重新填充到 IM 列式存储中。
您可以启用内存快速启动功能,将内存列存储中的列式数据以压缩列格式写回数据库的表空间。此功能可加快数据库启动速度。请注意,此功能不适用于内存执行单元 (IMEU)。IMEU 始终由内存管理单元 (IMCU) 动态填充。
内存深度向量化可以通过对每个 SQL 运算符内部的物理运算符进行流水线化,并使用单指令多数据流 ( SIMD)技术对其进行向量化,从而优化复杂的 SQL 运算符。此功能默认启用,但您可以通过将INMEMORY_DEEP_VECTORIZATION初始化参数设置为 false 来禁用它。
CDB
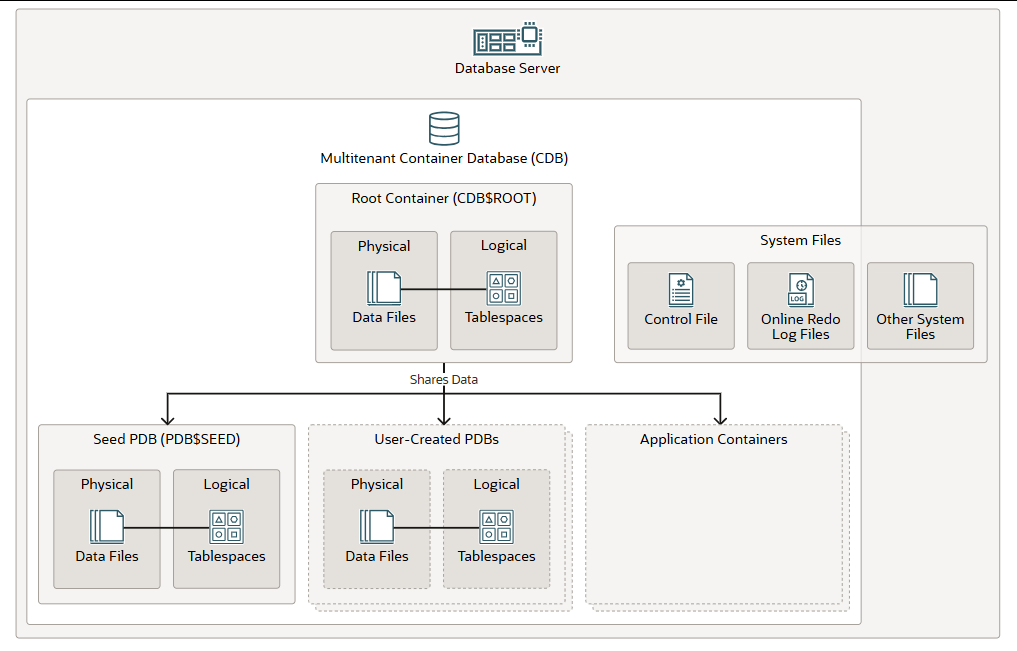
多租户容器数据库 (CDB) 是多个容器数据库的集合,其中每个容器都是模式、对象和相关结构的集合。可插拔数据库 (PDB) 是用户创建的容器,用于存储应用程序(例如人力资源应用程序)的数据和代码。
从用户或应用程序的角度来看,PDB 似乎是一个逻辑上独立且分离的数据库。而从操作系统的角度来看,CDB 才是真正的数据库。
每个 CDB 都包含以下容器:
- 一个名为 CDB$ROOT 的根容器,用于存储 Oracle 提供的元数据和公共用户(属于该 CDB 的所有容器中都已知的数据库用户)。根容器不存储任何用户数据。所有 PDB 都属于该根容器。
- 系统提供一个名为 PDB$SEED 的种子 PDB,它是一个模板,CDB 可以使用该模板创建新的 PDB。您无法修改种子 PDB。
- CDB 中可以包含零个或多个用户创建的 PDB。首次创建 CDB 时,不存在任何 PDB。您可以同时将多个 PDB 插入到同一个 CDB 中,但不能将一个 PDB 插入到多个 CDB 中。每个 PDB 都与其他插入到同一个 CDB 的 PDB 完全隔离。用户只能与 PDB 交互,而不能与种子 PDB 或根容器交互。
- 零个或多个应用程序容器,它们是 CDB 内可选的 PDB 集合,用于存储应用程序的数据和元数据。一个应用程序容器(类似于 CDB)可以包含多个应用程序 PDB,并使这些 PDB 能够共享元数据和数据。
在物理层面上,容器由物理数据文件组成。每个容器至少包含一个数据文件。在逻辑层面上,数据库通过称为表空间的逻辑结构将数据分配到各个数据文件中。
CDB 在运行过程中还会使用多个系统文件。控制文件和重做在线日志文件位于 CDB 内部,并在所有 PDB 和应用程序容器之间共享。其他系统文件则位于 CDB 外部。
注意: Oracle Database 21c 中不再支持非 CDB,这意味着 Oracle 通用安装程序和数据库配置助手 (DBCA)无法再创建非 CDB Oracle AI 数据库实例。
应用容器
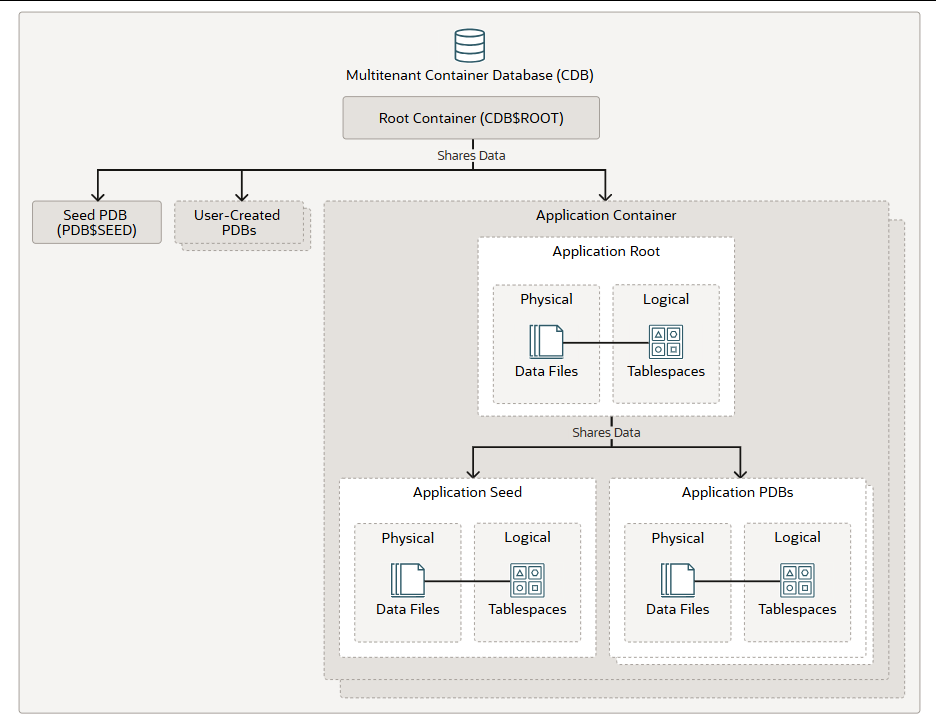
应用程序容器是多租户容器数据库 (CDB)中可选的用户创建组件。应用程序容器存储特定于应用程序的可插拔数据库 (PDB) 的数据和元数据。
在某种程度上,应用程序容器的功能类似于 CDB 内部的特定应用程序 CDB。应用程序容器与 CDB 本身一样,可以包含多个应用程序 PDB,并使这些 PDB 能够以与 CDB 根目录共享数据和元数据的方式共享数据和元数据,就像CDB 根目录与种子 PDB、用户创建的 PDB 以及插入到 CDB 根目录的应用程序容器共享数据和元数据一样。
CDB 可以包含零个或多个应用程序容器。一个应用程序容器由一个应用程序根目录和一个或多个应用程序 PDB 组成,这些应用程序 PDB 插入到应用程序根目录中。应用程序根目录属于 CDB 根目录。应用程序根目录与 CDB 根目录和标准 PDB 的区别在于,它可以存储用户创建的公共对象,这些对象可供插入到应用程序根目录的应用程序 PDB 访问。
应用程序种子是应用程序容器内可选的用户创建 PDB 文件。一个应用程序容器可以包含零个或一个应用程序种子。应用程序种子使您能够快速创建应用程序 PDB 文件。它在应用程序容器中的作用与种子 PDB 文件在 CDB 本身中的作用相同。
在物理层面上,容器由物理数据文件组成。每个容器至少包含一个数据文件。在逻辑层面上,数据库通过称为表空间的逻辑结构将数据分配到各个数据文件中。
典型的应用程序会安装应用程序通用用户、元数据链接的通用对象和数据链接的通用对象。例如,您可以在一个应用程序容器内创建多个与销售相关的产品数据数据库 (PDB),这些 PDB 共享一个应用程序后端,该后端由一组通用表和表定义组成。
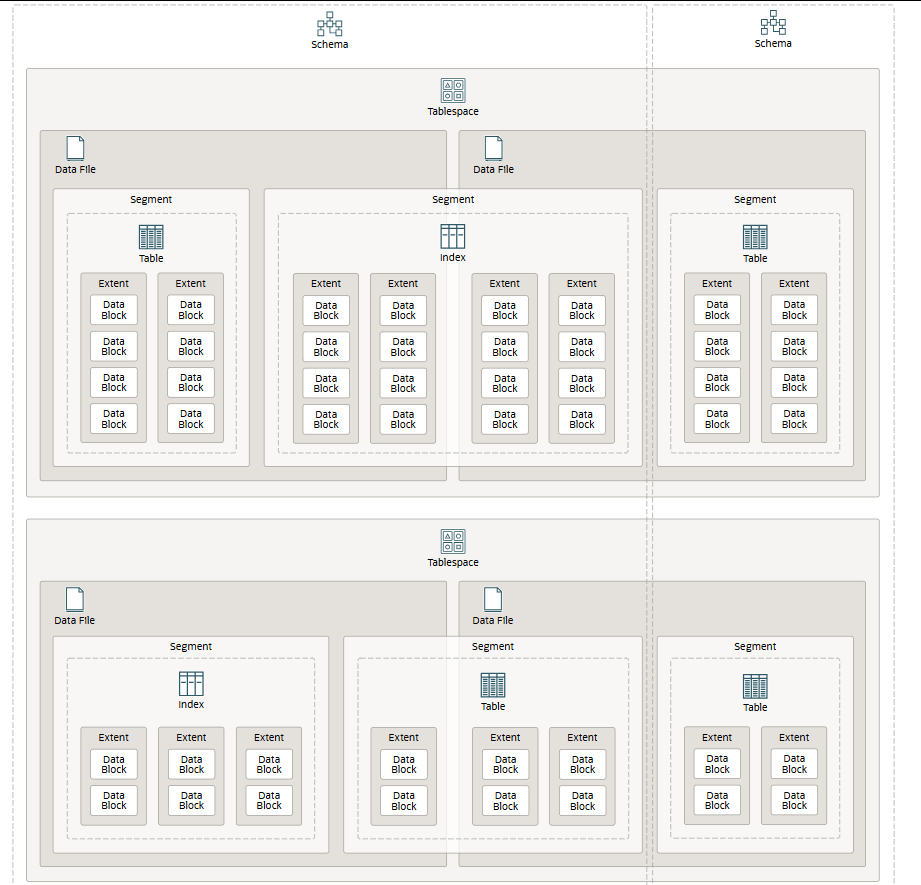
数据库存储结构
多租户容器数据库 (CDB) 是模式和模式对象(例如表和索引)的集合。
在物理层面上,CDB 将对象存储在数据文件中。您可以使用以下机制来存储数据文件:
-
操作系统文件系统是一种用于存储和检索数据的结构。大多数 Oracle AI 数据库都将文件存储在文件系统中。
-
集群文件系统是一种分布式文件系统,它由一组服务器组成,这些服务器协同工作,为客户端提供一致性和高性能。在 Oracle 实时应用集群 (Oracle RAC) 环境中,集群文件系统使共享存储看起来像是一个单一的文件系统,供集群环境中的多台计算机共享。
-
Oracle 自动存储管理(Oracle ASM)。
在逻辑层面上,CDB 使用以下结构将数据分配到各个数据文件中:
- 表空间包含零个或多个段,每个段对应于一个模式对象。一个表空间可以包含分配给不同模式的段,而一个模式的段可以跨越多个表空间。在物理层面上,一个表空间可以将数据存储在多个数据文件中,但多个表空间不能共享数据文件。每个可插拔数据库 (PDB) 和应用程序容器都有自己的一组表空间。您可以将用户数据存储在默认的 USERS 表空间中,也可以为特定的应用程序数据或系统数据创建额外的表空间。
- 段是为特定模式对象分配的区段集合。每个占用存储空间的模式对象(或对象分区)都有自己的段。一个段可以包含来自多个数据文件的区段,但不能跨越多个表空间。
- 区段是逻辑上连续的数据块集合。每个区段都分配给单个数据文件中的一个模式对象。默认情况下,Oracle AI 数据库会在您创建模式对象和段时分配一个初始区段。如果初始区段已满,数据库会自动为该段分配另一个区段。新区段不必位于同一个数据文件中。
- 数据块 是数据存储的最小逻辑单元。一个逻辑数据块对应于数据文件中特定数量的字节的持久存储空间(例如,2 KB)。
Tablespace 表空间
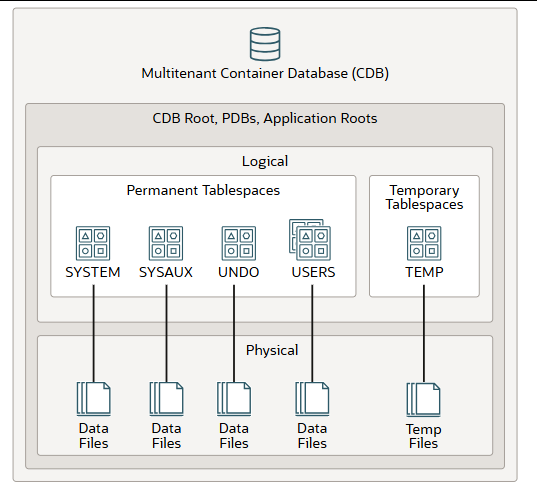
表空间是用于存储段的逻辑存储容器。段是数据库对象,例如表和索引,它们会占用存储空间。
在多租户容器数据库(CDB)中,每个可插拔数据库(PDB)和应用程序根目录都有自己的一组永久表空间,这些表空间对应于物理数据文件:
- 一个SYSTEM 表空间,其中包括数据字典;包含数据库管理信息的表和视图;以及已编译的存储对象,例如触发器、过程和包。
- SYSAUX 表空间是SYSTEM 表空间的辅助表空间。它是许多 Oracle AI 数据库特性和产品的默认表空间,这些特性和产品以前需要自己的表空间,因此它减少了数据库所需的表空间数量。
- 一个或多个撤销表空间。在本地撤销模式(默认模式)下,数据库会在每个 PDB 中自动创建一个撤销表空间。在共享撤销模式下,单实例 CDB 只有一个活动的撤销表空间,而 Oracle 实时应用集群 (Oracle RAC) CDB 的每个实例都有一个活动的撤销表空间。在共享撤销模式下,所有撤销表空间在所有容器的数据字典和相关视图中均可见。
- 用户创建的表空间可以有零个或多个,用于存储 PDB 中用户定义的模式和对象的数据。您可以将用户数据存储在默认的 USERS 表空间中,也可以创建额外的表空间来存储特定的应用程序数据或系统数据。
每个容器还有一个临时表空间,对应于物理临时文件。CDB 根目录以及每个应用程序根目录、应用程序 PDB和 PDB 都有一个默认的临时表空间。临时表空间包含仅在会话期间存在的瞬态数据。任何永久模式对象都不能驻留在临时表空间中。
Schema 模式和模式对象
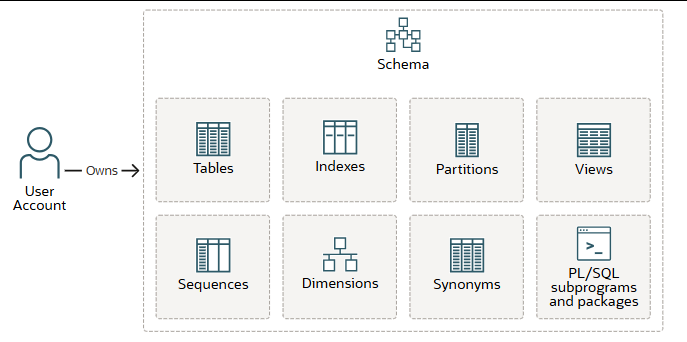
数据库模式是数据结构(称为模式对象)的逻辑容器。每个 Oracle AI 数据库用户帐户都拥有一个与用户名相同的模式。
注意:数据库还会存储模式中未包含的其他类型的对象。这些对象包括数据库用户帐户、角色、上下文和字典对象。
分配了物理空间的模式对象(例如表和索引)存储在数据文件中 。在逻辑层面上,数据库使用表空间将数据分配到各个数据文件中。模式和表空间之间没有必然联系:一个表空间可以包含来自不同模式的对象,而同一模式的对象也可以存储在不同的表空间中。
模式包含以下几种主要类型的对象:
- 表以行的形式存储数据。表是关系数据库中最重要的模式对象。
- 索引包含表或表簇中每个索引行的条目,并提供对行的直接、快速访问。
- 分区是大型表和索引的组成部分。每个分区都有自己的名称,并且可以选择性地具有自己的存储特性。
- 视图是对一个或多个表或其他视图中数据的自定义呈现。您可以将其视为存储的查询。视图本身并不包含数据。
- 多个用户可以共享序列来生成整数。通常,序列用于生成主键值。
- 维度定义了列集之间的父子关系,其中列集中的所有列必须来自同一张表。但是,一个列集(称为级别)中的列可以来自与另一个列集中的列不同的表。您可以使用维度对客户、产品和时间等数据进行分类。
- 同义词是其他模式对象的别名。由于同义词本质上就是别名,因此除了在数据字典中定义之外,它不需要其他存储空间。
- PL/SQL 是 Oracle 对 SQL 的过程式扩展。PL /SQL 子程序是一个已命名的 PL/SQL 代码块,您可以使用一组参数来调用它。PL/SQL 包将逻辑上相关的 PL/SQL 类型、变量和子程序组合在一起。
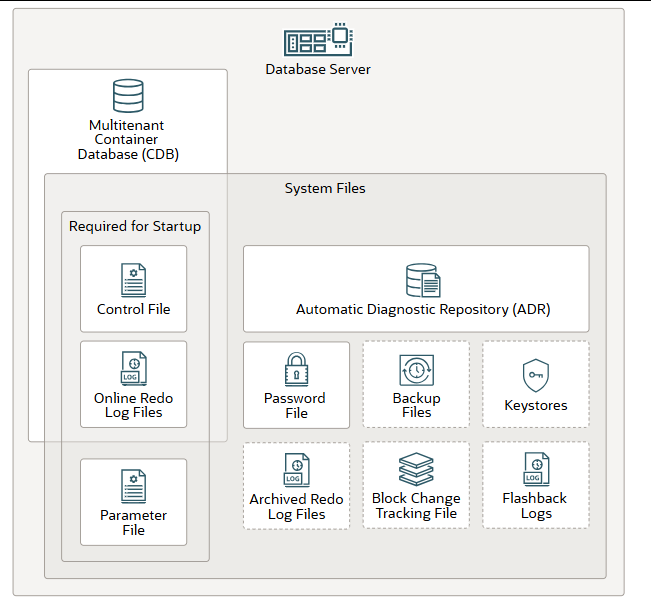
数据库系统文件
Oracle AI 数据库使用多个位于数据库服务器上的数据库系统文件。这些文件与数据文件不同,数据文件是属于数据库容器的物理文件。
数据库启动需要以下文件:
- 控制文件: 控制文件存储数据文件和在线重做日志文件的元数据(例如,它们的名称和状态)。数据库实例需要这些信息才能打开数据库。控制文件还包含在数据库未打开时必须可访问的元数据。每个多租户容器数据库 (CDB) 都有一个唯一的控制文件,但允许存在多个相同的副本。可插拔数据库 (PDB) 没有单独的控制文件。
- 参数文件:定义了数据库实例启动时的配置方式。您可以使用初始化参数文件(pfile)或服务器参数文件(spfile)。
- 在线重做日志文件:会实时存储数据库的更改,并用于数据恢复。这些文件是 CDB 的一部分。
注意: Oracle 建议您在不同位置维护多个控制文件和联机重做日志文件的副本,以避免单点故障。这称为多路复用。有关详细信息,请参阅“多个控制文件和多个联机重做日志文件副本”。
数据库还使用以下系统文件,这些文件位于 CDB 之外:
- 自动诊断存储库 (ADR)是一个基于文件的数据库诊断数据存储库,用于存储跟踪信息、转储文件、告警日志、运行状况监控报告等。它在多个实例和多个产品中采用统一的目录结构。数据库、Oracle 自动存储管理 (Oracle ASM)、监听器、Oracle 集群件以及其他 Oracle 产品或组件都会将所有诊断数据存储在 ADR 中。每个产品的每个实例都会将诊断数据存储在 ADR 中各自的主目录中。
- (可选)备份文件用于数据库恢复。通常情况下,当介质故障或用户错误导致原始文件损坏或删除时,您需要还原备份文件。
- (可选)归档重做日志文件包含数据库实例生成的数据更改历史记录。您可以使用这些文件和数据库备份来恢复丢失的数据文件。
- (可选)密码文件允许具有 SYSDBA、SYSOPER、SYSBACKUP、SYSDG、SYSKM、SYSRAC 和 SYSASM 角色的用户远程连接到数据库实例并执行管理任务。
- (可选)密钥库 (以前称为钱包)是安全的软件容器,用于存储身份验证和签名凭证。Oracle AI 数据库支持软件密钥库、Oracle Key Vault 和其他兼容 PKCS#11 的密钥管理设备。
- (可选)块更改跟踪文件包含已更改的数据块,用于提高增量备份的性能。在增量备份期间,恢复管理器 (RMAN) 无需扫描所有数据块来识别已更改的数据块,而是使用此文件来识别需要备份的已更改数据块。
- (可选)闪回数据库使用闪回日志访问数据块的历史版本以及归档重做日志中的一些信息。这使您可以将数据库恢复到最近的某个时间点的状态。闪回数据库要求您为数据库配置快速恢复区,因为闪回日志只能存储在快速恢复区中。只有在闪回日志可用的情况下才能使用闪回数据库,因此您必须预先设置数据库以创建闪回日志。
ADR 自动诊断库
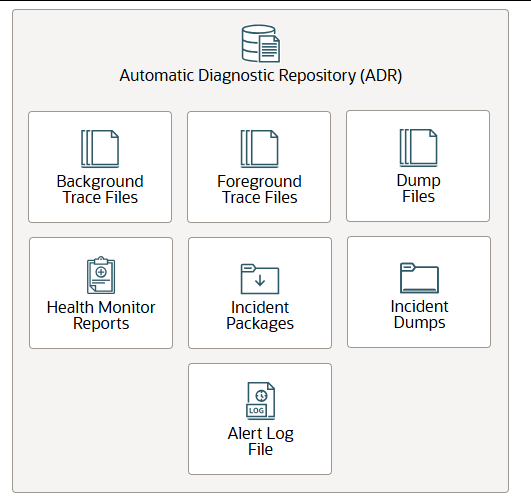
自动诊断存储库(ADR)是一个系统级的数据库诊断数据跟踪和日志记录中央存储库。它包含以下内容:
- 后台跟踪文件存储来自数据库后台进程的信息。当进程检测到内部错误时,它会将错误信息转储到其跟踪文件中。写入跟踪文件的部分信息供数据库管理员使用,而其他信息则供 Oracle 支持服务使用。通常,数据库后台进程跟踪文件名包含 Oracle 系统标识符 (SID)、后台进程名称和操作系统进程号。RECO 进程的跟踪文件示例为mytest_reco_10355.trc:
- 前台跟踪文件存储来自服务器进程的信息。当进程检测到内部错误时,它会将错误信息转储到其跟踪文件中。服务器进程跟踪文件名包含 Oracle SID、字符串ora和操作系统进程号。服务器进程跟踪文件名示例为
<server_process_id>mytest_ora_10304.trc。 - 转储文件是一种特殊的跟踪文件,其中包含有关状态或结构的详细时间点信息。转储文件通常是对某个事件的一次性诊断数据输出,而跟踪文件则往往是连续的诊断数据输出。
- 健康监控报告包含来自健康监控框架的诊断检查结果。健康检查可以检测文件损坏、物理块和逻辑块损坏、撤销和重做损坏、数据字典损坏等等。健康检查会生成检查结果报告,并且在许多情况下,还会提供解决问题的建议。
- 事件包包含用于将诊断数据上传到 Oracle 支持的信息。事件包是存储在 ADR 中的元数据集合,指向 ADR 内外的诊断数据文件和其他文件。创建事件包时,您可以选择一个或多个问题添加到其中。然后,支持工作台会自动将与所选问题关联的问题信息、事件信息和诊断数据(例如跟踪文件和转储文件)添加到事件包中。
- 事件转储文件包含 Oracle AI 数据库在事件发生时收集的诊断数据。数据库会将一个或多个转储文件写入为该事件创建的事件目录。事件转储文件的文件名中还包含事件编号。
- 告警日志文件是按时间顺序记录消息和错误的日志。Oracle 建议您定期查看告警日志。
备份文件
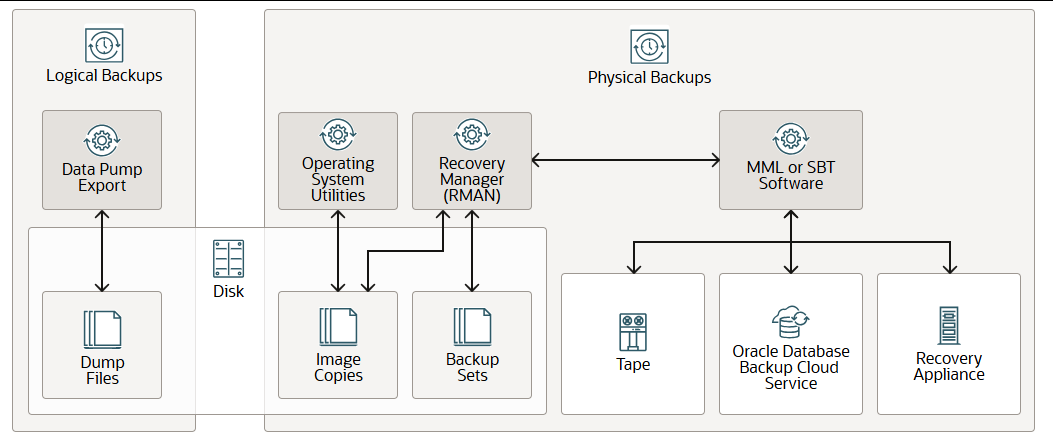
您可以创建以下几种类型的备份:
- 逻辑备份包含表、存储过程和其他逻辑数据。您可以使用 Oracle AI 数据库实用程序(例如数据泵导出)提取逻辑数据,并将其存储在磁盘上的二进制文件中。逻辑备份可以作为物理备份的补充。
- 物理备份是数据库文件的物理副本。您可以使用恢复管理器 (RMAN)或操作系统自带的实用程序创建物理备份。
使用 RMAN 时,您可以将以下类型的备份格式存储在磁盘上:
- 镜像副本是指数据文件、控制文件或归档重做日志文件的逐位磁盘副本。您可以使用操作系统实用程序或 RMAN 创建物理文件的镜像副本,并使用任一工具进行还原。镜像副本对于磁盘非常有用,因为您可以对其进行增量更新并进行原地恢复。
- 备份集是 RMAN 创建的一种专有格式。它包含来自一个或多个数据文件、归档重做日志文件、控制文件或服务器参数文件的数据。备份集的最小单元是称为备份片段的二进制文件。备份集是 RMAN 唯一能够将备份写入顺序设备(例如磁带驱动器)的格式。备份集的一个优点是 RMAN 使用未使用块压缩来节省备份数据文件的空间。备份集仅包含数据文件中已用于存储数据的块。备份集还可以进行压缩、加密和写入磁带。它们可以使用数据文件副本所不具备的高级未使用空间压缩技术。
RMAN 还可以与媒体管理库 (MML) 或系统备份到磁带 (SBT) 软件进行交互,从而创建磁带备份、Oracle 数据库备份云服务或零数据丢失恢复设备(通常称为恢复设备)。
后台进程
进程监控进程 PMON
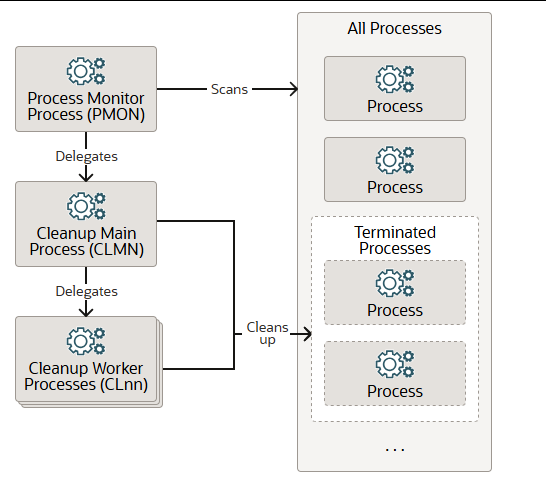
进程监视器进程 (PMON)会定期扫描所有进程,查找任何异常终止的进程。PMON 将清理工作委托给清理主进程 (CLMN),CLMN 会定期清理已终止的进程和会话。CLMN 再将清理工作委托给清理工作进程 (CLnn)。
PMON 作为操作系统进程运行,而非线程。除了数据库实例外,PMON 还运行在 Oracle 自动存储管理 (Oracle ASM) 实例和 Oracle ASM 代理实例上。
进程管理进程 PMAN
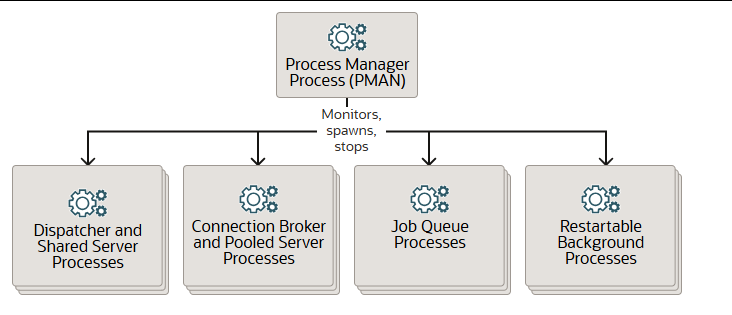
进程管理器进程 (PMAN)负责管理多个后台进程,包括共享服务器、池化服务器和作业队列进程。PMAN 会根据需要监控、启动和停止以下类型的进程:
- 调度程序和共享服务器进程
- 数据库驻留连接池的连接代理和池化服务器进程
- 作业队列进程
- 可重启的后台进程
PMAN 作为操作系统进程运行,而非线程运行。除了数据库实例外,PMAN 还可在 Oracle 自动存储管理 (Oracle ASM) 实例和 Oracle ASM 代理实例上运行。
监听注册进程 LREG
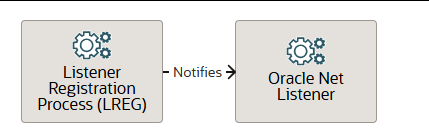
监听器注册进程(LREG)会通知监听器有关实例、服务、处理程序和端点的信息。LREG 可以作为线程或操作系统进程运行。除了数据库实例外,LREG 还会在Oracle自动存储管理(Oracle ASM)实例和 Oracle 实时应用集群(Oracle RAC)上运行。
系统监听进程 SMON
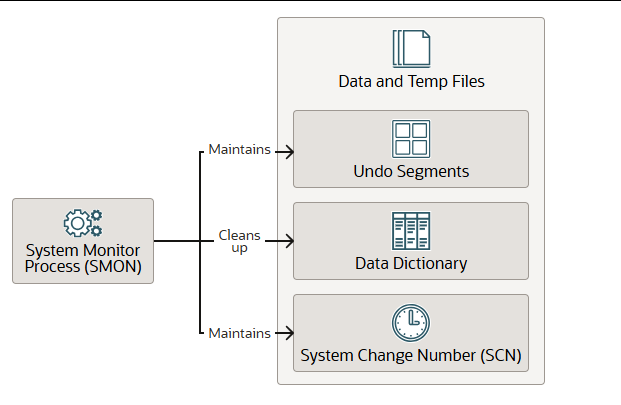
系统监控进程 (SMON)执行许多数据库维护任务,包括以下任务:
- SMON通过根据撤销空间使用统计信息对撤销段进行联机、脱机和收缩操作来维护撤销表空间。作为撤销维护的一部分,SMON 还有助于清理较大的已终止事务,例如当 PMON 检测到拥有该事务的进程已终止并开始清理时。SMON 可能会调用并行查询进程来帮助并行回滚这些事务。
- 当数据字典处于瞬态和不一致状态时,对其进行清理。
- 维护用于支持 Oracle Flashback 功能的系统变更号 (SCN) 到时间映射表。
SMON 能够应对后台活动期间发生的内部和外部错误。SMON 可以作为线程或操作系统进程运行。在 Oracle 实时应用集群 (Oracle RAC) 数据库中,一个实例的 SMON 进程可以为其他发生故障的实例执行实例恢复。
数据库写入进程 DBWn
数据库写入进程 (DBWn)读取数据库缓冲区缓存,并将修改后的缓冲区写入数据文件。它还处理检查点、文件打开同步以及块写入记录的日志记录。如果配置了闪存缓存,DBWn 还会读取数据库智能闪存缓存(闪存缓存)。
在许多情况下,DBWn 写入的数据块分散在磁盘各处,因此其写入速度往往比日志写入进程 (LGWR) 执行的顺序写入要慢。DBWn 会尽可能执行多块写入以提高效率。多块写入中写入的数据块数量因操作系统而异。
初始化DB_WRITER_PROCESSES参数指定数据库写入进程的数量。数据库写入进程的数量可以设置为 1 到 100 个。前 36 个数据库写入进程的名称分别为 DBW0-DBW9 和 DBWa-DBWz。第 37 个到第 100 个数据库写入进程的名称分别为 BW36-BW99。数据库会DB_WRITER_PROCESSES根据 CPU 和处理器组的数量,为该参数选择一个合适的默认设置,或者调整用户指定的设置。
检查点进程
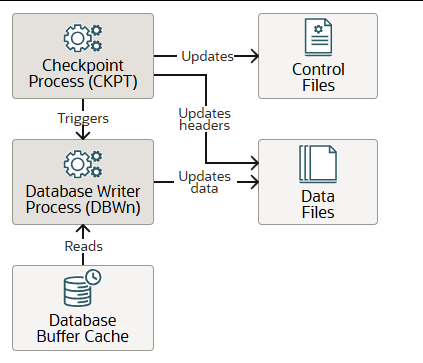
检查点进程 (CKPT)会在特定时间触发数据库写入进程 (DBWn)读取数据库缓冲区缓存并将修改后的缓冲区写入数据文件,从而启动检查点请求。每次检查点请求完成后,CKPT 会更新数据文件头和控制文件,以记录最新的检查点信息。
CKPT 每三秒检查一次内存量是否超过PGA_AGGREGATE_LIMIT初始化参数的值,如果超过,则采取相应措施。
CKPT 可以作为线程或操作系统进程运行。除了数据库实例外,CKPT 还可以在 Oracle 自动存储管理 (Oracle ASM) 实例上运行。
可管理性监控流程 (MMON) 和可管理性监控精简版流程 (MMNL)
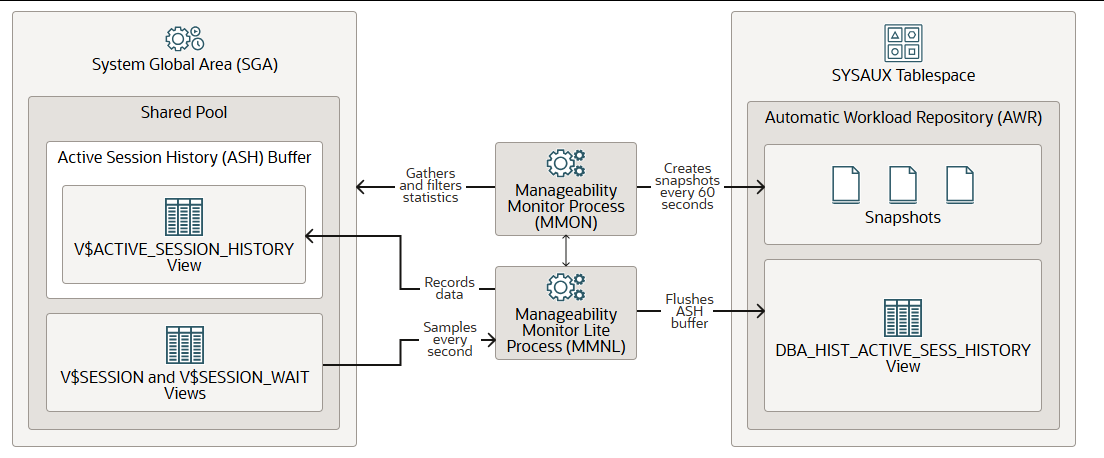
可管理性监视进程(MMON)和可管理性监视轻量级进程(MMNL)执行与自动工作负载存储库(AWR)相关的任务。AWR是一个历史性能数据仓库,包含系统、会话、单个SQL语句、段和服务的累积统计信息。它提供问题检测和自动调优功能。AWR位于SYSAUX表空间中。AWR报告可以在CDB根容器或任何PDB中生成。有关多租户容器数据库(CDB)中AWR的工作方式的更多信息,请参见《关于在CDB中使用可管理性功能》。
MMON从系统全局区(SGA)收集内存统计信息,对其进行筛选,并每60分钟(或您选择的其他间隔)在AWR中创建这些统计信息的快照。它还执行自动数据库诊断监视器(ADDM)分析,并对超过阈值的指标发出警报。
MMNL收集会话统计信息(例如用户ID、状态、机器以及正在处理的SQL),并将它们存储在活动会话历史(ASH)缓冲区中,该缓冲区是SGA共享池的一部分。具体来说,MMNL每秒采样VSESSION和VSESSION_WAIT视图,然后将这些数据记录在ASH缓冲区中的V$ACTIVE_SESSION_HISTORY视图中。MMNL不采样非活动会话。ASH是内存中的滚动缓冲区,因此当需要时,较新的信息会覆盖较早的信息。当ASH缓冲区满或MMON创建快照时,MMNL会将ASH缓冲区的内容刷新(清空)到AWR中的DBA_HIST_ACTIVE_SESS_HISTORY视图中。由于空间成本较高,MMNL每10条记录仅刷新一条。MMNL还计算指标。
MMON和MMNL既可以作为线程运行,也可以作为操作系统进程运行。除了数据库实例外,MMON和MMNL还会在Oracle自动存储管理(Oracle ASM)实例上运行。
恢复进程(RECO)
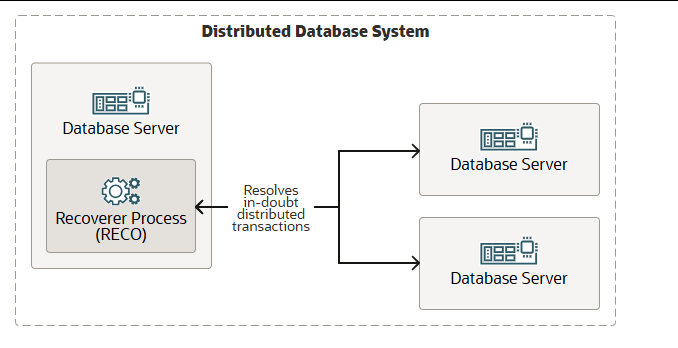
恢复进程(RECO)用于解决分布式数据库系统中因网络或系统故障而处于挂起状态的分布式事务。分布式数据库系统是由多个数据库服务器组成的一组,这些服务器对应用程序而言看起来像是一个单一的数据源。节点的RECO进程会自动连接到参与可疑分布式事务的其他数据库。当RECO重新建立数据库之间的连接时,它会自动解决所有可疑事务,并从每个数据库的待处理事务表中删除与已解决事务对应的行。RECO可以作为线程运行,也可以作为操作系统进程运行。
日志写进程 LGWR
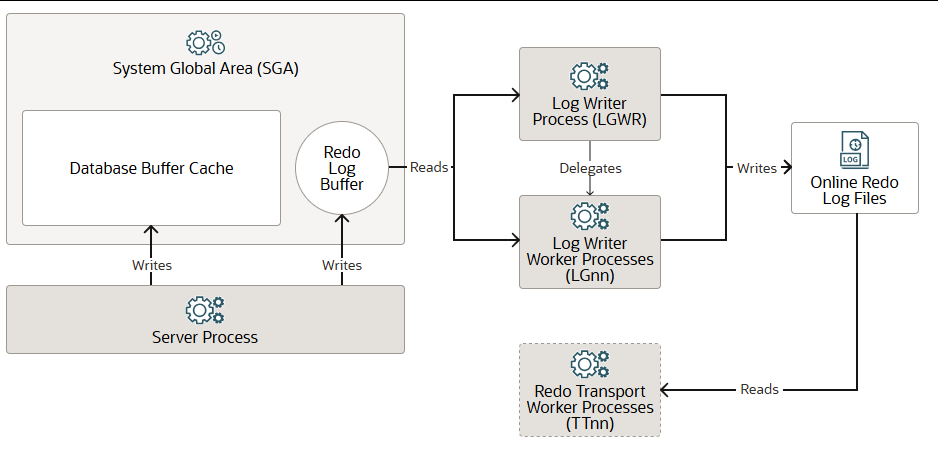
服务器进程将数据块的更改写入数据库缓冲区缓存,并将重做数据写入重做日志缓冲区。日志写入进程(LGWR)将重做日志条目按顺序从重做日志缓冲区写入联机重做日志。如果数据库具有多路复用的重做日志,则LGWR会将相同的重做日志条目写入重做日志文件组中的所有成员。
LGWR处理速度非常快或必须进行协调的操作。它将可能受益于并发操作的任务委托给日志写入工作进程(LGnn),这些进程的编号为LG00-LG99。这些操作包括将日志缓冲区中的重做数据写入重做日志文件,以及向等待的服务器进程发布已完成的写入通知。
重做传输工作进程(TTnn),编号为TT00-TTzz,将来自当前联机重做日志和备用重做日志的重做数据传输到为异步(ASYNC)重做传输配置的远程备用目标。
LGWR可以作为线程或操作系统进程运行。除了数据库实例外,LGWR还运行在Oracle自动存储管理(Oracle ASM)实例上。在Oracle Real Application Clusters(Oracle RAC)配置中的每个数据库实例都有其自己的重做日志文件集。
归档进程 ARCn
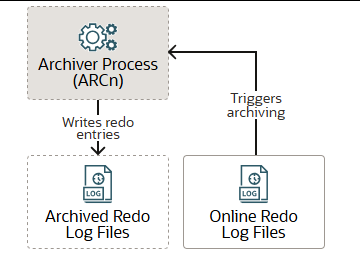
归档进程(ARCn)仅在数据库处于ARCHIVELOG模式且启用了自动归档时存在。在这种情况下,ARCn会自动归档联机重做日志文件。日志写入进程(LGWR)在联机重做日志组已被归档之前,无法重用并覆盖该日志组。数据库会根据需要启动多个ARCn进程,以确保已填满的联机重做日志的归档不会滞后。可能的进程包括ARC0-ARC9和ARCa-ARCt(共31个可能的目标)。LOG_ARCHIVE_MAX_PROCESSES初始化参数指定数据库初始调用的ARCn进程数量。如果您预计归档工作量较大(例如在数据批量加载期间),可以增加ARCn进程的最大数量。此外,还可以有多个归档日志目标。Oracle建议每个目标至少有一个ARCn进程。ARCn可以作为线程运行,也可以作为操作系统进程运行。
CJQ0
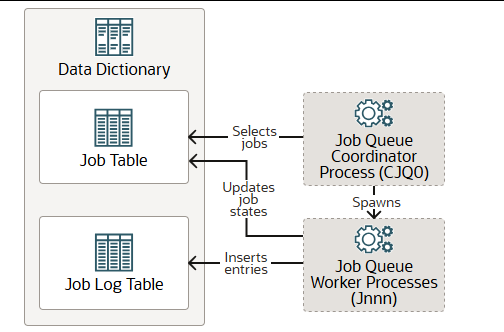
作业队列协调进程(CJQ0)从数据字典中选择需要运行的作业,并启动作业队列工作进程(Jnnn)来执行这些作业。Oracle Scheduler 会根据需要自动启动和停止 CJQ0。JOB_QUEUE_PROCESSES 初始化参数指定可用于运行作业的最大进程数。CJQ0 仅启动与需要运行的作业数量和可用资源相匹配的作业队列进程。
Jnnn 进程运行作业协调器分配的作业。当工作进程选择作业进行处理时,它们会执行以下操作:
- 收集运行作业所需的所有元数据(例如,程序参数和权限信息)。
- 以作业所有者的身份启动数据库会话,启动事务,然后开始运行作业。
- 作业完成后提交并结束事务。
- 关闭会话。
当作业完成时,工作进程会执行以下操作:
- 如需重新调度,则重新安排作业。
- 更新作业表中的状态,以反映作业是否已完成或计划再次运行。
- 在作业日志表中插入一条记录。
- 更新运行次数,必要时更新失败次数和重试次数。
- 清理。
- 查找新任务。(如果没有新任务,它们将进入睡眠状态。)
CJQ0 和 Jnnn 均可作为线程或操作系统进程运行。
恢复写进程 RVWR
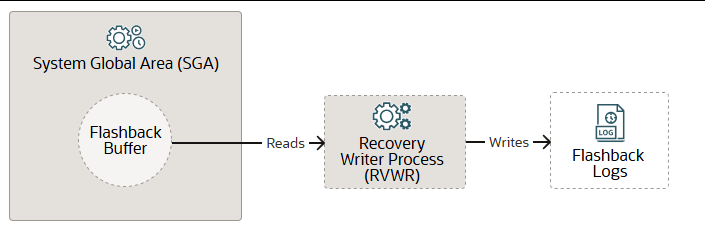
当您使用闪回数据库功能时,恢复写入进程(RVWR)会从系统全局区(SGA)中的闪回缓冲区读取闪回数据,并将其写入闪回日志。也就是说,它会将数据库从当前状态回退到过去某个时间点的事务,前提是您拥有所需的闪回日志。RVWR可以作为线程运行,也可以作为操作系统进程运行。
闪回数据归档进程 FBDA
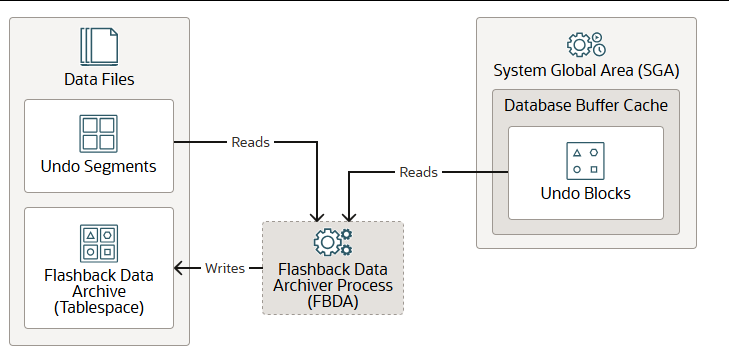
使用闪回数据库时,闪回数据归档进程(FBDA)会跟踪并存储表在其整个生命周期中的事务更改。这样,您可以将表闪回,将其恢复到过去某个时间点的状态。
当修改已跟踪表的事务提交时,FBDA 会读取数据库缓冲区缓存中的撤销块以及数据文件中的撤销段。然后,它会筛选出与标记为归档的对象相关的部分,并将这些撤销信息复制到数据文件中的闪回数据归档(表空间)中。FBDA 会维护当前行的元数据,并跟踪已归档的数据量。
FBDA 可以自动管理闪回数据归档的空间、组织(表空间分区)和保留期限。此外,FBDA 还会跟踪已跟踪事务的归档进度。FBDA 可以作为线程或操作系统进程运行。
空间管理协调员进程 SMCO
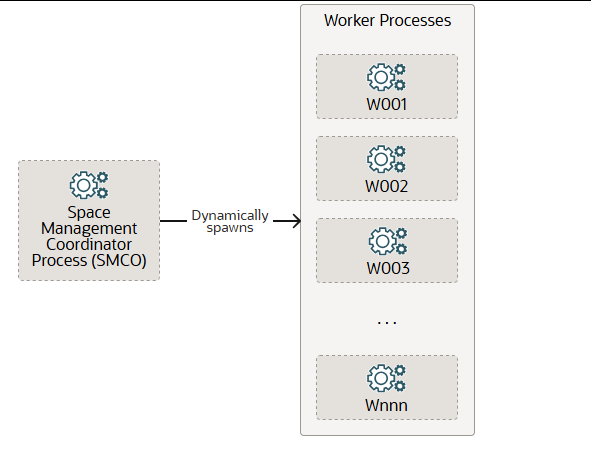
可选的空间管理协调进程 (SMCO)负责调度各种空间管理任务,包括主动空间分配和空间回收。SMCO 会动态生成空间管理工作进程 (Wnnn)来执行这些任务。工作进程启动后,会作为自主代理运行。完成一项任务后,工作进程会自动从队列中领取另一项任务。长时间空闲后,该进程会自动终止。
Wnnn 工作进程(命名为 W001、W002 等)代表空间管理和 Oracle AI 数据库内存选项执行任务。
对于空间管理,Wnnn 进程在后台执行空间管理任务,包括以下任务:
根据空间使用增长分析,预先将空间分配到本地管理的表空间和 SecureFiles 段中。
创建和管理临时表空间元数据,并从孤立的临时段中回收空间。
从丢弃的段中回收空间。
执行快速导入延迟插入操作。
对于 Oracle AI 数据库内存选项,Wnnn 进程执行以下任务:
预先填充优先级为 LOW/MEDIUM/HIGH/CRITICAL 的内存启用对象,并为内存协调器后台进程 (IMCO) 重新填充内存对象。
响应引用内存启用对象的查询和 DML,启动 IMCO 前台进程的内存填充和重新填充任务。
SMCO 和 Wnnn 都可以作为线程或操作系统进程运行。
调度程序进程 (Dnnn) 和共享服务器进程 (Snnn)
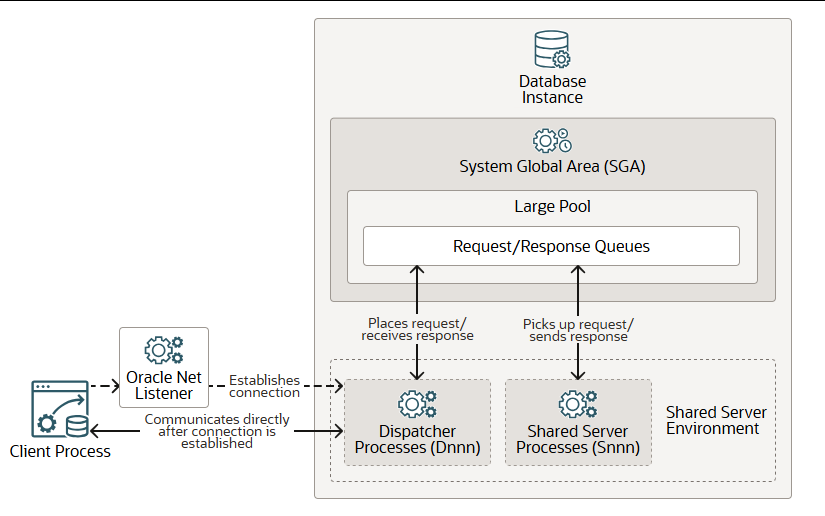
在共享服务器环境中,dispatcher process 调度进程 (Dnnn)将多个传入的网络会话请求定向到 shared server processes 共享服务器进程池(Snnn) 。您可以为单个数据库实例创建多个调度进程。
Oracle Net 监听器进程会与调度器建立连接。当客户端进程发出需要共享服务器进程的连接请求时,监听器会返回调度器的地址,以便客户端进程在连接建立后可以直接与调度器通信。
调度器将客户端请求放入数据库实例内系统全局区 (SGA) 大池中的请求队列。下一个可用的共享服务器进程会领取并处理该请求。请求处理完毕后,共享服务器进程会将响应放入调用调度器的响应队列(位于大池中),响应队列会将响应发送给调度器。调度器最终将处理完毕的请求返回给客户端进程。
Snnn 和 Dnnn 都可以作为线程或操作系统进程运行。除了数据库实例之外,Dnnn 还可以在共享服务器环境中运行。
参考链接
https://docs.oracle.com/en/database/oracle/oracle-database/26/cncpt/introduction-to-oracle-database.html#GUID-8F2EEEC8-0372-4419-88FF-7D77A9C0FCAD https://docs.oracle.com/en/database/oracle/oracle-database/26/dbiad/db_dbserver.html https://docs.oracle.com/en/database/oracle/oracle-database/26/adrac/rac_db_config.html
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
——————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
——————————————————————————

